
復旦邱錫鵬教授:2020最新NLP預訓練模型綜述

新智元報道
新智元報道
編輯:SF
【新智元導讀】本文該綜述系統(tǒng)地介紹了nlp中的預訓練模型,深入盤點了目前主流的預訓練模型,提出了一種預訓練模型的分類體系。
本篇文章主要介紹邱錫鵬老師在2020年發(fā)表的一篇預訓練模型的綜述:「Pre-trained Models for Natural Language Processing: A survey」。
該綜述系統(tǒng)地介紹了nlp中的預訓練模型。主要的貢獻包括:
表征的類型,即:是否上下文感知
編碼器結(jié)構(gòu),如:LSTM、CNN、Transformer
預訓練任務類型,如:語言模型LM,帶掩碼的語言模型MLM,排列語言模型PLM,對比學習等
針對特定場景的拓展和延伸。如:知識增強預訓練,多語言預訓練,多模態(tài)預訓練和模型壓縮等
3、如何將PTMs學到的知識遷移到下游的任務中。
4、收集了目前關(guān)于PTMs的學習資料。
5、指明PTMs未來的研究方向,如:局限、挑戰(zhàn)、建議。
由于篇幅原因,本文主要針對前面兩點進行梳理,即「目前主流的預訓練模型」和「預訓練模型的分類體系」。

背景
「nlp、cv領(lǐng)域的傳統(tǒng)方法極度依賴于手動特征工程」。例如nlp中的log-linear、CRF模型等,cv中各種抽取特征的模型,如sift特征等。深度學習中本質(zhì)上是一種表示學習,能夠一定程度上避免手動的特征工程。
究其原因,主要得益于深度學習中一系列很強大的特征提取器,如CNN、RNN、Transformer等,這些特征提取器能夠有效地捕獲原始輸入數(shù)據(jù)中所蘊含的特點和規(guī)律。
nlp領(lǐng)域的發(fā)展比cv領(lǐng)域相對緩慢的原因是什么呢?
相比于cv領(lǐng)域,「nlp領(lǐng)域的劣勢在于有監(jiān)督數(shù)據(jù)集大小非常小」(除了機器翻譯),導致深度學習模型容易過擬合,不能很好地泛化。

