
21個(gè)深度學(xué)習(xí)開源數(shù)據(jù)集匯總!
↓↓↓點(diǎn)擊關(guān)注,回復(fù)資料,10個(gè)G的驚喜
轉(zhuǎn)自丨極市平臺
導(dǎo)讀
?本文收集整理了21個(gè)國內(nèi)外經(jīng)典的開源數(shù)據(jù),包含了目標(biāo)檢測、圖像分割、圖像分類、人臉、自動(dòng)駕駛、姿態(tài)估計(jì)、目標(biāo)跟蹤等方向。
深度學(xué)習(xí)的三大要素:數(shù)據(jù)、算法、算力。
數(shù)據(jù)在深度學(xué)習(xí)中占據(jù)著非常重要的地位,一個(gè)高質(zhì)量的數(shù)據(jù)集往往能夠提高模型訓(xùn)練的質(zhì)量和預(yù)測的準(zhǔn)確率。極市平臺收集整理了21個(gè)國內(nèi)外經(jīng)典的開源數(shù)據(jù),包含了目標(biāo)檢測、圖像分割、圖像分類、人臉、自動(dòng)駕駛、姿態(tài)估計(jì)、目標(biāo)跟蹤等方向。
數(shù)據(jù)集下載匯總鏈接:https://www.cvmart.net/dataSets
數(shù)據(jù)集將會不斷更新,歡迎大家持續(xù)關(guān)注!
一、目標(biāo)檢測
1.COCO2017數(shù)據(jù)集
COCO2017是2017年發(fā)布的COCO數(shù)據(jù)集的一個(gè)版本,主要用于COCO在2017年后持有的物體檢測任務(wù)、關(guān)鍵點(diǎn)檢測任務(wù)和全景分割任務(wù)。
二、圖像分割
1.LVIS數(shù)據(jù)集
LVIS是一個(gè)大規(guī)模細(xì)粒度詞匯集標(biāo)記數(shù)據(jù)集,該數(shù)據(jù)集針對超過 1000 類物體進(jìn)行了約 200 萬個(gè)高質(zhì)量的實(shí)例分割標(biāo)注,包含 164k 張圖像。
2.高密度人群及移動(dòng)物體視頻數(shù)據(jù)集
Crowd Segmentation Dataset 是一個(gè)高密度人群和移動(dòng)物體視頻數(shù)據(jù),視頻來自BBC Motion Gallery 和 Getty Images 網(wǎng)站。
3.DAVIS 視頻分割數(shù)據(jù)集
Densely Annotated Video Segmentation 是一個(gè)高清視頻中的物體分割數(shù)據(jù)集,包括 50個(gè) 視頻序列,3455個(gè) 幀標(biāo)注,視頻采集自高清 1080p 格式。
