
推薦系統(tǒng)技術演進趨勢:召回篇
煉丹筆記干貨

推薦系統(tǒng)技術,總體而言,與NLP和圖像領域比,發(fā)展速度不算太快。不過最近兩年,由于深度學習等一些新技術的引入,總體還是表現(xiàn)出了一些比較明顯的技術發(fā)展趨勢。這篇文章試圖從推薦系統(tǒng)幾個環(huán)節(jié),以及不同的技術角度,來對目前推薦技術的比較彰顯的技術趨勢做個歸納。個人判斷較多,偏頗難免,所以還請謹慎參考。
在寫技術趨勢前,照例還是對推薦系統(tǒng)的宏觀架構做個簡單說明,以免讀者迷失在技術細節(jié)中。
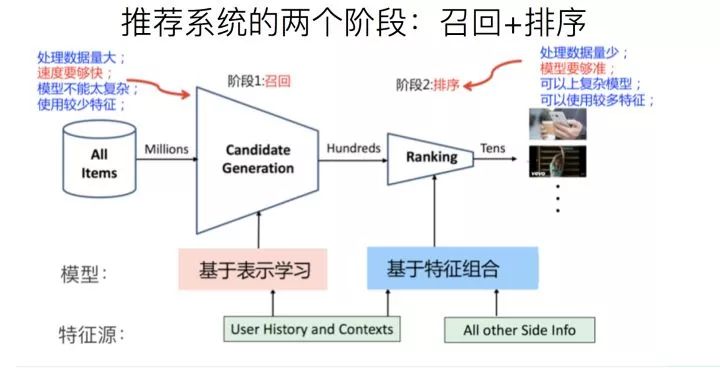 實際的工業(yè)推薦系統(tǒng),如果粗分的化,經(jīng)常講的有兩個階段。首先是召回,主要根據(jù)用戶部分特征,從海量的物品庫里,快速找回一小部分用戶潛在感興趣的物品,然后交給排序環(huán)節(jié),排序環(huán)節(jié)可以融入較多特征,使用復雜模型,來精準地做個性化推薦。召回強調(diào)快,排序強調(diào)準。當然,這是傳統(tǒng)角度看推薦這個事情。
實際的工業(yè)推薦系統(tǒng),如果粗分的化,經(jīng)常講的有兩個階段。首先是召回,主要根據(jù)用戶部分特征,從海量的物品庫里,快速找回一小部分用戶潛在感興趣的物品,然后交給排序環(huán)節(jié),排序環(huán)節(jié)可以融入較多特征,使用復雜模型,來精準地做個性化推薦。召回強調(diào)快,排序強調(diào)準。當然,這是傳統(tǒng)角度看推薦這個事情。但是,如果我們更細致地看實用的推薦系統(tǒng),一般會有四個環(huán)節(jié),如下圖所示:
四個環(huán)節(jié)分別是:召回、粗排、精排和重排。
召回目的如上所述;有時候因為每個用戶召回環(huán)節(jié)返回的物品數(shù)量還是太多,怕排序環(huán)節(jié)速度跟不上,所以可以在召回和精排之間加入一個粗排環(huán)節(jié),通過少量用戶和物品特征,簡單模型,來對召回的結果進行個粗略的排序,在保證一定精準的前提下,進一步減少往后傳送的物品數(shù)量,粗排往往是可選的,可用可不同,跟場景有關。
之后,是精排環(huán)節(jié),使用你能想到的任何特征,可以上你能承受速度極限的復雜模型,盡量精準地對物品進行個性化排序。排序完成后,傳給重排環(huán)節(jié),傳統(tǒng)地看,這里往往會上各種技術及業(yè)務策略,比如去已讀、去重、打散、多樣性保證、固定類型物品插入等等,主要是技術產(chǎn)品策略主導或者為了改進用戶體驗的。
