時(shí)隔一年,OpenAI 放出的預(yù)訓(xùn)練語(yǔ)言模型 GPT-3 再次讓人刮目相看。

「我們訓(xùn)練了 GPT-3,一種具有 1750 億參數(shù)的自回歸語(yǔ)言模型,這個(gè)數(shù)字比以往任何非稀疏語(yǔ)言模型都多 10 倍。我們?cè)?few-shot 情況下測(cè)試了它的性能。」本周五,OpenAI 提出的 GPT-3 在社交網(wǎng)絡(luò)上掀起了新一陣風(fēng)潮。它的參數(shù)量要比 2 月份剛剛推出的、全球最大深度學(xué)習(xí)模型 Turing NLP 大上十倍,而且不僅可以更好地答題、翻譯、寫(xiě)文章,還帶有一些數(shù)學(xué)計(jì)算的能力。這樣強(qiáng)大的深度學(xué)習(xí),不禁讓人產(chǎn)生一種錯(cuò)覺(jué):真正的 AI 要來(lái)了嗎?首先,GPT-3 最令人驚訝的還是模型體量,它使用的最大數(shù)據(jù)集在處理前容量達(dá)到了 45TB。根據(jù) OpenAI 的算力統(tǒng)計(jì)單位 petaflops/s-days,訓(xùn)練 AlphaGoZero 需要 1800-2000pfs-day,而 OpenAI 剛剛提出的 GPT-3 用了 3640pfs-day,看來(lái)擁有微軟無(wú)限算力的 OpenAI,現(xiàn)在真的是為所欲為了。研究者們希望 GPT-3 能夠成為更通用化的 NLP 模型,解決當(dāng)前 BERT 等模型的兩個(gè)不足之處:對(duì)領(lǐng)域內(nèi)有標(biāo)記數(shù)據(jù)的過(guò)分依賴,以及對(duì)于領(lǐng)域數(shù)據(jù)分布的過(guò)擬合。GPT-3 致力于能夠使用更少的特定領(lǐng)域,不做 fine-tuning 解決問(wèn)題。和往常一樣,GPT-3 立即放出了 GitHub 項(xiàng)目頁(yè)面,不過(guò)目前僅是一些生成樣本和數(shù)據(jù)集,還沒(méi)有代碼:https://github.com/openai/gpt-3。不過(guò)上傳的沒(méi)有那么快其實(shí)情有可原,在 issue 里有人道出了真相:參數(shù)這么多,如果按照 GPT-2 十五億參數(shù)等于 6G 這么算的話,GPT-3 模型可能要 700G,老硬盤還裝不下,不是正常人能玩的轉(zhuǎn)的。
2019 年 3 月機(jī)器學(xué)習(xí)先驅(qū),阿爾伯塔大學(xué)教授 Richard S. Sutton 著名的文章《苦澀的教訓(xùn)》里開(kāi)篇就曾說(shuō)道:「70 年的人工智能研究史告訴我們,利用計(jì)算能力的一般方法最終是最有效的方法。」GPT-3 的提出或許會(huì)讓開(kāi)發(fā)者落淚,大學(xué)老師沉默,黃仁勛感到肩上擔(dān)子更重了。還記得幾周前剛剛結(jié)束的 GTC 2020 嗎,英偉達(dá) CEO 的 Keynote 上有一頁(yè)講最近幾年來(lái)人工智能領(lǐng)域里最大的深度學(xué)習(xí)模型:
英偉達(dá)表示,自 2017 年底發(fā)布 Tesla V100 之后,訓(xùn)練最大模型的算力需求增長(zhǎng)了 3000 倍。在這里面 GPT-2 也不在最高的位置了,微軟今年 2 月推出的 Turing NLG(170 億參數(shù))、英偉達(dá)的 Megatron-BERT(80 億參數(shù))排名前列。GPT-3 要放進(jìn)這個(gè)表里,尺度表還要再向上挪一挪。
另有網(wǎng)友吐槽,GPT-3 共 72 頁(yè)的論文長(zhǎng)度也令人絕望:
下一次更大的模型,論文長(zhǎng)度怕不是要破百了。