三、圖像分類
1.MNIST 手寫數(shù)字圖像數(shù)據(jù)集
MNIST數(shù)據(jù)集是一個(gè)手寫阿拉伯?dāng)?shù)字圖像識別數(shù)據(jù)集,圖片分辨率為 20x20 灰度圖圖片,包含‘0 - 9’ 十組手寫手寫阿拉伯?dāng)?shù)字的圖片。其中,訓(xùn)練樣本 60000 ,測試樣本 10000,數(shù)據(jù)為圖片的像素點(diǎn)值,作者已經(jīng)對數(shù)據(jù)集進(jìn)行了壓縮。
2.Kaggle 垃圾分類圖片數(shù)據(jù)集
該數(shù)據(jù)集是圖片數(shù)據(jù),分為訓(xùn)練集85%(Train)和測試集15%(Test)。其中O代表Organic(有機(jī)垃圾),R代表Recycle(可回收)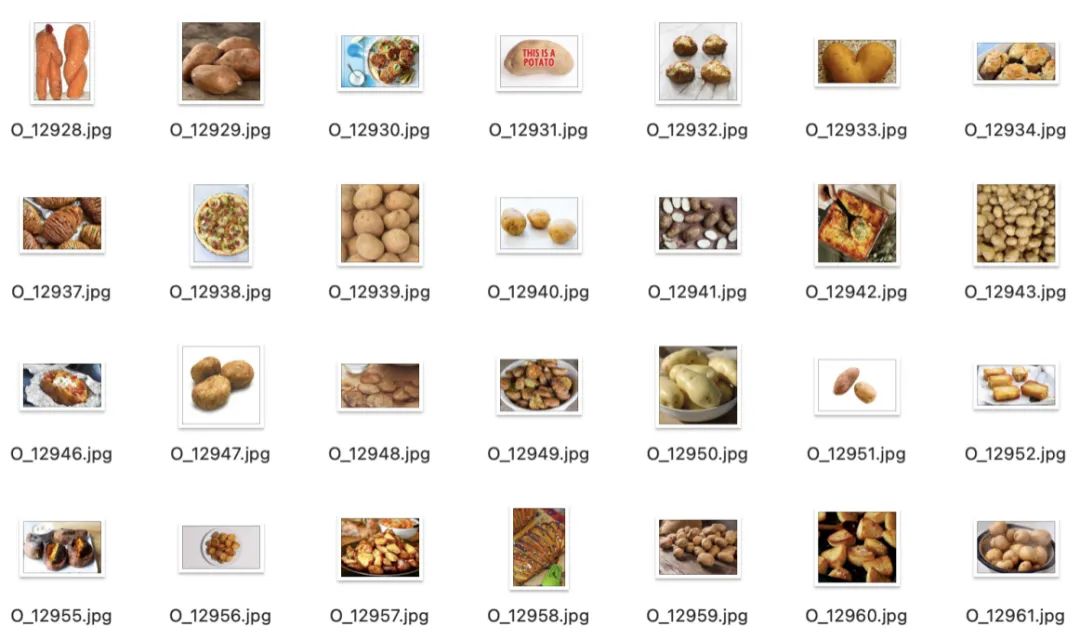
四、人臉
1.IMDB-WIKI人臉數(shù)據(jù)集
IMDB-WIKI 500k+ 是一個(gè)包含名人人臉圖像、年齡、性別的數(shù)據(jù)集,圖像和年齡、性別信息從 IMDB 和 WiKi 網(wǎng)站抓取,總計(jì) 524230 張名人人臉圖像及對應(yīng)的年齡和性別。其中,獲取自 IMDB 的 460723 張,獲取自 WiKi 的 62328 張。
2.WiderFace人臉檢測數(shù)據(jù)集
WIDER FACE數(shù)據(jù)集是人臉檢測的一個(gè)benchmark數(shù)據(jù)集,包含32203圖像,以及393,703個(gè)標(biāo)注人臉,其中,158,989個(gè)標(biāo)注人臉位于訓(xùn)練集,39,,496個(gè)位于驗(yàn)證集。每一個(gè)子集都包含3個(gè)級別的檢測難度:Easy,Medium,Hard。這些人臉在尺度,姿態(tài),光照、表情、遮擋方面都有很大的變化范圍。WIDER FACE選擇的圖像主要來源于公開數(shù)據(jù)集WIDER。制作者來自于香港中文大學(xué),他們選擇了WIDER的61個(gè)事件類別,對于每個(gè)類別,隨機(jī)選擇40%10%50%作為訓(xùn)練、驗(yàn)證、測試集。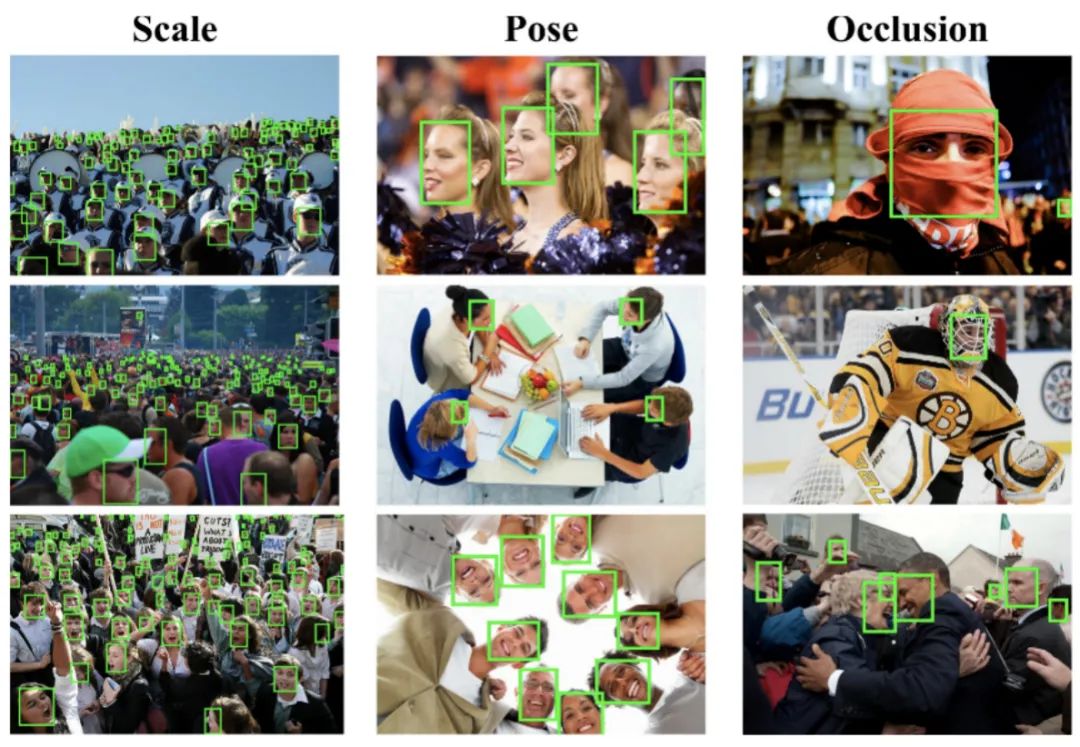
3.LFW 人像圖像數(shù)據(jù)集
