
1000元的Python副業(yè)單子,爬取下載美國(guó)科研網(wǎng)站數(shù)據(jù)
任務(wù)簡(jiǎn)介
目標(biāo)網(wǎng)站:https://app.powerbigov.us/view?r=eyJrIjoiYWEx... 目標(biāo)數(shù)據(jù):下載2009-2013年的表格數(shù)據(jù),并存儲(chǔ)為CSV文件  ??目標(biāo)網(wǎng)站是漂亮國(guó)的科研數(shù)據(jù),是PowerBI實(shí)現(xiàn)的網(wǎng)頁(yè)數(shù)據(jù),無(wú)法使用Ctrl+C復(fù)制內(nèi)容,因此,求助于我們進(jìn)行爬取。
??目標(biāo)網(wǎng)站是漂亮國(guó)的科研數(shù)據(jù),是PowerBI實(shí)現(xiàn)的網(wǎng)頁(yè)數(shù)據(jù),無(wú)法使用Ctrl+C復(fù)制內(nèi)容,因此,求助于我們進(jìn)行爬取。
任務(wù)解決思路與經(jīng)驗(yàn)收獲
??首先任務(wù)可拆解為兩個(gè)部分:一是從網(wǎng)站爬取數(shù)據(jù)到本地,二是解析數(shù)據(jù)輸出CSV文件:
爬取數(shù)據(jù)部分:
解析網(wǎng)頁(yè),找到數(shù)據(jù)異步加載的實(shí)際請(qǐng)求地址與參數(shù) 書寫爬蟲代碼獲取全部數(shù)據(jù) 解析數(shù)據(jù)部分
??這是本次任務(wù)的主要難點(diǎn)所在,難點(diǎn)在于:在返回的數(shù)據(jù)list中,元素不是固定的個(gè)數(shù),只有與上一行不同的數(shù)值,而具體哪一列不同、哪一列相同,是使用一個(gè)“R”值表示,正常解決思路是要通過(guò)JS逆向,找出解析R關(guān)系的函數(shù),完成解析。但是,由于網(wǎng)頁(yè)的JS非常復(fù)雜,且許多函數(shù)名都是簡(jiǎn)寫,閱讀十分困難,一直沒(méi)有逆向成功

??在解決該問(wèn)題上,先是手工查詢總結(jié)關(guān)系,完成了第一個(gè)版本,沒(méi)想到后續(xù)在寫寫這篇分享文章時(shí)突然思路打開,改變了請(qǐng)求數(shù)據(jù)方式,繞過(guò)了分析R關(guān)系的步驟:
方案一:按正常請(qǐng)求,使用R關(guān)系解析數(shù)據(jù)
??下載完整的數(shù)據(jù)后分析,所需要的2009至2013年的數(shù)據(jù)中,R關(guān)系一共有124種,最小值0、最大值4083,通過(guò)人工查詢這124種關(guān)系,制作成字典,完成解析。總結(jié)出的關(guān)系如下圖(手工查詢了5個(gè)小時(shí),累啊):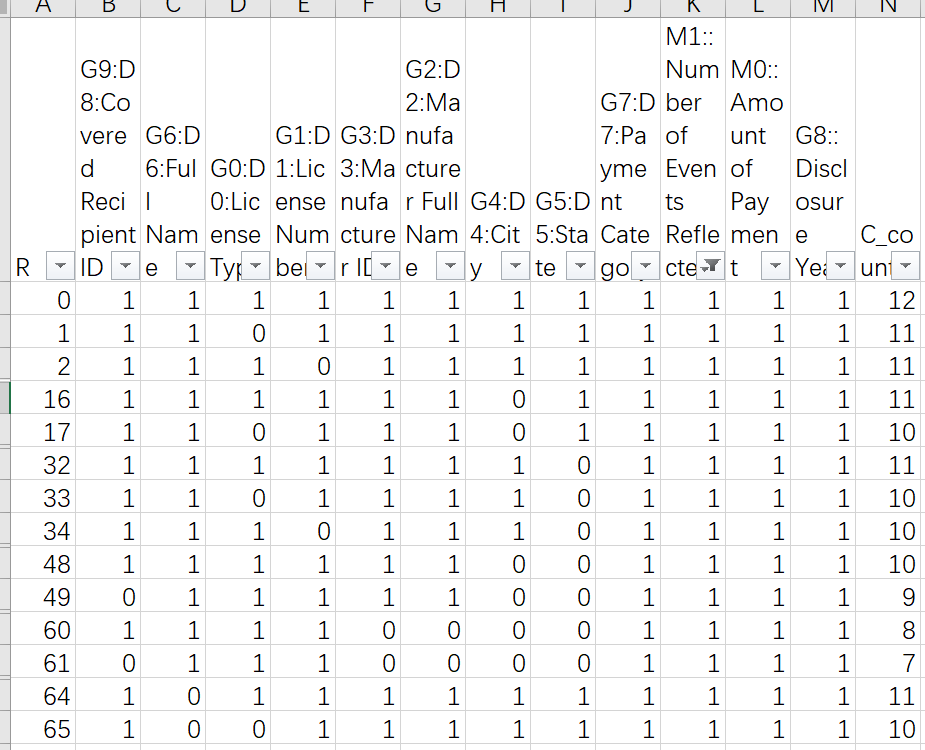
方案二:以時(shí)間換空間,每次僅請(qǐng)求一行數(shù)據(jù),繞過(guò)解析R關(guān)系的難題
??在復(fù)盤時(shí),突然頭腦開竅,請(qǐng)求到的數(shù)據(jù)第一行一定是完整的,要是每次只請(qǐng)求一行數(shù)據(jù),那就不可能存在與上一行相同的情形了,這種情況下就能繞過(guò)解析R關(guān)系這一難題。測(cè)試后方案可行,只是需要考慮以下問(wèn)題:開啟多線程加速以縮時(shí)間,但即使開啟多線程,也只能按12個(gè)年份開啟12個(gè)線程,而行數(shù)最多的年份約2萬(wàn)行,爬蟲需要運(yùn)行約5至6個(gè)小時(shí) 斷點(diǎn)續(xù)爬,避免程序異常中斷后,需要從頭開始;
具體步驟
目標(biāo)網(wǎng)站分析
??第一步當(dāng)然是對(duì)目標(biāo)網(wǎng)站進(jìn)行分析,找到數(shù)據(jù)正確的請(qǐng)求地址,這點(diǎn)很容易,打開Chrome的開發(fā)者模式,向下拖動(dòng)滾動(dòng)條,看到新出現(xiàn)的請(qǐng)求,就是真實(shí)的地址了,直接上結(jié)果: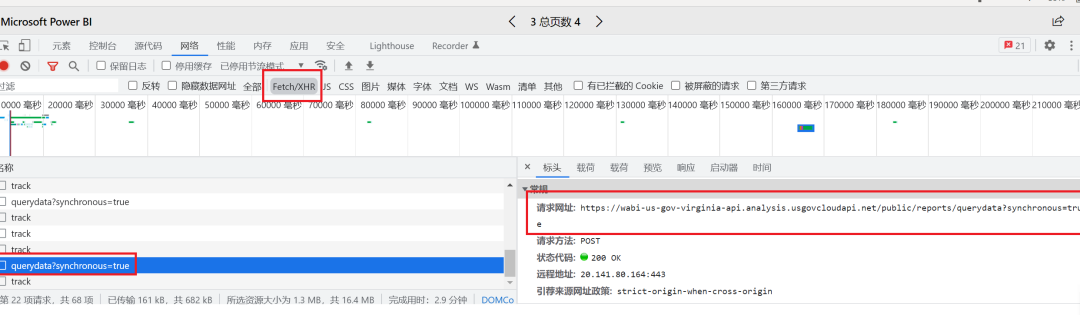
然后看一下POST請(qǐng)求的參數(shù)

再看一下Headers,意外發(fā)現(xiàn),竟然沒(méi)有反爬!沒(méi)有反爬!沒(méi)有反爬!好吧,漂亮國(guó)的網(wǎng)站就是大氣。