不過(guò)巨大的參數(shù)量帶來(lái)的文本生成效果也是頗為可觀的,讓我們來(lái)看看 GPT-3 究竟能不能實(shí)現(xiàn)寫(xiě)新聞、寫(xiě)小說(shuō),甚至寫(xiě)論文的能力吧。GPT-3:我是 GPT-2 的「究極進(jìn)化版」2019 年初,OpenAI 發(fā)布了通用語(yǔ)言模型?GPT-2,能夠生成連貫的文本段落,在許多語(yǔ)言建模基準(zhǔn)上取得了 SOTA 性能。這一基于 Transformer 的大型語(yǔ)言模型共包含 15 億參數(shù)、在一個(gè) 800 萬(wàn)網(wǎng)頁(yè)數(shù)據(jù)集上訓(xùn)練而成。GPT-2 是對(duì) GPT 模型的直接擴(kuò)展,在超出 10 倍的數(shù)據(jù)量上進(jìn)行訓(xùn)練,參數(shù)量也多出了 10 倍。然而,長(zhǎng)江后浪推前浪。昨日,OpenAI 發(fā)布 GPT-3 模型,1750 億參數(shù)量,足足是 GPT-2 的 116 倍。GPT-3 的論文作者多達(dá) 31 人,來(lái)自 OpenAI、約翰霍普金斯大學(xué)的 Dario Amodei 等研究人員證明了在 GPT-3 中,對(duì)于所有任務(wù),模型無(wú)需進(jìn)行任何梯度更新或微調(diào),而僅通過(guò)與模型的文本交互指定任務(wù)和少量示例即可獲得很好的效果。GPT-3 在許多 NLP 數(shù)據(jù)集上均具有出色的性能,包括翻譯、問(wèn)答和文本填空任務(wù),這還包括一些需要即時(shí)推理或領(lǐng)域適應(yīng)的任務(wù),例如給一句話中的單詞替換成同義詞,或執(zhí)行 3 位數(shù)的數(shù)學(xué)運(yùn)算。當(dāng)然,GPT-3 也可以生成新聞報(bào)道的樣本,我們很難將機(jī)器寫(xiě)的文章與人類寫(xiě)的區(qū)分開(kāi)來(lái)。據(jù)《華盛頓郵報(bào)》報(bào)道,經(jīng)過(guò)兩天的激烈辯論,聯(lián)合衛(wèi)理公會(huì)同意了一次歷史性的分裂:要么創(chuàng)立新教派,要么則在神學(xué)和社會(huì)意義上走向保守。大部分參加五月份教會(huì)年度會(huì)議的代表投票贊成加強(qiáng)任命 LGBTQ 神職人員的禁令,并制定新的規(guī)則「懲戒」主持同性婚禮的神職人員。但是反對(duì)這些措施的人有一個(gè)新計(jì)劃:2020 年他們將形成一個(gè)新教派「基督教衛(wèi)理公會(huì)」。
《華盛頓郵報(bào)》指出,聯(lián)合衛(wèi)理公會(huì)是一個(gè)自稱擁有 1250 萬(wàn)會(huì)員的組織,在 20 世紀(jì)初期是「美國(guó)最大的新教教派」,但是近幾十年來(lái)它一直在萎縮。這次新的分裂將是該教會(huì)歷史上的第二次分裂。第一次發(fā)生在 1968 年,當(dāng)時(shí)大概只剩下 10% 的成員組成了「福音聯(lián)合弟兄會(huì)」。《華盛頓郵報(bào)》指出,目前提出的分裂「對(duì)于多年來(lái)成員不斷流失的聯(lián)合衛(wèi)理公會(huì)而言,來(lái)得正是時(shí)候」,這「在 LGBTQ 角色問(wèn)題上將該教派推向了分裂邊緣」。同性婚姻并不是分裂該教會(huì)的唯一問(wèn)題。2016 年,該教派因跨性別神職人員的任命而分裂。北太平洋地區(qū)會(huì)議投票禁止他們擔(dān)任神職人員,而南太平洋地區(qū)會(huì)議投票允許他們擔(dān)任神職人員。

這確定不是報(bào)刊記者撰寫(xiě)的短新聞嗎?給出標(biāo)題「聯(lián)合衛(wèi)理公會(huì)同意這一歷史性分裂」和子標(biāo)題「反對(duì)同性戀婚姻的人將創(chuàng)建自己的教派」,GPT-3 生成了上述新聞。
就問(wèn)你能不能看出來(lái)?反正我認(rèn)輸……
在 OpenAI 的測(cè)試中,人類評(píng)估人員也很難判斷出這篇新聞的真假,檢測(cè)準(zhǔn)確率僅為 12%。不過(guò),GPT-3 也有失手的時(shí)候。比如對(duì)于 GPT-3 生成的下列短文,人類判斷真?zhèn)蔚臏?zhǔn)確率達(dá)到了 61%!