該數(shù)據(jù)集是用于研究無約束面部識別問題的面部照片數(shù)據(jù)庫。數(shù)據(jù)集包含從網(wǎng)絡(luò)收集的13000多張圖像。每張臉都貼上了所畫的人的名字,圖片中的1680人在數(shù)據(jù)集中有兩個(gè)或更多不同的照片。
GENKI數(shù)據(jù)集是由加利福尼亞大學(xué)的機(jī)器概念實(shí)驗(yàn)室收集。該數(shù)據(jù)集包含GENKI-R2009a,GENKI-4K,GENKI-SZSL三個(gè)部分。GENKI-R2009a包含11159個(gè)圖像,GENKI-4K包含4000個(gè)圖像,分為“笑”和“不笑”兩種,每個(gè)圖片的人臉的尺度大小,姿勢,光照變化,頭的轉(zhuǎn)動(dòng)等都不一樣,專門用于做笑臉識別。GENKI-SZSL包含3500個(gè)圖像,這些圖像包括廣泛的背景,光照條件,地理位置,個(gè)人身份和種族等。
五、姿態(tài)估計(jì)
1.MPII人體模型數(shù)據(jù)集
MPII Human Shape 人體模型數(shù)據(jù)是一系列人體輪廓和形狀的3D模型及工具。模型是從平面掃描數(shù)據(jù)庫 CAESAR 學(xué)習(xí)得到。
2.MPII人類姿態(tài)數(shù)據(jù)集
MPII 人體姿態(tài)數(shù)據(jù)集是用于評估人體關(guān)節(jié)姿勢估計(jì)的最先進(jìn)基準(zhǔn)。該數(shù)據(jù)集包括大約 25,000 張圖像,其中包含超過 40,000 個(gè)帶有注釋身體關(guān)節(jié)的人。這些圖像是使用已建立的人類日常活動(dòng)分類法系統(tǒng)收集的。總的來說,數(shù)據(jù)集涵蓋了 410 項(xiàng)人類活動(dòng),每個(gè)圖像都提供了一個(gè)活動(dòng)標(biāo)簽。每張圖像都是從 YouTube 視頻中提取的,并提供前后未注釋的幀。此外,測試集有更豐富的注釋,包括身體部位遮擋和 3D 軀干和頭部方向。
六、自動(dòng)駕駛
1.KITTI 道路數(shù)據(jù)集
道路和車道估計(jì)基準(zhǔn)包括289次培訓(xùn)和290幅測試圖像。我們在鳥瞰空間中評估道路和車道的估計(jì)性能。它包含不同類別的道路場景:城市無標(biāo)記、城市標(biāo)記、 城市多條標(biāo)記車道以及以上三者的結(jié)合。
2.CrackForest數(shù)據(jù)集
