來自 | 知乎? ?作者丨卜居
鏈接丨h(huán)ttps://zhuanlan.zhihu.com/p/231302709
文僅交流,如侵刪
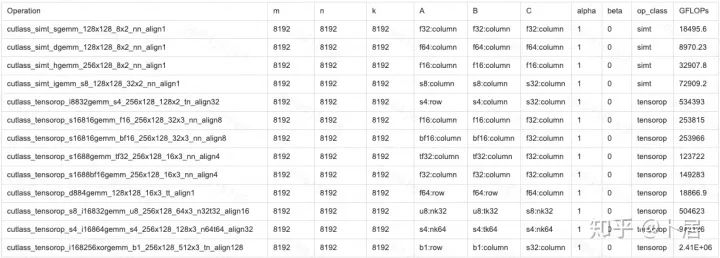
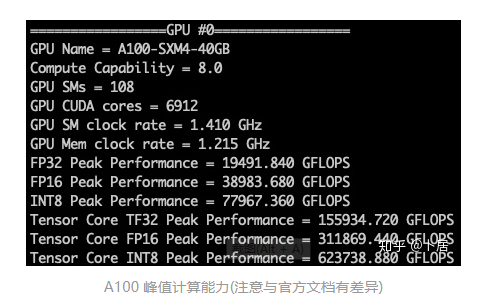
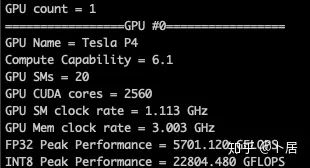
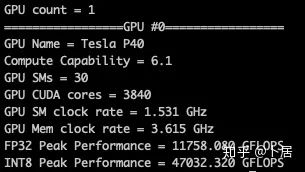
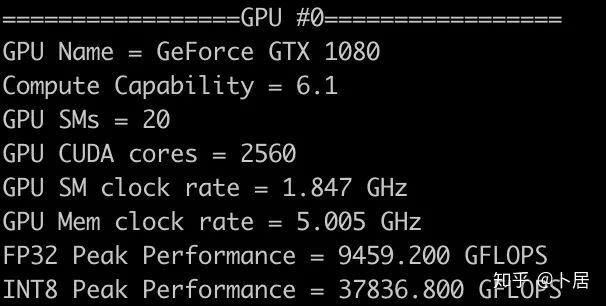
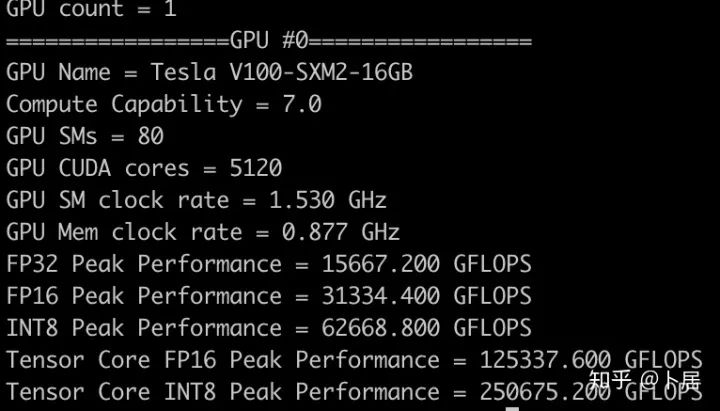
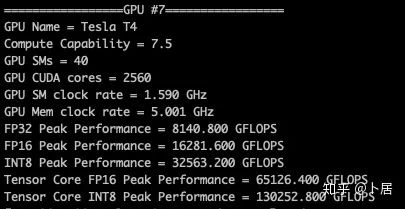
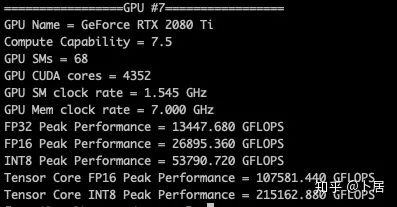
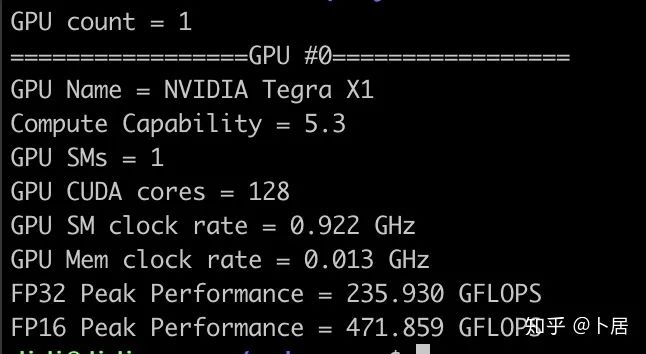
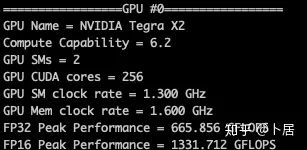
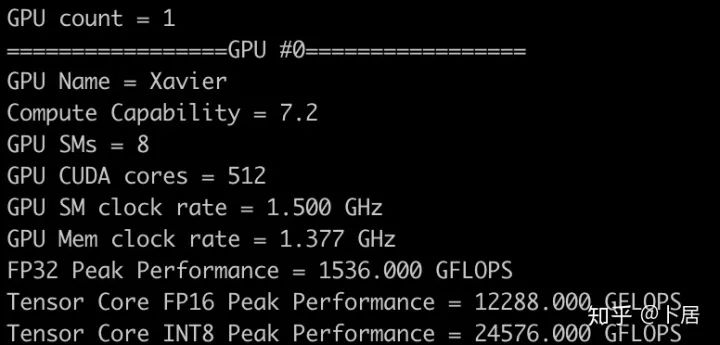
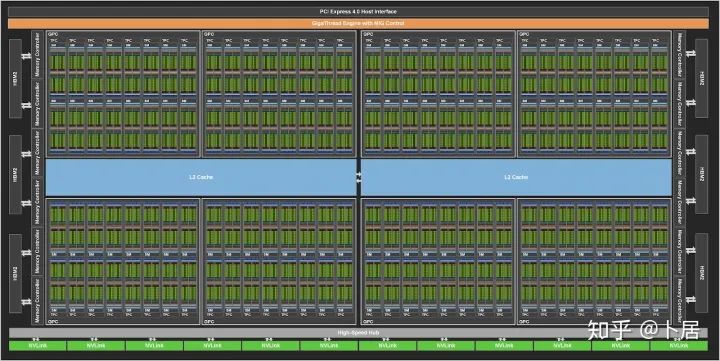
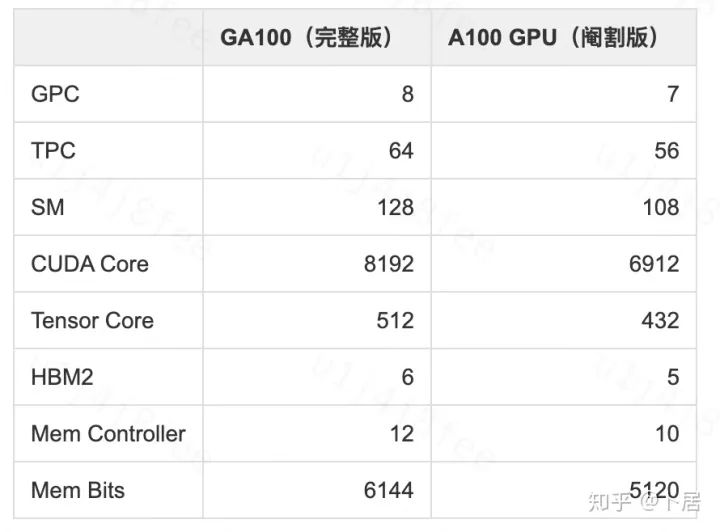
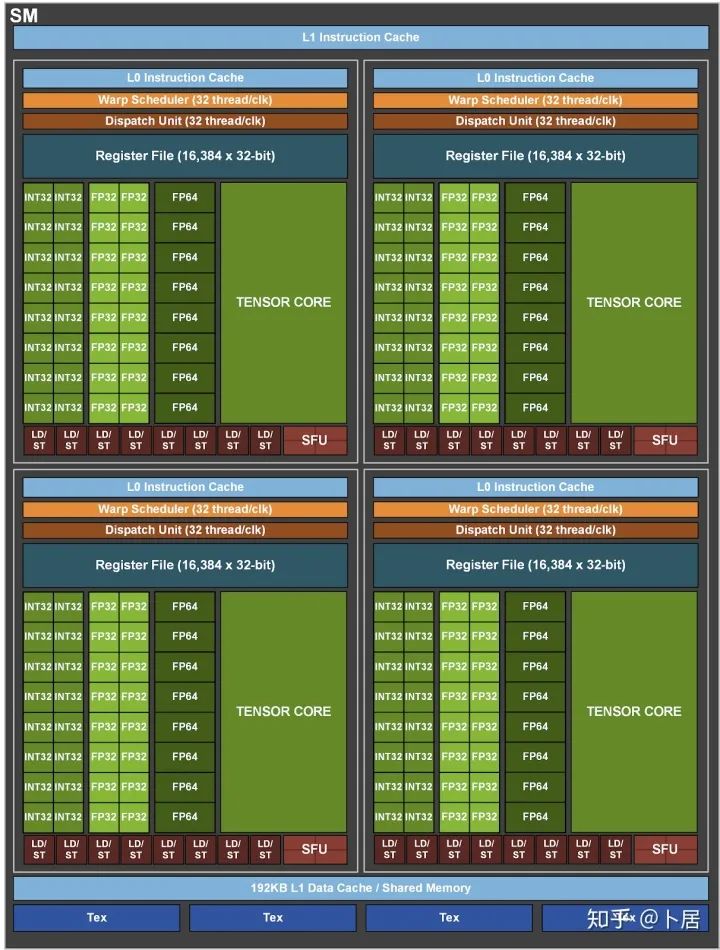
? ?? 1、前言 2020年5月14日,在全球疫情肆虐,無數(shù)仁人志士前赴后繼攻關新冠疫苗之際,NVIDIA 創(chuàng)始人兼首席執(zhí)行官黃仁勛在自家廚房直播帶貨,哦不對應該是 NVIDIA GTC 2020 主題演講中熱情洋溢地介紹了新鮮出爐的基于最新 Ampere 架構的 NVIDIA A100 GPU,號稱史上最豪華的燒烤。 從 NVIDIA 發(fā)布會內容以及白皮書中能看到一些奪目的數(shù)字,今天我們來解密這些數(shù)字是怎么得出來的。為此我們需要深入 GPU 架構一探究竟。 ? ?? 2、GPU 架構演變 圖形處理器(GPU, Graphics Processing Unit),用來加速計算機圖形實時繪制,俗稱顯卡,經常用于打游戲。自 NVIDIA 于 1999 年發(fā)明第一款 GPU GeForce 256,爾來二十有一年矣。 