本文4300字,建議閱讀8分鐘
展示梯度提升模型下表格數(shù)據(jù)中的數(shù)字和分類特征的各種編碼策略之間的基準(zhǔn)測(cè)試研究的結(jié)果。
為梯度提升學(xué)習(xí)選擇默認(rèn)的特征編碼策略需要考慮的兩個(gè)重要因素是訓(xùn)練時(shí)間和與特征表示相關(guān)的預(yù)測(cè)性能。Automunge庫(kù)是處理表格數(shù)據(jù)常用的庫(kù),它可以填充空值,也可以進(jìn)行分類的編碼和歸一化等操作,默認(rèn)的境況下Automunge對(duì)分類特征進(jìn)行二值化處理,并對(duì)數(shù)值特征進(jìn)行z-score歸一化。本文將通過(guò)對(duì)一系列不同數(shù)據(jù)集進(jìn)行基準(zhǔn)測(cè)試來(lái)驗(yàn)證這些默認(rèn)值是否是最優(yōu)化的選項(xiàng)。
長(zhǎng)期以來(lái)特征工程對(duì)深度學(xué)習(xí)應(yīng)用的有用性一直被認(rèn)為是一個(gè)已解決的否定問(wèn)題,因?yàn)樯窠?jīng)網(wǎng)絡(luò)本身就是通用函數(shù)逼近器(Goodfellow et al., 2016)。但是即使在深度學(xué)習(xí)的背景下,表格特征也經(jīng)常使用某種形式的編碼進(jìn)行預(yù)處理。Automunge (Teague, 2022a) 這個(gè) python 庫(kù)最初是為數(shù)字和分類特征的基本編碼而構(gòu)建的,例如 z-score 標(biāo)準(zhǔn)化和 one-hot 編碼。在迭代開(kāi)發(fā)過(guò)程中開(kāi)始加入了完整的編碼選項(xiàng)庫(kù),包括一系列數(shù)字和分類特征選項(xiàng),現(xiàn)在也包括自動(dòng)的規(guī)范化、二值化、散列和缺失數(shù)據(jù)填充場(chǎng)景。盡管這些編碼選項(xiàng)可能對(duì)于深度學(xué)習(xí)來(lái)說(shuō)是多余的,但這并不排除它們?cè)谄渌P椭械男в茫ê?jiǎn)單回歸、支持向量機(jī)、決策樹(shù)或本文的重點(diǎn)梯度提升模型。本文目的是展示梯度提升模型下表格數(shù)據(jù)中的數(shù)字和分類特征的各種編碼策略之間的基準(zhǔn)測(cè)試研究的結(jié)果。梯度提升
梯度提升 (Friedman, 2001) 是一種類似于隨機(jī)森林 (Briemen, 2001) 的決策樹(shù)學(xué)習(xí)范式 (Quinlan, 1986),通過(guò)遞歸訓(xùn)練迭代的目標(biāo)以糾正前一次迭代的性能來(lái)提升優(yōu)化模型。在實(shí)踐中一般都會(huì)使用 XGBoost 庫(kù) (Chen & Guestrin, 2016) 和 LightGBM (Ke et al, 2017) 來(lái)進(jìn)行建模。到目前為止梯度提升還是被認(rèn)為是 Kaggle 平臺(tái)上表格模態(tài)競(jìng)賽的獲勝解決方案,甚至在用于基于窗口的回歸時(shí),它的效率也在更復(fù)雜的應(yīng)用(如時(shí)間序列順序?qū)W習(xí))中得到證明(Elsayed ?,2022 ?) .最近的表格基準(zhǔn)測(cè)試論文中也說(shuō)明,梯度提升可能仍然在大多數(shù)情況下勝過(guò)復(fù)雜的神經(jīng)架構(gòu),如transformers (Gorishniy ?,2021)。傳統(tǒng)觀點(diǎn)認(rèn)為,對(duì)于表格應(yīng)用程序梯度提升模型具有比隨機(jī)森林更好的性能,但在沒(méi)有超參數(shù)調(diào)整的情況下會(huì)增加過(guò)度擬合的概率(Howard & Gugger,2020)。