
2021最新爬蟲教程.ppt



點擊上方藍字關(guān)注我們
爬蟲框架就是一些爬蟲項目的半成品,可以將些爬蟲常用的功能寫好。然后留下一些接口,在不同的爬蟲項目當(dāng)中,調(diào)用適合自己項目的接口,再編寫少量的代碼實現(xiàn)自己需要的功能。因為框架中已經(jīng)實現(xiàn)了爬蟲常用的功能,所以為開發(fā)人員節(jié)省了很多精力與時間。
Scrapy
Scrapy框架是一套比較成熟的Python爬蟲框架,簡單輕巧,并且非常方便。可以高效事的爬取 Web頁面井從頁面中提取結(jié)構(gòu)化的數(shù)據(jù)。
重要的是Scrapy 是一套開源的框架,所以在使用時不需要擔(dān)心收取費用的問題。
Scrapy是一個為了爬取網(wǎng)站數(shù)據(jù),提取結(jié)構(gòu)性數(shù)據(jù)而編寫的應(yīng)用框架。可以應(yīng)用在包括數(shù)據(jù)挖掘,信息處理或存儲歷史數(shù)據(jù)等一系列的程序中。可以用它輕松的爬下來如亞馬遜商品信息之類的數(shù)據(jù)。
Scrapy 的官網(wǎng)地址為:
https://scrapy.org/
Crawley
Crawley也是Python開發(fā)出的爬蟲框架,該框架致力于改變?nèi)藗儚幕ヂ?lián)網(wǎng)中提取數(shù)據(jù)的方式Crawley的具體特性如下:
基于Eventlet構(gòu)建的高速網(wǎng)絡(luò)爬蟲框架。
可以將數(shù)據(jù)存儲在關(guān)系數(shù)據(jù)庫中,例如,Postgres, Mysql. Oracle. Sqlite.
可以將爬取的數(shù)據(jù)導(dǎo)入為Json. XML格式。
支持非關(guān)系數(shù)據(jù)跨,例如,Mongodb 和Couchdb.
支持命令行工具。
可以使用喜歡的工具進行數(shù)據(jù)的提取,例如,XPath 或Pyquery工具。
支持使用Cookie登錄或訪問那些只有登錄才可以訪問的網(wǎng)頁。
Crawley的官網(wǎng)地址:
http://project.crawley-cloud.com/PySpider
相對于Scrapy 框架而言,PySpider 框架是一支新秀。它采用Pyho語言編寫,分布式架構(gòu),支持多 種數(shù)據(jù)庫后端,強大的WebUl支持腳本編輯器、任務(wù)監(jiān)視器、項目管理器以及結(jié)果查看器。PSpier 的具體特性如下:
Python 腳本控制,可以用任何你喜歡的html解析包(內(nèi)置pyquery)。
Web界面編寫調(diào)試腳本、起停腳本、監(jiān)控執(zhí)行狀態(tài)、查看活動歷史、獲取結(jié)果產(chǎn)出。
支持MySQL、MongoDB、 Redis. SQLite、Elasticsearch, PostgreSQL與SQLAlchemy 。
支持RabbitMQ、Beanstalk、 Redis 和Kombu作為消息隊列。
支持抓取JavaSeript的頁面。
強大的調(diào)度控制,支持超時重爬及優(yōu)先級設(shè)置。
專組件可替換,支持單機/分布式部署,支持Docker部署。
項目地址:
https://github.com/binux/pyspiderPortia
Portia是一個開源可視化爬蟲工具,可讓您在不需要任何編程知識的情況下爬取網(wǎng)站!簡單地注釋您感興趣的頁面,Portia將創(chuàng)建一個蜘蛛來從類似的頁面提取數(shù)據(jù)。

Newspaper
Newspaper可以用來提取新聞、文章和內(nèi)容分析。使用多線程,支持10多種語言等。
Newspaper框架是Python爬蟲框架中在GitHub上點贊排名第三的爬蟲框架,適合抓取新聞網(wǎng)頁。它的操作非常簡單易學(xué),即使對完全沒了解過爬蟲的初學(xué)者也非常的友好,簡單學(xué)習(xí)就能輕易上手,因為使用它不需要考慮header、IP代理,也不需要考慮網(wǎng)頁解析,網(wǎng)頁源代碼架構(gòu)等問題。這個是它的優(yōu)點,但也是它的缺點,不考慮這些會導(dǎo)致它訪問網(wǎng)頁時會有被直接拒絕的可能。
Newspaper功能如下:
多線程文章下載框架
新聞網(wǎng)址識別
從html中提取文本
從html中提取頂部圖像
從html中提取所有圖像
從文本中提取關(guān)鍵字
從文本中提取摘要
從文本中提取作者
Google趨勢術(shù)語提取。
使用10種以上語言(英語,中文,德語,阿拉伯語......)