分析小結(jié): #?完整參數(shù)就略過(guò),關(guān)鍵參數(shù)以下三項(xiàng):
# 1.篩選年份的參數(shù),示例:
param['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Query']['Where'][0]['Condition']['In']['Values'][0][0]['Literal']['Value']?=?'2009L'
# 2.請(qǐng)求下一批數(shù)據(jù)(請(qǐng)求首批數(shù)據(jù)時(shí)無(wú)需傳入該參數(shù)),示例:
param['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction']['Primary']['Window']['RestartTokens']?=?[["'Augusto?E?Caballero-Robles'","'Physician'","'159984'","'Daiichi?Sankyo,?Inc.'","'CC0131'","'Basking?Ridge'","'NJ'","'Compensation?for?Bona?Fide?Services'","2009L","'4753'"]]
#?注:以上"RestartTokens"的值在前一批數(shù)據(jù)的response中,為上一批數(shù)據(jù)的返回字典值,示例res['results'][0]['result']['data']['dsr']['DS'][0]['RT']
# 3.請(qǐng)求頁(yè)面的行數(shù)(瀏覽器訪問(wèn)默認(rèn)是500行/頁(yè),但爬蟲訪問(wèn)的話...你懂的),示例:
param['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction']['Primary']['Window']['Count']?=?500
#?參數(shù)還有很多,例如排序的參數(shù)ordby,各種篩選項(xiàng)等請(qǐng)求數(shù)據(jù)的網(wǎng)址: https://wabi-us-gov-virginia-api.analysis.usgovcloudapi.net/public/reports/querydata?synchronous=truePOST的關(guān)鍵參數(shù):
爬蟲主要步驟及代碼
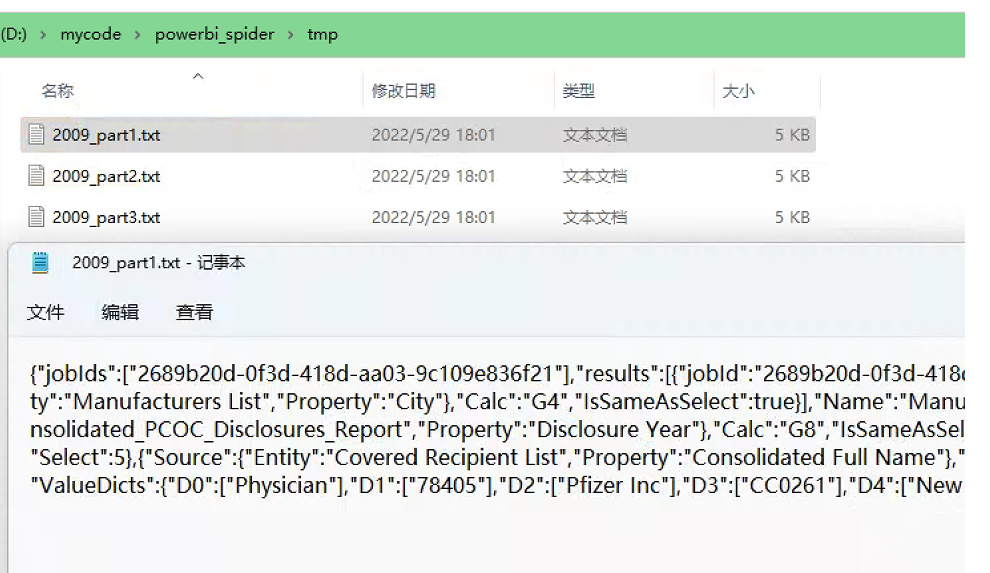
在獲取全部數(shù)據(jù)上,則使用一個(gè)while True死循環(huán),每次請(qǐng)求返回值中如有"RT"關(guān)鍵字,則修改POST參數(shù),發(fā)起下一個(gè)請(qǐng)求,直至返回值中沒(méi)有"RT"關(guān)鍵字,代表全部數(shù)據(jù)爬取結(jié)束(詳見代碼)
請(qǐng)求過(guò)程中出現(xiàn)的異常需要捕獲,根據(jù)異常類型決定下一步操作,由于該網(wǎng)站沒(méi)有反爬,只有超時(shí)或連接錯(cuò)誤的異常,因此,只需要重啟發(fā)起請(qǐng)求即可,因此可以不考慮斷點(diǎn)續(xù)爬
以上步驟,詳細(xì)代碼如下:
網(wǎng)站沒(méi)有反爬,找到正確的路徑和參數(shù)后,在爬蟲代碼實(shí)現(xiàn)上相對(duì)簡(jiǎn)單,直接發(fā)起post請(qǐng)求即可,代碼中通過(guò)PageSpider類實(shí)現(xiàn)(詳細(xì)代碼附后)
在斷點(diǎn)續(xù)傳上,通過(guò)流程解決,把每行數(shù)據(jù)存儲(chǔ)到TXT文件中,文件名記錄年份以及行數(shù),先讀取已爬取的記錄,找到最后一次請(qǐng)求結(jié)果,然后發(fā)起后續(xù)請(qǐng)求。
#?-*-?coding:?utf-8?-*-
#?@author:?Lin?Wei
#?@contact:[email protected]
#?@time:?2022/5/27?12:38
"""
爬取頁(yè)面數(shù)據(jù)的爬蟲
"""
import?pathlib?as?pl
import?requests
import?json
import?time
import?threading
import?urllib3
def?get_cost_time(start:?time.time,?end:?time.time?=?None):
??"""
