
推薦系統(tǒng)技術(shù)演進(jìn)趨勢:排序篇
煉丹筆記干貨

四個環(huán)節(jié)分別是:召回、粗排、精排和重排。
召回目的如上所述;有時候因?yàn)槊總€用戶召回環(huán)節(jié)返回的物品數(shù)量還是太多,怕排序環(huán)節(jié)速度跟不上,所以可以在召回和精排之間加入一個粗排環(huán)節(jié),通過少量用戶和物品特征,簡單模型,來對召回的結(jié)果進(jìn)行個粗略的排序,在保證一定精準(zhǔn)的前提下,進(jìn)一步減少往后傳送的物品數(shù)量,粗排往往是可選的,可用可不同,跟場景有關(guān)。
之后,是精排環(huán)節(jié),使用你能想到的任何特征,可以上你能承受速度極限的復(fù)雜模型,盡量精準(zhǔn)地對物品進(jìn)行個性化排序。排序完成后,傳給重排環(huán)節(jié),傳統(tǒng)地看,這里往往會上各種技術(shù)及業(yè)務(wù)策略,比如去已讀、去重、打散、多樣性保證、固定類型物品插入等等,主要是技術(shù)產(chǎn)品策略主導(dǎo)或者為了改進(jìn)用戶體驗(yàn)的。
那么,每個環(huán)節(jié),從技術(shù)發(fā)展的角度看,都各自有怎樣的發(fā)展趨勢呢?下面我們分頭說明。
排序環(huán)節(jié)是推薦系統(tǒng)最關(guān)鍵,也是最具有技術(shù)含量的部分,目前大多數(shù)推薦技術(shù)其實(shí)都聚焦在這塊。下面我們從模型表達(dá)能力、模型優(yōu)化目標(biāo)以及特征及信息三個角度分述推薦排序模型的技術(shù)發(fā)展趨勢。

模型表達(dá)能力代表了模型是否具備充分利用有效特征及特征組合的能力,其中顯示特征組合、新型特征抽取器、增強(qiáng)學(xué)習(xí)技術(shù)應(yīng)用以及AutoML自動探索模型結(jié)構(gòu)是這方面明顯的技術(shù)進(jìn)化方向。
模型優(yōu)化目標(biāo)則體現(xiàn)了我們希望推薦系統(tǒng)去做好什么,往往跟業(yè)務(wù)目標(biāo)有關(guān)聯(lián),這里我們主要從技術(shù)角度來探討,而多目標(biāo)優(yōu)化以及ListWise最優(yōu)是目前最常見的技術(shù)進(jìn)化方向,ListWise優(yōu)化目標(biāo)在排序階段和重排階段都可采用,我們把它放到重排部分去講,這里主要介紹多目標(biāo)優(yōu)化。
從特征和信息角度,如何采用更豐富的新類型特征,以及信息和特征的擴(kuò)充及融合是主要技術(shù)進(jìn)化方向,用戶長短期興趣分離、用戶行為序列數(shù)據(jù)的使用、圖神經(jīng)網(wǎng)絡(luò)以及多模態(tài)融合等是這方面的主要技術(shù)趨勢,因?yàn)橛脩粜袨樾蛄幸约皥D神經(jīng)網(wǎng)絡(luò)在召回部分介紹過,這些點(diǎn)同樣可以應(yīng)用在排序部分,所以這里不再敘述這兩點(diǎn)。


顯式特征組合
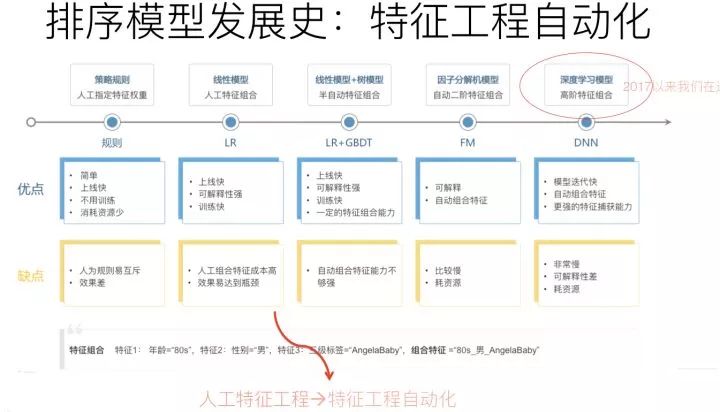
如果歸納下工業(yè)界CTR模型的演化歷史的話,你會發(fā)現(xiàn),特征工程及特征組合的自動化,一直是推動實(shí)用化推薦系統(tǒng)技術(shù)演進(jìn)最主要的方向,而且沒有之一。
最早的LR模型,基本是人工特征工程及人工進(jìn)行特征組合的,簡單有效但是費(fèi)時費(fèi)力;再發(fā)展到LR+GBDT的高階特征組合自動化,以及FM模型的二階特征組合自動化;再往后就是DNN模型的引入,純粹的簡單DNN模型本質(zhì)上其實(shí)是在FM模型的特征Embedding化基礎(chǔ)上,添加幾層MLP隱層來進(jìn)行隱式的特征非線性自動組合而已。
所謂隱式,意思是并沒有明確的網(wǎng)絡(luò)結(jié)構(gòu)對特征的二階組合、三階組合進(jìn)行直接建模,只是通過MLP,讓不同特征發(fā)生交互,至于怎么發(fā)生交互的,怎么進(jìn)行特征組合的,誰也說不清楚,這是MLP結(jié)構(gòu)隱式特征組合的作用,當(dāng)然由于MLP的引入,也會在特征組合時候考慮進(jìn)入了特征間的非線性關(guān)系。
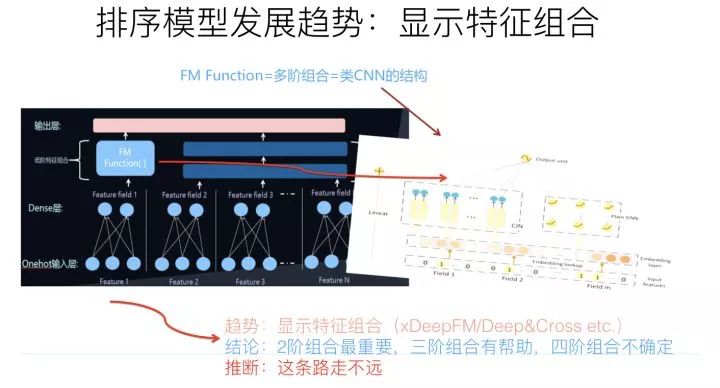