根據(jù) OpenAI 的統(tǒng)計(jì),人類對(duì) GPT-3 175B 模型生成的約 500 詞文章的判斷準(zhǔn)確率為 52%,不過(guò)相比于 GPT-3 control 模型(沒(méi)有語(yǔ)境和不斷增加的輸出隨機(jī)性且只具備 1.6 億參數(shù)的模型),GPT-3 175B 生成的文本質(zhì)量要高得多。果然很暴力啊!
「牙牙學(xué)語(yǔ)」,GPT-3 的造句能力給出一個(gè)新單詞及其定義,造出一個(gè)新句子。難嗎?這需要你理解單詞的意義及適用語(yǔ)境。OpenAI 研究者測(cè)試了 GPT-3 在這一任務(wù)上的能力:給出一個(gè)不存在的單詞(如「Gigamuru」),令 GPT-3 使用它造句。我們來(lái)看 GPT-3 的生成結(jié)果:
給出新單詞「Gigamuru」(表示一種日本樂(lè)器)。GPT-3 給出的句子是:叔叔送了我一把 Gigamuru,我喜歡在家彈奏它。

GPT-3 造出的句子是:我們玩了幾分鐘擊劍,然后出門吃冰淇淋。
接下來(lái),我們?cè)賮?lái)看 GPT-3 的其他能力。給出一句帶有語(yǔ)法錯(cuò)誤的話,讓 GPT-3 進(jìn)行修改。

第一個(gè)例子中,原句里有兩個(gè)并列的動(dòng)詞「was」和「died」,GPT-3 刪除系動(dòng)詞「was」,將其修改為正確的句子。第二個(gè)例子中,原句里 likes 后的 ourselves 是 we 的反身代詞,而這里 like 這一動(dòng)作的執(zhí)行者是 Leslie,因此 likes 后即使要用反身代詞,也應(yīng)該是 himself,而另一個(gè)改法是將反身代詞改成 we 的賓格 us,即「我們認(rèn)為 Leslie 喜歡我們」。看完 GPT-3 的糾錯(cuò)效果,真是英語(yǔ)老師欣慰,學(xué)生慚愧……不止英語(yǔ)老師欣慰,數(shù)學(xué)老師也跑不了。GPT-3 可以執(zhí)行簡(jiǎn)單的計(jì)算。OpenAI 研究人員在以下 10 項(xiàng)任務(wù)中測(cè)試了 GPT-3 做簡(jiǎn)單計(jì)算的能力,且無(wú)需任何任務(wù)特定的訓(xùn)練。這十項(xiàng)任務(wù)分別是:兩位數(shù)加減法、三位數(shù)加減法、四位數(shù)加減法、五位數(shù)加減法、兩位數(shù)乘法,以及一位數(shù)混合運(yùn)算。