那么,每個環(huán)節(jié),從技術發(fā)展的角度看,都各自有怎樣的發(fā)展趨勢呢?下面我們分頭說明。
推薦系統(tǒng)的召回階段是很關鍵的一個環(huán)節(jié),但是客觀的說,傳統(tǒng)地看,這個環(huán)節(jié),技術含量是不太高的,偏向策略型導向,往往靈機一動,就能想到一個策略,增加一路新的召回。你在網(wǎng)上搜,發(fā)現(xiàn)講推薦模型的,95%是講排序階段的模型,講召回的別說模型,講它本身的都很少,這與它的策略導向有關系,大家覺得沒什么好講的。
總體而言,召回環(huán)節(jié)的有監(jiān)督模型化以及一切Embedding化,這是兩個相輔相成的總體發(fā)展趨勢。而打embedding的具體方法,則可以有各種選擇,比如下面介紹的幾個技術發(fā)展趨勢,可以理解為不同的給用戶和物品打embedding的不同方法而已。


模型召回

傳統(tǒng)的標準召回結構一般是多路召回,如上圖所示。如果我們根據(jù)召回路是否有用戶個性化因素存在來劃分,可以分成兩大類:
一類是無個性化因素的召回路,比如熱門商品或者熱門文章或者歷史點擊率高的物料的召回;另外一類是包含個性化因素的召回路,比如用戶興趣標簽召回。
我們應該怎么看待包含個性化因素的召回路呢?其實吧,你可以這么看,可以把某個召回路看作是:單特征模型排序的排序結果。意思是,可以把某路召回,看成是某個排序模型的排序結果,只不過,這個排序模型,在用戶側(cè)和物品側(cè)只用了一個特征。
比如說,標簽召回,其實就是用用戶興趣標簽和物品標簽進行排序的單特征排序結果;再比如協(xié)同召回,可以看成是只包含UID和ItemID的兩個特征的排序結果….諸如此類。我們應該統(tǒng)一從排序的角度來看待推薦系統(tǒng)的各個環(huán)節(jié),這樣可能會更好理解本文所講述的一些技術。
如果我們換做上面的角度看待有個性化因素召回路,那么在召回階段引入模型,就是自然而然的一個拓展結果:無非是把單特征排序,拓展成多特征排序的模型而已;而多路召回,則可以通過引入多特征,被融入到獨立的召回模型中,找到它的替代品。如此而已。所以,隨著技術的發(fā)展,在embedding基礎上的模型化召回,必然是個符合技術發(fā)展潮流的方向。
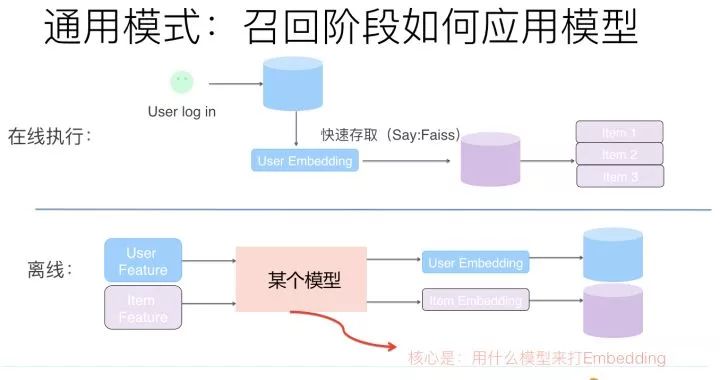
那么如何在召回階段利用模型來代替多路召回呢?