Beautiful Soup
Beautiful Soup 是一個可以從HTML或XML文件中提取數(shù)據(jù)的Python庫.它能夠通過你喜歡的轉(zhuǎn)換器實現(xiàn)慣用的文檔導(dǎo)航,查找,修改文檔的方式.Beautiful Soup會幫你節(jié)省數(shù)小時甚至數(shù)天的工作時間。
與Scrapy不同的是Beautiful Soup并不是一個框架,而是一個模塊;與Scrapy相比,bs4中間多了一道解析的過程(Scrapy是URL返回什么數(shù)據(jù),程序就接受什么數(shù)據(jù)進行過濾),bs4則在接收數(shù)據(jù)和進行過濾之間多了一個解析的過程,根據(jù)解析器的不同,最終處理的數(shù)據(jù)也有所不同,加上這一步驟的優(yōu)點是可以根據(jù)輸入數(shù)據(jù)的不同進行針對性的解析;同一選擇lxml解析器;
Beautiful Soup的查找數(shù)據(jù)的方法更加靈活方便,不但可以通過標簽查找,還可以通過標簽屬性來查找,而且bs4還可以配合第三方的解析器,可以針對性的對網(wǎng)頁進行解析,使得bs4威力更加強大,方便。
Grab爬蟲框架
Grab是一個用于構(gòu)建Web刮板的Python框架。