用于測(cè)試 GPT-3 計(jì)算能力的十項(xiàng)任務(wù)。
在這十項(xiàng)任務(wù)中,模型必須生成正確的答案。對(duì)于每項(xiàng)任務(wù),該研究生成包含 2000 個(gè)隨機(jī)實(shí)例的數(shù)據(jù)集,并在這些實(shí)例上評(píng)估所有模型。下圖展示了 GPT-3(few-shot)在這十項(xiàng)計(jì)算任務(wù)上的性能。從圖中可以看到,小模型的性能較差,即使是擁有 130 億參數(shù)的模型(僅次于擁有 1750 億的 GPT-3 完整版模型)處理二位數(shù)加減法的準(zhǔn)確率也只有 50% 左右,處理其他運(yùn)算的準(zhǔn)確率還不到 10%。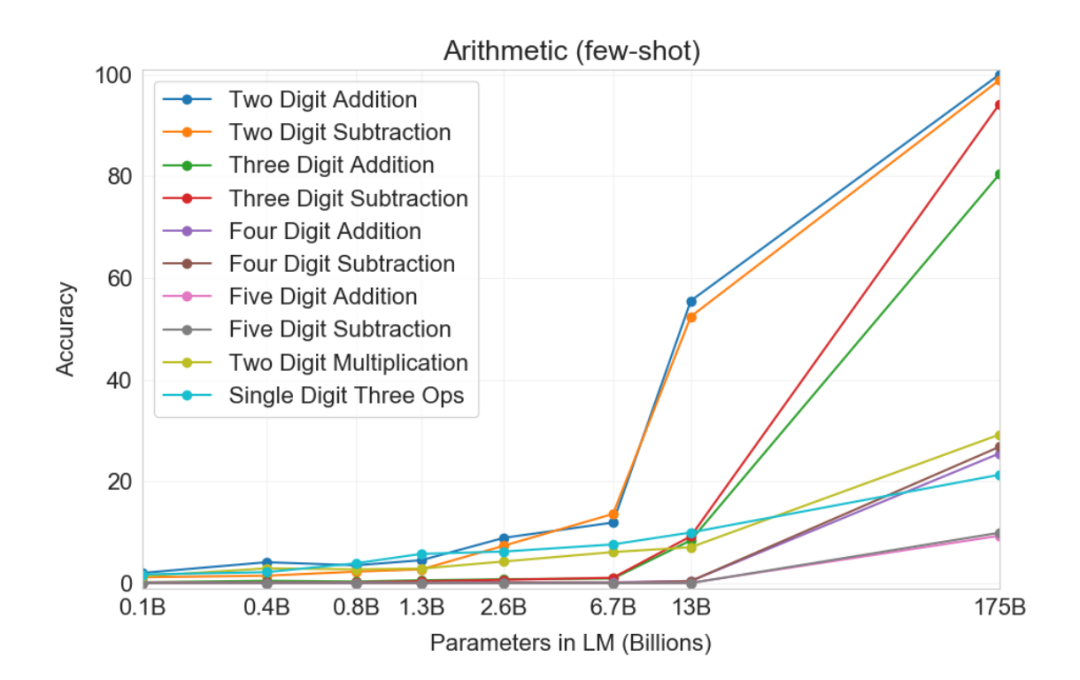
GPT-3 在多個(gè)語(yǔ)言建模任務(wù)中的表現(xiàn)GPT-2 發(fā)布時(shí)在多個(gè)領(lǐng)域特定的語(yǔ)言建模任務(wù)上實(shí)現(xiàn)了當(dāng)前最佳性能。現(xiàn)在,我們來(lái)看參數(shù)和成本大量增加后的 GPT-3 效果如何。OpenAI 在多項(xiàng)任務(wù)中對(duì) GPT-3 的性能進(jìn)行了測(cè)試,包括語(yǔ)言建模、補(bǔ)全、問(wèn)答、翻譯、常識(shí)推理、SuperGLUE 等任務(wù)。具體結(jié)果如下表所示: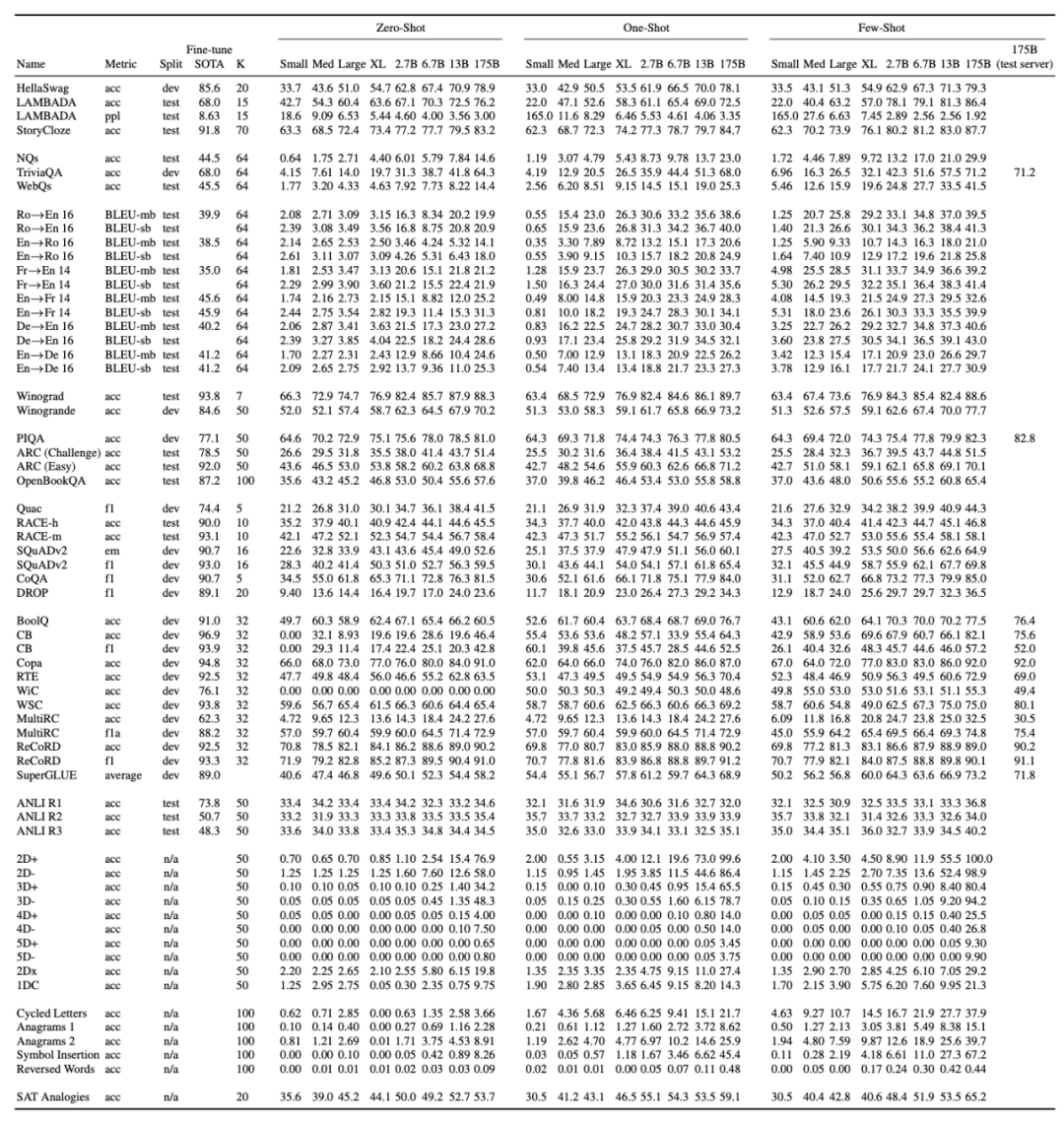
不同模型在所有任務(wù)上的性能,以及任務(wù)的 SOTA 性能(包括模型規(guī)模、訓(xùn)練細(xì)節(jié)等信息)。