??計(jì)算間隔時(shí)長(zhǎng)的方法
??:param?start:?起始時(shí)間
??:param?end:?結(jié)束時(shí)間,默認(rèn)為空,按最新時(shí)間計(jì)算
??:return:?時(shí)分秒格式
??"""
??if?not?end:
??????end?=?time.time()
??cost?=?end?-?start
??days?=?int(cost?/?86400)
??hours?=?int(cost?%?86400?/?3600)
??mins?=?int(cost?%?3600?/?60)
??secs?=?round(cost?%?60,?4)
??text?=?''
??if?days:
??????text?=?f'{text}{days}天'
??if?hours:
??????text?=?f'{text}{hours}小時(shí)'
??if?mins:
??????text?=?f'{text}{mins}分鐘'
??if?secs:
??????text?=?f'{text}{secs}秒'
??return?text
class?PageSpider:
??def?__init__(self,?year:?int,?nrows:?int?=?500,?timeout:?int?=?30):
??????"""
??????初始化爬蟲的參數(shù)
??????:param?year:?下載數(shù)據(jù)的年份,默認(rèn)空,不篩選年份,取得全量數(shù)據(jù)
??????:param?nrows:?每次請(qǐng)求獲取的數(shù)據(jù)行數(shù),默認(rèn)500,最大30000(服務(wù)器自動(dòng)限制,超過(guò)無(wú)效)
??????:param?timeout:?超時(shí)等待時(shí)長(zhǎng)
??????"""
??????self.year?=?year?if?year?else?'all'
??????self.timeout?=?timeout
??????#?請(qǐng)求數(shù)據(jù)的地址
??????self.url?=?'https://wabi-us-gov-virginia-api.analysis.usgovcloudapi.net/public/reports/querydata?synchronous=true'
??????#?請(qǐng)求頭
??????self.headers?=?{
??????????#?太長(zhǎng)省略,自行在瀏覽器中復(fù)制
??????}
??????#?默認(rèn)參數(shù)
??????self.params?=?{
??????????#?太長(zhǎng)省略,自行在瀏覽器中復(fù)制
??????}
??????#?修改默認(rèn)參數(shù)中的每次請(qǐng)求的行數(shù)
??????self.params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction'][
??????????'Primary']['Window']['Count']?=?nrows
??????#?修改默認(rèn)參數(shù)中請(qǐng)求的年份
??????if?self.year?!=?'all':
??????????self.params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Query']['Where'][0][
??????????????'Condition']['In']['Values'][0][0]['Literal']['Value']?=?f'{year}L'
??@classmethod
??def?read_json(cls,?file_path:?pl.Path):
??????with?open(file_path,?'r',?encoding='utf-8')?as?fin:
??????????res?=?json.loads(fin.read())
??????return?res
??def?get_idx_and_rt(self):
??????"""
??????獲取已經(jīng)爬取過(guò)的信息,最大的idx以及請(qǐng)求下一頁(yè)的參數(shù)
??????"""
??????single?=?True
??????tmp_path?=?pl.Path('./tmp/')
??????if?not?tmp_path.is_dir():
??????????tmp_path.mkdir()
??????files?=?list(tmp_path.glob(f'{self.year}_part*.txt'))
??????if?files:
??????????idx?=?max([int(filename.stem.replace(f'{self.year}_part',?''))?for?filename?in?files])
??????????res?=?self.read_json(tmp_path?/?f'{self.year}_part{idx}.txt')
??????????key?=?res['results'][0]['result']['data']['dsr']['DS'][0].get('RT')
??????????if?not?key:
??????????????single?=?False
??????else:
??????????idx?=?0
??????????key?=?None
??????return?idx,?key,?single
??def?make_params(self,?key:?list?=?None)?->?dict:
??????"""
??????制作請(qǐng)求體中的參數(shù)
??????:param?key:?下一頁(yè)的關(guān)鍵字RestartTokens,默認(rèn)空,第一次請(qǐng)求時(shí)無(wú)需傳入該參數(shù)
??????:return:?dict
??????"""
??????params?=?self.params.copy()
??????if?key:
??????????params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction'][
??????????????'Primary']['Window']['RestartTokens']?=?key
??????return?params
??def?crawl_pages(self,?idx:?int?=?1,?key:?list?=?None):
??????"""