明白了隱式特征組合,也就明白了什么是顯式特征組合。就是在模型結(jié)構(gòu)中,明確設(shè)計一些子網(wǎng)絡(luò)或者子結(jié)構(gòu),對二階特征組合、三階特征組合,甚至更高階的特征組合進(jìn)行表征。
比如說DeepFM,Deep部分就是個典型的DNN模型,這個大家基本都會用,而FM部分則是明確對特征二階組合進(jìn)行建模的子模型。這就是一個典型的顯式二階特征組合的模型。而如果進(jìn)一步拓展的話,很自然想到的一個改進(jìn)思路是:除了明確的把特征二階組合做一個子結(jié)構(gòu),還可以把特征三階特征組合,更高階特征組合…..分別做一個模型子結(jié)構(gòu)。融合這些子結(jié)構(gòu)一起來做預(yù)測。這就是顯式特征組合的含義,其實(shí)這條線的發(fā)展脈絡(luò)是異常清晰的。
典型的對高階特征組合建模的比如Deep& Cross、XDeepFM模型等,就是這么個思路。
在兩年多前,我一直以為這個方向是CTR或者推薦模型的關(guān)鍵所在,而且可能如何簡潔融入更多特征組合是最重要且最有前景的方向。但是后來發(fā)現(xiàn)可能錯了,目前基本對這個方向改變了看法。目前我對這個方向的看法是:這個方向確實(shí)很重要,但是未來可挖掘的潛力和空間很有限,在這條路上繼續(xù)行進(jìn),應(yīng)該不會走得太遠(yuǎn)。
原因在于,目前基本很多經(jīng)驗(yàn)已經(jīng)證明了,顯式的二階特征組合是非常重要的,三階特征組合對不同類型任務(wù)基本都有幫助。四階特征組合已經(jīng)說不清楚是否有用了,跟數(shù)據(jù)集有關(guān)系,有些數(shù)據(jù)集合引入顯式4階特征組合有幫助,有些數(shù)據(jù)集合沒什么用。至于更高階的特征組合,明確用對應(yīng)的子結(jié)構(gòu)建模,基本已經(jīng)沒什么用了,甚至是負(fù)面作用。這說明:我們在實(shí)際做事情的時候,其實(shí)顯式結(jié)構(gòu)把三階特征組合引入,已經(jīng)基本足夠了。這是為什么說這條路繼續(xù)往后走潛力不大的原因。
典型工作
Deep& Cross: Deep & Cross Network for Ad Click Predictions
XDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
從特征抽取器的角度來看,目前主流的DNN 排序模型,最常用的特征抽取器仍然是MLP結(jié)構(gòu),通常是兩層或者三層的MLP隱層。目前也有理論研究表明:MLP結(jié)構(gòu)用來捕獲特征組合,是效率比較低下的,除非把隱層神經(jīng)元個數(shù)急劇放大,而這又會急劇增加參數(shù)規(guī)模。與自然語言處理和圖像處理比較,推薦領(lǐng)域的特征抽取器仍然處于非常初級的發(fā)展階段。所以,探尋新型特征抽取器,對于推薦模型的進(jìn)化是個非常重要的發(fā)展方向。
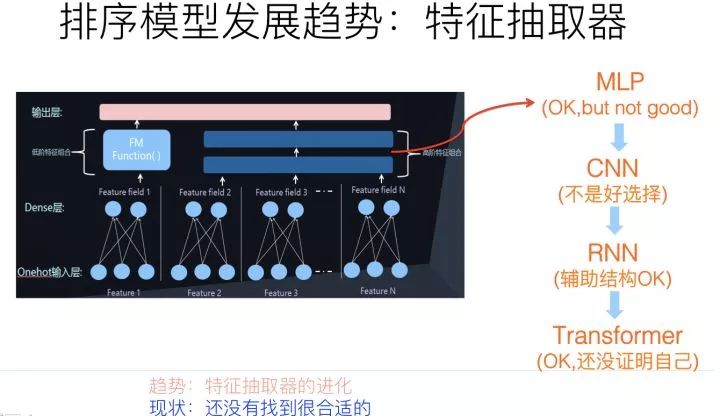
目前其它AI領(lǐng)域里,常用的特征抽取器包括圖像領(lǐng)域的CNN、NLP領(lǐng)域的RNN和Transformer。這些新型特征抽取器,在推薦領(lǐng)域最近兩年也逐步開始嘗試使用,但是宏觀地看,在推薦領(lǐng)域,相對MLP結(jié)構(gòu)并未取得明顯優(yōu)勢,這里的原因比較復(fù)雜。
CNN捕獲局部特征關(guān)聯(lián)是非常有效的結(jié)構(gòu),但是并不太適合做純特征輸入的推薦模型,因?yàn)橥扑]領(lǐng)域的特征之間,在輸入順序上并無必然的序列關(guān)系,基本屬于人工定義隨機(jī)順序,而CNN處理這種遠(yuǎn)距離特征關(guān)系能力薄弱,所以并不是特別適合用來處理特征級的推薦模型。
當(dāng)然,對于行為序列數(shù)據(jù),因?yàn)楸旧韼в行蛄袑傩裕訡NN和RNN都是非常適合應(yīng)用在行為序列結(jié)構(gòu)上的,也是有一定應(yīng)用歷史的典型工具,但是對于沒有序關(guān)系存在的特征來說,這兩個模型的優(yōu)勢不能發(fā)揮出來,反而會放大各自的劣勢,比如CNN的捕獲遠(yuǎn)距離特征關(guān)系能力差的弱點(diǎn),以及RNN的不可并行處理、所以速度慢的劣勢等。