近期大量研究工作表明,通過(guò)對(duì)大量文本進(jìn)行預(yù)訓(xùn)練,并且針對(duì)特定任務(wù)進(jìn)行微調(diào),模型的性能可以在許多 NLP 任務(wù)以及基準(zhǔn)測(cè)試中獲得顯著提升。最近,OpenAI 團(tuán)隊(duì)訓(xùn)練了 GPT-3(這是一個(gè)具有 1750 億參數(shù)的自回歸語(yǔ)言模型,參數(shù)量是之前任何非稀疏語(yǔ)言模型的 10 倍),并在少樣本(few-shot)環(huán)境下對(duì)其性能進(jìn)行了測(cè)試。在所有任務(wù)中,GPT-3 無(wú)需進(jìn)行任何額外的梯度更新或微調(diào),完全只通過(guò)模型與文本的交互,即可直接應(yīng)用于特定任務(wù)與少樣本 demo。GPT-3 在許多 NLP 數(shù)據(jù)集上均有出色的性能,包括翻譯、問(wèn)答和內(nèi)容填充任務(wù),以及多項(xiàng)需要實(shí)時(shí)推理或域適應(yīng)的任務(wù),如利用新單詞造句或執(zhí)行三位數(shù)運(yùn)算等。GPT-3 生成的新聞文章足以以假亂真,令人類評(píng)估員難以分辨。不過(guò),GPT-3 也有缺點(diǎn)。該研究團(tuán)隊(duì)發(fā)現(xiàn) GPT-3 (few-shot) 在文本合成和多個(gè) NLP 數(shù)據(jù)集上的性能不夠好,還存在一些結(jié)構(gòu)和算法上的缺陷。另一個(gè)語(yǔ)言模型大多會(huì)有的缺陷「預(yù)訓(xùn)練樣本效率較低」的問(wèn)題它也有,GPT-3 在預(yù)訓(xùn)練期間閱讀的文本比人一生讀的還要多。此外,還有可解釋性問(wèn)題等。OpenAI 團(tuán)隊(duì)使用的基礎(chǔ)預(yù)訓(xùn)練方法包括模型、數(shù)據(jù)與訓(xùn)練三部分。GPT-3 的訓(xùn)練過(guò)程與 GPT-2 類似,但對(duì)模型大小、數(shù)據(jù)集大小與多樣性、訓(xùn)練長(zhǎng)度都進(jìn)行了相對(duì)直接的擴(kuò)充。