與隨機(jī)森林相比,梯度提升對(duì)調(diào)整參數(shù)的敏感性更高,并且運(yùn)行的參數(shù)數(shù)量更多,所以通常需要比簡(jiǎn)單的網(wǎng)格或隨機(jī)搜索更復(fù)雜的調(diào)整。這樣就出現(xiàn)了各種不同的超參數(shù)搜索的方法,例如一種可用的折衷方法是通過(guò)不同的參數(shù)子集進(jìn)行順序網(wǎng)格搜索(Jain,2016 ), Optuna 等黑盒優(yōu)化庫(kù)(Akiba ,2019 年)可以使用更自動(dòng)化甚至并行化的方法進(jìn)行超參數(shù)的搜索,這也是行業(yè)研究的一個(gè)活躍的方向。特征編碼
特征編碼是指用于為機(jī)器學(xué)習(xí)準(zhǔn)備數(shù)據(jù)的特征集轉(zhuǎn)換。特征編碼準(zhǔn)備的常見(jiàn)形式包括數(shù)字特征標(biāo)準(zhǔn)化和分類特征的編碼,盡管一些學(xué)習(xí)庫(kù)(catboost)可能接受字符串表示中的分類特征并進(jìn)行內(nèi)部編碼,但是手動(dòng)的進(jìn)行分類特征的轉(zhuǎn)換還是有必要的。在深度學(xué)習(xí)出現(xiàn)之前,通常使用提取信息的替代表示來(lái)補(bǔ)充特征或以某種方式進(jìn)行特征的組合來(lái)進(jìn)行特征的擴(kuò)充,這種特征工程對(duì)于梯度提升學(xué)習(xí)來(lái)說(shuō)還是可以繼續(xù)使用的。所以本文的這些基準(zhǔn)的目的之一是評(píng)估實(shí)踐與直接對(duì)數(shù)據(jù)進(jìn)行訓(xùn)練相比的好處。特征編碼的一個(gè)重要問(wèn)題就是需要領(lǐng)域知識(shí),例如基于填充數(shù)值分布派生的 bin 與基于外部數(shù)據(jù)庫(kù)查找提取 bin 來(lái)補(bǔ)充特征之間是否有很大的區(qū)別?在 Automunge 的情況下,內(nèi)部編碼庫(kù)的編碼基于固有的數(shù)字或字符串屬性,并且不考慮可以根據(jù)相關(guān)應(yīng)用程序域推斷出的相鄰屬性。(日期時(shí)間格式的功能例外,它在自動(dòng)化下自動(dòng)提取工作日、營(yíng)業(yè)時(shí)間、節(jié)假日等,并根據(jù)不同時(shí)間尺度的循環(huán)周期對(duì)條目進(jìn)行冗余編碼)數(shù)字特征
數(shù)值標(biāo)準(zhǔn)化在實(shí)踐中最常被使用的,例如z-score。在實(shí)踐中可能發(fā)現(xiàn)的其他變化包括mean scaling 和max scaling 。更復(fù)雜的約定可以轉(zhuǎn)換除尺度之外的分布形狀,例如 box-cox 冪律變換(Box & Cox, 1964) 或Scikit-Learn 的分位數(shù)轉(zhuǎn)換器qttf(Pedregosa ,2011),都可以將特征轉(zhuǎn)換成一個(gè)更像高斯分布的特性集。數(shù)字歸一化更常用于線性模型,而不是樹(shù)的模型,例如在神經(jīng)網(wǎng)絡(luò)中,它們的目的是跨特征進(jìn)行歸一化梯度更新,應(yīng)用于數(shù)值特征的標(biāo)準(zhǔn)化類型似乎會(huì)影響性能。
分類特征
分類編碼通常在實(shí)踐中使用獨(dú)熱編碼進(jìn)行轉(zhuǎn)換,這種熱編碼的做法在高基數(shù)情況下存在缺陷(分類很多導(dǎo)致生成的特征多并且離散),梯度提升模型中分類標(biāo)簽過(guò)多時(shí)甚至可能導(dǎo)致訓(xùn)練超過(guò)內(nèi)存限制。Automunge 庫(kù)試圖以兩種方式規(guī)避這種高基數(shù)邊緣情況,首先是默認(rèn)使用二值化編碼而不是獨(dú)熱編碼,其次是通過(guò)區(qū)分哈希編碼的最高基數(shù)集(Teague,2020a),減少唯一條目的數(shù)量。分類二值化是可以理解為將模擬信號(hào)轉(zhuǎn)換成數(shù)字信號(hào)過(guò)程中的量化,返回特征中每一個(gè)byte位代表是否屬于該類分類表示的第三種常見(jiàn)編碼方式是標(biāo)簽編碼,他將分類表示為一個(gè)連續(xù)的數(shù)值型變量。