GeForce 256, 1999 從圖片看到 GeForce 256 衣著相當簡樸,完全看不到 RTX 3090 的貴族氣質,顯示輸出口僅支持 VGA,顯存 32 MB,另外和主機的接口是早已不見蹤影的 AGP,支持的圖形 API 為 DirectX 7.0、OpenGL 1.2,目前主流游戲都跑不動,放到現(xiàn)在只能當擺設。 那時顯卡還只是純粹的顯卡,硬件架構還是固定的渲染流水線,如下圖所示。 渲染流水線中可被程序員控制的部分有兩處:Geometry Processing 和 Pixel Processing,前者處理幾何坐標變換,涉及矩陣乘計算;后者處理圖像像素,涉及插值計算。有一些對科學有執(zhí)著追求的人們試圖用渲染流水線做一些除了打游戲之外更為正經的工作。于是,他們把計算輸入數(shù)據(jù)偽造成頂點坐標或紋理素材,把計算機程序模擬為渲染過程,發(fā)揮異于常人的聰明才智,使用 OpenGL/DirectX/Cg 實現(xiàn)各類數(shù)值算法,將顯卡這個為游戲做出突出貢獻的可造之材打造為通用并行計算的利器,此時的 GPU 被賦能了更多工作內容,稱作 GPGPU(General Purpose GPU)。 從事 GPGPU 編程的程序員十分苦逼,既要懂圖形 API、GPU 架構,還要把各個領域算法摸清楚翻譯為頂點坐標、紋理、渲染器這些底層實現(xiàn),十分難以維護,今天一氣呵成的代碼,明天就形同陌路。程序如有 bug,調試工具奇缺,只能靠運氣和瞪眼法。 為了徹底解放生產力,提高編程效率,NVIDIA 在 2006 年引入統(tǒng)一圖形和計算架構以及 CUDA 工具,從此 GPU 就可以直接用高級語言編程,由程序員控制眾多 CUDA 核心完成海量數(shù)值計算,GPGPU 業(yè)已成為歷史。 GeForce 8800 是第一款支持 CUDA 計算的 GPU,核心為 G80,首次將渲染流水線中分離的頂點處理器與像素處理器替換為統(tǒng)一的計算單元,可用于執(zhí)行頂點/幾何/像素/通用計算等程序。G80 首次引入 SIMT(Single-Instruction Multiple-Thread) 執(zhí)行模型,多個線程在不同計算單元上并發(fā)執(zhí)行同一條指令,引入 barrier 和 shared memory實現(xiàn)線程間同步與通信。