關(guān)于語(yǔ)境學(xué)習(xí),GPT-3 同樣使用了與 GPT-2 類似的方法,不過(guò) GPT-3 研究團(tuán)隊(duì)系統(tǒng)地探索了不同的語(yǔ)境學(xué)習(xí)設(shè)定。OpenAI 團(tuán)隊(duì)明確地定義了用于評(píng)估 GPT-3 的不同設(shè)定,包括 zero-shot、one-shot 和 few-shot。Fine-Tuning (FT):微調(diào)是近幾年來(lái)最為常用的方法,涉及在期望任務(wù)的特定數(shù)據(jù)集上更新經(jīng)過(guò)預(yù)訓(xùn)練模型的權(quán)重;
Few-Shot (FS):在該研究中指與 GPT-2 類似的,在推理階段為模型提供少量任務(wù)演示,但不允許更新網(wǎng)絡(luò)權(quán)重的情形;
One-Shot (1S):?jiǎn)螛颖九c小樣本類似,不同的是除了對(duì)任務(wù)的自然語(yǔ)言描述外,僅允許提供一個(gè)任務(wù)演示;
Zero-Shot (0S):零次樣本除了不允許有任何演示外與單樣本類似,僅為模型提供用于描述任務(wù)的自然語(yǔ)言指示。

zero-shot、one-shot、few-shot 設(shè)置與傳統(tǒng)微調(diào)方法的對(duì)比。上圖以英-法翻譯任務(wù)為例,展示了四種方法。該研究將重點(diǎn)放在 zero-shot、one-shot 和 few-shot 上,其目的并非將它們作為競(jìng)品進(jìn)行比較,而是作為不同的問(wèn)題設(shè)置。OpenAI 團(tuán)隊(duì)特別強(qiáng)調(diào)了 few-shot 結(jié)果,因?yàn)槠渲性S多結(jié)果僅僅略微遜色于 SOTA 微調(diào)模型。不過(guò),用 one-shot 甚至有時(shí)是 zero-shot 與人類水平進(jìn)行對(duì)比似乎最為公平,這也是未來(lái)工作的重要目標(biāo)之一。該研究使用了和 GPT-2 相同的模型和架構(gòu),包括改進(jìn)的初始設(shè)置、預(yù)歸一化和 reversible tokenization。