Transformer作為NLP領(lǐng)域最新型也是最有效的特征抽取器,從其工作機(jī)制來說,其實(shí)是非常適合用來做推薦的。為什么這么說呢?核心在于Transformer的Multi-Head Self Attention機(jī)制上。
MHA結(jié)構(gòu)在NLP里面,會對輸入句子中任意兩個單詞的相關(guān)程度作出判斷,而如果把這種關(guān)系套用到推薦領(lǐng)域,就是通過MHA來對任意特征進(jìn)行特征組合,而上文說過,特征組合對于推薦是個很重要的環(huán)節(jié),所以從這個角度來說,Transformer是特別適合來對特征組合進(jìn)行建模的,一層Transformer Block代表了特征的二階組合,更多的Transformer Block代表了更高階的特征組合。
但是,實(shí)際上如果應(yīng)用Transformer來做推薦,其應(yīng)用效果并沒有體現(xiàn)出明顯優(yōu)勢,甚至沒有體現(xiàn)出什么優(yōu)勢,基本稍微好于或者類似于典型的MLP結(jié)構(gòu)的效果。這意味著,可能我們需要針對推薦領(lǐng)域特點(diǎn),對Transformer需要進(jìn)行針對性的改造,而不是完全直接照搬NLP里的結(jié)構(gòu)。
典型工作
AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
DeepFM: An End-to-End Wide & Deep Learning Framework for CTR Prediction
AutoML在17年初開始出現(xiàn),最近三年蓬勃發(fā)展,在比如圖像領(lǐng)域、NLP領(lǐng)域等都有非常重要的研究進(jìn)展,在這些領(lǐng)域,目前都能通過AutoML找到比人設(shè)計的效果更好的模型結(jié)構(gòu)。
AutoML作為算法方向最大的領(lǐng)域趨勢之一,能否在不同領(lǐng)域超過人類專家的表現(xiàn)?這應(yīng)該不是一個需要回答“會不會”的問題,而是應(yīng)該回答“什么時間會”的問題。原因很簡單,AutoML通過各種基礎(chǔ)算子的任意組合,在超大的算子組合空間內(nèi),尋找性能表現(xiàn)最好的模型,幾乎可以達(dá)到窮舉遍歷的效果,而人類專家設(shè)計出來的最好的模型,無非是算子組合空間中的一個點(diǎn)而已,而且人類專家設(shè)計的那個模型,是最好模型的可能性是很低的。
如果設(shè)計精良的AutoML,一定可以自己找到超過目前人類專家設(shè)計的最好的那個模型,這基本不會有什么疑問,就像人類就算不是2017年,也會是某一年,下圍棋下不過機(jī)器,道理其實(shí)是一樣的,因?yàn)锳utoML在巨大的算子組合空間里尋找最優(yōu)模型,跟圍棋在無窮的棋盤空間尋找勝利的盤面,本質(zhì)上是一個事情。無非,現(xiàn)在AutoML的不成熟,體現(xiàn)在需要搜索的空間太大,比較消耗計算資源方面而已,隨著技術(shù)的不斷成熟,搜索成本越來越低,AutoML在很多算法方向超過人類表現(xiàn)只是個時間問題。


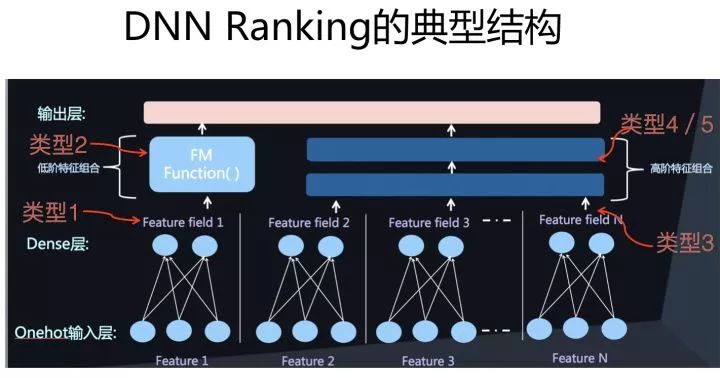
在推薦領(lǐng)域,采用AutoML做網(wǎng)絡(luò)結(jié)構(gòu)的工作還很少,這里面有很多原因。由于我一直以來特別看好這個方向,所以在18年的時候,我們也嘗試過利用AutoML來自動探索推薦系統(tǒng)的網(wǎng)絡(luò)結(jié)構(gòu),這里非常簡略地介紹下過程及結(jié)果(參考上面三圖)。
我們用ENAS作為網(wǎng)絡(luò)搜索工具,設(shè)計了推薦領(lǐng)域網(wǎng)絡(luò)結(jié)構(gòu)自動探索的嘗試。ENAS是個非常高效率的AutoML工具,可以做到單GPU半天搜索找到最優(yōu)的網(wǎng)絡(luò)結(jié)構(gòu),但是它定義的主要是CNN結(jié)構(gòu)和RNN結(jié)構(gòu)搜索。