借助Grab,您可以構(gòu)建各種復(fù)雜的網(wǎng)頁抓取工具,從簡單的5行腳本到處理數(shù)百萬個網(wǎng)頁的復(fù)雜異步網(wǎng)站抓取工具。Grab提供一個API用于執(zhí)行網(wǎng)絡(luò)請求和處理接收到的內(nèi)容,例如與HTML文檔的DOM樹進行交互。
Cola爬蟲框架
Cola是一個分布式的爬蟲框架,對于用戶來說,只需編寫幾個特定的函數(shù),而無需關(guān)注分布式運行的細節(jié)。任務(wù)會自動分配到多臺機器上,整個過程對用戶是透明的。
文末福利:
2021最新黑馬程序員爬蟲教程!
從最簡答的html語法到進階的scrap爬蟲框架。新年福利。送送送!


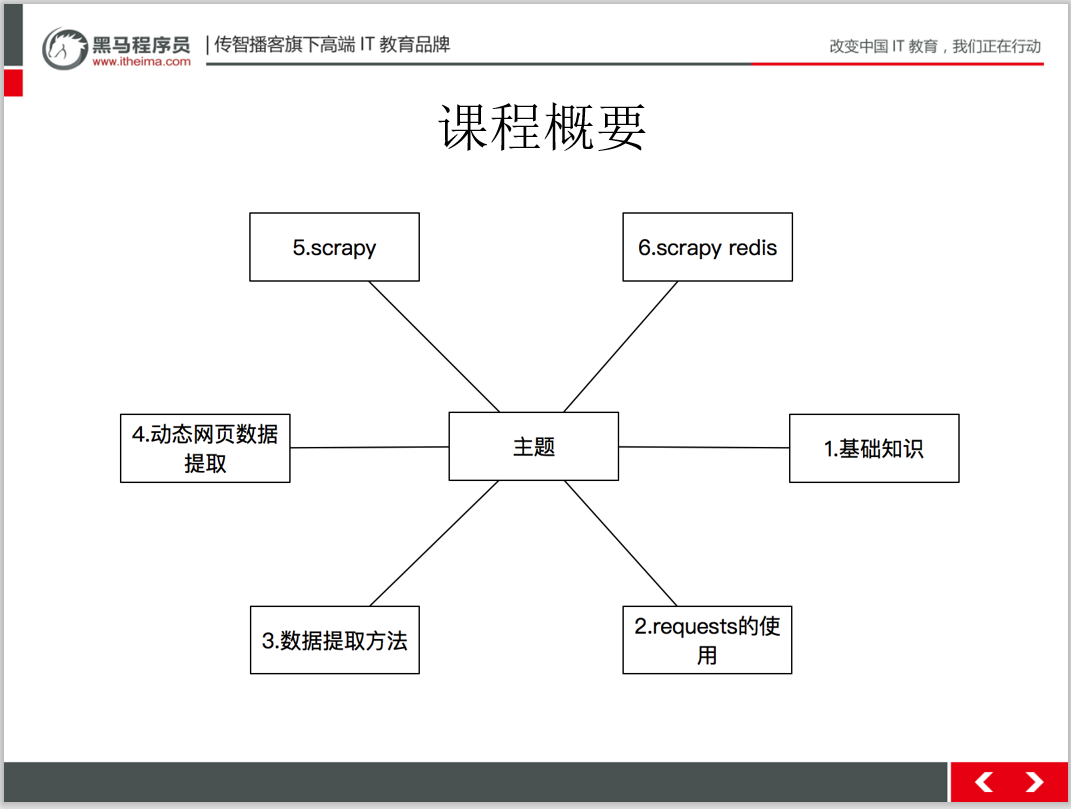
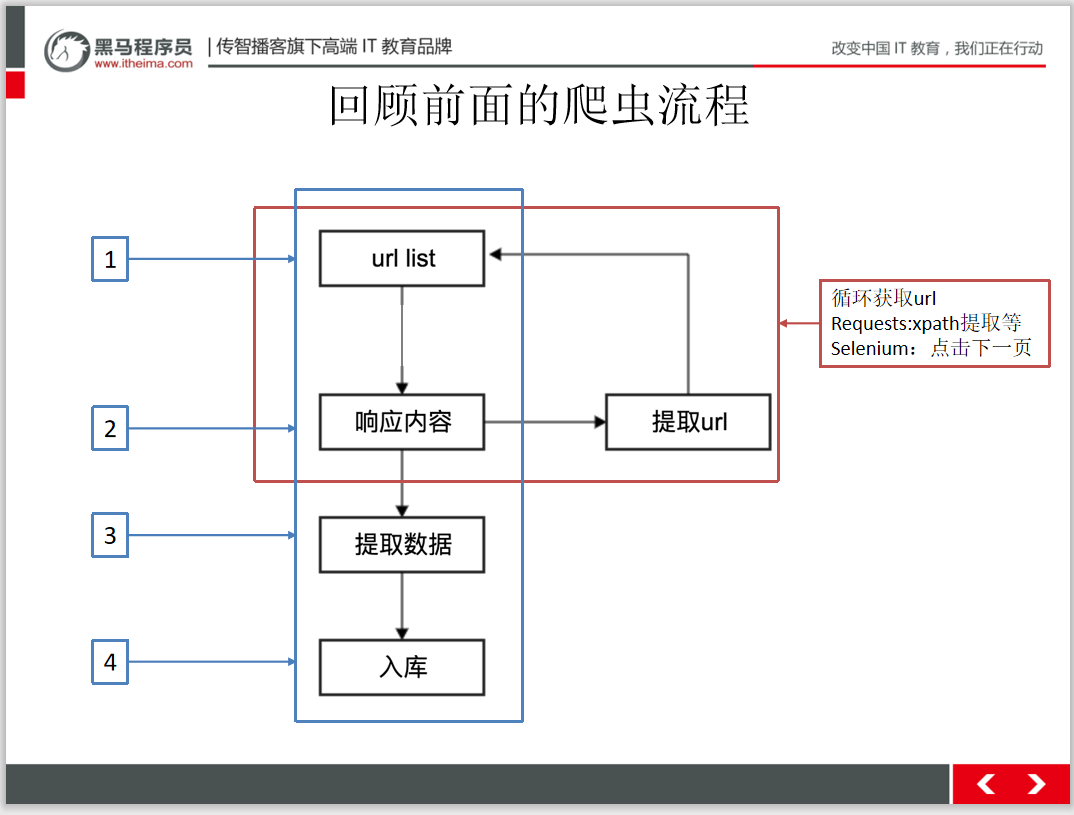
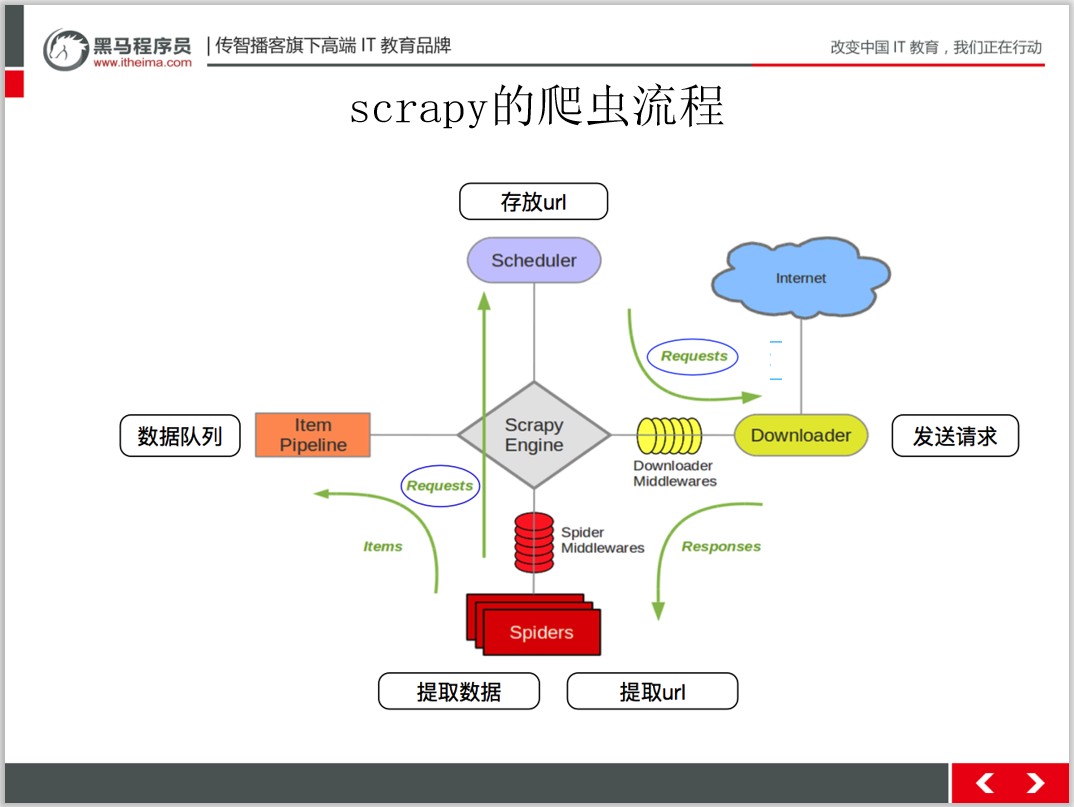
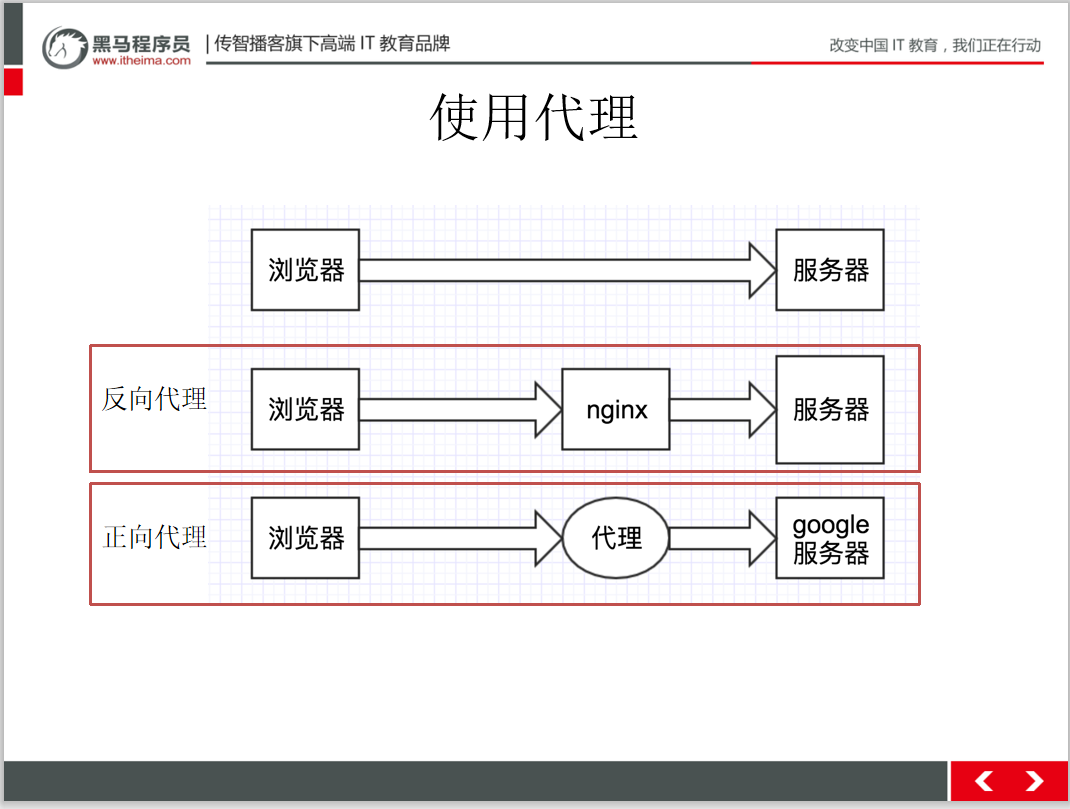
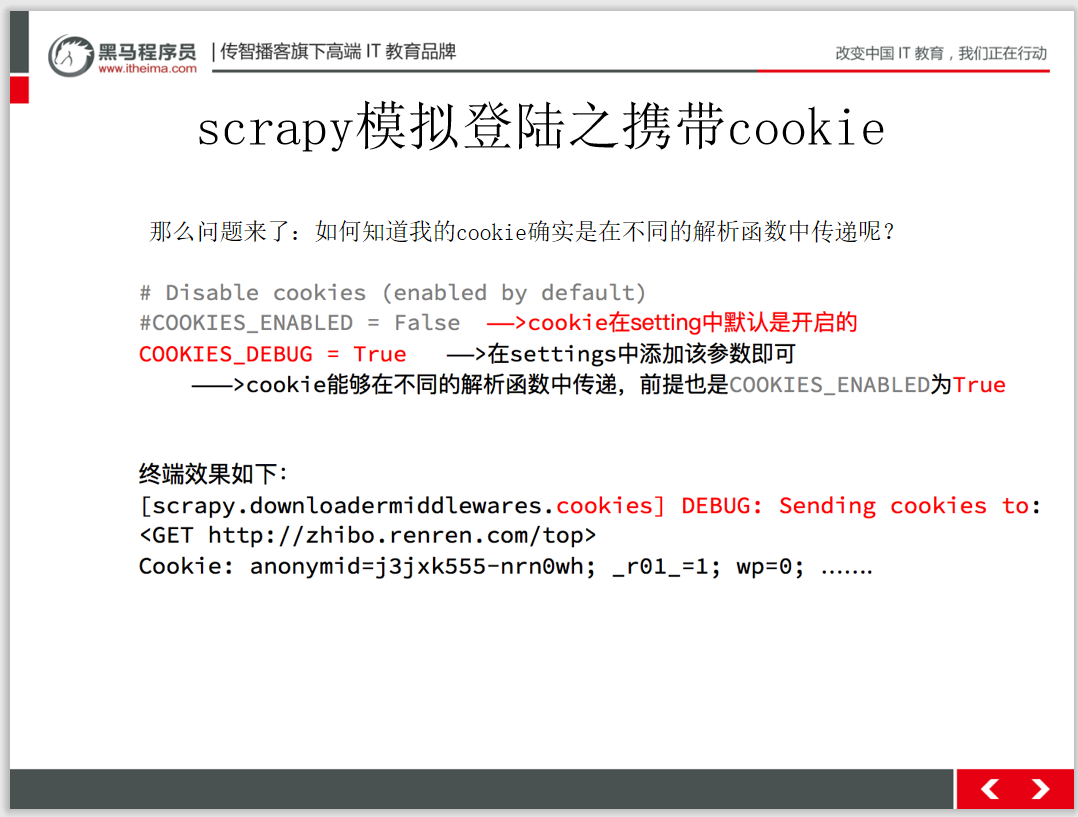
掃碼回復(fù)‘爬蟲教程’ 送你黑馬程序員最新爬蟲教程
掃描二維碼
獲取更多精彩
python學(xué)前班
福利僅此一天,歡迎掃碼關(guān)注獲取。后續(xù)福利更大!

點個在看你最好看