??????爬取頁(yè)面并輸出TXT文件的方法,
??????:param?idx:?爬取的索引值,默認(rèn)為1,在每行爬取時(shí),代表行數(shù)
??????:param?key:?下一頁(yè)的關(guān)鍵字RestartTokens,默認(rèn)空,第一次請(qǐng)求時(shí)無(wú)需傳入該參數(shù)
??????:return:?None
??????"""
??????start?=?time.time()
??????while?True:??#?創(chuàng)建死循環(huán)爬取直至結(jié)束
??????????try:
??????????????res?=?requests.post(url=self.url,?headers=self.headers,?json=self.make_params(key),
??????????????????????????????????timeout=self.timeout)
??????????except?(
??????????????????requests.exceptions.ConnectTimeout,
??????????????????requests.exceptions.ConnectionError,
??????????????????urllib3.exceptions.ConnectionError,
??????????????????urllib3.exceptions.ConnectTimeoutError
??????????):??#?捕獲超時(shí)異常?或?連接異常
??????????????print(f'{self.year}_part{idx}:?timeout,?wait?5?seconds?retry')
??????????????time.sleep(5)??#?休息5秒后再次請(qǐng)求
??????????????continue??#?跳過(guò)后續(xù)步驟
??????????except?Exception?as?e:??#?其他異常,打印一下異常信息
??????????????print(f'{self.year}_part{idx}?Error:?{e}')
??????????????time.sleep(5)??#?休息5秒后再次請(qǐng)求
??????????????continue??#?跳過(guò)后續(xù)步驟
??????????if?res.status_code?==?200:
??????????????with?open(f'./tmp/{self.year}_part{idx}.txt',?'w',?encoding='utf-8')?as?fout:
??????????????????fout.write(res.text)
??????????????if?idx?%?100?==?0:
??????????????????print(f'{self.year}的第{idx}行數(shù)據(jù)寫入完成,已用時(shí):?{get_cost_time(start)}')
??????????????key?=?json.loads(res.text)['results'][0]['result']['data']['dsr']['DS'][0].get('RT',?None)
??????????????if?not?key:??#?如果沒(méi)有RT值,說(shuō)明已經(jīng)全部爬取完畢了,打印一下信息退出
??????????????????print(f'{self.year}?completed?max_idx?is?{idx}')
??????????????????return
??????????????idx?+=?1
??????????else:??#?打印一下信息重新請(qǐng)求
??????????????print(f'{self.year}_part{idx}?not?200,check?please',?res.text)
??????????????continue
def?mul_crawl(year:?int,?nrows:?int?=?2):
??"""
??多線程爬取的方法,注按行爬取
??:param?year:?需要爬取的年份
??:param?nrows:?每份爬取的行數(shù),若每次僅爬取1行數(shù)據(jù),nrows參數(shù)需要為2,才會(huì)有下一行,否則都是第一行
??"""
??#?定義爬蟲對(duì)象
??spider?=?PageSpider(year,?nrows=nrows)
??#?獲取爬取對(duì)象已爬取的idx,key和是否完成爬取的信號(hào)single
??idx,?key,?single?=?spider.get_idx_and_rt()
??if?not?single:
??????print(f'{year}年的共{idx}行數(shù)據(jù)已經(jīng)全部下載,無(wú)需爬取')
??????return
??print(f'{year}年的爬蟲任務(wù)啟動(dòng),?從{idx+1}行開始爬取')
??spider.crawl_pages(idx+1,?key)??#?特別注意,已經(jīng)爬取了idx行,重啟時(shí),下一行需要+1,否則重啟后,會(huì)覆蓋一行數(shù)據(jù)
if?__name__?==?'__main__':
??pools?=?[]
??for?y?in?range(2009,?2021):
??????pool?=?threading.Thread(
??????????target=mul_crawl,?args=(y,?2),?name=f'{y}_thread'??#?按行爬取,nrows參數(shù)需要為2
??????)
??????pool.start()
??????pools.append(pool)
??for?pool?in?pools:
??????pool.join()
??print('任務(wù)全部完成')
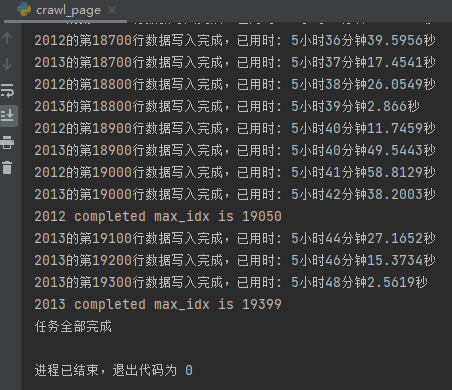
代碼運(yùn)行示例:
解析數(shù)據(jù)
方案一
??解析數(shù)據(jù)困難的部分就是找出R關(guān)系規(guī)律,這部分是使用手工查詢來(lái)解決的,直接上代碼吧:
class?ParseData:
????"""
????解析數(shù)據(jù)的對(duì)象
????"""
????def?__init__(self,?file_path:?pl.Path?=?None):
????????"""
????????初始化對(duì)象
????????:param?file_path:?TXT數(shù)據(jù)存放的路徑,默認(rèn)自身目錄下的tmp文件夾
????????"""
????????self.file_path?=?pl.Path('./tmp')?if?not?file_path?else?file_path
????????self.files?=?list(self.file_path.glob('2*.txt'))
????????self.cols_dict?=?None
????????self.colname_dict?=?{
????????????'D0':?'License?Type',
????????????'D1':?'License?Number',
????????????'D2':?'Manufacturer?Full?Name',
????????????'D3':?'Manufacturer?ID',
????????????'D4':?'City',
????????????'D5':?'State',
????????????'D6':?'Full?Name',
????????????'D7':?'Payment?Category',
????????????'D8':?'Covered?Recipient?ID'
????????}
????????self.colname_dict_T?=?{v:?k?for?k,?v?in?self.colname_dict.items()}
????def?make_excels(self):
????????"""
????????將每個(gè)數(shù)據(jù)文件單獨(dú)轉(zhuǎn)換為excel數(shù)據(jù)表用于分析每份數(shù)據(jù)
????????:return:
????????"""
