
我用《覺醒年代》做數(shù)據(jù)分析!
最近有同學(xué)和我說《覺醒年代》好好看,于是我后知后覺地查了一下,不查不知道,這部劇豆瓣評(píng)分9.3,微博討論度26億+。《覺醒年代》都是哪些人在看?不如給受眾群體做一個(gè)用戶畫像分析。

開始前要先準(zhǔn)備數(shù)據(jù),覺醒年代作為關(guān)鍵詞在微博平臺(tái)有很高的閱讀量,于是就從微博作為切入口進(jìn)行數(shù)據(jù)采集。
因?yàn)槲⒉?duì)爬蟲的限制,我們只爬取了覺醒年代超話下的50頁(yè)的相關(guān)信息,數(shù)量已經(jīng)很多了,這個(gè)爬取的時(shí)間也比較長(zhǎng)。
1. 數(shù)據(jù)準(zhǔn)備
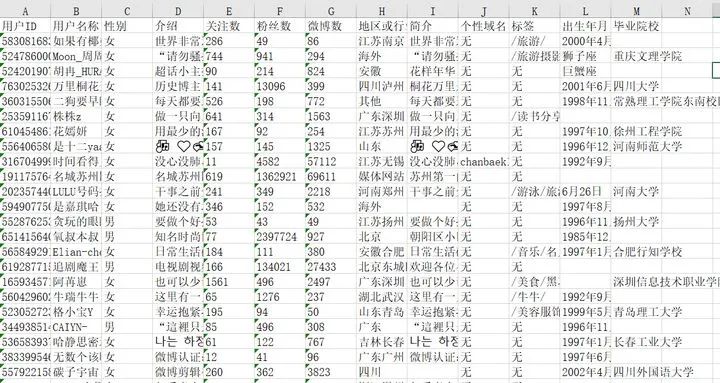
因?yàn)槲⒉┦莿?dòng)態(tài)加載的數(shù)據(jù),因此我們使用了selenium操作瀏覽器對(duì)微博的數(shù)據(jù)進(jìn)行了爬取。使用關(guān)鍵詞#覺醒年代 進(jìn)行搜索,爬取這個(gè)話題下的相關(guān)微博動(dòng)態(tài),共爬取了1300個(gè)相關(guān)微博動(dòng)態(tài)以及微博用戶的相關(guān)信息。
后臺(tái)回復(fù) 覺醒年代 可獲取打包的數(shù)據(jù)與代碼
2. 數(shù)據(jù)分析實(shí)踐
導(dǎo)入相關(guān)的數(shù)據(jù)
user=pd.read_excel('微博用戶信息.xlsx')
info=pd.read_excel('微博信息.xlsx',header=None,names=['用戶名','設(shè)備','內(nèi)容'])
info

2.1 用戶性別分布
from pyecharts.charts import Pie
from pyecharts import options as opts
data=[('男',266),('女',1081)]
pie = Pie()
pie.add("性別分布分析",data)
pie.set_global_opts(title_opts=opts.TitleOpts(title='用戶的性別分布'))
#formatter參數(shù){a}(系列名稱),{b}(數(shù)據(jù)項(xiàng)名稱),{c}(數(shù)值), go7utgvlrp(百分比)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="go7utgvlrp%"))
pie.render_notebook()
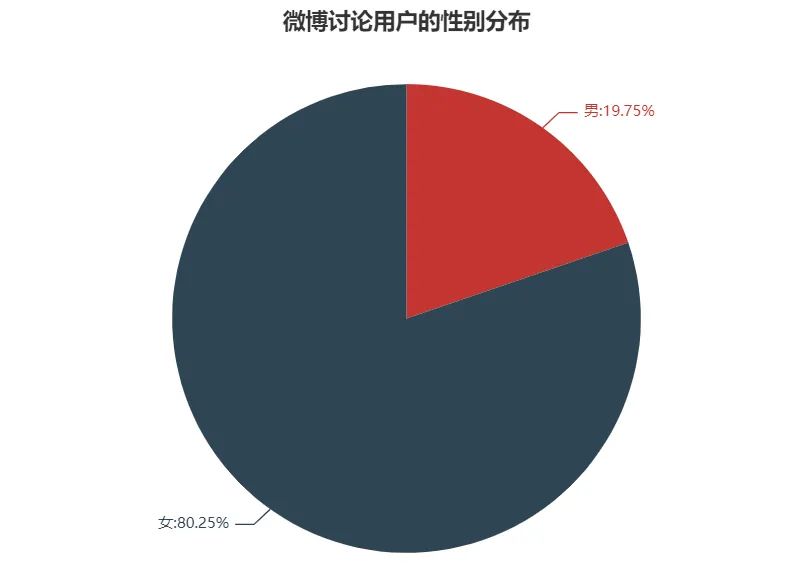
通過分析我看可以看到,微博討論用戶群中女性占比達(dá)到80.25%。
因?yàn)椴荒茏鋈繑?shù)據(jù)抽取,數(shù)據(jù)的采集是通過微博動(dòng)態(tài)采集,考慮到微博本身的用戶性別占比,同時(shí)女性人群更愛通過互聯(lián)網(wǎng)平臺(tái)寫自己的觀影感受,因此我們的數(shù)據(jù)采集有一定的偏好性,但是也能說明《覺醒年代》的受眾群體中,女性占據(jù)了一個(gè)較高的比例。