但是相反,nlp領(lǐng)域的優(yōu)勢在于,存在大量的無監(jiān)督數(shù)據(jù)集,如果能夠充分利用這類數(shù)據(jù)進行訓練,那么勢必能夠提升模型的能力以及在下游任務中的表現(xiàn)。
nlp中的預訓練模型就是這樣一類能夠在大規(guī)模語料上進行無監(jiān)督訓練,學習得到通用的語言表征,有助于解決下游任務的nlp模型。
那么什么是好的語言表征呢?
作者引用了Bengio的話,「好的表征能夠表達非特定任務的通用先驗知識,能夠有助于學習器來解決AI任務」
"a good representation should express general-purpose priors that are not task-speci?c but would be likely to be useful for a learning machine to solve AI-tasks."
「nlp領(lǐng)域好的文本表征則意味著能夠捕捉蘊含在文本中的隱性的語言學規(guī)則和常識性知識」
"capture the implicit linguistic rules and common sense knowledge hiding in text data, such as lexical meanings, syntactic structures, semantic roles, and even pragmatics."
目前主流的語言表征方式采用的是「分布式表征」(distributed representation),即低維實值稠密向量,每個維度沒有特定的含義,但是「整個向量表達了一種具體的概念」。預訓練模型是學習分布式表征的重要途徑之一,它的好處主要包括:
在大規(guī)模語料上進行預訓練能夠?qū)W習到「通用的語言表示」,并有助于下游任務。
提供好的模型「參數(shù)初始化」,提高泛化性和收斂速度。
在「小數(shù)據(jù)集」上可以看作是一種「正則化」,防止過擬合。
預訓練分類體系
下面將圍繞四種分類方式來介紹目前主流的預訓練模型,這些分類方式包括:
-
「表征的類型」,即:學習到的表征是否是上下文感知的; -
「編碼器結(jié)構(gòu)」,如:LSTM、Transformer; -
「預訓練任務類型」,如LM,MLM,PLM; -
「針對特定場景的拓展」,如跨語言預訓練,知識增強,多模態(tài)預訓練,模型壓縮等。
這些分類方式是交叉的,也就是說同一個模型可以劃分到多個分類體系下。
先一睹為快,這幅圖是該綜述的精華之一。下面將圍繞上述4種分類體系來介紹預訓練任務的工作。
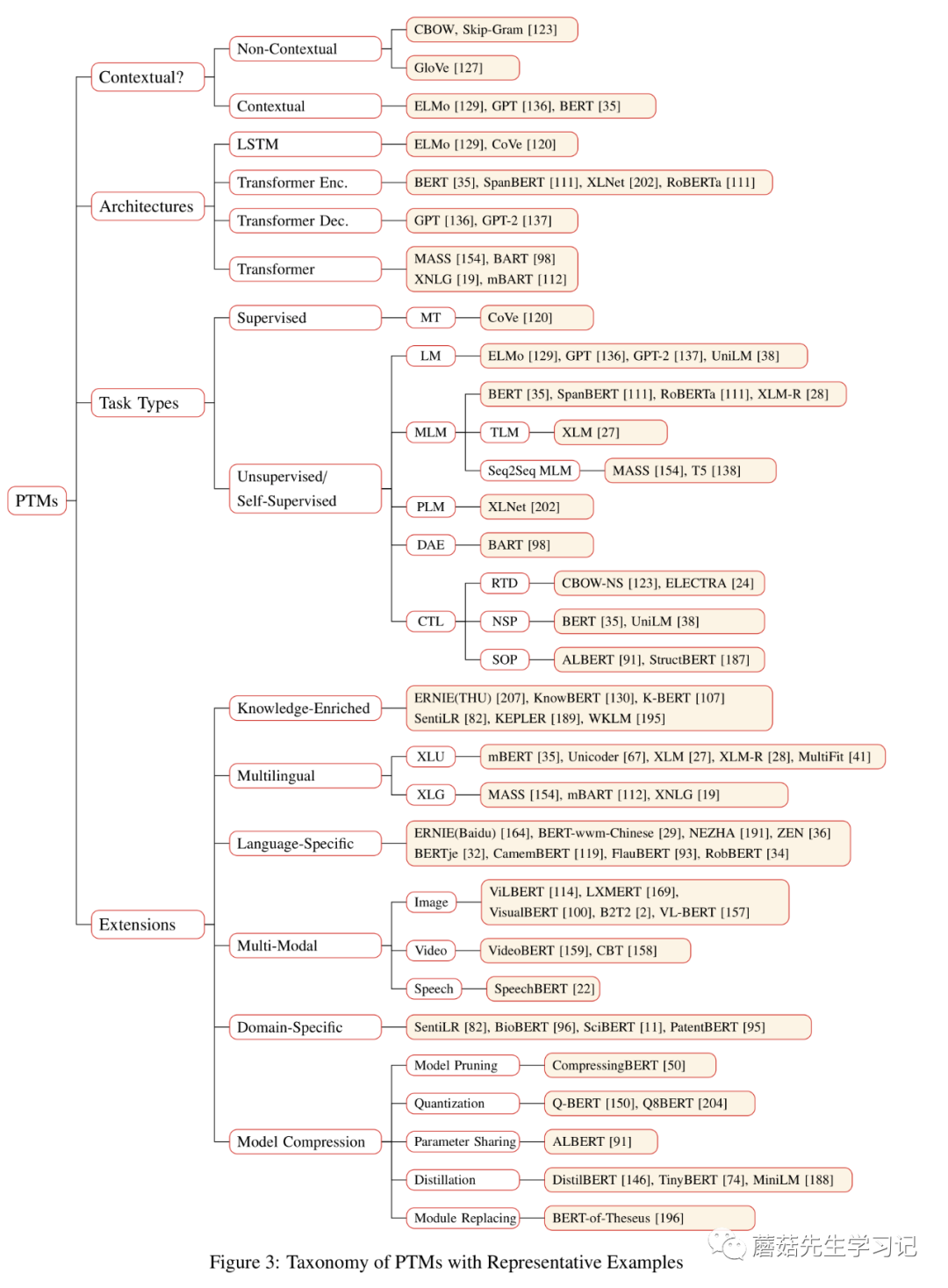
根據(jù)表征類型的不同可以分為:「非上下文感知的表征」 (Non-Contextual Representation)和「上下文感知的表征」(Contextual Representation)。上下文可以從字面上來理解,即:這個詞所在的上下文,如句子,段落等。