我們對ENAS進(jìn)行了改造,包括算子定義,優(yōu)化目標(biāo)以及評價指標(biāo)定義等。DNN排序模型因?yàn)槟P捅容^單一,所以算子是比較好找的,我們定義了推薦領(lǐng)域的常用算子,然后在這些算子組合空間內(nèi)通過ENAS自動尋找效果最優(yōu)的網(wǎng)絡(luò)結(jié)構(gòu),最終找到的一個表現(xiàn)最好的網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示:
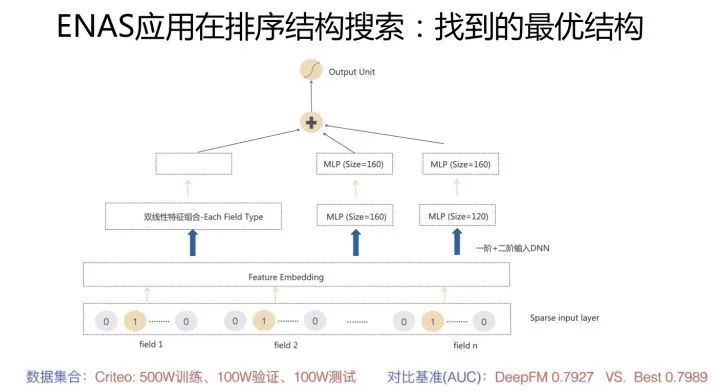
首先是特征onehot到embedding的映射,我們把這層固定住了,不作為模型結(jié)構(gòu)探索因子。在特征embedding之上,有三個并行結(jié)構(gòu),其中兩個是包含兩個隱層的MLP結(jié)構(gòu),另外一個是特征雙線性組合模塊(Each Fields Type,具體含義可以參考下面的FibiNet)。其表現(xiàn)超過了DeepFM等人工結(jié)構(gòu),但是并未超過很多。(感謝黃通文同學(xué)的具體嘗試)
總體而言,目前AutoML來做推薦模型,還很不成熟,找出的結(jié)構(gòu)相對人工設(shè)計結(jié)構(gòu)效果優(yōu)勢也不是太明顯。這與DNN Ranking模型比較簡單,算子類型太少以及模型深度做不起來也有很大關(guān)系。但是,我相信這里可以有更進(jìn)一步的工作可做。
典型工作
ENAS結(jié)構(gòu)搜索:AutoML在推薦排序網(wǎng)絡(luò)結(jié)構(gòu)搜索的應(yīng)用
雙線性特征組合: FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
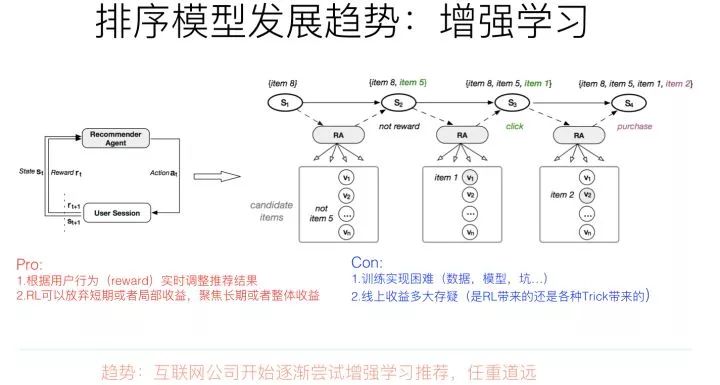
增強(qiáng)學(xué)習(xí)其實(shí)是比較吻合推薦場景建模的。一般而言,增強(qiáng)學(xué)習(xí)有幾個關(guān)鍵要素:狀態(tài)、行為以及回報。在推薦場景下,我們可以把狀態(tài)St定義為用戶的行為歷史物品集合;推薦系統(tǒng)可選的行為空間則是根據(jù)用戶當(dāng)前狀態(tài)St推薦給用戶的推薦結(jié)果列表,這里可以看出,推薦場景下,用戶行為空間是巨大無比的,這制約了很多無法對巨大行為空間建模的增強(qiáng)學(xué)習(xí)方法的應(yīng)用;而回報呢,則是用戶對推薦系統(tǒng)給出的列表內(nèi)容進(jìn)行互動的行為價值,比如可以定義點(diǎn)擊了某個物品,則回報是1,購買了某個物品,回報是5….諸如此類。有了這幾個要素的場景定義,就可以用典型的增強(qiáng)學(xué)習(xí)來對推薦進(jìn)行建模。
利用增強(qiáng)學(xué)習(xí)來做推薦系統(tǒng),有幾個顯而易見的好處,比如:
比較容易對“利用-探索”(Exploitation/Exploration)建模。所謂利用,就是推薦給用戶當(dāng)前收益最大的物品,一般推薦模型都是優(yōu)化這個目標(biāo);所謂探索,就是隨機(jī)推給用戶一些物品,以此來探測用戶潛在感興趣的東西。如果要進(jìn)行探索,往往會犧牲推薦系統(tǒng)的當(dāng)前總體收益,畢竟探索效率比較低,相當(dāng)?shù)耐ㄟ^探索渠道推給用戶的物品,用戶其實(shí)并不感興趣,浪費(fèi)了推薦位。但是,利用-探索的均衡,是比較容易通過調(diào)節(jié)增強(qiáng)學(xué)習(xí)的回報(Reward)來體現(xiàn)這個事情的,比較自然;
比較容易體現(xiàn)用戶興趣的動態(tài)變化。我們知道,用戶興趣有長期穩(wěn)定的,也有不斷變化的。而增強(qiáng)學(xué)習(xí)比較容易通過用戶行為和反饋的物品對應(yīng)的回報的重要性,而動態(tài)對推薦結(jié)果產(chǎn)生變化,所以是比較容易融入體現(xiàn)用戶興趣變化這個特點(diǎn)的。
有利于推薦系統(tǒng)長期收益建模。這點(diǎn)是增強(qiáng)學(xué)習(xí)做推薦最有優(yōu)勢的一個點(diǎn)。我們優(yōu)化推薦系統(tǒng),往往會有一些短期的目標(biāo)比如增加點(diǎn)擊率等,但是長期目標(biāo)比如用戶體驗(yàn)或者用戶活躍留存等指標(biāo),一般不太好直接優(yōu)化,而增強(qiáng)學(xué)習(xí)模型比較容易對長期收益目標(biāo)來進(jìn)行建模。