CrackForest數(shù)據(jù)集是一個(gè)帶注釋的道路裂縫圖像數(shù)據(jù)庫,可以大致反映城市路面狀況。
3.KITTI-2015立體聲數(shù)據(jù)集
stero 2015 基準(zhǔn)測試包含 200 個(gè)訓(xùn)練場景和 200 個(gè)測試場景(每個(gè)場景 4 幅彩色圖像,以無損 png 格式保存)。與stereo 2012 和flow 2012 基準(zhǔn)測試相比,它包含動(dòng)態(tài)場景,在半自動(dòng)過程中為其建立了真值。該數(shù)據(jù)集是通過在卡爾斯魯厄中等規(guī)模城市、農(nóng)村地區(qū)和高速公路上行駛而捕獲的。每張圖像最多可以看到 15 輛汽車和 30 名行人。
4.KITTI-2015光流數(shù)據(jù)集
Flow 2015 基準(zhǔn)測試包含 200 個(gè)訓(xùn)練場景和 200 個(gè)測試場景(每個(gè)場景 4 幅彩色圖像,以無損 png 格式保存)。與stereo 2012 和flow 2012 基準(zhǔn)測試相比,它包含動(dòng)態(tài)場景,在半自動(dòng)過程中為其建立了真值。該數(shù)據(jù)集是通過在卡爾斯魯厄中等規(guī)模城市、農(nóng)村地區(qū)和高速公路上行駛而捕獲的。每張圖像最多可以看到 15 輛汽車和 30 名行人。
5.KITTI-2015場景流數(shù)據(jù)集
Sceneflow 2015 基準(zhǔn)測試包含 200 個(gè)訓(xùn)練場景和 200 個(gè)測試場景(每個(gè)場景 4 幅彩色圖像,以無損 png 格式保存)。與stereo 2012 和flow 2012 基準(zhǔn)測試相比,它包含動(dòng)態(tài)場景,在半自動(dòng)過程中為其建立了真值。該數(shù)據(jù)集是通過在卡爾斯魯厄中等規(guī)模城市、農(nóng)村地區(qū)和高速公路上行駛而捕獲的。每張圖像最多可以看到 15 輛汽車和 30 名行人。
6.KITTI深度數(shù)據(jù)集
KITTI-depth 包含超過 93,000 個(gè)深度圖以及相應(yīng)的原始 LiDaR 掃描和 RGB 圖像。鑒于大量的訓(xùn)練數(shù)據(jù),該數(shù)據(jù)集應(yīng)允許訓(xùn)練復(fù)雜的深度學(xué)習(xí)模型,以完成深度補(bǔ)全和單幅圖像深度預(yù)測的任務(wù)。此外,該數(shù)據(jù)集提供了帶有未發(fā)布深度圖的手動(dòng)選擇圖像,作為這兩個(gè)具有挑戰(zhàn)性的任務(wù)的基準(zhǔn)。
