
收藏 | 計算機視覺中的Transformer
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達


Transformer結(jié)構(gòu)已經(jīng)在許多自然語言處理任務(wù)中取得了最先進的成果。Transformer 模型的一個主要的突破可能是今年年中發(fā)布的GPT-3,被授予NeurIPS2020“最佳論文“。
在計算機視覺領(lǐng)域,CNN自2012年以來已經(jīng)成為視覺任務(wù)的主導(dǎo)模型。隨著出現(xiàn)了越來越高效的結(jié)構(gòu),計算機視覺和自然語言處理越來越收斂到一起,使用Transformer來完成視覺任務(wù)成為了一個新的研究方向,以降低結(jié)構(gòu)的復(fù)雜性,探索可擴展性和訓(xùn)練效率。
以下是幾個在相關(guān)工作中比較知名的項目:
DETR(End-to-End Object Detection with Transformers),使用Transformers進行物體檢測和分割。 Vision Transformer?(AN IMAGE IS WORTH 16X16 WORDS: Transformer FOR IMAGE RECOGNITION AT SCALE),使用Transformer 進行圖像分類。 Image GPT(Generative Pretraining from Pixels),使用Transformer進行像素級圖像補全,就像其他GPT文本補全一樣。 End-to-end Lane Shape Prediction with Transformers,在自動駕駛中使用Transformer進行車道標(biāo)記檢測
總的來說,在CV中采用Transformer的相關(guān)工作中主要有兩種模型架構(gòu)。一種是純Transformer結(jié)構(gòu),另一種是將CNNs/主干網(wǎng)與Transformer相結(jié)合的混合結(jié)構(gòu)。
純Transformer 混合型:(CNNs+ Transformer)
Vision Transformer是基于完整的自注意力的Transformer結(jié)構(gòu)沒有使用CNN,而DETR是使用混合模型結(jié)構(gòu)的一個例子,它結(jié)合了卷積神經(jīng)網(wǎng)絡(luò)(CNNs)和Transformer。
為什么要在CV中使用Transformer?如何使用 benchmark上的結(jié)果是什么樣的? *What are the constraints and challenges of using Transformer in CV?* 哪種結(jié)構(gòu)更高效和靈活?為什么?
你會在ViT、DETR和Image GPT的下面的深入研究中找到答案。
Vision Transformer(ViT)將純Transformer架構(gòu)直接應(yīng)用到一系列圖像塊上進行分類任務(wù),可以取得優(yōu)異的結(jié)果。它在許多圖像分類任務(wù)上也優(yōu)于最先進的卷積網(wǎng)絡(luò),同時所需的預(yù)訓(xùn)練計算資源大大減少(至少減少了4倍)。