基準(zhǔn)基準(zhǔn)
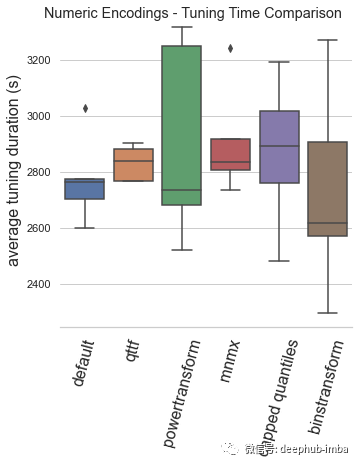
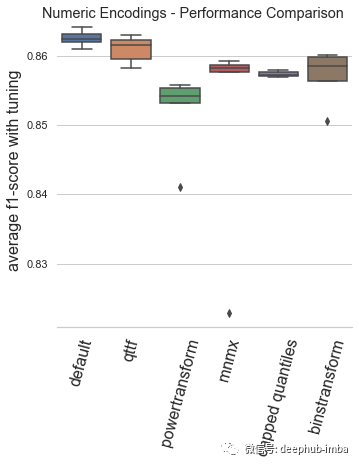
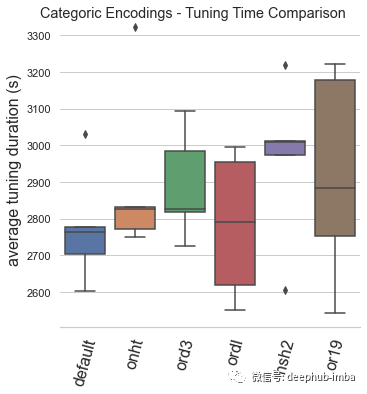
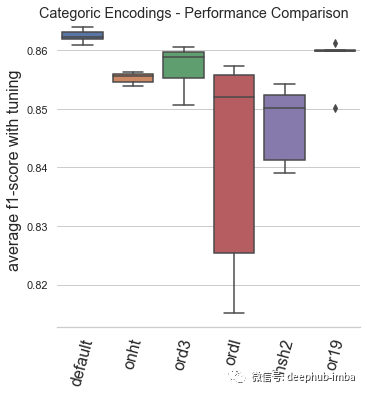
本文的基準(zhǔn)測(cè)試是通過(guò)訓(xùn)練時(shí)間和模型性能這兩個(gè)關(guān)鍵性能指標(biāo)來(lái)評(píng)估一系列數(shù)字和分類編碼場(chǎng)景。在配備 AMD 3970X 處理器、128Gb RAM 和兩個(gè) Nvidia 3080 GPU 的 Lambda 工作站上進(jìn)行了約 1.5 周的測(cè)試。訓(xùn)練是通過(guò) Optuna 調(diào)整的 XGBoost 進(jìn)行的,具有 ?5-fold快速交叉驗(yàn)證 (Swersky et al, 2013) 和 如果33 次調(diào)整迭代沒(méi)有改進(jìn)則停止訓(xùn)練。性能指標(biāo)是對(duì)25% 驗(yàn)證集進(jìn)行根據(jù) f1 分?jǐn)?shù)評(píng)估進(jìn)行的。以上是對(duì)分類任務(wù)的偏差和方差性能進(jìn)行平衡評(píng)估的良好默認(rèn)設(shè)置(Stevens ?,2020 )。在來(lái)自 OpenML 基準(zhǔn)測(cè)試庫(kù)(Vanschoren ?,2013)的 31 個(gè)表格分類數(shù)據(jù)集上循環(huán) 5 次并取平均值。報(bào)告的指標(biāo)是上面說(shuō)提到的每種編碼類型的 31 個(gè)數(shù)據(jù)集的 5 次重復(fù)的平均值,這些編碼類型都使用了所有用于訓(xùn)練的數(shù)字或分類特征。default:Automunge 的默認(rèn)值使用 z 分?jǐn)?shù)規(guī)范化(庫(kù)中的“nmbr”代碼)從調(diào)整持續(xù)時(shí)間和模型性能的角度來(lái)看,默認(rèn)編碼已被驗(yàn)證為平均表現(xiàn)最佳的場(chǎng)景。qttf:具有正態(tài)輸出分布的 Scikit-Learn QuantileTransformer,分位數(shù)分布轉(zhuǎn)換的平均表現(xiàn)不如簡(jiǎn)單的 z 分?jǐn)?shù)歸一化,盡管它仍然是表現(xiàn)最好的。powertransform:根據(jù)分布屬性在“bxcx”、“mmmx”或“MAD3”之間有條件地編碼(通過(guò)Automunge 庫(kù)的 powertransform = True 設(shè)置),這是效果最差的場(chǎng)景。mmmx:min max scaling 'mnmx' 將特征分布轉(zhuǎn)移到 0-1 范圍內(nèi),這種情況的表現(xiàn)比 z-score 歸一化差得多,這可能是由于異常值導(dǎo)致數(shù)據(jù)在編碼空間中“擠在一起”的情況。capped quantiles:min max scaling with capped outliers at 0.99 and 0.01 quantiles ('mnm3' code in library),這種情況最好直接與mmmx進(jìn)行比較,表明了默認(rèn)設(shè)置異常值上限并不能提高平均性能。binstransform:z-score 歸一化再加上以 5 個(gè)獨(dú)熱編碼標(biāo)準(zhǔn)偏差箱(通過(guò)庫(kù)的 binstransform = True 設(shè)置),這個(gè)配置除了增加了訓(xùn)練時(shí)間以外,似乎對(duì)模型性能沒(méi)有好處。