2.2 用戶地域分布
因?yàn)榈赜蚍植嫉臄?shù)據(jù)包含了省和地級(jí)市,因此我們需要進(jìn)行一定程度的處理。
def clean(row):
pro=['上海','云南','內(nèi)蒙古','北京','臺(tái)灣','吉林','四川','天津','寧夏','安徽','山東','山西','廣東','廣西','新疆','江蘇','江西','河北','河南','浙江','海南','湖北','湖南','澳門','甘肅','福建', '西藏','貴州','遼寧','重慶','陜西','青海','香港','黑龍江']
row=str(row)
flag1=row[:2]
flag2=row[:3]
if flag1 in pro:
return flag1
elif flag2 in pro:
return flag2
else:
return '其它'
user['地域']=user['地區(qū)或行業(yè)類別'].apply(clean)
location=user['地域'].value_counts()
data=[list(z) for z in zip(location.index, location)]
c=Map()
c.add(series_name="位置分布", data_pair=data, maptype="china",zoom = 1,center=[105,38])
c.set_global_opts(
title_opts=opts.TitleOpts(title='用戶的位置分布',pos_left = 'center'),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(max_=150,range_color=["white", "#FA8072", "#FF0000"])
)
c.render_notebook()

從地域分布圖來看,用戶分布有2個(gè)高峰群,分別是北京和廣東。分析其產(chǎn)生的可能原因是北京擁有較多的高校,廣東包含了廣州以及深圳兩個(gè)一線城市,年輕用戶群較多。包括一線、新一線以及江浙沿海地區(qū)也有較高的討論度。
2.3 用戶年齡分布
from pyecharts.charts import Bar
def age(row):
if '年' in str(row):
num=2021-int(row.split('年')[0])
if num>=40:
return '40歲以上'
elif 40>num>=30:
return '30-40歲'
elif 30>num>=20:
return '20-30歲'
elif 20>num:
return '小于20歲'
else:
return '其它'
else:
return '其它'
user['年齡']=user['出生年月'].apply(age)
columns=['小于20歲','20-30歲','30-40歲','40歲以上']
num=[100,464,62,23]
bar=Bar()
bar.add_xaxis(columns)
bar.add_yaxis('人數(shù)',num)