Vision Transformer模型結(jié)構(gòu)
它們是如何將圖像分割成固定大小的小塊,然后將這些小塊的線性投影連同它們的圖像位置一起輸入變壓器的。然后剩下的步驟就是一個干凈的和標(biāo)準(zhǔn)的Transformer編碼器和解碼器。
在圖像patch的嵌入中加入位置嵌入,通過不同的策略在全局范圍內(nèi)保留空間/位置信息。在本文中,他們嘗試了不同的空間信息編碼方法,包括無位置信息編碼、1D/2D位置嵌入編碼和相對位置嵌入編碼。
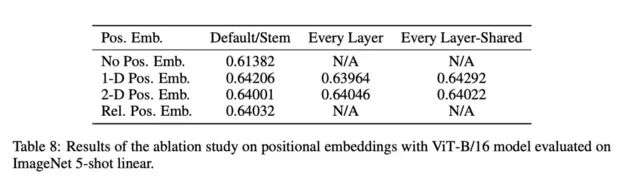
不同位置編碼策略的對比
一個有趣的發(fā)現(xiàn)是,與一維位置嵌入相比,二維位置嵌入并沒有帶來顯著的性能提升。
該模型是從多個大型數(shù)據(jù)集上刪除了重復(fù)數(shù)據(jù)預(yù)訓(xùn)練得到的,以支持微調(diào)(較小數(shù)據(jù)集)下游任務(wù)。
ILSVRC-2012 ImageNet數(shù)據(jù)集有1k類和130萬圖像 ImageNet-21k具有21k類和1400萬圖像 JFT擁有18k類和3.03億高分辨率圖像
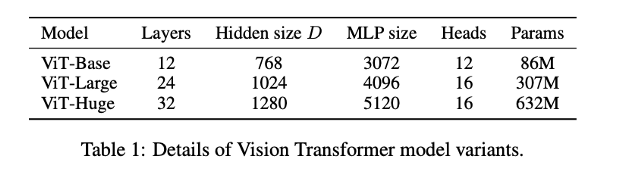
像其他流行的Transformer 模型(GPT、BERT、RoBERTa)一樣,ViT(vision transformer)也有不同的模型尺寸(基礎(chǔ)型、大型和巨大型)和不同數(shù)量的transformer層和heads。例如,ViT-L/16可以被解釋為一個大的(24層)ViT模型,具有16×16的輸入圖像patch大小。
注意,輸入的patch尺寸越小,計算模型就越大,這是因為輸入的patch數(shù)目N = HW/P*P,其中(H,W)為原始圖像的分辨率,P為patch圖像的分辨率。這意味著14 x 14的patch比16 x 16的圖像patch在計算上更昂貴。
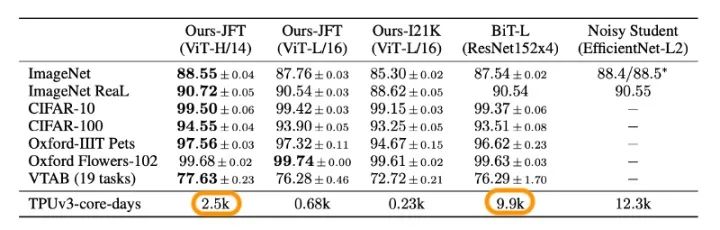
圖像分類的Benchmark
以上結(jié)果表明,該模型在多個流行的基準(zhǔn)數(shù)據(jù)集上優(yōu)于已有的SOTA模型。
在JFT-300M數(shù)據(jù)集上預(yù)訓(xùn)練的vision transformer(ViT-H/14, ViT-L/16)優(yōu)于所有測試數(shù)據(jù)集上的ResNet模型(ResNet152x4,在相同的JFT-300M數(shù)據(jù)集上預(yù)訓(xùn)練),同時在預(yù)訓(xùn)練期間占用的計算資源(TPUv3 core days)大大減少。即使是在ImageNet-21K上預(yù)訓(xùn)練的ViT也比基線表現(xiàn)更好。
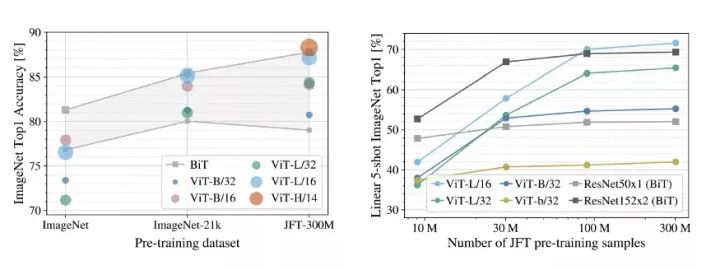
預(yù)訓(xùn)練數(shù)據(jù)集大小VS模型性能