????????for?file?in?self.files:
????????????with?open(file,?'r')?as?fin:
????????????????res?=?json.loads(fin.read())
????????????dfx?=?pd.DataFrame(res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'])
????????????dfx['filename']?=?file.stem
????????????dfx[['year',?'part']]?=?dfx['filename'].str.split('_',?expand=True)
????????????dfx['C_count']?=?dfx['C'].map(len)
????????????writer?=?pd.ExcelWriter(self.file_path?/?f'{file.stem}.xlsx')
????????????dfx.to_excel(writer,?sheet_name='data')
????????????for?k,?v?in?res['results'][0]['result']['data']['dsr']['DS'][0]['ValueDicts'].items():
????????????????dfx?=?pd.Series(v).to_frame()
????????????????dfx.to_excel(writer,?sheet_name=k)
????????????writer.save()
????????print('所有數(shù)據(jù)均已轉(zhuǎn)為Excel')
????def?make_single_excel(self):
????????"""
????????將所有數(shù)據(jù)生成一份excel文件,不包含字典
????????:return:
????????"""
????????#?合并成整個(gè)文件
????????df?=?pd.DataFrame()
????????for?file?in?self.files:
????????????with?open(file,?'r')?as?fin:
????????????????res?=?json.loads(fin.read())
????????????dfx?=?pd.DataFrame(res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'])
????????????dfx['filename']?=?file.stem
????????????dfx[['year',?'part']]?=?dfx['filename'].str.split('_',?expand=True)
????????????dfx['C_count']?=?dfx['C'].map(len)
????????????df?=?pd.concat([df,?dfx])
????????return?df
????def?get_cols_dict(self):
????????"""
????????讀取列關(guān)系的字典
????????:return:
????????"""
????????#?讀取列字典表
????????self.cols_dict?=?pd.read_excel(self.file_path.parent?/?'cols_dict.xlsx')
????????self.cols_dict.set_index('R',?inplace=True)
????????self.cols_dict?=?self.cols_dict.dropna()
????????self.cols_dict.drop(columns=['C_count',?],?inplace=True)
????????self.cols_dict.columns?=?[col.split(':')[-1]?for?col?in?self.cols_dict.columns]
????????self.cols_dict?=?self.cols_dict.astype('int')
????def?make_dataframe(self,?filename):
????????"""
????????讀取TXT文件,轉(zhuǎn)換成dataframe
????????:param?filename:?需要轉(zhuǎn)換的文件
????????:return:?
????????"""
????????with?open(filename,?'r')?as?fin:
????????????res?=?json.loads(fin.read())
????????df0?=?pd.DataFrame(res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'])
????????df0['R']?=?df0['R'].fillna(0)
????????df0['R']?=?df0['R'].map(int)
????????values_dict?=?res['results'][0]['result']['data']['dsr']['DS'][0]['ValueDicts']
????????dfx?=?[]
????????for?idx?in?df0.index:
????????????row_value?=?df0.loc[idx,?'C'].copy()
????????????cols?=?self.cols_dict.loc[int(df0.loc[idx,?'R'])].to_dict()
????????????row?=?{}
????????????for?col?in?['License?Type',?'License?Number',?'Manufacturer?Full?Name',?'Manufacturer?ID',?'City',?'State',
????????????????????????'Full?Name',?'Payment?Category',?'Disclosure?Year',?'Covered?Recipient?ID',?'Amount?of?Payment',
????????????????????????'Number?of?Events?Reflected']:
????????????????v?=?cols.get(col)
????????????????if?v:
????????????????????value?=?row_value.pop(0)
????????????????????if?col?in?self.colname_dict.values():
????????????????????????if?not?isinstance(value,?str):
????????????????????????????value_list?=?values_dict.get(self.colname_dict_T.get(col),?[])
????????????????????????????value?=?value_list[value]
????????????????????row[col]?=?value
????????????????else:
????????????????????row[col]?=?None
????????????row['R']?=?int(df0.loc[idx,?'R'])
????????????dfx.append(row)
????????dfx?=?pd.DataFrame(dfx)
????????dfx?=?dfx.fillna(method='ffill')
????????dfx[['Disclosure?Year',?'Number?of?Events?Reflected']]?=?dfx[
????????????['Disclosure?Year',?'Number?of?Events?Reflected']].astype('int')
????????dfx?=?dfx[['Covered?Recipient?ID',?'Full?Name',?'License?Type',?'License?Number',?'Manufacturer?ID',
???????????????????'Manufacturer?Full?Name',?'City',
???????????????????'State',?'Payment?Category',?'Amount?of?Payment',?'Number?of?Events?Reflected',?'Disclosure?Year',
???????????????????'R']]
????????return?dfx
????def?parse_data(self,?out_name:?str?=?None):
????????"""
????????解析合并數(shù)據(jù)
????????:param?out_name:?輸出的文件名
????????:return:?
????????"""
????????df?=?pd.DataFrame()
????????for?n,?f?in?enumerate(self.files):
????????????dfx?=?self.make_dataframe(f)
????????????df?=?pd.concat([df,?dfx])
????????????print(f'完成第{n?+?1}個(gè)文件,剩余{len(self.files)?-?n?-?1}個(gè),共{len(self.files)}個(gè)')
????????df.drop(columns='R').to_csv(self.file_path?/?f'{out_name}.csv',?index=False)
????????return?df
方案二
??使用方案二處理數(shù)據(jù)時(shí),在進(jìn)行數(shù)據(jù)后驗(yàn)后發(fā)現(xiàn),還有兩個(gè)細(xì)節(jié)問(wèn)題需要解決:
??一是返回值中出現(xiàn)了新的關(guān)鍵字“?”,經(jīng)手工驗(yàn)證才知道代表輸出的行中,存在本身就是空值的情況,遍歷數(shù)據(jù)后,發(fā)現(xiàn)只有出現(xiàn)3個(gè)不同值(60, 128, 2048),因此,手工制作了col_dict(詳見代碼)。\
class?ParseDatav2:
????"""