G80 架構圖如下: G80/G92 架構圖,G92 相比 G80 僅為工藝升級(90nm -> 65nm),架構沒有變化 在 G80 中有 8 個 TPC(紋理處理簇,Texture Processing Clusters),每個 TPC 有 2 個 SM(流多處理器,Stream Multiprocessors),共計 16 個 SM。每個 SM 內部架構如下圖: G80/G92 架構圖 每個 SM 內部有 8 個 SP(流處理器,Streaming Processor,后改稱 CUDA Core),這是真正干活的單元,可以完成基本數(shù)學計算。8 個 SP 需要聽口號統(tǒng)一行動,互相之間通過 shared memory 傳遞信息。 G80 架構比較簡單,奠定了通用計算 GPU 的基礎。接下來的 14 年,NVIDIA GPU 以大約每兩年一代的速度逐步升級硬件架構,配套軟件和庫也不斷豐富起來,CUDA Toolkit 最新已到 11.0,生態(tài)系統(tǒng)已頗為健壯,涵蓋石油探測、氣象預報、醫(yī)療成像、智能安防等各行各業(yè), GPU 現(xiàn)已成為世界頂級超算中心的標配計算器件。 下表展示了從 2006 年至今支持 CUDA 計算的 GPU。有沒有看到你手中的那一款? 架構起名是有講究的,都是科學史上著名的物理學家、數(shù)學家(同時也是理工科同學的夢魘,多少次因為寫錯了計量單位被扣分): 特斯拉、費米、開普勒、麥克斯韋、帕斯卡、伏打、圖靈、安培。 (那么接下來是? ) 限于篇幅,我們不再深入探討每種架構細節(jié),直接跳躍到最新 Ampere 架構,看看世界頂級計算能力是如何煉成的。對歷史感興趣的讀者可以繼續(xù)研讀擴展材料【6】。 ? ?? 3、Ampere 架構詳解 從 Ampere 白皮書【1】看到 GA100 的總體架構圖如下: 總體布局比較中正,八個 GPC 與 L2 Cache 坐落于核心地段,左右為外部存儲接口,12 道顯存控制器負責與 6 塊 HBM2 存儲器數(shù)據(jù)交互,頂部為 PCIe 4.0 控制器負責與主機通信,底部又有 12 條高速 NVLink 通道與其他 GPU 連為一體。 GA100 以及基于 GA100 GPU 實現(xiàn)的 A100 Tensor Core GPU 內部資源如下表所示: GPC —— 圖形處理簇,Graphics Processing Clusters TPC —— 紋理處理簇,Texture Processing Clusters SM —— 流多處理器,Stream Multiprocessors HBM2 —— 高帶寬存儲器二代,High Bandwidth Memory Gen 2 實際上到手的 A100 GPU 是閹割版,相比完整版 GA100 少了一組 GPC 和一組 HBM2。