上圖展示了一個抽象的模型召回的通用架構,核心思想是:將用戶特征和物品特征分離,各自通過某個具體的模型,分別打出用戶Embedding以及物品Embedding。在線上,可以根據(jù)用戶興趣Embedding,采用類似Faiss等高效Embedding檢索工具,快速找出和用戶興趣匹配的物品,這樣就等于做出了利用多特征融合的召回模型了。理論上來說,任何你能見到的有監(jiān)督模型,都可以用來做這個召回模型,比如FM/FFM/DNN等,常說的所謂“雙塔”模型,指的其實是用戶側(cè)和物品側(cè)特征分離分別打Embedding的結構而已,并非具體的模型。
模型召回具備自己獨有的好處和優(yōu)勢,比如多路召回每路截斷條數(shù)的超參個性化問題等會自然被消解掉。當然,它也會帶來自己的問題,比較典型的是召回內(nèi)容頭部問題,因為之前多路,每路召回個數(shù)靠硬性截斷,可以根據(jù)需要,保證你想要召回的,總能通過某一路拉回來;而由于換成了模型召回,面向海量物料庫,排在前列得分高的可能聚集在幾個物料分布比較多的頭部領域。解決這個問題的方法包括比如訓練數(shù)據(jù)對頭部領域的降采樣,減少某些領域主導,以及在模型角度鼓勵多樣性等不同的方法。
另外一點值得注意的是:如果在召回階段使用模型召回,理論上也應該同步采用和排序模型相同的優(yōu)化目標,尤其是如果排序階段采用多目標優(yōu)化的情況下,召回模型也應該對應采取相同的多目標優(yōu)化。同理,如果整個流程中包含粗排模塊,粗排也應該采用和精排相同的多目標優(yōu)化,幾個環(huán)節(jié)優(yōu)化目標應保持一致。因為召回和粗排是精排的前置環(huán)節(jié),否則,如果優(yōu)化目標不一致,很可能會出現(xiàn)高質(zhì)量精排目標,在前置環(huán)節(jié)就被過濾掉的可能,影響整體效果。
典型工作
FM模型召回:推薦系統(tǒng)召回四模型之:全能的FM模型
DNN雙塔召回:Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations
用戶在使用APP或者網(wǎng)站的時候,一般會產(chǎn)生一些針對物品的行為,比如點擊一些感興趣的物品,收藏或者互動行為,或者是購買商品等。而一般用戶之所以會對物品發(fā)生行為,往往意味著這些物品是符合用戶興趣的,而不同類型的行為,可能代表了不同程度的興趣。比如購買就是比點擊更能表征用戶興趣的行為。
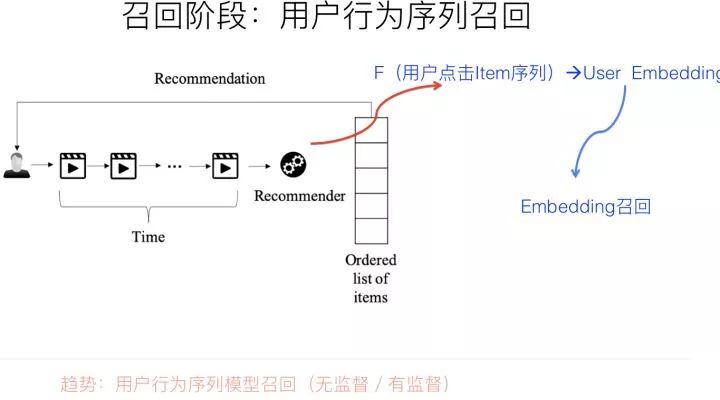
而用戶行為過的物品序列,其實是具備表征用戶興趣的非常有價值的信息,而且這種興趣表征,是細粒度的用戶興趣,所以對于刻畫用戶興趣具備特別的價值。利用用戶行為過的物品序列,來表征用戶興趣,具備很好的實用價值。
