
最簡單的爬蟲:用Pandas爬取表格數(shù)據(jù)

有一說一,咱得先承認,用Pandas爬取表格數(shù)據(jù)有一定的局限性。
它只適合抓取Table表格型數(shù)據(jù),那咱們先看看什么樣的網(wǎng)頁滿足條件?
什么樣的網(wǎng)頁結構?
用瀏覽器打開網(wǎng)頁,F(xiàn)12查看其HTML的結構,會發(fā)現(xiàn)符合條件的網(wǎng)頁結構都有個共同的特點。
如果你發(fā)現(xiàn)HTML結構是下面這個Table格式的,那直接可以用Pandas上手。
"..."?id="...">
?????
?????
?????...
?????
?????
?????
????????
????????????...
????????
????????...
????????...
????????...
????????...
????????...
????
這個看著不直觀,打開一個北京地區(qū)空氣質量網(wǎng)站。
F12,左側是網(wǎng)頁中的質量指數(shù)表格,它的網(wǎng)頁結構完美符合了Table表格型數(shù)據(jù)網(wǎng)頁結構。
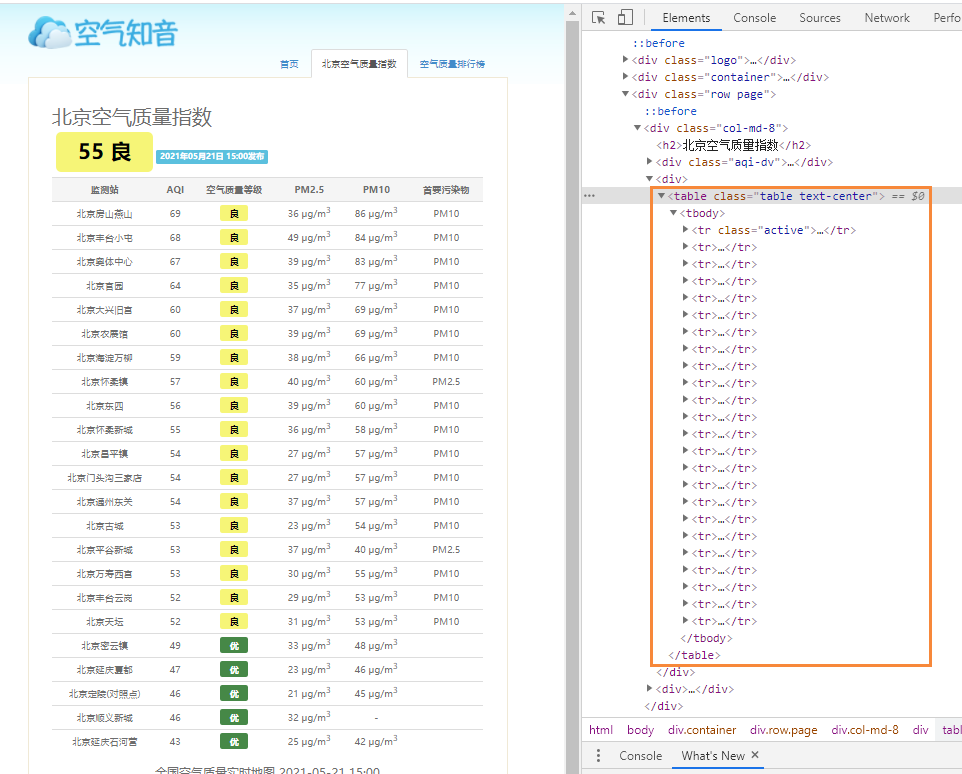
它就非常適合使用pandas來爬取。
pd.read_html()
Pandas提供read_html(),to_html()兩個函數(shù)用于讀寫html格式的文件。這兩個函數(shù)非常有用,一個輕松將DataFrame等復雜的數(shù)據(jù)結構轉換成HTML表格;另一個不用復雜爬蟲,簡單幾行代碼即可抓取Table表格型數(shù)據(jù),簡直是個神器![1]
