5個十分高效的pandas函數(shù)!
熟練掌握pandas函數(shù)都能幫我們在數(shù)據(jù)分析過程中節(jié)省時間。pandas還有很多讓人舒適的用法,這次就為大家介紹5個pandas函數(shù)!
本文來源towardsdatascience,作者Soner Y?ld?r?m,由Python大數(shù)據(jù)分析編譯。
1. explode
explode用于將一行數(shù)據(jù)展開成多行。比如說dataframe中某一行其中一個元素包含多個同類型的數(shù)據(jù),若想要展開成多行進行分析,這時候explode就派上用場,而且只需一行代碼,非常節(jié)省時間。
用法:
DataFrame.explode(self,?column:?Union[str,?Tuple])
參數(shù)作用:
column :str或tuple
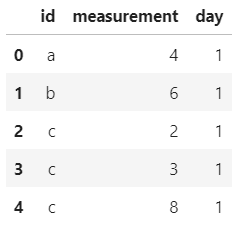
以下表中第三行、第二列為例,展開[2,3,8]:
#?先創(chuàng)建表
id?=?['a','b','c']
measurement?=?[4,6,[2,3,8]]
day?=?[1,1,1]
df1?=?pd.DataFrame({'id':id,?'measurement':measurement,?'day':day})
df1

使用explode輕松將[2,3,8]轉(zhuǎn)換成多行,且行內(nèi)其他元素保持不變。
df1.explode('measurement').reset_index(drop=True)
2. Nunique
Nunique用于計算行或列上唯一值的數(shù)量,即去重后計數(shù)。這個函數(shù)在分類問題中非常實用,當不知道某字段中有多少類元素時,Nunique能快速生成結(jié)果。
用法:
Series.nunique(dropna=True)
#?或者
DataFrame.nunique(axis=0,?dropna=True)
參數(shù)作用:
axis:int型,0代表行,1代表列,默認0; dropna:bool類型,默認為True,計數(shù)中不包括NaN;
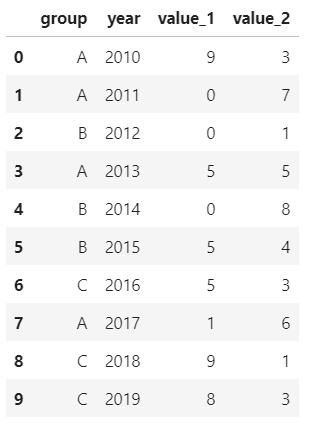
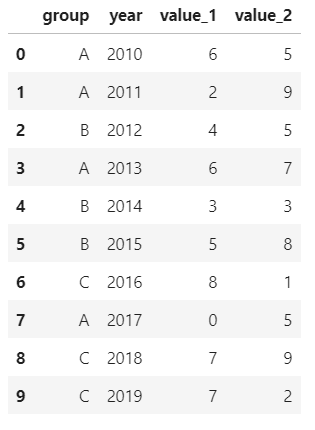
先創(chuàng)建一個df:
values_1?=?np.random.randint(10,?size=10)
values_2?=?np.random.randint(10,?size=10)
years?=?np.arange(2010,2020)
groups?=?['A','A','B','A','B','B','C','A','C','C']
df?=?pd.DataFrame({'group':groups,?'year':years,?'value_1':values_1,?'value_2':values_2})
df
對year列進行唯一值計數(shù):
df.year.nunique()
輸出:10 對整個dataframe的每一個字段進行唯一值計數(shù):
df.nunique()

3. infer_objects
infer_objects用于將object類型列推斷為更合適的數(shù)據(jù)類型。
用法:
#?直接將df或者series推斷為合適的數(shù)據(jù)類型
DataFrame.infer_objects()
pandas支持多種數(shù)據(jù)類型,其中之一是object類型。object類型包括字符串和混合值(數(shù)字及非數(shù)字)。
object類型比較寬泛,如果可以確定為具體數(shù)據(jù)類型,則不建議用object。
df?=?pd.DataFrame({"A":?["a",?1,?2,?3]})
df?=?df.iloc[1:]
df

df.dtypes

使用infer_objects方法將object推斷為int類型:
df.infer_objects().dtypes

4. memory_usage
memory_usage用于計算dataframe每一列的字節(jié)存儲大小,這對于大數(shù)據(jù)表非常有用。
用法:
DataFrame.memory_usage(index=True,?deep=False)
參數(shù)解釋:index:指定是否返回df中索引字節(jié)大小,默認為True,返回的第一行即是索引的內(nèi)存使用情況;deep:如果為True,則通過查詢object類型進行系統(tǒng)級內(nèi)存消耗來深入地檢查數(shù)據(jù),并將其包括在返回值中。
首先創(chuàng)建一個df,共2列,1000000行。
df_large?=?pd.DataFrame({'A':?np.random.randn(1000000),
????????????????????'B':?np.random.randint(100,?size=1000000)})
df_large.shape
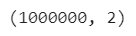
返回每一列的占用字節(jié)大小:
df_large.memory_usage()

第一行是索引index的內(nèi)存情況,其余是各列的內(nèi)存情況。
5. replace
顧名思義,replace是用來替換df中的值,賦以新的值。
用法:
DataFrame.replace(to_replace=None,?value=None,?inplace=False,?limit=None,?regex=False,?method='pad')
參數(shù)解釋:
to_replace:被替換的值 value:替換后的值 inplace:是否要改變原數(shù)據(jù),F(xiàn)alse是不改變,True是改變,默認是False limit:控制填充次數(shù) regex:是否使用正則,False是不使用,True是使用,默認是False method:填充方式,pad,ffill,bfill分別是向前、向前、向后填充
創(chuàng)建一個df:
values_1?=?np.random.randint(10,?size=10)
values_2?=?np.random.randint(10,?size=10)
years?=?np.arange(2010,2020)
groups?=?['A','A','B','A','B','B','C','A','C','C']
df?=?pd.DataFrame({'group':groups,?'year':years,?'value_1':values_1,?'value_2':values_2})
df
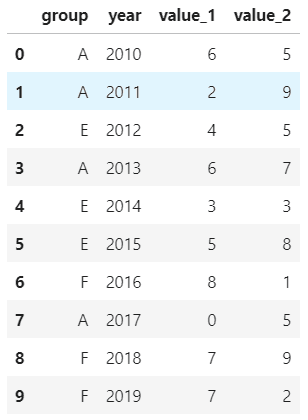
將A全部替換為D:
df.replace('A','D')
將B替換為E,C替換為F:
df.replace({'B':'E','C':'F'})