如果我們抽象地來看的話,利用用戶行為過的物品序列對用戶興趣建模,本質(zhì)上就是這么個過程:輸入是用戶行為過的物品序列,可以只用物品ID表征,也可以融入物品的Side Information比如名稱,描述,圖片等,現(xiàn)在我們需要一個函數(shù)Fun,這個函數(shù)以這些物品為輸入,需要通過一定的方法把這些進行糅合到一個embedding里,而這個糅合好的embedding,就代表了用戶興趣。無論是在召回過程,還是排序過程,都可以融入用戶行為序列。在召回階段,我們可以用用戶興趣Embedding采取向量召回,而在排序階段,這個embedding則可以作為用戶側(cè)的特征。
所以,核心在于:這個物品聚合函數(shù)Fun如何定義的問題。這里需要注意的一點是:用戶行為序列中的物品,是有時間順序的。理論上,任何能夠體現(xiàn)時序特點或特征局部性關聯(lián)的模型,都比較適合應用在這里,典型的比如CNN、RNN、Transformer等,都比較適合用來集成用戶行為序列信息。而目前的很多試驗結果證明,GRU(RNN的變體模型)可能是聚合用戶行為序列效果最好又比較簡單的模型。當然,RNN不能并行的低效率,那是另外一個問題。
在召回階段,如何根據(jù)用戶行為序列打embedding,可以采取有監(jiān)督的模型,比如Next Item Prediction的預測方式即可;也可以采用無監(jiān)督的方式,比如物品只要能打出embedding,就能無監(jiān)督集成用戶行為序列內(nèi)容,例如Sum Pooling。而排序側(cè),必然是有監(jiān)督的模式,需要注意的是:排序側(cè)表征用戶特征的時候,可以只用用戶行為過的物品序列,也可以混合用戶其它特征,比如群體屬性特征等一起來表征用戶興趣,方式比較靈活。比如DIEN,就是典型的采用混合模式的方法。
典型工作
GRU:Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
CNN:Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
Transformer: Self-Attentive Sequential Recommendation
上文講了利用用戶行為物品序列,打出用戶興趣Embedding的做法。但是,另外一個現(xiàn)實是:用戶往往是多興趣的,比如可能同時對娛樂、體育、收藏感興趣。這些不同的興趣也能從用戶行為序列的物品構成上看出來,比如行為序列中大部分是娛樂類,一部分體育類,少部分收藏類等。那么能否把用戶行為序列物品中,這種不同類型的用戶興趣細分,而不是都籠統(tǒng)地打到一個用戶興趣Embedding里呢?用戶多興趣拆分就是解決這類更細致刻畫用戶興趣的方向。
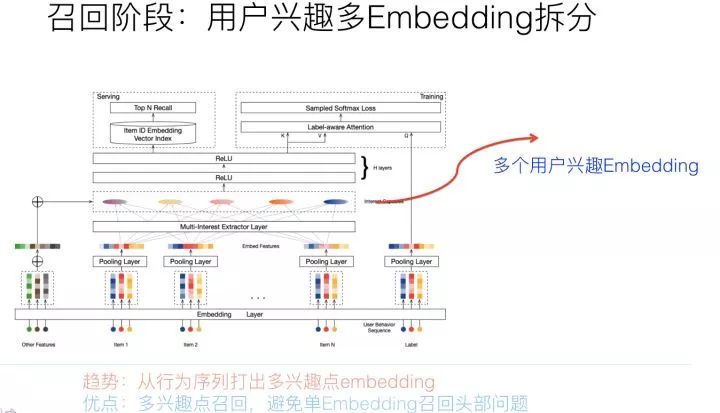
用戶多興趣拆分,本質(zhì)上是上文所敘述的用戶行為序列打embedding方向的一個細化,無非上文說的是:以用戶行為序列物品作為輸入,通過一些能體現(xiàn)時序特點的模型,映射成一個用戶興趣embedding。而用戶多興趣拆分,輸入是一樣的,輸出不同,無非由輸出單獨一個用戶embedding,換成輸出多個用戶興趣embedding而已。雖說道理如此,但是在具體技術使用方向上卻不太一樣,對于單用戶興趣embedding來說,只需要考慮信息有效集成即可。