????解析數(shù)據(jù)的對(duì)象第二版,將按行爬取的的json文件,轉(zhuǎn)換成dataframe,增量寫入csv文件,
????因每次請(qǐng)求一行,首行數(shù)據(jù)不存在與上一行相同情形,因此,除個(gè)別本身無(wú)數(shù)據(jù)情況,絕大多數(shù)均為完整的12列數(shù)據(jù),
????"""
????def?__init__(self):
????????"""
????????初始化
????????"""
????????#?初始化一行的dataframe,
????????self.row?=?pd.DataFrame([
????????????'Covered?Recipient?ID',?'Full?Name',?'License?Type',?'License?Number',?'Manufacturer?ID',
????????????'Manufacturer?Full?Name',?'City',?'State',?'Payment?Category',?'Amount?of?Payment',
????????????'Number?of?Events?Reflected',?'Disclosure?Year'
????????]).set_index(0)
????????self.row[0]?=?None
????????self.row?=?self.row.T
????????self.row['idx']?=?None
????????#?根據(jù)???值的不同選擇不同的列,目前僅三種不同的?值,注0為默認(rèn)值,指包含所有列
????????self.col_dict?=?{
????????????#?完整的12列
????????????0:?['License?Type',?'License?Number',?'Manufacturer?Full?Name',?'Manufacturer?ID',?'City',?'State',
????????????????'Full?Name',?'Payment?Category',?'Disclosure?Year',?'Covered?Recipient?ID',?'Amount?of?Payment',
????????????????'Number?of?Events?Reflected'],
????????????#?有4列是空值,分別是?'Manufacturer?Full?Name',?'Manufacturer?ID',?'City',?'State'
????????????60:?['License?Type',?'License?Number',
?????????????????'Full?Name',?'Payment?Category',?'Disclosure?Year',?'Covered?Recipient?ID',?'Amount?of?Payment',
?????????????????'Number?of?Events?Reflected'],
????????????#?有1列是空值,是?'Payment?Category'
????????????128:?['License?Type',?'License?Number',?'Manufacturer?Full?Name',?'Manufacturer?ID',?'City',?'State',
??????????????????'Full?Name',?'Disclosure?Year',?'Covered?Recipient?ID',?'Amount?of?Payment',
??????????????????'Number?of?Events?Reflected'],
????????????#?有1列是空值,是?'Number?of?Events?Reflected'
????????????2048:?['License?Type',?'License?Number',?'Manufacturer?Full?Name',?'Manufacturer?ID',?'City',?'State',
???????????????????'Full?Name',?'Payment?Category',?'Disclosure?Year',?'Covered?Recipient?ID',?'Amount?of?Payment'],
????????}
????????#?列名轉(zhuǎn)換字典
????????self.colname_dict?=?{
????????????'License?Type':?'D0',
????????????'License?Number':?'D1',
????????????'Manufacturer?Full?Name':?'D2',
????????????'Manufacturer?ID':?'D3',
????????????'City':?'D4',
????????????'State':?'D5',
????????????'Full?Name':?'D6',
????????????'Payment?Category':?'D7',
????????????'Covered?Recipient?ID':?'D8'
????????}
????????#?儲(chǔ)存爬取的json文件的路徑
????????self.data_path?=?pl.Path('./tmp')
????????#?獲取json文件的迭代器
????????self.files?=?self.data_path.glob('*.txt')
????????#?初始化輸出文件的名稱及路徑
????????self.file_name?=?self.data_path.parent?/?'data.csv'
????def?create_csv(self):
????????"""
????????先輸出一個(gè)CSV文件頭用于增量寫入數(shù)據(jù)
????????:return:
????????"""
????????self.row.drop(0,?axis=0).to_csv(self.file_name,?index=False)
????def?parse_data(self,?filename:?pl.Path):
????????"""
????????讀取按1行數(shù)據(jù)請(qǐng)求獲取的json文件,一行數(shù)據(jù)
????????:param?filename:?json文件的路徑
????????:return:?None
????????"""
????????row?=?self.row.copy()??#?復(fù)制一行dataframe用于后續(xù)修改
????????res?=?PageSpider.read_json(filename)
????????#?獲取數(shù)據(jù)中的valuedicts
????????valuedicts?=?res['results'][0]['result']['data']['dsr']['DS'][0]['ValueDicts']
????????#?獲取數(shù)據(jù)中每行的數(shù)據(jù)
????????row_values?=?res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'][0]['C']
????????#?獲取數(shù)據(jù)中的'?'值(若有),該值代表輸出的行中,存在空白部分,用于確定數(shù)據(jù)列
????????cols?=?ic(self.col_dict.get(
????????????res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'][0].get('?',?0)
????????))
????????#?遍歷每行數(shù)據(jù),修改row這個(gè)dataframe的值
????????for?col,?value?in?zip(cols,?row_values):
????????????ic(col,?value)
????????????colname?=?self.colname_dict.get(col)??#?colname轉(zhuǎn)換,D0~D8
????????????if?colname:??#?如果非空,則需要轉(zhuǎn)換值
????????????????value?=?valuedicts.get(self.colname_dict.get(col))[0]
????????????#?修改dataframe數(shù)據(jù)
????????????row.loc[0,?col]?=?value
????????#?寫入索引值
????????row['idx']?=?int(filename.stem.split('_')[-1].replace('part',?''))
????????return?row
????def?run(self):
????????"""
????????運(yùn)行寫入程序
????????"""
????????self.create_csv()
????????for?idx,?filename?in?enumerate(self.files):
????????????row?=?self.parse_data(filename)
????????????row.to_csv(self.file_name,?mode='a',?header=None,?index=False)
????????????print(f'第{idx?+?1}個(gè)文件{filename.stem}寫入表格成功')
????????print('全部文件寫入完成')
??二是每行數(shù)據(jù)請(qǐng)求,nrows需要設(shè)置為2,而最后一行數(shù)據(jù)無(wú)法通過(guò)該方式獲取,因此,需要從最后一個(gè)返回的json數(shù)據(jù)中解析出最后一行數(shù)據(jù)(詳見LastRow類)
class?LastRow:
????"""
