
如何快速比對(duì)表格數(shù)據(jù)
最近在倒騰一些表格數(shù)據(jù),遇到這么個(gè)問(wèn)題:先前下載了一批數(shù)據(jù),等再次更新下載時(shí),數(shù)目卻變少了,我需要快速定位到缺失的條目并探究原因。
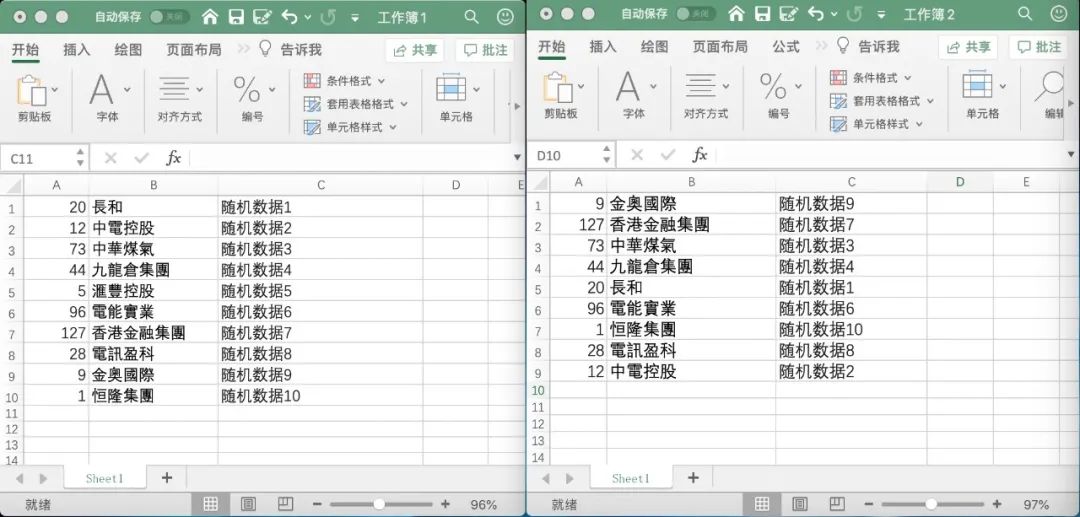
如圖,左側(cè) 10 條數(shù)據(jù)是先前下載的,右側(cè)少了 1 條(數(shù)據(jù)是隨便編的):

Python?操作
因?yàn)閷?duì) Excel 的函數(shù)操作不太熟,第一時(shí)間我是用 Python 來(lái)比對(duì)數(shù)據(jù)的:選取兩份表格中的 id 列,分別復(fù)制到兩份 txt 文檔中,轉(zhuǎn)化為 Python 讀取 txt 文檔數(shù)據(jù)、列表的相關(guān)操作問(wèn)題。
# 讀取兩文檔中的id數(shù)據(jù)with open("001.txt","r") as f:data1 = f.readlines()# data1 為 ['20\n', '12\n', '73\n', '44\n', '5\n', '96\n', '127\n', '28\n', '9\n', '1']with open("002.txt","r") as f:data2 = f.readlines()# data2 為 ['9\n', '127\n', '73\n', '44\n', '20\n', '96\n', '1\n', '28\n', '12']# 對(duì)讀取到的數(shù)據(jù)做下簡(jiǎn)單處理,去掉字符串中的換行符data1 = [x.strip() for x in data1 ]data2 = [y.strip() for y in data2 ]# 選取在 data1 中出現(xiàn)過(guò)、但 data2 中卻不包含的數(shù)據(jù)result = [i for i in data1 if i not in data2 ]print(result)# 得到結(jié)果 ['5']
根據(jù)得到的結(jié)果 5 定位到缺失的數(shù)據(jù)條目。
Excel 操作
拿到結(jié)果自然是心滿意足繼續(xù)干活了,閑下來(lái)想一般不會(huì)編程的文職人員會(huì)怎么解決這問(wèn)題呢?
經(jīng)過(guò)一番搜索,可以直接使用 Excel 的函數(shù)。首先隨便選定兩個(gè)表格中的同列數(shù)據(jù),放到一個(gè)表格中:

選擇 C1 處,輸入如下公式:
=IF(COUNTIF(B:B,A1)>0,"","少了")Excel 中 IF 函數(shù):=IF(條件判斷, 結(jié)果為真返回值, 結(jié)果為假返回值)
COUNTIF 函數(shù):=COUNTIF(條件區(qū)域,條件),返回滿足條件的單元格數(shù)目
對(duì) C1 處設(shè)置好函數(shù)后,鼠標(biāo)移到右下角,變成十字時(shí)點(diǎn)擊往下拖覆蓋到 C10,便可將該函數(shù)自動(dòng)設(shè)置到其它位置,最終得到結(jié)果。
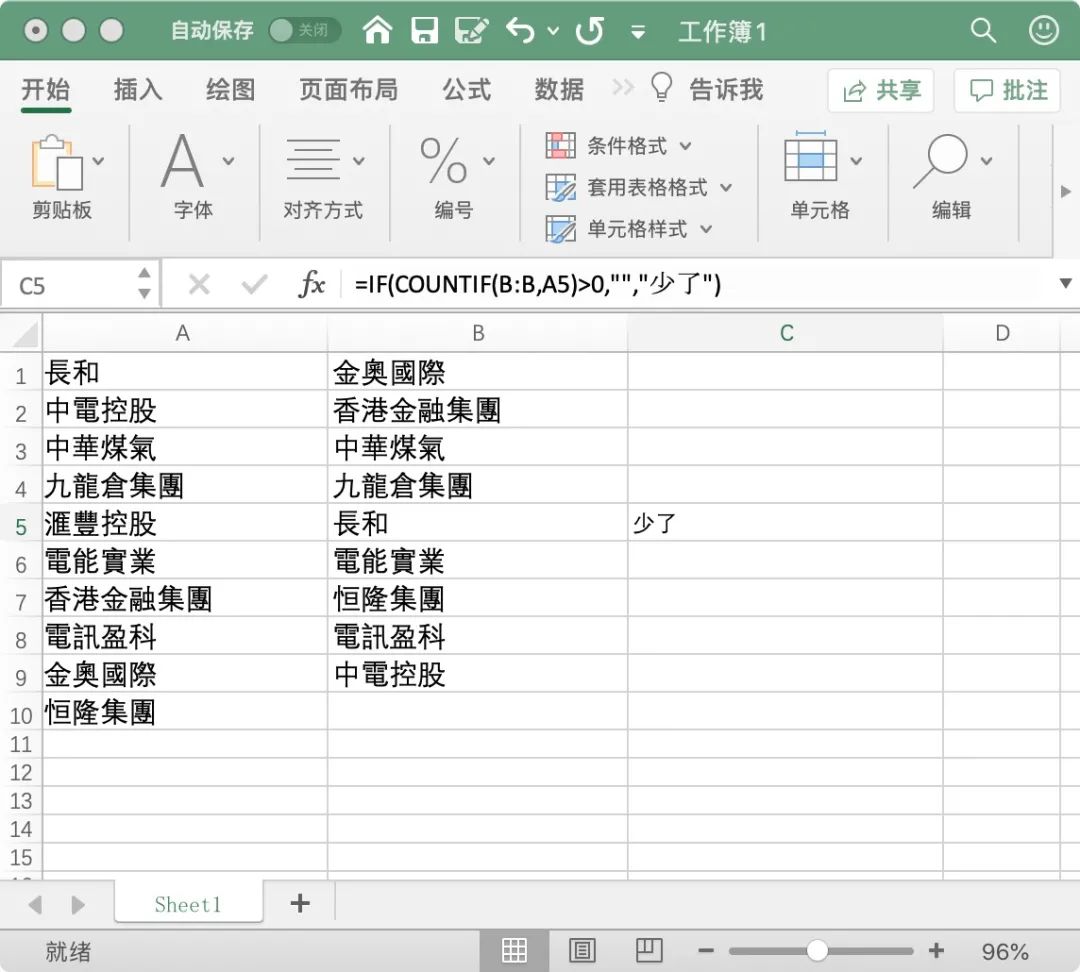
“少了”是自定義的提示信息,得到的結(jié)果與之前 Python 得出的 "5" 對(duì)應(yīng)的數(shù)據(jù)是一致的。

問(wèn)題不大,也挺簡(jiǎn)單,琢磨琢磨也挺有意思的。
兩種解法其實(shí)最后的邏輯是相同的,只不過(guò)體現(xiàn)在不同的程序和語(yǔ)言上。
解決問(wèn)題可能幾分鐘,整理記錄卻比較耗時(shí),希望能給看到的各位帶來(lái)點(diǎn)幫助吧~
往期推薦