而對于多用戶興趣拆分來說,需要多做些事情,多做什么事情呢?本質(zhì)上,把用戶行為序列打到多個embedding上,實際它是個類似聚類的過程,就是把不同的Item,聚類到不同的興趣類別里去。目前常用的拆分用戶興趣embedding的方法,主要是膠囊網(wǎng)絡和Memory Network,但是理論上,很多類似聚類的方法應該都是有效的,所以完全可以在這塊替換成你自己的能產(chǎn)生聚類效果的方法來做。
說到這里,有同學會問了:把用戶行為序列拆分到不同的embedding里,有這個必要嗎?反正不論怎樣,即使是一個embedding,信息都已經(jīng)包含到里面了,并未有什么信息損失問題呀。這個問題很好。
我的個人感覺是:在召回階段,把用戶興趣拆分成多個embedding是有直接價值和意義的,前面我們說過,召回階段有時候容易碰到頭部問題,就是比如通過用戶興趣embedding拉回來的物料,可能集中在頭部優(yōu)勢領域中,造成弱勢興趣不太能體現(xiàn)出來的問題。而如果把用戶興趣進行拆分,每個興趣embedding各自拉回部分相關的物料,則可以很大程度緩解召回的頭部問題。
所以我感覺,這種興趣拆分,在召回階段是很合適的,可以定向解決它面臨的一些實際問題。對于排序環(huán)節(jié),是否有必要把用戶興趣拆分成多個,我倒覺得必要性不是太大,很難直觀感受這樣做背后發(fā)生作用的機理是怎樣的。
我能想到的,在排序環(huán)節(jié)使用多興趣Embedding能發(fā)生作用的地方,好像有一個:因為我們在計算user對某個item是否感興趣的時候,對于用戶行為序列物品,往往計算目標item和行為序列物品的Attention是有幫助的,因為用戶興趣是多樣的,物品Item的類型歸屬往往是唯一的,所以行為序列里面只有一部分物品和當前要判斷的Item是類型相關的,這會對判斷有作用,其它的無關物品其實沒啥用,于是Attention就是必要的,可以減少那些無關物品對當前物品判斷的影響。
而當行為序列物品太多的時候,我們知道,Atttention計算是非常耗時的操作,如果我們把這種Attention計算,放到聚類完的幾個興趣embedding維度計算,無疑能極大提升訓練和預測的速度。貌似這個優(yōu)點還是成立的。
典型工作
召回:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
排序:Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction
推薦系統(tǒng)中,最核心的數(shù)據(jù)是用戶對物品的行為數(shù)據(jù),因為這直接表明了用戶興趣所在。如上圖所示,如果把用戶放在一側(cè),物品放在另一側(cè),若用戶對某物品有行為產(chǎn)生,則建立一條邊,這樣就構建了用戶-物品交互的二部圖。其實,有另外一種隱藏在冰山之下的數(shù)據(jù),那就是物品之間是有一些知識聯(lián)系存在的,就是我們常說的知識圖譜,而這類數(shù)據(jù)是可以考慮用來增強推薦效果的,尤其是對于用戶行為數(shù)據(jù)稀疏的場景,或者冷啟動場景。以上圖例子說明,用戶點擊過電影“泰坦尼克號”,這是用戶行為數(shù)據(jù),我們知道,電影“泰坦尼克號”的主演是萊昂納多,于是可以推薦其它由萊昂納多主演的電影給這個用戶。后面這幾步操作,利用的是電影領域的知識圖譜數(shù)據(jù),通過知識圖譜中的“電影1—>主演—>電影2”的圖路徑給出的推薦結果。