上圖顯示了數(shù)據(jù)集大小對模型性能的影響。當(dāng)預(yù)訓(xùn)練數(shù)據(jù)集的大小較小時,ViT的表現(xiàn)并不好,當(dāng)訓(xùn)練數(shù)據(jù)充足時,它的表現(xiàn)優(yōu)于以前的SOTA。
如一開始所提到的,使用transformer進行計算機視覺的架構(gòu)設(shè)計也有不同,有的用Transformer完全取代CNNs (ViT),有的部分取代,有的將CNNs與transformer結(jié)合(DETR)。下面的結(jié)果顯示了在相同的計算預(yù)算下各個模型結(jié)構(gòu)的性能。
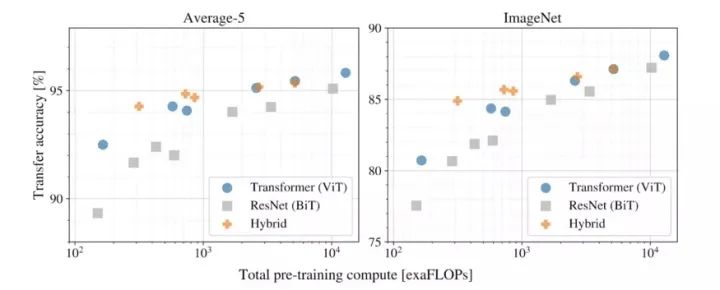
不同模型架構(gòu)的性能與計算成本
以上實驗表明:
純Transformer架構(gòu)(ViT)在大小和計算規(guī)模上都比傳統(tǒng)的CNNs (ResNet BiT)更具效率和可擴展性 混合架構(gòu)(CNNs + Transformer)在較小的模型尺寸下性能優(yōu)于純Transformer,當(dāng)模型尺寸較大時性能非常接近
使用Transformer架構(gòu)(純或混合) 輸入圖像由多個patch平鋪開來 在多個圖像識別基準(zhǔn)上擊敗了SOTA 在大數(shù)據(jù)集上預(yù)訓(xùn)練更便宜 更具可擴展性和計算效率
DETR是第一個成功地將Transformer作為pipeline中的主要構(gòu)建塊的目標(biāo)檢測框架。它與以前的SOTA方法(高度優(yōu)化的Faster R-CNN)的性能匹配,具有更簡單和更靈活的pipeline。
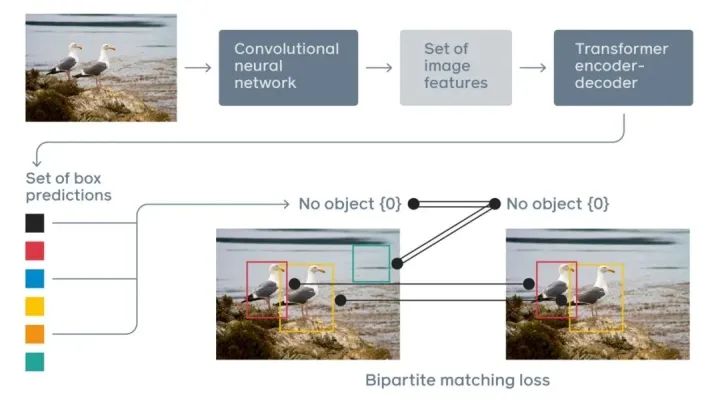
DETR結(jié)合CNN和Transformer的pipeline的目標(biāo)檢測
上圖為DETR,一種以CNN和Transformer為主要構(gòu)建塊的混合pipeline。以下是流程:
CNN被用來學(xué)習(xí)圖像的二維表示并提取特征 CNN的輸出是扁平化的,并輔以位置編碼,以饋入標(biāo)準(zhǔn)Transformer的編碼器 Transformer的解碼器通過輸出嵌入到前饋網(wǎng)絡(luò)(FNN)來預(yù)測類別和包圍框

傳統(tǒng)目標(biāo)檢測pipeline和DETR的對比
傳統(tǒng)的目標(biāo)檢測方法,如Faster R-CNN,有多個步驟進行錨的生成和NMS。DETR放棄了這些手工設(shè)計的組件,顯著地簡化了物體檢測pipeline。
在這篇論文中,他們進一步擴展了DETR的pipeline用于全景分割任務(wù),這是一個最近流行和具有挑戰(zhàn)性的像素級識別任務(wù)。為了簡單解釋全景分割的任務(wù),它統(tǒng)一了2個不同的任務(wù),一個是傳統(tǒng)的語義分割(為每個像素分配類標(biāo)簽),另一個是實例分割(檢測并分割每個對象的實例)。使用一個模型架構(gòu)來解決兩個任務(wù)(分類和分割)是非常聰明的想法。
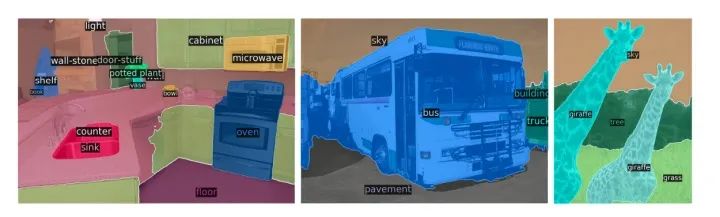