說了這么多優(yōu)點(diǎn),貌似增強(qiáng)學(xué)習(xí)應(yīng)該重點(diǎn)投入去做,是吧?我的意見正好相反,覺得從實(shí)際落地角度來看,推薦系統(tǒng)里要嘗試增強(qiáng)學(xué)習(xí)方法,如果你有這個沖動,最好還是抑制一下。主要原因是,貌似增強(qiáng)學(xué)習(xí)是技術(shù)落地投入產(chǎn)出比非常低的技術(shù)點(diǎn)。
首先投入高,要想把增強(qiáng)學(xué)習(xí)做work,意味著有很多大坑在等著你去踩,數(shù)據(jù)怎么做、模型怎么寫、回報怎么拍,長期收益怎么定義、建模并拆解成回報…….超大規(guī)模實(shí)際場景的用戶和物品,增強(qiáng)學(xué)習(xí)這么復(fù)雜的模型,系統(tǒng)怎么才能真的落地并撐住流量…..很多坑在里面;
其次,貌似目前看到的文獻(xiàn)看,貌似很少見到真的把增強(qiáng)學(xué)習(xí)大規(guī)模推到真實(shí)線上系統(tǒng),并產(chǎn)生很好的收益的系統(tǒng)。Youtube在最近一年做了不少嘗試,雖說把系統(tǒng)推上線了,但是收益怎樣不好說。
而且,從另外一個角度看,做增強(qiáng)學(xué)習(xí)里面還是有不少Trick在,那些收益到底是系統(tǒng)帶來的,還是Trick帶來的,真還不太好說。
所以,綜合而言,目前看在增強(qiáng)學(xué)習(xí)做推薦投入,貌似還是一筆不太合算的買賣。當(dāng)然,長遠(yuǎn)看,可能還是很有潛力的,但是貌似這個潛力還需要新的技術(shù)突破去推動和挖掘。
典型工作
Youtube: Top-K Off-Policy Correction for a REINFORCE Recommender System
Youtube: Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
推薦系統(tǒng)的多目標(biāo)優(yōu)化(點(diǎn)擊,互動,時長等多個目標(biāo)同時優(yōu)化)嚴(yán)格來說不僅僅是趨勢,而是目前很多公司的研發(fā)現(xiàn)狀。對于推薦系統(tǒng)來說,不同的優(yōu)化目標(biāo)可能存在互相拉后腿的現(xiàn)象,比如互動和時長,往往拉起一個指標(biāo)另外一個就會明顯往下掉,而多目標(biāo)旨在平衡不同目標(biāo)的相互影響,盡量能夠做到所有指標(biāo)同步上漲,即使很難做到,也盡量做到在某個優(yōu)化目標(biāo)上漲的情況下,不拉低或者將盡量少拉低其它指標(biāo)。
多目標(biāo)優(yōu)化對于實(shí)用化的推薦系統(tǒng)起到了舉足輕重的作用,這里其實(shí)是有很多工作可以做的,而如果多目標(biāo)優(yōu)化效果好,對于業(yè)務(wù)效果的推動作用也非常大。總而言之,多目標(biāo)優(yōu)化是值得推薦系統(tǒng)相關(guān)研發(fā)人員重點(diǎn)關(guān)注的技術(shù)方向。
從技術(shù)角度講,多目標(biāo)優(yōu)化最關(guān)鍵的有兩個問題。第一個問題是多個優(yōu)化目標(biāo)的模型結(jié)構(gòu)問題;第二個問題是不同優(yōu)化目標(biāo)的重要性如何界定的問題。
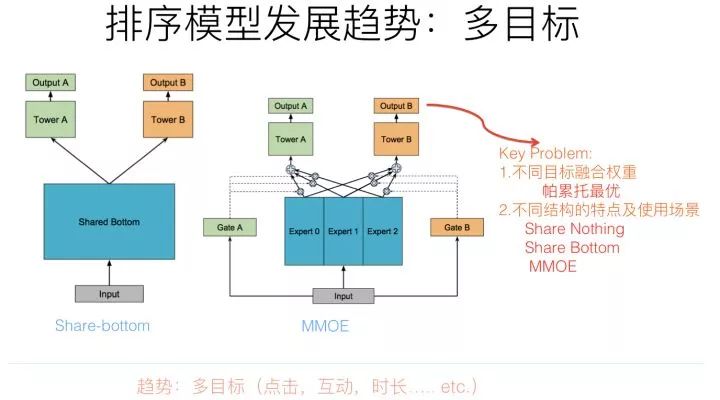
既然存在多個優(yōu)化目標(biāo),最簡單直接的方式,也是目前最常用的方式是:每個優(yōu)化目標(biāo)獨(dú)立優(yōu)化,比如點(diǎn)擊目標(biāo)訓(xùn)練一個模型,互動目標(biāo)訓(xùn)練一個模型,時長目標(biāo)訓(xùn)練一個模型,各自優(yōu)化,然后每個目標(biāo)獨(dú)立給實(shí)例預(yù)測打分,給每個目標(biāo)設(shè)定權(quán)重值,各個目標(biāo)打分加權(quán)求和線性融合,或者引入權(quán)重指數(shù)及根據(jù)目標(biāo)關(guān)系引入非線性融合。這是目前最常見的落地方案。因?yàn)槟繕?biāo)之間獨(dú)立優(yōu)化,模型是通過分?jǐn)?shù)融合來實(shí)現(xiàn)多目標(biāo)的,所以可以把這種多目標(biāo)方式稱作“Share-Nothing”結(jié)構(gòu)。這個結(jié)構(gòu)實(shí)現(xiàn)和優(yōu)化方式很簡單。