區(qū)別在于 GPT-3 在 transformer 的各層上都使用了交替密集和局部帶狀稀疏的注意力模式,類似于 Sparse Transformer [CGRS19]。為了研究性能對(duì)模型大小的依賴性,該研究訓(xùn)練了?8 種不同的模型大小,涵蓋 3 個(gè)數(shù)量級(jí),從 1.25 億參數(shù)到 1750 億個(gè)參數(shù)不等,具備 1750 億個(gè)參數(shù)的模型即為 GPT-3。先前的研究 [KMH+20] 表明,在有足夠訓(xùn)練數(shù)據(jù)的情況下,驗(yàn)證損失的縮放比例應(yīng)該近似為模型大小的光滑冪律函數(shù)。這項(xiàng)研究訓(xùn)練了多個(gè)不同大小的模型,這使得研究者可以對(duì)驗(yàn)證損失和下游語(yǔ)言任務(wù)檢驗(yàn)該假設(shè)。表 2.1 展示了 8 個(gè)模型的大小和架構(gòu)。這里 n_params 表示可訓(xùn)練參數(shù)總量,n_layers 表示層數(shù),d_model 表示每個(gè)瓶頸層中的單元數(shù)量(在該研究中前饋層總是瓶頸層大小的 4 倍,即 d_ff = 4 ? d_model),d_head 表示每個(gè)注意力頭的維度。所有的模型均使用 n_ctx = 2048 tokens 的語(yǔ)境窗口。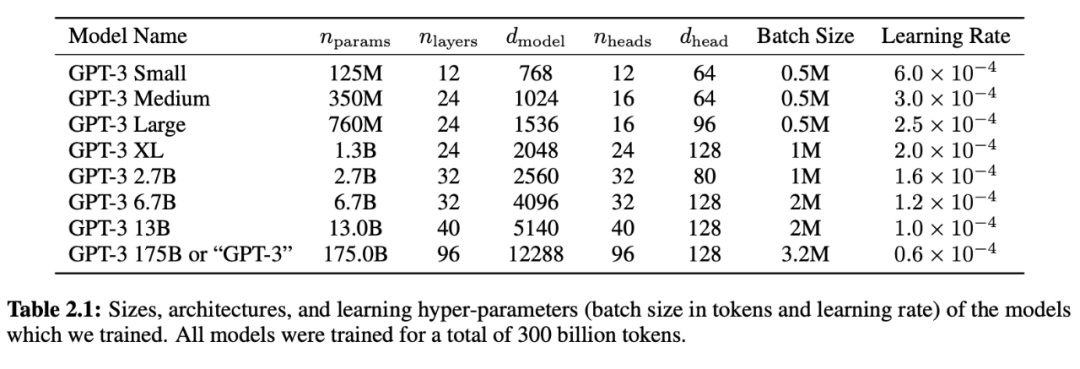
表 2.1:該研究所訓(xùn)練 8 個(gè)模型的大小、架構(gòu)和超參數(shù)信息。所有模型一共使用了 3000 億 token。為了最大程度地減少節(jié)點(diǎn)之間的數(shù)據(jù)傳輸,該研究從深度和寬度兩個(gè)方向進(jìn)行跨 GPU 模型分割。然后基于跨 GPU 模型布局的計(jì)算效率和負(fù)載平衡選擇每個(gè)模型精確的架構(gòu)參數(shù)。先前的研究 [KMH+20] 表明,在合理范圍內(nèi),驗(yàn)證損失對(duì)這些參數(shù)并不是特別敏感。下表介紹了 GPT-3 訓(xùn)練過(guò)程中所用的數(shù)據(jù)集。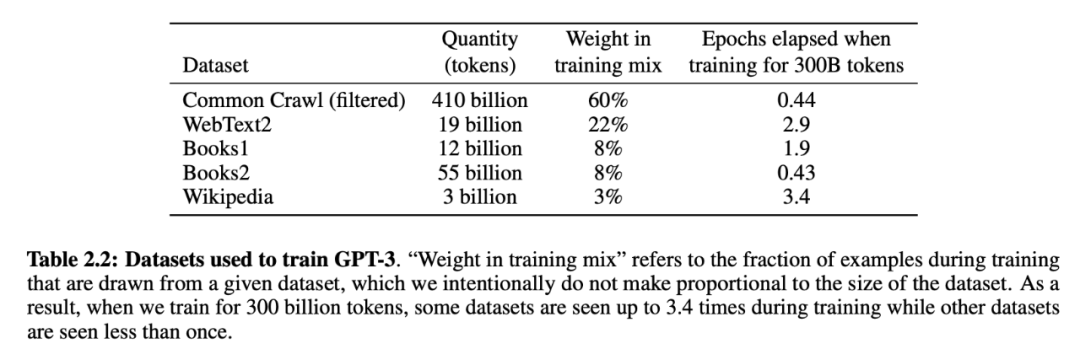