像素級別的全景分割
上圖顯示了全景分割的一個例子。通過DETR的統(tǒng)一pipeline,它超越了非常有競爭力的基線。
下圖顯示了Transformer解碼器對預(yù)測的注意力。不同物體的注意力分數(shù)用不同的顏色表示。
通過觀察顏色/注意力,你會驚訝于模型的能力,通過自注意在全局范圍內(nèi)理解圖像,解決重疊的包圍框的問題。尤其是斑馬腿上的橙色,盡管它們與藍色和綠色局部重疊,但還是可以很好的分類。

預(yù)測物體的解碼器注意力可視化
使用Transformer得到更簡單和靈活的pipeline 在目標(biāo)檢測任務(wù)上可以匹配SOTA 并行的更有效的直接輸出最終的預(yù)測集 統(tǒng)一的目標(biāo)檢測和分割架構(gòu) 大目標(biāo)的檢測性能顯著提高,但小目標(biāo)檢測性能下降
Image GPT是一個在像素序列上用圖像補全訓(xùn)練的GPT-2 transformer 模型。就像一般的預(yù)訓(xùn)練的語言模型,它被設(shè)計用來學(xué)習(xí)高質(zhì)量的無監(jiān)督圖像表示。它可以在不知道輸入圖像二維結(jié)構(gòu)的情況下自回歸預(yù)測下一個像素。
來自預(yù)訓(xùn)練的圖像GPT的特征在一些分類基準(zhǔn)上取得了最先進的性能,并在ImageNet上接近最先進的無監(jiān)督精度。
下圖顯示了由人工提供的半張圖像作為輸入生成的補全模型,隨后是來自模型的創(chuàng)造性補全。

來自Image GPT的圖像補全
Image GPT的要點:
使用與NLP中的GPT-2相同的transformer架構(gòu) 無監(jiān)督學(xué)習(xí),無需人工標(biāo)記 需要更多的計算來生成有競爭力的表示 學(xué)習(xí)到的特征在低分辨率數(shù)據(jù)集的分類基準(zhǔn)上實現(xiàn)了SOTA性能
Transformer在自然語言處理中的巨大成功已經(jīng)在計算機視覺領(lǐng)域得到了探索,并成為一個新的研究方向。
Transformer被證明是一個簡單和可擴展的框架,用于計算機視覺任務(wù),如圖像識別、分類和分割,或僅僅學(xué)習(xí)全局圖像表示。 與傳統(tǒng)方法相比,在訓(xùn)練效率上具有顯著優(yōu)勢。 在架構(gòu)上,可以采用純Transformer的方式使用,也可以與cnn結(jié)合使用混合的方式使用。 它也面臨著挑戰(zhàn),比如在DETR中檢測小目標(biāo)的性能較低,在Vision Transformer (ViT)中,當(dāng)預(yù)訓(xùn)練數(shù)據(jù)集較小時,性能也不是很好。 Transformer正在成為學(xué)習(xí)序列數(shù)據(jù)(包括文本、圖像和時間序列數(shù)據(jù))的更通用的框架。
英文原文:
https://towardsdatascience.com/transformer-in-cv-bbdb58bf335e
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~