bar.set_global_opts(title_opts=opts.TitleOpts(title='微博討論用戶年齡分布',pos_left = 'center'),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name="人數(shù)",name_location='middle',name_gap=30,name_textstyle_opts=opts.TextStyleOpts(font_size=20)))
bar.render_notebook()
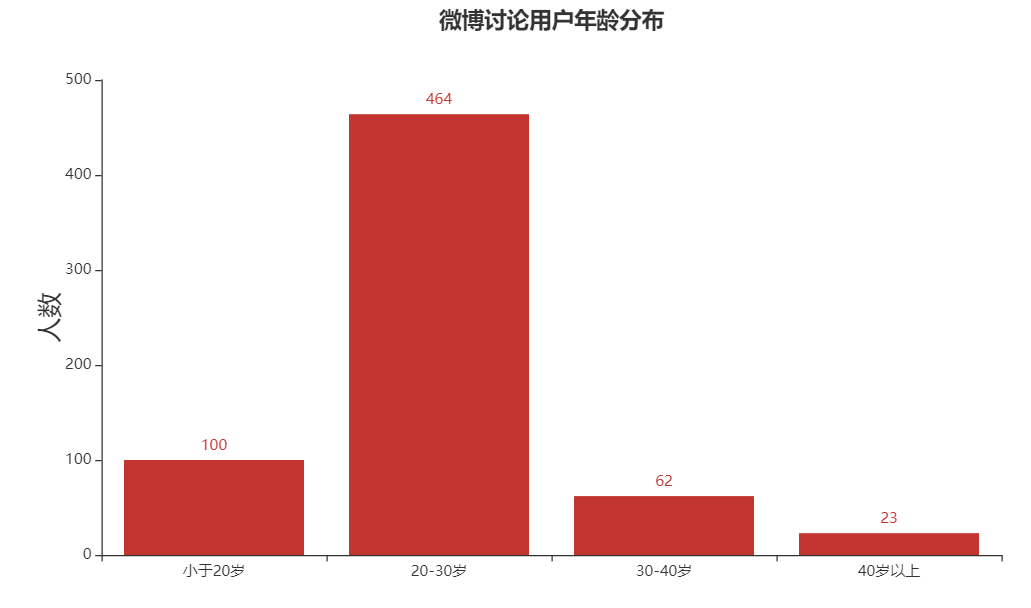
從微博討論用戶群來看,年齡主要集中在20-30歲之間,這說明《覺醒年代》在90后的觀眾有比較深遠(yuǎn)的影響。作為一部主旋律電影,讓90后追劇上頭足以證明它的誠(chéng)意和質(zhì)量。
這里也要留意潛在的數(shù)據(jù)采集誤差,因?yàn)閿?shù)據(jù)入口是微博討論用戶,平臺(tái)中80以及90后本身就占據(jù)較大比例,同時(shí)90后更喜歡通過社交媒體自我表達(dá)。
2.4 用戶設(shè)備分布
def device(row):
row=str(row)
if 'iPhone' in row:
return 'iPhone'
elif 'iPad' in row:
return 'iPad'
elif ('榮耀' in row) or ('honor' in row):
return 'honor'
elif ('HUAWEI'in row) or ('華為'in row) or ('nova'in row) or ('HarmonyOS' in row) or ('麥芒' in row) :
return 'HUAWEI'
elif ('mi'in row) or ('小米'in row) or ('Redmi'in row) or ('紅米'in row) or('K30' in row ) :
return 'mi'
elif ('vivo' in row) or ('ColorOS' in row):
return 'vivo'
elif 'OPPO' in row:
return 'oppo'
elif 'OnePlus' in row:
return 'OnePlus'
elif 'iQOO' in row:
return 'iQOO'
elif ('真我' in row) or ('realme' in row):
return 'realme'
elif '三星' in row:
return 'sumsung'
elif '索尼' in row:
return 'sony'
else:
return '其它'
info['device']=info['設(shè)備'].apply(device)
columns=['iPhone','HUAWEI','mi','honor','oppo','vivo','iPad','OnePlus','sumsung','realme']
num=[497,222,58,44,41,36,13,5,4,2]
data=[list(x) for x in zip(columns,num)]
pie = Pie()
pie.add("微博討論用戶手機(jī)品牌分布",data)