與Share-Nothing結(jié)構(gòu)相比,其實(shí)我們是可以讓不同優(yōu)化目標(biāo)共享一部分參數(shù)的,一旦引入不同目標(biāo)或者任務(wù)的參數(shù)共享,我們就踏入了Transfer Learning的領(lǐng)地了。
那么為什么要共享參數(shù)呢?
一方面出于計算效率考慮,不同目標(biāo)共享結(jié)構(gòu)能夠提升計算效率;
另外一點(diǎn),假設(shè)我們有兩類任務(wù)或者目標(biāo),其中一個目標(biāo)的訓(xùn)練數(shù)據(jù)很充分,而另外一個目標(biāo)的訓(xùn)練數(shù)據(jù)比較少;如果獨(dú)立優(yōu)化,訓(xùn)練數(shù)據(jù)少的目標(biāo)可能很難獲得很好的效果;如果兩個任務(wù)相關(guān)性比較高的話,其實(shí)我們可以通過共享參數(shù),達(dá)到把大訓(xùn)練數(shù)據(jù)任務(wù)的知識遷移給訓(xùn)練數(shù)據(jù)比較少的任務(wù)的目的,這樣可以極大提升訓(xùn)練數(shù)據(jù)量比較少的任務(wù)的效果。
Share-Bottom結(jié)構(gòu)是個非常典型的共享參數(shù)的多目標(biāo)優(yōu)化結(jié)構(gòu),核心思想是在比如網(wǎng)絡(luò)的底層參數(shù),所有任務(wù)共享參數(shù),而上層網(wǎng)絡(luò),不同任務(wù)各自維護(hù)自己獨(dú)有的一部分參數(shù),這樣就能達(dá)成通過共享參數(shù)實(shí)現(xiàn)知識遷移的目的。但是,Share-Bottom結(jié)構(gòu)有他的缺點(diǎn):如果兩個任務(wù)不那么相關(guān)的話,因?yàn)閺?qiáng)制共享參數(shù),所以可能任務(wù)之間相互干擾,會拉低不同目標(biāo)的效果。
MMOE針對Share-Bottom結(jié)構(gòu)的局限進(jìn)行了改進(jìn),核心思想也很簡單,就是把底層全部共享的參數(shù)切分成小的子網(wǎng)絡(luò),不同任務(wù)根據(jù)自己的特點(diǎn),學(xué)習(xí)配置不同權(quán)重的小網(wǎng)絡(luò)來進(jìn)行參數(shù)共享。這樣做的話,即使是兩個任務(wù)不太相關(guān),可以通過不同的配置來達(dá)到模型解耦的目的,而如果模型相關(guān)性強(qiáng),可以共享更多的子網(wǎng)絡(luò)。明顯這樣的組合方式更靈活,所以對于MMOE來說,無論是相關(guān)還是不相關(guān)的任務(wù),它都可以達(dá)到我們想要的效果。
上面介紹的是典型的不同多目標(biāo)的模型結(jié)構(gòu),各自有其適用場景和特點(diǎn)。而假設(shè)我們選定了模型結(jié)構(gòu),仍然存在一個很關(guān)鍵的問題:不同優(yōu)化目標(biāo)權(quán)重如何設(shè)定?當(dāng)然,我們可以根據(jù)業(yè)務(wù)要求,強(qiáng)制制定一些權(quán)重,比如視頻網(wǎng)站可能更重視時長或者完播率等指標(biāo),那就把這個目標(biāo)權(quán)重設(shè)置大一些。
但是,我們講過,有些任務(wù)之間的指標(biāo)優(yōu)化是負(fù)相關(guān)的,提升某個目標(biāo)的權(quán)重,有可能造成另外一些指標(biāo)的下跌。所以,如何設(shè)定不同目標(biāo)權(quán)重,能夠盡量減少相互之間的負(fù)面影響,就非常重要。這塊貌似目前并沒有特別簡單實(shí)用的方案,很多實(shí)際做法做起來還是根據(jù)經(jīng)驗(yàn)拍一些權(quán)重參數(shù)上線AB測試,費(fèi)時費(fèi)力。而如何用模型自動尋找最優(yōu)權(quán)重參數(shù)組合就是一個非常有價值的方向,目前最常用的方式是采用帕累托最優(yōu)的方案來進(jìn)行權(quán)重組合尋優(yōu),這是從經(jīng)濟(jì)學(xué)引入的技術(shù)方案,未來還有很大的發(fā)展空間.