具體的pd.read_html()參數(shù),可以查看其官方文檔:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_html.html
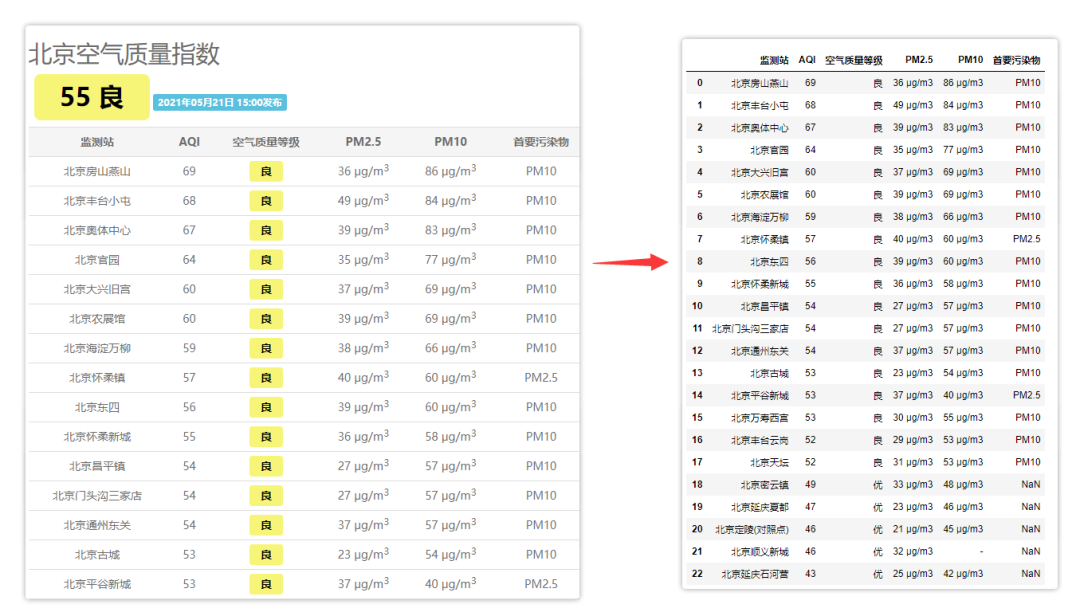
下面直接拿剛才的網(wǎng)頁直接上手開大!
import?pandas?as?pd
df?=?pd.read_html("http://www.air-level.com/air/beijing/",?encoding='utf-8',header=0)[0]
這里只加了幾個參數(shù),header是指定列標題所在的行。加上導包,只需兩行代碼。
df.head()
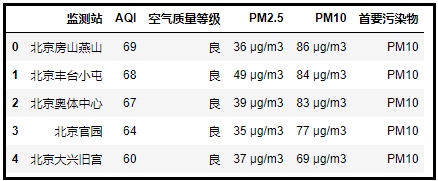
對比結果,可以看到成功獲取了表格數(shù)據(jù)。
多個表格
上一個案例中,不知道有小伙伴注意到?jīng)]有
pd.read_html()[0]
對于pd.read_html()獲取網(wǎng)頁結果后,還加了一個[0]。這是因為網(wǎng)頁上可能存在多個表格,這時候就需要靠列表的切片tables[x]來指定獲取哪個表格。
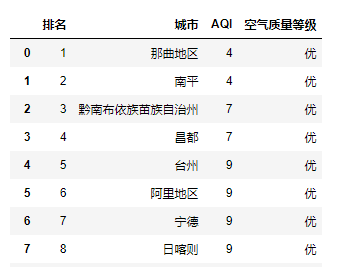
比如還是剛才的網(wǎng)站,空氣質量排行榜網(wǎng)頁就明顯由兩個表格構成的。
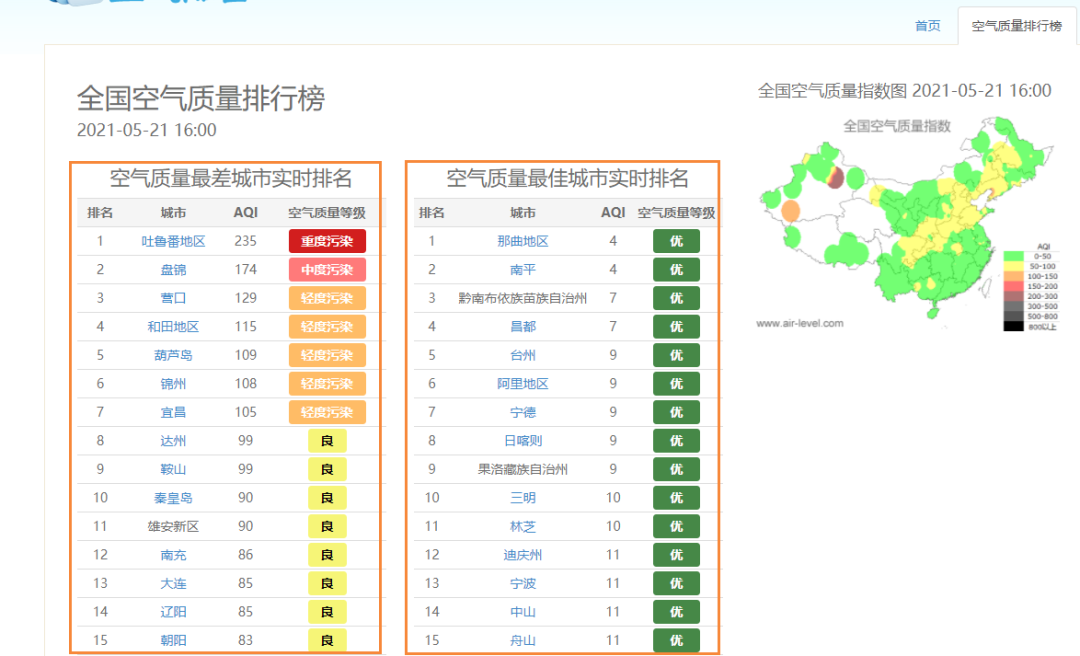
這時候如果用pd.read_html()來獲取右邊的表格,只需要稍微修改即可。
import?pandas?as?pd
df?=?pd.read_html("http://www.air-level.com/rank",?encoding='utf-8',header=0)[1]