至于為什么,要考慮這個芯片巨大的面積和工藝水平,以及整板功耗。由于少了這一組 GPC,導致后面一些奇奇怪怪的數(shù)字出現(xiàn),等到了合適的時機再解釋。 GA100 的 SM 架構相比 G80 復雜了很多,占地面積也更大。每個 SM 包括 4 個區(qū)塊,每個區(qū)塊有獨立的 L0 指令緩存、Warp 調度器、分發(fā)單元,以及 16384 個 32 位寄存器,這使得每個 SM 可以并行執(zhí)行 4 組不同指令序列。4 個區(qū)塊共享 L1 指令緩存和數(shù)據(jù)緩存、shared memory、紋理單元。 圖中能看出 INT32 計算單元數(shù)量與 FP32 一致,而 FP64 計算單元數(shù)量是 FP32 的一半,這在后面峰值計算能力中會有體現(xiàn)。 每個 SM 除了 INT32、FP32、FP64 計算單元之外,還有額外 4 個身寬體胖的 Tensor Core,這是加速 Deep Learning 計算的重磅武器,已發(fā)展到第三代,每個時鐘周期可做 1024 次 FP16 乘加運算,與 Volta 和 Turing 相比,每個 SM 的吞吐翻倍,支持的數(shù)據(jù)類型也更為豐富,包括 FP64、TF32、FP16、BF16、INT8、INT4、INT1(另外還有 BF16),不同類型指令吞吐見下表【2】所示: Volta/Turing/Ampere 單個 SM 不同數(shù)值類型指令吞吐 利用這張表我們可以計算出 GPU 峰值計算能力,公式如下: 其中? 例如 A100 FP32 CUDA Core 指令吞吐? 對照 NVIDIA Ampere 白皮書【1】 中有關 FP32 峰值計算能力的數(shù)字 19.5 TFLOPS,基本一致。 將剩下的指令吞吐數(shù)字代入公式中,可以得到 A100 其他數(shù)據(jù)類型的峰值計算能力,包括令人震驚的 TF32 和令人迷惑的 FP16 性能。 理論峰值計算能力只是一個上限,我們還關心 GPU 計算能力實測值,可以利用如下公式: 其中? 其中 A、B、C、D 均為矩陣,各自尺寸以下標作為標識。