pie.set_global_opts(title_opts=opts.TitleOpts(title='微博討論用戶手機(jī)品牌分布',pos_left = 'center'),legend_opts=opts.LegendOpts(is_show=False))
#formatter參數(shù){a}(系列名稱),{b}(數(shù)據(jù)項(xiàng)名稱),{c}(數(shù)值), go7utgvlrp(百分比)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b} go7utgvlrp%"))
pie.render_notebook()
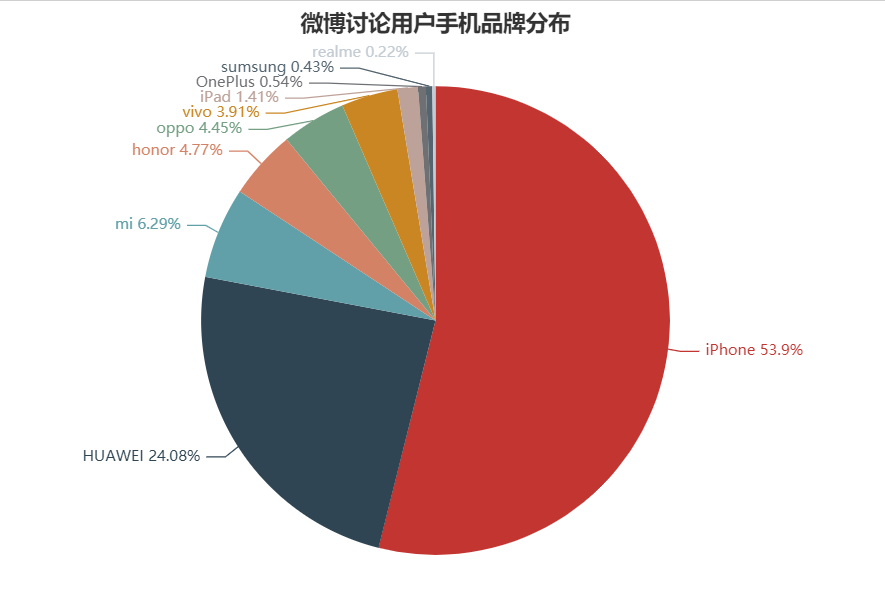
通過數(shù)據(jù)來看,微博討論用戶的主力設(shè)備是iPhone和華為,其中蘋果設(shè)備占比超過了50%,隨著蘋果手機(jī)價(jià)格的降低在市場(chǎng)占有率上有著明顯的優(yōu)勢(shì)。
2.5 用戶個(gè)性標(biāo)簽詞云
且慢!在開始做詞云之前,要先刪除停頓詞,停頓詞往往沒有有效的含義還會(huì)占據(jù)大量位置,影響詞云的效果。
在github上找到了停頓詞表:
goto456/stopwords:https://link.zhihu.com/?target=https%3A//github.com/goto456/stopwords
#pip install jieba
import jieba
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
from collections import Counter
content=''.join([str(i) for i in list(info['內(nèi)容'])])
stopwords = [line.strip('') for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
jieba.add_word("覺醒年代")
jieba.add_word("yyds")
content=[x for x in jieba.lcut(content) if x not in stopwords and len(x)>1]
content=Counter(content)
test_mask = np.array(Image.open("datawhale.png"))
stopwords = set(STOPWORDS)
stopwords.add("said")
wc = WordCloud(background_color="white",mask=test_mask,font_path='simhei.ttf',width=5000,height=5000,
stopwords=stopwords)
wc.generate_from_frequencies(content)
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
wc.to_file("test.png")

2.6 角色討論熱度
import pandas as pd