????獲取并寫入最后一行數(shù)據(jù)的類
????由于每次請(qǐng)求一行數(shù)據(jù)的方式,存在缺陷,無(wú)法獲取到最后一行數(shù)據(jù),
????本方法是對(duì)最后一個(gè)能夠獲取的json(倒數(shù)第二行)進(jìn)行解析,取得最后一行數(shù)據(jù),
????本方法存在缺陷,即默認(rèn)最后一行“Amount?of?Payment”列值一定與倒數(shù)第二行不同,
????目前2009年至2020年共12年的數(shù)據(jù)中,均滿足上述條件,沒(méi)有出錯(cuò)。
????除本方法外,還可以通過(guò)逆轉(zhuǎn)排序請(qǐng)求的方式,獲取最后一行數(shù)據(jù)
????"""
????def?__init__(self):
????????"""
????????初始化
????????"""
????????self.file_path?=?pl.Path('./tmp')??#?存儲(chǔ)爬取json數(shù)據(jù)的路徑
????????self.files_df?=?pd.DataFrame()??#?初始化最后一份請(qǐng)求的dataframe
????????#?列名對(duì)應(yīng)的字典
????????self.colname_dict?=?{
????????????'D0':?'License?Type',
????????????'D1':?'License?Number',
????????????'D2':?'Manufacturer?Full?Name',
????????????'D3':?'Manufacturer?ID',
????????????'D4':?'City',
????????????'D5':?'State',
????????????'D6':?'Full?Name',
????????????'D7':?'Payment?Category',
????????????'year':?'Disclosure?Year',
????????????'D8':?'Covered?Recipient?ID',
????????????'M0':?'Amount?of?Payment',
????????????'M1':?'Number?of?Events?Reflected'
????????}??
????????self.data?=?pd.DataFrame()??#?初始化最后一行數(shù)據(jù)data
????def?get_last_file(self):
????????"""
????????遍歷文件夾,取得最后一份請(qǐng)求的dataframe
????????"""
????????self.files_df?=?pd.DataFrame(list(self.file_path.glob('*.txt')),?columns=['filename'])
????????self.files_df[['year',?'idx']]?=?self.files_df['filename'].map(lambda?x:?x.stem).str.split('_',?expand=True)
????????self.files_df['idx']?=?self.files_df['idx'].str.replace('part',?'')
????????self.files_df['idx']?=?self.files_df['idx'].astype(int)
????????self.files_df.sort_values(by=['year',?'idx'],?inplace=True)
????????self.files_df?=?self.files_df.drop_duplicates('year',?keep='last')
????def?get_last_row(self,?ser:?pd.Series)?->?pd.DataFrame:
????????"""
????????解析文件,獲取最后一行的數(shù)據(jù)
????????:param?ser:?一行文件信息的series
????????"""
????????#?讀取json數(shù)據(jù)
????????res?=?PageSpider.read_json(ser['filename'])
????????#?獲取values_dict
????????values_dict?=?res['results'][0]['result']['data']['dsr']['DS'][0]['ValueDicts']
????????#?獲取文件中的第一行數(shù)據(jù)
????????row_values?=?res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'][0]['C']
????????#?獲取文件中的下一行數(shù)據(jù),因文件是倒數(shù)第二行的數(shù)據(jù),因此下一行即為最后一行
????????next_row_values?=?res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'][1]['C']
????????#?初始化Series
????????row?=?pd.Series()
????????#?解析數(shù)據(jù)填充series
????????for?k,?col?in?self.colname_dict.items():
????????????value?=?row_values.pop(0)
????????????if?k.startswith('D'):??#?如果K值是D開頭
????????????????values?=?values_dict[k]
????????????????if?len(values)?==?2:
????????????????????value?=?next_row_values.pop(0)
????????????????value?=?values[-1]
????????????elif?k?==?'year':
????????????????pass
????????????else:
????????????????if?next_row_values:
???????????????????value?=?next_row_values.pop(0)
????????????row[col]?=?value
????????row['idx']?=?ser['idx']?+?1
????????row?=?row.to_frame().T
????????return?row
????def?run(self):
????????"""
????????運(yùn)行獲取最后一行數(shù)據(jù)的方法
????????"""
????????self.get_last_file()
????????for?i?in?self.files_df.index:
????????????self.data?=?pd.concat([self.data,?self.get_last_row(self.files_df.loc[i])])
????????self.data?=?self.data[[
????????????'Covered?Recipient?ID',?'Full?Name',?'License?Type',?'License?Number',?'Manufacturer?ID',
????????????'Manufacturer?Full?Name',?'City',?'State',?'Payment?Category',?'Amount?of?Payment',
????????????'Number?of?Events?Reflected',?'Disclosure?Year',?'idx'
????????]]