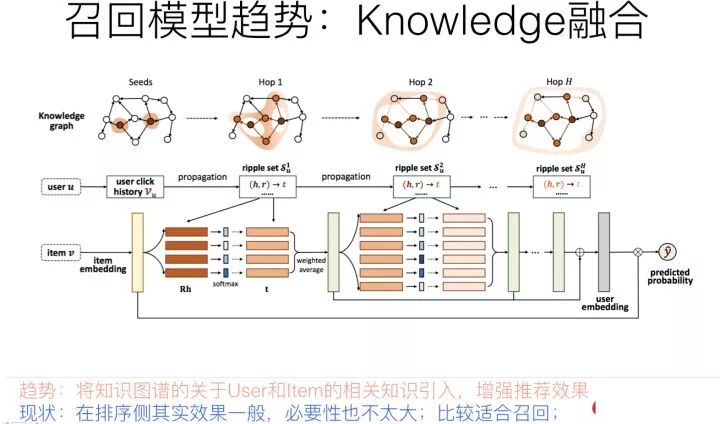
用于做推薦,一般有兩大類知識圖譜融合模式:知識圖譜Embedding模式(KGE)及圖路徑模式。知識圖譜Embedding模式首先根據(jù)TransE等對知識圖譜進行Embedding化編碼的工具,將節(jié)點和邊轉(zhuǎn)換成Embedding表征方式。然后根據(jù)用戶行為過的物品,以及物品在知識圖譜中的Embedding和知識圖譜中其它知識embedding的距離,來擴展物品的信息含量,或者擴充用戶行為數(shù)據(jù),類似用已知的用戶行為數(shù)據(jù),在知識圖譜輔助下進行外擴。
知識圖譜的Embedding模式在可解釋性方面比較弱,因為知識之間的關聯(lián)是通過Embedding計算出來的,不好解釋為什么從這個知識跳到那個知識;而圖路徑模式則是根據(jù)物品屬性之間的關聯(lián)等人工定義好的所謂Meta-Path,也就是人工定義的知識圖譜中知識的關聯(lián)和傳播模式,通過中間屬性來對知識傳播進行路徑搭建,具體例子就是上面說的“電影1主演電影2”,這就是人事先定義好的Meta-Path,也就是人把自己的經(jīng)驗寫成規(guī)則,來利用知識圖譜里的數(shù)據(jù)。圖路徑模式在可解釋性方面效果較好,因為是人工定義的傳播路徑,所以非常好理解知識傳播關系,但是往往實際應用效果并不好。
知識圖譜是一種信息拓展的模式,很明顯,對知識進行近距離的拓展,這可能會帶來信息補充作用,但是如果拓展的比較遠,或者拓展不當,反而可能會引入噪音,這個道理好理解。所以,我的感覺是,知識圖譜在排序側(cè)并不是特別好用,如果想用的化,比較適合用戶行為數(shù)據(jù)非常稀疏以及用戶冷啟動的場景,也就是說如果用戶數(shù)據(jù)太少,需要拓展,可以考慮使用它。
另外,知識圖譜還有一個普適性的問題,完全通用的知識圖譜在特定場景下是否好用,對此我是有疑問的,而專業(yè)性的知識圖譜,還有一個如何構建以及構建成本問題;而且很多時候,所謂的知識傳播,是可以通過添加屬性特征來解決的,比如:電影1—>主演—>電影2這種知識傳播路徑,完全可以通過把主演作為電影這個實體的屬性特征加入常規(guī)排序模型,來達到類似知識近距離傳播的目的,所以感覺也不是很有必要在排序側(cè)專門去做知識圖譜拓展這種事情。
這種知識拓展,可能比較適合用在召回階段,因為對于傳統(tǒng)觀點的召回來說,精準并不是最重要的目標,找出和用戶興趣有一定程度相關性但是又具備泛化性能的物品是召回側(cè)的重點,所以可能知識圖譜的模式更適合將知識圖譜放在召回側(cè)。