hero=['陳獨(dú)秀','李大釗','延年','魯迅','喬年','蔡元培','胡適','毛澤東','周恩來','辜鴻銘','顧維鈞','趙紉蘭','汪大燮','鄧中夏','柳眉','白蘭','吳炳湘','易白沙','高君曼','章士釗','黃侃','沈尹默']
content=''.join([str(i) for i in list(info['內(nèi)容'])])
hero_num=[]
for i in hero:
num=content.count(i)
hero_num.append((i,num))
hero_num=pd.DataFrame(hero_num)
hero_num.columns=['人名','出現(xiàn)次數(shù)']
hero_num=hero_num.sort_values(by='出現(xiàn)次數(shù)',ascending=False)
hero_num=hero_num.reset_index(drop=True)
columns=list(hero_num['人名'])[:10]
num=list(hero_num['出現(xiàn)次數(shù)'])[:10]
bar=Bar()
bar.add_xaxis(columns)
bar.add_yaxis('次數(shù)',num)
bar.set_global_opts(title_opts=opts.TitleOpts(title='微博討論角色頻率分布',pos_left = 'center'),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(name="次數(shù)",name_location='middle',name_gap=30,name_textstyle_opts=opts.TextStyleOpts(font_size=20)))
bar.render_notebook()
對(duì)于劇中的常用角色對(duì)內(nèi)容進(jìn)行匹配,選出來排名前10的角色
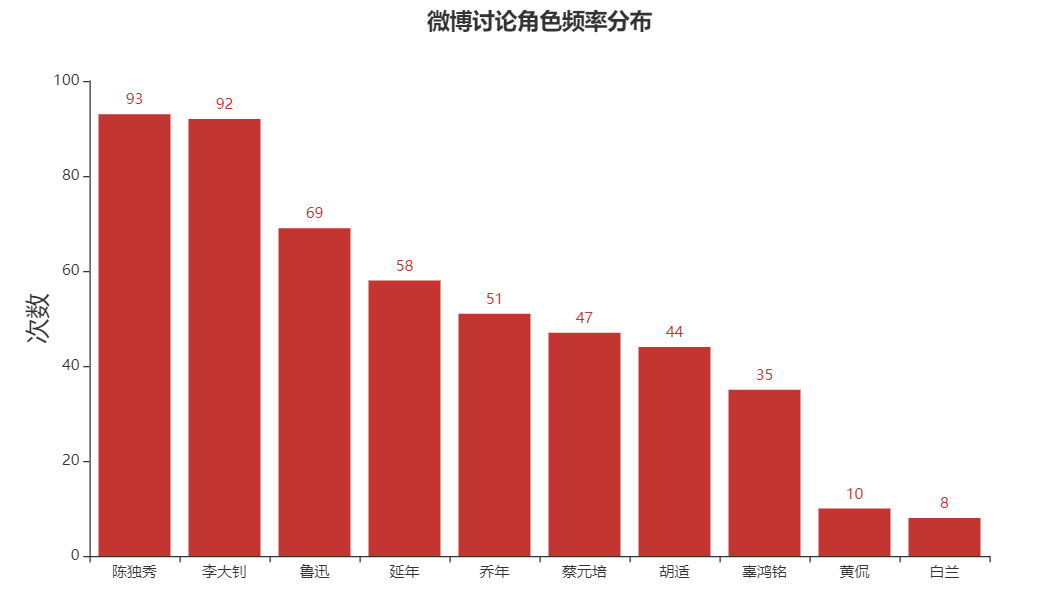
可以看到根據(jù)討論內(nèi)容中出現(xiàn)的次數(shù)來看,陳獨(dú)秀及李大釗兩位作為主角,討論熱度遙遙領(lǐng)先于其他角色,延年與喬年也都是排行在前列。
也是在電視劇播出后,很多市民在延喬路鮮花,想起了習(xí)總書記在中國(guó)共產(chǎn)黨成立100周年上的講話:中國(guó)人民也絕不允許任何外來勢(shì)力欺負(fù)、壓迫、奴役我們,誰妄想這樣干,必將在14億多中國(guó)人民用血肉筑成的鋼鐵長(zhǎng)城面前碰得頭破血流。這盛世,如你所愿!

3. 數(shù)據(jù)及代碼
在本次的項(xiàng)目中,我們爬取了微博關(guān)鍵詞下的相關(guān)數(shù)據(jù),同時(shí)對(duì)數(shù)據(jù)進(jìn)行清洗與相關(guān)的可視化分析,項(xiàng)目中包含了一定的可視化技巧,適合初學(xué)者進(jìn)行相關(guān)的學(xué)習(xí)。如需代碼數(shù)據(jù),公眾號(hào)后臺(tái)回復(fù) 覺醒年代 可下載。