default:Automunge 的默認(rèn)值是分類二值化(庫(kù)中的“1010”代碼),從調(diào)整持續(xù)時(shí)間和模型性能的角度來(lái)看,默認(rèn)編碼已被驗(yàn)證為最好的。onht:獨(dú)熱編碼,這通常用作主流實(shí)踐中的默認(rèn)值,與二值化相比,模型性能影響出人意料地不好。基于這個(gè)測(cè)試,建議在特殊用例之外(例如,出于特征重要性分析的目的)停止使用 one-hot 編碼。ord3:具有按分類頻率“ord3”排序的整數(shù)的序數(shù)編碼,按類別頻率而不是字母順序?qū)π驍?shù)整數(shù)進(jìn)行排序顯著有益于模型性能,在大多數(shù)情況下,表現(xiàn)比獨(dú)熱編碼好,但是仍然不如二值化。ordl:“ordl”按字母順序排序的整數(shù)的序數(shù)編碼,字母排序的序數(shù)編碼(Scikit-Learn 的 OrdinalEncoder 的默認(rèn)值)表現(xiàn)不佳,建議在應(yīng)用序數(shù)時(shí)默認(rèn)為頻率排序的整數(shù)。hsh2:散列序號(hào)編碼(高基數(shù)類別“hsh2”的庫(kù)默認(rèn)值),該基準(zhǔn)主要用于參考,由于某些類別可能會(huì)合并,因此會(huì)對(duì)低基數(shù)集產(chǎn)生性能影響。or19:多層字符串解析“or19”(Teague,2020b),多層字符串解析成功地超越了單熱編碼,并且是第二好的表現(xiàn),但與普通二值化相比,它的性能不足以推薦默認(rèn)值。如果應(yīng)用程序可能具有與語(yǔ)法內(nèi)容相關(guān)的某些擴(kuò)展結(jié)構(gòu)的情況下可以試試。總結(jié)
從訓(xùn)練時(shí)間和模型性能的角度來(lái)看, Automunge 庫(kù)的 z-score 歸一化和分類二值化在測(cè)試中都表現(xiàn)了出了很好的效果,所以如果你在處理表格數(shù)據(jù)的時(shí)候可以優(yōu)先使用 Automunge 的默認(rèn)值進(jìn)行特征的處理,如果你想自己處理特征,那么z-score 歸一化和分類二值化也是首先可以考慮的方法。基準(zhǔn)測(cè)試包括以下表格數(shù)據(jù)集,此處顯示了它們的 OpenML ID 號(hào):
Click prediction / 233146
C.C.FraudD. / 233143
sylvine / 233135
jasmine / 233134
fabert / 233133
APSFailure / 233130
MiniBooNE / 233126
volkert / 233124
jannis / 233123
numerai28.6 / 233120
Jungle-Chess-2pcs / 233119
segment / 233117
car / 233116
Australian / 233115
higgs / 233114
shuttle / 233113
connect-4 / 233112
bank-marketing / 233110
blood-transfusion / 233109
nomao / 233107
ldpa / 233106
skin-segmentation / 233104
phoneme / 233103
walking-activity / 233102
adult / 233099
kc1 / 233096
vehicle / 233094
credit-g / 233088
mfeat-factors / 233093
arrhythmia / 233092
kr-vs-kp / 233091
Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In KDD. (2019). URL https://optuna.org/#paper.