當然,知識圖譜有一個獨有的優(yōu)勢和價值,那就是對于推薦結果的可解釋性;比如推薦給用戶某個物品,可以在知識圖譜里通過物品的關鍵關聯(lián)路徑給出合理解釋,這對于推薦結果的解釋性來說是很好的,因為知識圖譜說到底是人編碼出來讓自己容易理解的一套知識體系,所以人非常容易理解其間的關系。但是,在推薦領域目前的工作中,知識圖譜的可解釋性往往是和圖路徑方法關聯(lián)在一起的,而Path類方法,很多實驗證明了,在排序角度來看,是效果最差的一類方法。所以,我覺得,應該把知識圖譜的可解釋性優(yōu)勢從具體方法中獨立出來,專門用它來做推薦結果的可解釋性,這樣就能獨立發(fā)揮它自身的優(yōu)勢;
至于如何利用知識圖譜做召回,其實很直觀,比如可以采取如下的無監(jiān)督學習版本:例如,推薦系統(tǒng)里對用戶感興趣的實體比如某個或者某些明星,往往是個單獨的召回路,而可以根據(jù)用戶的興趣實體,通過知識圖譜的實體Embedding化表達后(或者直接在知識圖譜節(jié)點上外擴),通過知識外擴或者可以根據(jù)Embedding相似性,拓展出相關實體。形成另外一路相關性弱,但是泛化能力強的Knowledge融合召回路。
典型工作
1. KGAT: Knowledge Graph Attention Network for Recommendation
2. RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
圖神經(jīng)網(wǎng)絡模型召回
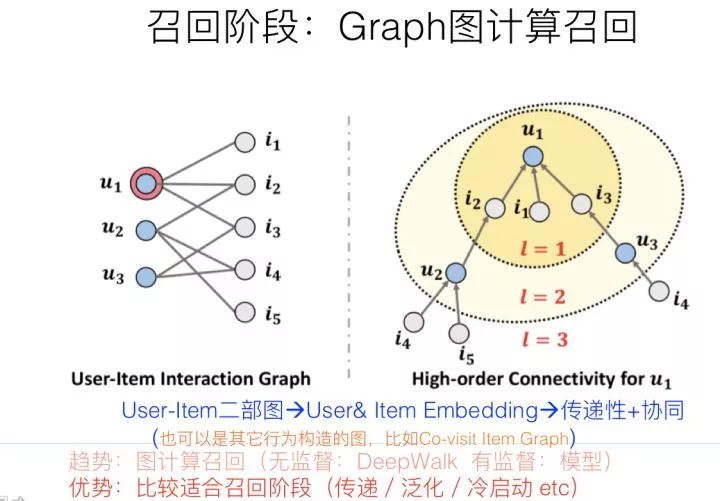
嚴格來說,知識圖譜其實是圖神經(jīng)網(wǎng)絡的一個比較特殊的具體實例,但是,知識圖譜因為編碼的是靜態(tài)知識,而不是用戶比較直接的行為數(shù)據(jù),和具體應用距離比較遠,這可能是導致兩者在推薦領域表現(xiàn)差異的主要原因。圖神經(jīng)網(wǎng)絡中的圖結構,可以是上面介紹知識圖譜時候說過的“用戶-物品”二部圖,也可以是我們常見的有向圖或者無向圖,圖中的節(jié)點是各種不同類型的物品及用戶,邊往往是通過用戶行為建立起來的,可以是具體用戶的具體行為,也可以是所有用戶的群體統(tǒng)計行為,比如物品1—>物品2可以有邊,邊還可以帶上權重,如果越多的用戶對物品1進行行為后對物品2進行行為,則這條邊的權重越大。而且對于用戶或者物品來說,其屬性也可以體現(xiàn)在圖中,比如對于一個微博,它的文本內(nèi)容、圖片內(nèi)容、發(fā)布者等等屬性都可以引入到圖中,比如掛接到物品上,或者建立獨立的節(jié)點也是可以的,這取決于具體的做法。
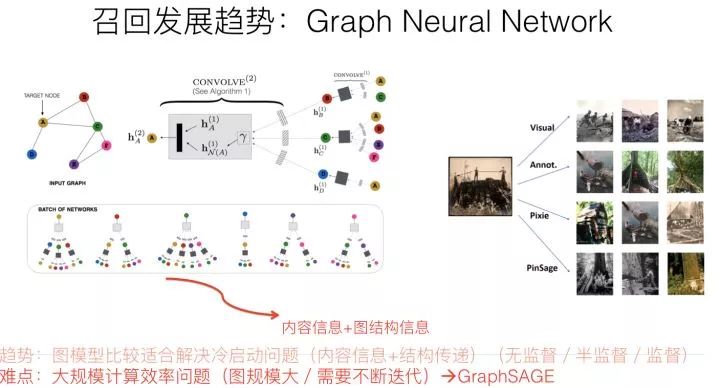
圖神經(jīng)網(wǎng)絡的最終目的是要通過一定技術手段,獲得圖中節(jié)點的embedding編碼。最常用的embedding聚合工具是CNN,對于某個圖節(jié)點來說,它的輸入可以有兩類信息,一類是自身的屬性信息,比如上面舉的微博的例子;另外一類是圖結構信息,就是和當前節(jié)點有直接邊關聯(lián)的其它節(jié)點信息。通過CNN,可以對兩類信息進行編碼和聚合,形成圖節(jié)點的embedding。通過CNN等信息聚合器,在圖節(jié)點上進行計算,并反復迭代更新圖節(jié)點的embedding,就能夠最終獲得可靠的圖節(jié)點embedding信息,而這種迭代過程,其實體現(xiàn)的是遠距離的節(jié)點將信息逐步通過圖結構傳遞信息的過程,所以圖結構是可以進行知識傳遞和補充的。