典型工作
MMOE:Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
帕累托最優(yōu):A Pareto-Efficient Algorithm for Multiple Objective Optimization in E-Commerce Recommendation
所謂模態(tài),指的是不同類型的或者模態(tài)形式的信息存在形式,比如文本、圖片、視頻、音頻、互動行為、社交關(guān)系等,都是信息不同的存在模態(tài)形式。如果類比一下的話,就仿佛我們?nèi)祟惛兄澜纾彩怯貌煌母泄賮砀兄煌男畔㈩愋偷模热缫曈X、聽覺、味覺、觸覺等等,就是接受不同模態(tài)類型的信息,而大腦會把多模態(tài)信息進(jìn)行融合,來接受更全面更綜合的世界知識。類似的,如何讓機(jī)器學(xué)習(xí)模型能夠接受不同模態(tài)類型的信息,并做知識和信息互補(bǔ),更全面理解實(shí)體或者行為。這不僅僅是推薦領(lǐng)域的技術(shù)發(fā)現(xiàn)趨勢,也是人工智能幾乎所有方向都面臨的重大發(fā)展方向,所以這個方向特別值得重視。
多模態(tài)融合,從技術(shù)手段來說,本質(zhì)上是把不同模態(tài)類型的信息,通過比如Embedding編碼,映射到統(tǒng)一的語義空間內(nèi),使得不同模態(tài)的信息,表達(dá)相同語義的信息完全可類比。比如說自然語言說的單詞“蘋果”,和一張?zhí)O果的圖片,應(yīng)該通過一定的技術(shù)手段,對兩者進(jìn)行信息編碼,比如打出的embedding,相似度是很高的,這意味著不同模態(tài)的知識映射到了相同的語義空間了。這樣,你可以通過文本的蘋果,比如搜索包含蘋果的照片,諸如此類,可以玩出很多新花樣。
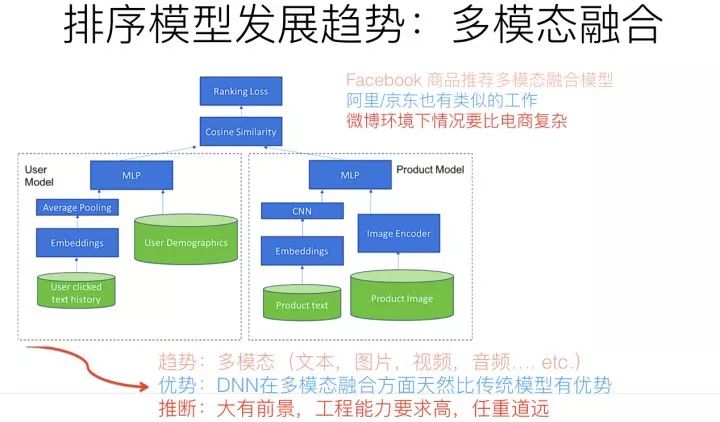
在推薦場景下,多模態(tài)融合其實(shí)不是個很有難度的算法方向,大的技術(shù)框架仍然遵循目前主流的技術(shù)框架,比如DNN Ranking。為了體現(xiàn)多模態(tài)集成的目標(biāo),可以在User側(cè)或者Item側(cè),把多模態(tài)信息作為新的特征融入,比如加入CNN特征抽取器,把商品圖片的特征抽取出來,作為商品側(cè)的一種新特征,不同模態(tài)的融入,很可能意味著找到對應(yīng)的特征抽取器,以新特征的方式融入,而有監(jiān)督學(xué)習(xí)的學(xué)習(xí)目標(biāo)會指導(dǎo)特征抽取器抽出那些有用的特征。
所以,你可以看到,如果在推薦里融入多模態(tài),從算法層面看,并不難,它的難點(diǎn)其實(shí)在它處;本質(zhì)上,多模態(tài)做推薦,如果說難點(diǎn)的話,難在工程效率。因?yàn)槟壳昂芏嗄B(tài)的信息抽取器,比如圖片的特征抽取,用深層ResNet或者ReceptionNet,效果都很好,但是因?yàn)榫W(wǎng)絡(luò)層深太深,抽取圖片特征的速度問題就是多模態(tài)落地面臨的主要問題。所以,本質(zhì)上,在推薦領(lǐng)域應(yīng)用多模態(tài),看上去其實(shí)是個工程效率問題,而非復(fù)雜的算法問題。而且,如果融合多模態(tài)的話,離開DNN模型,基本是不現(xiàn)實(shí)的。在這點(diǎn)上,可以比較充分體現(xiàn)DNN模型相對傳統(tǒng)模型的絕對技術(shù)優(yōu)勢。
多模態(tài)信息融合,不僅僅是排序端的一個發(fā)展方向,在召回側(cè)也是一樣的,比如用用戶點(diǎn)擊過的圖片,作為圖片類型的新召回路,或者作為模型召回的新特征。明顯這種多模態(tài)融合是貫穿了推薦領(lǐng)域各個技術(shù)環(huán)節(jié)的。