對比之下,可以看到成功獲取到了網(wǎng)頁右側的表格。
以上就是用pd.read_html()來簡單爬取靜態(tài)網(wǎng)頁。但是我們之所以使用Python,其實是為了提高效率。可是若僅僅一個網(wǎng)頁,鼠標選擇復制豈不是更簡單。所以Python操作最大的優(yōu)點會體現(xiàn)在批量操作上。
批量爬取
下面給大家展示一下,如何用Pandas批量爬取網(wǎng)頁表格數(shù)據(jù)??
以新浪財經(jīng)機構持股匯總數(shù)據(jù)為例:
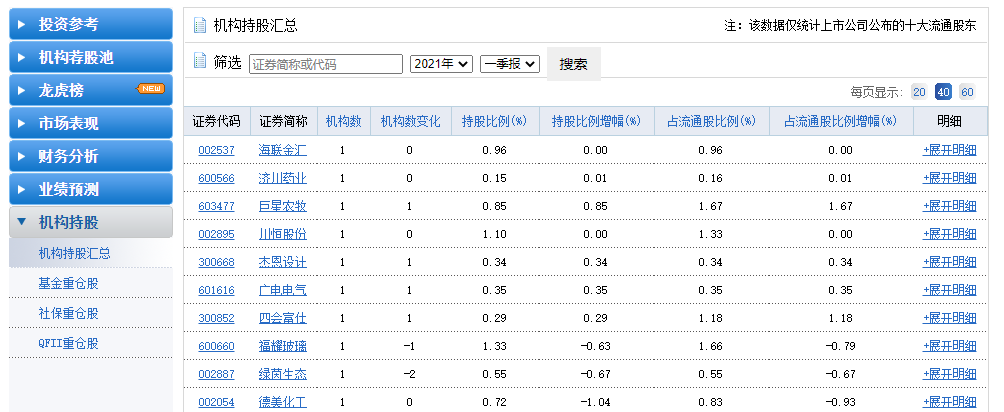
一共47頁,通過for循環(huán)構建47個網(wǎng)頁url,再用pd.read_html()循環(huán)爬取。
df?=?pd.DataFrame()
for?i?in?range(1,?48):
????url?=?f'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jgcg/index.phtml?p={i}'
????df?=?pd.concat([df,?pd.read_html(url)[0]])?#?爬取+合并DataFrame
還是幾行代碼,輕松解決。
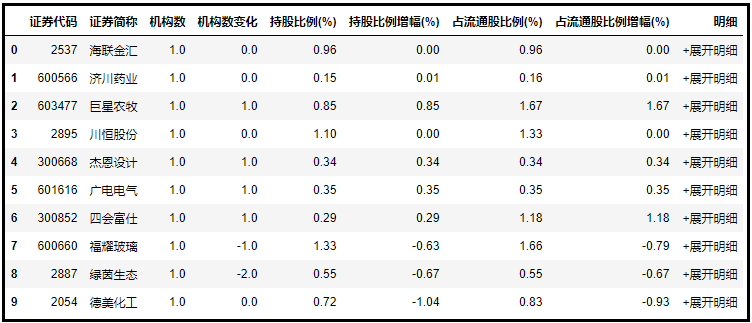
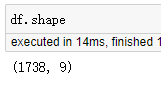
一共47頁1738條數(shù)據(jù)都獲取到了。
通過以上的小案例,相信大家可以輕松掌握用Pandas批量爬取表格數(shù)據(jù)啦??
參考資料
Python讀財: 天秀!Pandas還能用來寫爬蟲?
 點擊“閱讀原文”了解知識星球
點擊“閱讀原文”了解知識星球