完成上述公式計算所需總乘加次數(shù)為: 從前面兩張圖看到 Volta/Turing 架構 CUDA Core FP16 計算吞吐為 FP32 的 2 倍,而到了 Ampere 架構發(fā)生了階躍,直接變 4 倍(256 vs 64,78 TFLOPS vs 19.5 TFLOPS),我們拿到物理卡后第一時間進行了不同精度 GEMM 評測,發(fā)現(xiàn) FP16 性能相比 FP32 并非 4 倍,而是和 Turing 一樣 2 倍左右,感覺更像是文檔出現(xiàn)了謬誤。 ? ?? 4、不同型號 GPU 峰值計算能力對比 我們可以通過翻閱 GPU 數(shù)據(jù)手冊、白皮書獲得不同型號 GPU 峰值計算能力,但這僅停留在紙面,對于管控系統(tǒng)而言需要借助工具來獲取這些數(shù)值記錄在設備數(shù)據(jù)庫,之后調度器可根據(jù)計算需求以及庫存情況進行計算能力分配。本節(jié)將提供這樣一個工具來自動計算 GPU 峰值計算能力,基于 CUDA Runtime API 編寫,對具體 CUDA 版本沒有特殊要求。A100 上運行輸出如下: 由此得到的 A100 理論峰值計算能力與上節(jié) CUTLASS 實測結果能對號入座。 利用該工具,你可以更深入了解自己手頭 GPU 的計算能力上限,買新卡時會做出更理性判斷。下面展示 2016-2020 主流 GPU 型號及其理論峰值計算力: Tesla P4 峰值計算能力, P4 實際可以超頻到 1.531 GHz,官方并未對超頻性能做出承諾,用戶需根據(jù)業(yè)務特點進行合理設置 Tesla P100(PCIe 版) 峰值計算能力, NVLink 版比這個結果要高一點 Tesla V100 峰值計算能力,忽略最后一行(系早期工具 bug) Tesla T4 峰值計算能力, 實測 T4 正常工作頻率約為峰值的 70% RTX 2080 Ti, 2018, Turing Jetson Nano, 2019, Maxwell Jetson Xavier, 2018, Volta 如果上面結果中沒有發(fā)現(xiàn)你的 GPU 裝備,歡迎運行下面代碼并將結果發(fā)在評論區(qū)。 ? ?? 5、本文代碼 #include nvcc -I/usr/local/cuda/include -L/usr/local/cuda/lib64 -lcudart -o calc_peak_gflops calc_peak_gflops.cpp 如果提示 nvcc 命令未找到,請先安裝 CUDA 并設置 PATH 環(huán)境變量包含 nvcc 所在目錄(Linux 默認為 /usr/local/cuda/bin)。 