七、目標(biāo)跟蹤
1.ALOV300++跟蹤數(shù)據(jù)集
ALOV++,Amsterdam Library of Ordinary Videos for tracking 是一個(gè)物體追蹤視頻數(shù)據(jù),旨在對不同的光線、通透度、泛著條件、背景雜亂程度、焦距下的相似物體的追蹤。
八、動(dòng)作識別
1.HMDB人類動(dòng)作視頻數(shù)據(jù)集
由布朗大學(xué)發(fā)布的人類動(dòng)作視頻數(shù)據(jù)集,該數(shù)據(jù)集視頻多數(shù)來源于電影,還有一部分來自公共數(shù)據(jù)庫以及YouTube等網(wǎng)絡(luò)視頻庫。數(shù)據(jù)庫包含有6849段樣本,分為51類,每類至少包含有101段樣本。
2.UCF50動(dòng)作識別數(shù)據(jù)集
UCF50 是一個(gè)由中佛羅里達(dá)大學(xué)發(fā)布的動(dòng)作識別數(shù)據(jù)集,由來自 youtube 的真實(shí)視頻組成,包含 50 個(gè)動(dòng)作類別,如棒球投球、籃球投籃、臥推、騎自行車、騎自行車、臺球、蛙泳、挺舉、跳水、擊鼓等。對于所有 50 個(gè)類別,視頻分為 25 組,其中每組由超過 4 個(gè)動(dòng)作剪輯。同一組中的視頻片段可能具有一些共同的特征,例如同一個(gè)人、相似背景、相似視點(diǎn)等。
3.SBU Kinect 交互數(shù)據(jù)集
SBU Kinect Interaction是一個(gè)復(fù)雜的人類活動(dòng)數(shù)據(jù)集,描述了兩個(gè)人的交互,包括同步視頻、深度和運(yùn)動(dòng)捕捉數(shù)據(jù)。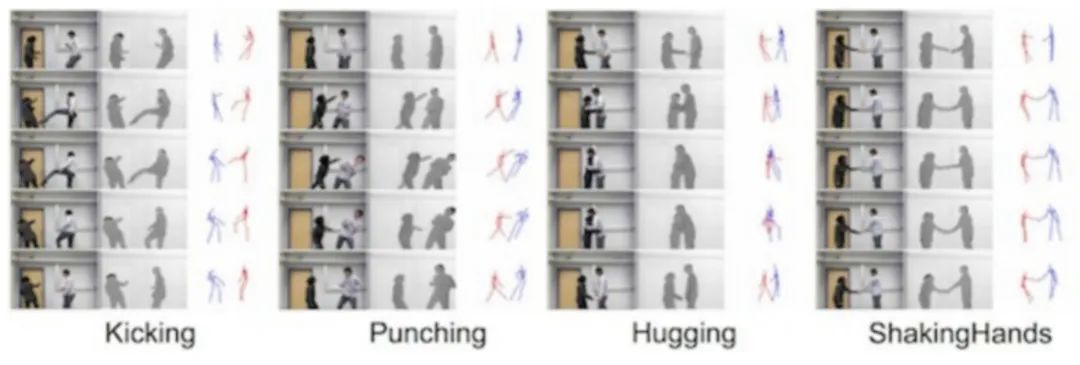
推薦閱讀
決策樹可視化,被驚艷到了! 開發(fā)機(jī)器學(xué)習(xí)APP,太簡單了 200 道經(jīng)典機(jī)器學(xué)習(xí)面試題總結(jié) 卷積神經(jīng)網(wǎng)絡(luò)(CNN)數(shù)學(xué)原理解析 收手吧,華強(qiáng)!我用機(jī)器學(xué)習(xí)幫你挑西瓜 為了這個(gè)GIF,我專門建了一個(gè)網(wǎng)站 【保姆級教程】白嫖老外的云服務(wù)器
三連在看,月入百萬??