表 2.2:用于訓(xùn)練 GPT-3 的數(shù)據(jù)集。
OpenAI:其實(shí)我們也有點(diǎn)玩不起了最開(kāi)始是訓(xùn)練不動(dòng),后來(lái) finetune 不起,現(xiàn)在到了 GPT-3 模型的時(shí)代,我們連 forward 也要不起了。你肯定想問(wèn)這樣一個(gè)問(wèn)題:訓(xùn)練 GPT-3 模型需要花多少錢?我們目前還只能粗略地估計(jì)——訓(xùn)練一個(gè) BERT 模型租用云算力要花大概 6912 美元,訓(xùn)練 GPT-2 每小時(shí)要花費(fèi) 256 美元,但 OpenAI 一直沒(méi)有透露一共要花多少小時(shí)。相比之下,GPT-3 需要的算力(flops)是 BERT 的 1900 多倍,所以這個(gè)數(shù)字應(yīng)該是千萬(wàn)美元級(jí)別的,以至于研究者在論文第九頁(yè)說(shuō):我們發(fā)現(xiàn)了一個(gè) bug,但沒(méi)錢再去重新訓(xùn)練模型,所以先就這么算了吧。

GPT-3 的實(shí)驗(yàn)結(jié)果,似乎驗(yàn)證了 Richard Sutton 去年頗具爭(zhēng)議的論斷,他在《苦澀的教訓(xùn)》的最后寫(xiě)道:「我們應(yīng)該從苦澀的教訓(xùn)中學(xué)到一點(diǎn):通用方法非常強(qiáng)大,這類方法會(huì)隨著算力的增加而繼續(xù)擴(kuò)展,搜索和學(xué)習(xí)似乎正是這樣的方法。」關(guān)于 GPT-3 的更多詳情,參見(jiàn)論文:https://arxiv.org/abs/2005.14165另外,油管博主 Yannic Kilcher 做了一個(gè)?GPT-3?解讀視頻,emmm… 光視頻就有一個(gè)小時(shí),感興趣的讀者請(qǐng)戳:
來(lái)源:機(jī)器之心
本文版權(quán)歸原作者所有,如有問(wèn)題請(qǐng)聯(lián)系我刪除。