我們可以進一步思考下,圖節(jié)點因為可以帶有屬性信息,比如物品的Content信息,所以明顯這對于解決物品側(cè)的冷啟動問題有幫助;而因為它也允許知識在圖中遠距離進行傳遞,所以比如對于用戶行為比較少的場景,可以形成知識傳遞和補充,這說明它也比較適合用于數(shù)據(jù)稀疏的推薦場景;另外一面,圖中的邊往往是通過用戶行為構建的,而用戶行為,在統(tǒng)計層面來看,本質(zhì)上是一種協(xié)同信息,比如我們常說的“A物品協(xié)同B物品”,本質(zhì)上就是說很多用戶行為了物品A后,大概率會去對物品B進行行為;所以圖具備的一個很好的優(yōu)勢是:它比較便于把協(xié)同信息、用戶行為信息、內(nèi)容屬性信息等各種異質(zhì)信息在一個統(tǒng)一的框架里進行融合,并統(tǒng)一表征為embedding的形式,這是它獨有的一個優(yōu)勢,做起來比較自然。另外的一個特有優(yōu)勢,就是信息在圖中的傳播性,所以對于推薦的冷啟動以及數(shù)據(jù)稀疏場景應該特別有用。
因為圖神經(jīng)網(wǎng)絡,最終獲得的往往是圖中節(jié)點的embedding,這個embedding,就像我們上面說的,其實融合了各種異質(zhì)信息。所以它是特別適合用來做召回的,比如拿到圖網(wǎng)絡中用戶的embedding和物品embedding,可以直接用來做向量召回。當然,物品和用戶的embedding也可以作為特征,引入排序模型中,這都是比較自然的。有些推薦場景也可以直接根據(jù)embedding計算user to user/item to item的推薦結果,比如看了又看這種推薦場景。
早期的圖神經(jīng)網(wǎng)絡做推薦,因為需要全局信息,所以計算速度是個問題,往往圖規(guī)模都非常小,不具備實戰(zhàn)價值。而GraphSAGE則通過一些手段比如從臨近節(jié)點進行采樣等減少計算規(guī)模,加快計算速度,很多后期改進計算效率的方法都是從這個工作衍生的;而PinSage在GraphSAGE基礎上(這是同一撥人做的),進一步采取大規(guī)模分布式計算,拓展了圖計算的實用性,可以計算Pinterest的30億規(guī)模節(jié)點、180億規(guī)模邊的巨型圖,并產(chǎn)生了較好的落地效果。所以這兩個工作可以重點借鑒一下。
總體而言,圖模型召回,是個很有前景的值得探索的方向。
典型工作
GraphSAGE: Inductive Representation Learning on Large Graphs
PinSage: Graph Convolutional Neural Networks for Web-Scale Recommender Systems
https://zhuanlan.zhihu.com/p/100019681