????????filename?=?self.file_path.parent?/?'data.csv'
????????self.data.to_csv(filename,?mode='a',?index=False,?header=None)
????????return?self.data
結(jié)果展示
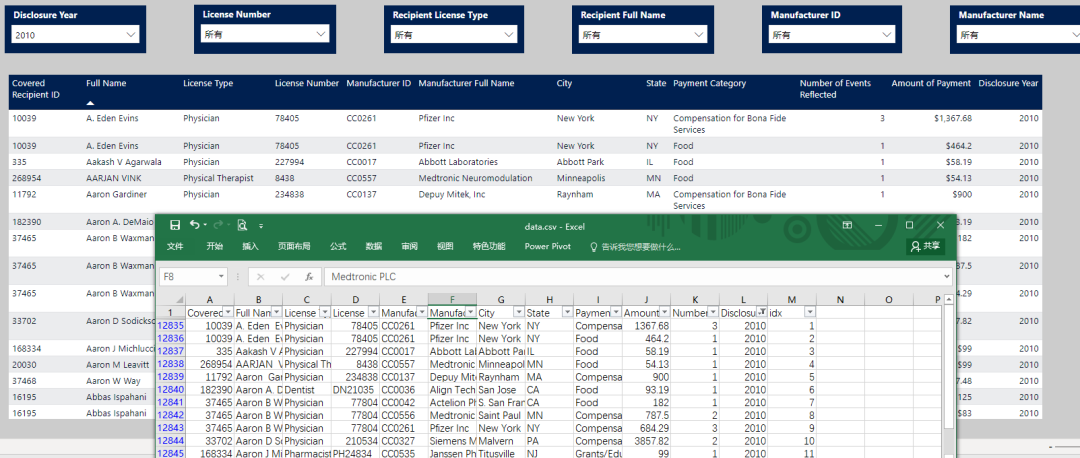
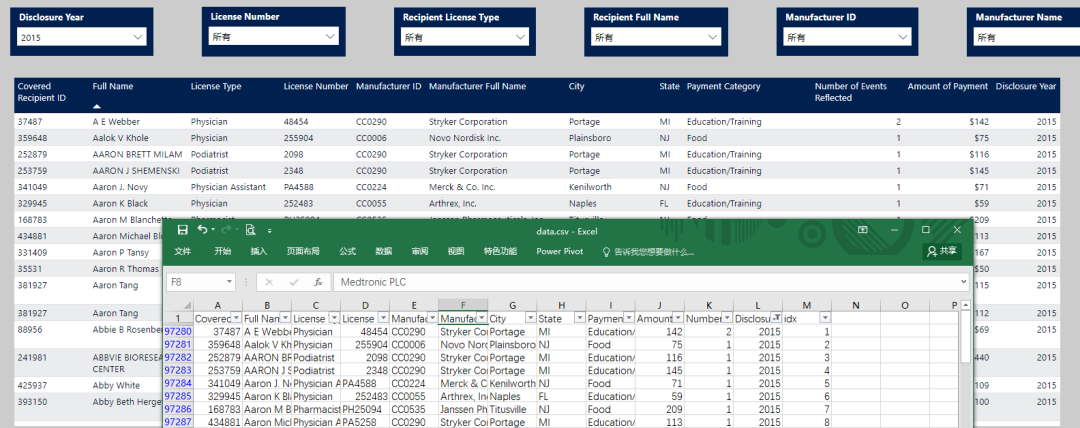
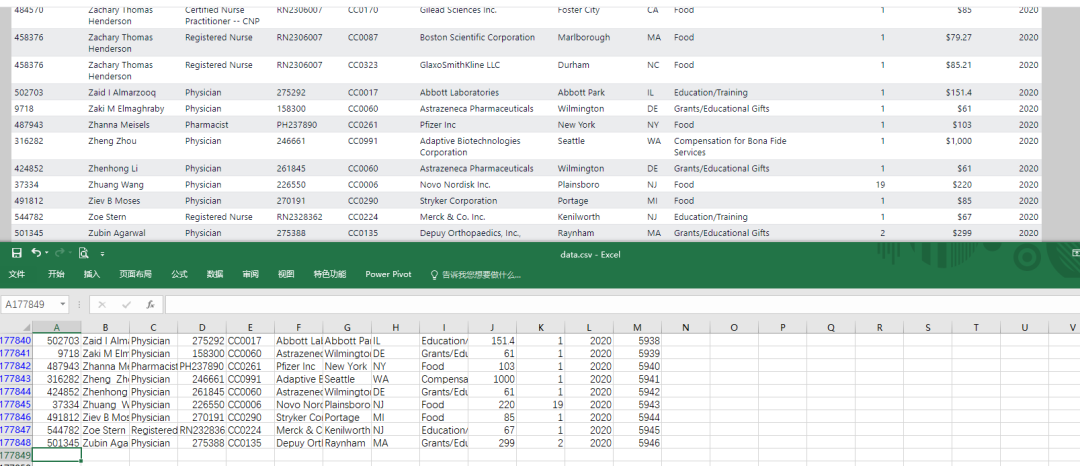
延伸思考
??如果將上述方案一與方案二結(jié)合,整理出所有不同R關(guān)系的行樣例,使用方案二爬取少量的部分示例,然后推導(dǎo)出完整的R關(guān)系字典,再使用方案一的方法進(jìn)行爬取解析,將大大節(jié)約時(shí)間。該方式在數(shù)據(jù)量遠(yuǎn)遠(yuǎn)超過(guò)當(dāng)前數(shù)量時(shí),可以考慮使用。
總結(jié)
??完成整個(gè)項(xiàng)目過(guò)程中歷經(jīng)了:暗爽(不到1小時(shí)就完成了爬蟲部分功能)->迷茫(JS逆向失敗,無(wú)法總結(jié)R關(guān)系規(guī)律)->焦慮與煩躁(擔(dān)心無(wú)法完成任務(wù),手工查詢規(guī)則5個(gè)多小時(shí))->開竅(復(fù)盤過(guò)程中突然發(fā)現(xiàn)新思路)一系列過(guò)程。最終結(jié)果還是較為順利的完成了整個(gè)任務(wù),而最大的感觸還是思路的開拓:一條路走不通時(shí),也許換個(gè)方向就能解決問(wèn)題(注:count參數(shù)500一開始就使用了,只是一直在增加請(qǐng)求的行數(shù),而一直沒(méi)有想到減少請(qǐng)求的行數(shù)這么一個(gè)小小的改變,就能帶來(lái)巨大的突破)。
??最后糾結(jié)一下,要不要系統(tǒng)的去學(xué)習(xí)一下JavaScript,解決無(wú)法JS逆向的問(wèn)題呢?
代碼地址:鏈接: https://pan.baidu.com/s/1l0khgjOgAEhdZNTaOdTP3Q 提取碼: 56hs?--來(lái)自百度網(wǎng)盤超級(jí)會(huì)員v5的分享
掃碼下方,購(gòu)買螞蟻老師課程
提供答疑服務(wù),和副業(yè)渠道
抖音每晚直播間購(gòu)買,便宜100元優(yōu)惠!