export PATH=/usr/local/cuda/bin:$PATH ? ??6、后記 通過獲取 GPU 峰值計算能力,可以加深對手頭的硬件資源了解程度,不被過度宣傳的文章洗腦,多快好省地完成工作。 [1] https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdfwww.nvidia.com [2] GPU Performance Background User Guidedocs.nvidia.com [3] https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper.pdfwww.nvidia.com [4] https://images.nvidia.com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdfimages.nvidia.com [5] https://images.nvidia.com/content/volta-architecture/pdf/volta-architecture-whitepaper.pdfimages.nvidia.com 推薦閱讀:



 GeForce 256, 1999
GeForce 256, 1999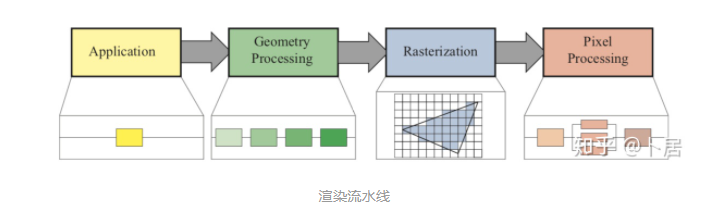
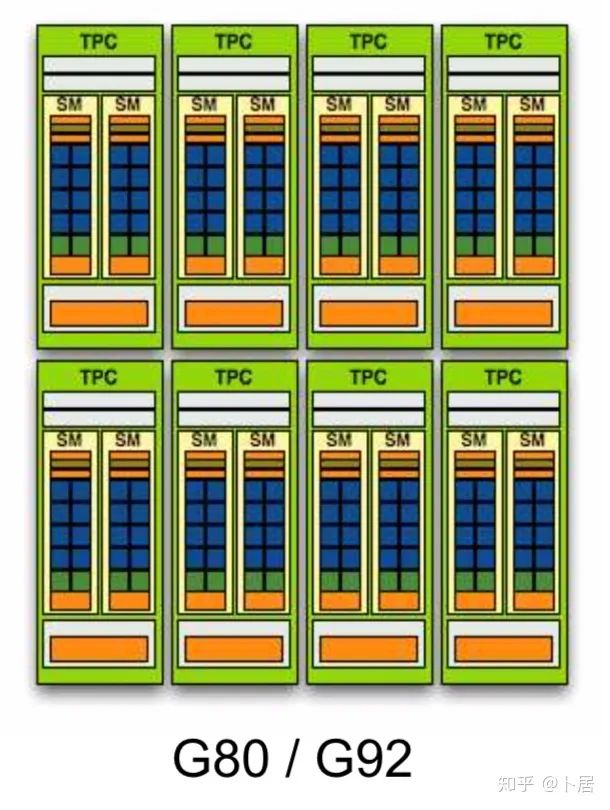 G80/G92 架構圖,G92 相比 G80 僅為工藝升級(90nm -> 65nm),架構沒有變化
G80/G92 架構圖,G92 相比 G80 僅為工藝升級(90nm -> 65nm),架構沒有變化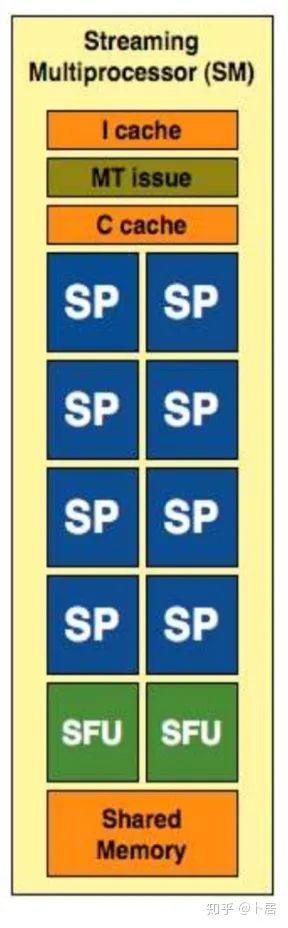 G80/G92 架構圖
G80/G92 架構圖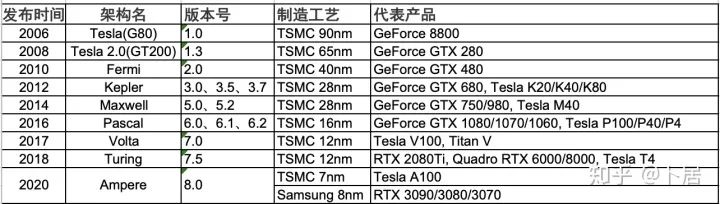
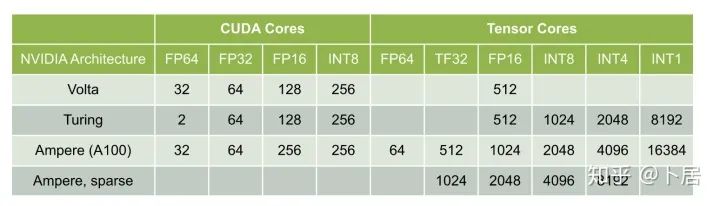 Volta/Turing/Ampere 單個 SM 不同數(shù)值類型指令吞吐
Volta/Turing/Ampere 單個 SM 不同數(shù)值類型指令吞吐