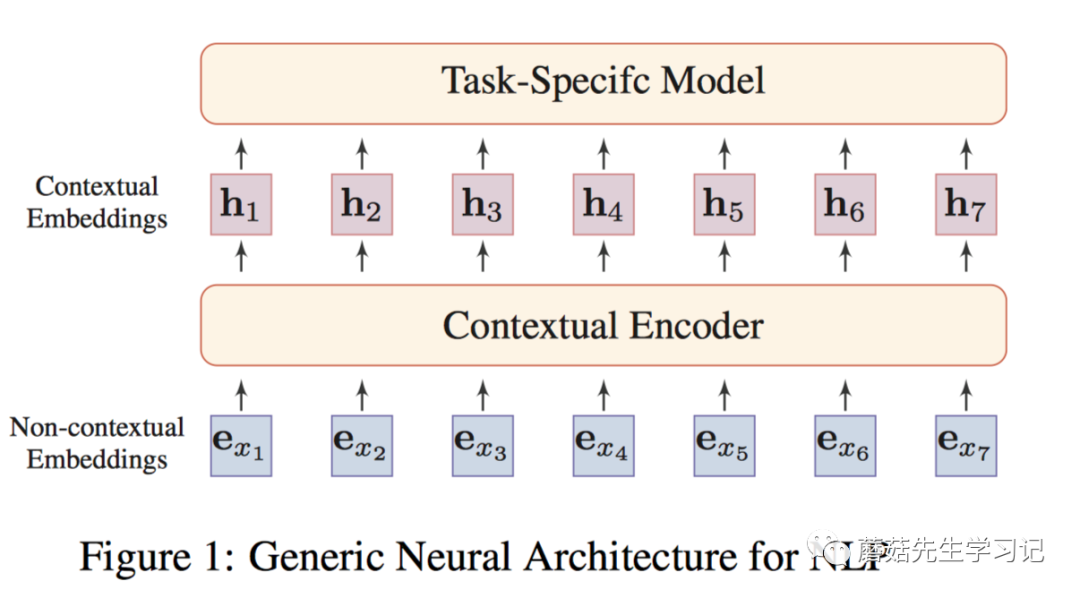
如上圖,將非上下文和上下文結(jié)合在一起。形成通用的NLP任務的架構(gòu)。
即:「非上下文感知的詞嵌入」(如word2vec訓練的embeddings),「輸入到上下文感知的Encoder」(例如:Transformer,能夠捕獲句子中詞之間的依賴關(guān)系),每個詞的表示都會融入句子中其它上下文詞的信息,得到「上下文感知的詞嵌入」。同一個詞在不同的語句中會得到不同的表示。
根據(jù)「表征類型的不同」,作者將預訓練模型的發(fā)展「主要劃分為了兩代」:
-
第一代預訓練模型由于「不是致力于解決下游任務」,主要致力于「學習好word embeddings本身,即不考慮上下文信息(context-free),只關(guān)注詞本身的語義(semantic meanings),」,同時為了計算的考慮,這些模型通常非常淺。如「Skip-Gram, GloVe」等。由于是上下文無關(guān)的,這些方法通常無法捕獲高階的概念(high-level concepts),如一詞多義,句法結(jié)構(gòu),語義角色,指代消解。代表性工作包括:「NNLM」,「word2vec」,「GloVe」。
-
第二代預訓練模型致力于學習「contextual」 word embeddings。第一代預訓練模型主要是word-level的。很自然的想法是將預訓練模型拓展到「sentence-level」或者更高層次,這種方式輸出的向量稱為contextual word embeddings,即:依賴于上下文來表示詞。此時,預訓練好的「Encoder」需要在下游任務「特定的上下文中」提取詞的表征向量。代表性工作包括兩方面,
1、僅作為特征提取器(feature extractor)
特征提取器產(chǎn)生的上下文詞嵌入表示,在下游任務訓練過程中是「固定不變」的。相當于只是把得到的上下文詞嵌入表示喂給下游任務的模型,作為「補充的特征」,只學習下游任務特定的模型參數(shù)。
代表性工作包括:
「CoVe」 用帶注意力機制的「seq2seq」從「機器翻譯任務」中預訓練一個LSTM encoder。輸出的上下文向量(CoVe)有助于提升一系列NLP下游任務的性能。
「ELMo」用「兩層的Bi-LSTM」從「雙向語言模型任務BiLM」(包括1個前向的語言模型以及1個后向的語言模型)中預訓練一個「Bi-LSTM Encoder」,能夠顯著提升一系列NLP下游任務的性能。
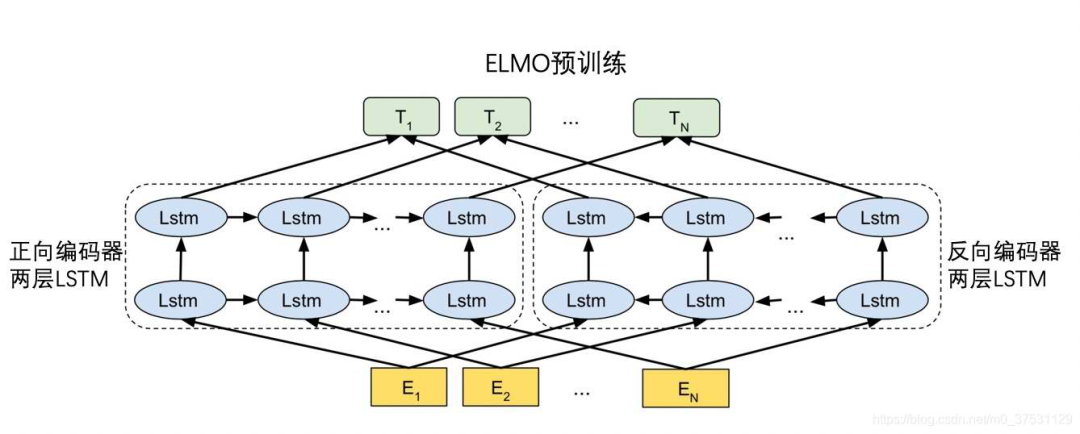
(此圖僅為示例)
2、微調(diào)(fine-tuning)
在下游任務中,「上下文編碼器」的參數(shù)也會進行微調(diào),即:把預訓練模型中的「encoder」模型結(jié)構(gòu)都提供給下游任務,這樣下游任務可以對「Encoder」的參數(shù)進行fine-tune。
代表性工作有:
「ULMFiT」(Universal Language Model Fine-tuning):通過在文本分類任務上微調(diào)預訓練好的語言模型達到了state-of-the-art結(jié)果。這篇也被認為是「預訓練模型微調(diào)」模式的開創(chuàng)性工作。
提出了3個階段的微調(diào):在通用數(shù)據(jù)上進行語言模型的預訓練來學習「通用語言特征」;在目標任務所處的領(lǐng)域特定的數(shù)據(jù)上進行語言模型的微調(diào)來學習「領(lǐng)域特征」;在目標任務上進行微調(diào)。文中還介紹了一些微調(diào)的技巧,如區(qū)分性學習率、斜三角學習率、逐步unfreezing等。