Box, G. E. P., and Cox, D. R. An analysis of transformations. Journal of the Royal Statistical Society: Series B (Methodological), 26(2):211–243, (1964). https://www.jstor.org/stable/2984418.
Breiman, L. Random Forests. Machine Learning 45, 5–32 (2001). https://doi.org/10.1023/A:1010933404324.
Chen, T. and Guestrin, C., XGBoost: A Scalable Tree Boosting System. (2016). https://arxiv.org/abs/1603.02754.
Elsayed, S., Thyssens, D., Rashed, A., Samer Jomaa, H., and Schmidt-Thieme, L., Do We Really Need Deep Learning Models for Time Series Forecasting? (2021). https://arxiv.org/abs/2101.02118.
Friedman, J. H. Greedy function approximation: A gradient boosting machine. The Annals of Statistics, 29(5) 1189–1232 (October 2001). https://doi.org/10.1214/aos/1013203451.
Goodfellow, I. J., Bengio, Y., and Courville, A. *Deep Learning*. MIT Press, Cambridge, MA, USA, (2016). http://www.deeplearningbook.org.
Gorishniy, Y., Rubachev, I., Khrulkov, V., and Babenko, A., Revisiting Deep Learning Models for Tabular Data. Advances in Neural Information Processing Systems, volume 30.?
Curran Associates, Inc. (2021). URL https://openreview.net/forum?id=i_Q1yrOegLY.
Howard, J. and Gugger, S. *Deep Learning for Coders with fastai and PyTorch*. O’Reilly Media, 2020. https://www.oreilly.com/library/view/deep-learning-for/9781492045519/.
Jain, A. Complete Guide to Parameter Tuning in XGBoost with codes in Python. Analytics Vidhya (2016). https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/.
Kadra, A., Lindauer, M., Hutter, F., and Grabocka, J. Well-tuned simple nets excel on tabular datasets. In Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W. (eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=d3k38LTDCyO.
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., and Liu, T. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc. (2020). URL https://proceedings.neurips.cc/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf.
London, I. Encoding cyclical continuous features — 24-hour time. (2016) URL https://ianlondon.github.io/blog/encoding-cyclical-features-24hour-time/
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., ?Blondel, M.,?
Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., ?Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, E., Scikit-learn: Machine Learning in Python, JMLR 12, pp. 2825–2830, (2011). https://www.jmlr.org/papers/v12/pedregosa11a.html.
Quinlan, J. R. Induction of Decision Trees. Mach. Learn. 1, 1, 81–106 (March 1986). https://doi.org/10.1023/A:1022643204877.
Ravi, Rakesh. One-Hot Encoding is making your Tree-Based Ensembles worse, here’s why? Towards Data Science, (January 2019). https://towardsdatascience.com/one-hot-encoding-is-making-your-tree-based-ensembles-worse-heres-why-d64b282b5769.
Stevens, E., Antiga, L., Viehmann, T. *Deep Learning with PyTorch*. Manning Publications, (2020). https://www.manning.com/books/deep-learning-with-pytorch.
Swersky, K. and Snoek, J. and Adams, R. P., Multi-Task Bayesian Optimization. Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc. (2013). URL https://proceedings.neurips.cc/paper/2013/file/f33ba15effa5c10e873bf3842afb46a6-Paper.pdf.
Teague, N. Automunge code repository, documentation, and tutorials, (2022). URL https://github.com/Automunge/AutoMunge.
Teague, N. Custom Transformations with Automunge. (2021). URL https://medium.com/automunge/custom-transformations-with-automunge-ae694c635a7e
Teague, N. Hashed Categoric Encodings with Automunge (2020a) https://medium.com/automunge/hashed-categoric-encodings-with-automunge-92c0c4b7668c.
Teague, N. Parsed Categoric Encodings with Automunge. (2020b) https://medium.com/automunge/string-theory-acbd208eb8ca.
Vanschoren, J., van Rijn, J. N., Bischl, B., and Torgo, L. OpenML: networked science in machine learning. SIGKDD Explorations 15(2), pp 49–60, (2013). https://arxiv.org/abs/1407.7722