典型工作
DNN召回:Collaborative Multi-modal deep learning for the personalized product retrieval in Facebook Marketplace
排序:Image Matters: Visually modeling user behaviors using Advanced Model Server
對于推薦系統(tǒng)而言,準(zhǔn)確描述用戶興趣是非常重要的。目前常用的描述用戶興趣的方式主要有兩類。一類是以用戶側(cè)特征的角度來表征用戶興趣,也是最常見的;另外一類是以用戶發(fā)生過行為的物品序列作為用戶興趣的表征。
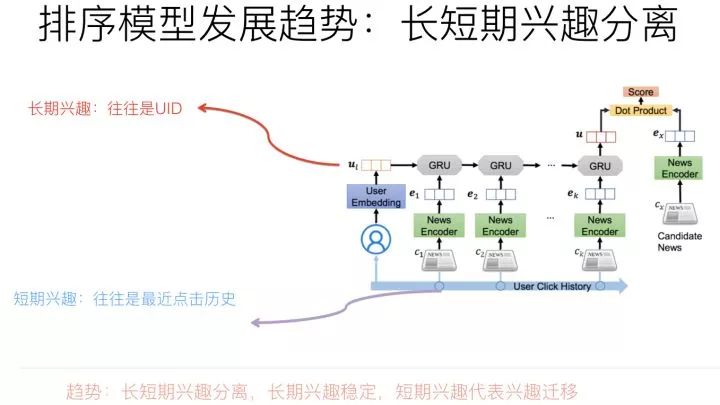
我們知道,用戶興趣其實(shí)是可以繼續(xù)細(xì)分的,一種典型的分法就是劃分為長期興趣和短期興趣。長期興趣代表用戶長久的比較穩(wěn)定的偏好;而短期興趣具有不斷變化等特點(diǎn)。兩者綜合,可以從穩(wěn)定性和變化性這個維度來表征用戶偏好。
最近推薦系統(tǒng)在排序側(cè)模型的演進(jìn)方向來說,把用戶長期興趣和短期興趣分離并各自建立模型是個技術(shù)小趨勢。
那么用什么信息作為用戶的短期興趣表征?什么信息作為用戶的長期興趣表征呢?各自又用什么模型來集成這些信息呢?這是這個趨勢的三個關(guān)鍵之處。
目前的常用做法是:用戶短期興趣往往使用用戶點(diǎn)擊(或購買,互動等其它行為類型)過的物品序列來表征,尤其對于比較活躍的用戶,用點(diǎn)擊序列更能體現(xiàn)短期的含義,因?yàn)槌鲇诠こ绦实目紤],如果用戶行為序列太長,往往不會都拿來使用,而是使用最近的K個行為序列中的物品,來表征用戶興趣,而這明顯更含有短期的含義;因?yàn)辄c(diǎn)擊序列具備序列性和時間屬性,所以對于這類數(shù)據(jù),用那些能夠刻畫序列特性或者物品局部相關(guān)性的模型比較合適,比如RNN/CNN和Transformer都比較適合用來對用戶短期興趣建模。
而用戶長期興趣如何表征呢?
我們換個角度來看,其實(shí)傳統(tǒng)的以特征作為用戶興趣表征的方法,其中部分特征就是從用戶長期興趣出發(fā)來刻畫的,比如群體人群屬性,是種間接刻畫用戶長期興趣的方法,再比如類似用戶興趣標(biāo)簽,是種用用戶行為序列物品的統(tǒng)計結(jié)果來表征用戶長期興趣的方法。這些方法當(dāng)然可以用來刻畫用戶長期興趣,但是往往粒度太粗,所以我們其實(shí)需要一個比較細(xì)致刻畫用戶長期興趣的方式和方法。
目前在對長短期興趣分離的工作中,關(guān)于如何刻畫用戶長期興趣,往往還是用非常簡單的方法,就是用UID特征來表征用戶的長期興趣,通過訓(xùn)練過程對UID進(jìn)行Embedding編碼,以此學(xué)習(xí)到的UID Embedding作為用戶長期興趣表征,而用戶行為序列物品作為用戶短期興趣表征。當(dāng)然,UID如果用一些其它手段比如矩陣分解獲得的Embedding初始化,也是很有幫助的。
總而言之,用戶長期興趣和短期興趣的分離建模,應(yīng)該還是有意義的。長期興趣目前建模方式還比較簡單,這里完全可以引入一些新方法來進(jìn)行進(jìn)一步的興趣刻畫,而且有很大的建模空間。
典型工作
1. Neural News Recommendation with Long- and Short-term User Representations
2. Sequence-Aware Recommendation with Long-Term and Short-Term Attention Memory Networks
https://zhuanlan.zhihu.com/p/100019681