「GPT」(Generative Pre-training) :使用「單向的Transformer」預訓練「單向語言模型」。單向的Transformer里頭用到了masked self-attention的技巧(相當于是Transformer原始論文里頭的Decoder結(jié)構(gòu)),即當前詞只能attend到前面出現(xiàn)的詞上面。之所以只能用單向transformer,主要受制于單向的預訓練語言模型任務,否則會造成信息leak。

「BERT」(Bidirectional Encoder Representation from Transformer):使用雙向Transformer作為Encoder(即Transformer中的Encoder結(jié)構(gòu)),引入了新的預訓練任務,帶mask的語言模型任務MLM和下一個句子預測任務NSP。由于MLM預訓練任務的存在,使得Transformer能夠進行「雙向」self-attention。
除此之外,還有些挺有意思的工作研究「上下文嵌入」中「所融入的知識」,如語言知識、世界知識等。
對于上下文感知的Encoder,根據(jù)「架構(gòu)」的不同,可以進一步分為「3種」,
「卷積模型」 (convolutional models):通過卷積操作來匯聚目標詞的「鄰居的局部信息」,從而捕獲目標詞的語義。優(yōu)點在于容易訓練,且能夠很捕獲「局部上下文信息」。典型工作是EMNLP 2014的文章TextCNN[13],卷積網(wǎng)絡(luò)應用于nlp中特征提取的開創(chuàng)性工作。還比如Facebook在ICML2017的工作。
「序列模型」 (Sequential models):以序列的方式來捕獲詞的上下文信息。如LSTMs、GRUs。實踐中,通常采取bi-directional LSTMs或bi-directional GRUs來同時捕獲「目標詞雙向的信息」。
優(yōu)點在于能夠捕獲「整個語句序列」上的依賴關(guān)系,缺點是捕獲的「長距離依賴較弱」。典型工作是NAACL 2018的文章:「ELMo」。
「圖模型」 (Graph-based models):將詞作為圖中的結(jié)點,通過預定義的詞語之間的語言學結(jié)構(gòu)(e.g., 句法結(jié)構(gòu)、語義關(guān)系等)來學習詞語的「上下文表示」。缺點是,構(gòu)造好的圖結(jié)構(gòu)很困難,且非常依賴于專家知識或外部的nlp工具,如依存關(guān)系分析工具。典型的工作如:NAACL 2018上的工作。
作者還提到,「Transformer實際上是圖模型的一種特例」。這個觀點「醍醐灌頂」,也解釋了Transformer應用于圖神經(jīng)網(wǎng)絡(luò)中的可行性。

即:句子中的詞構(gòu)成一張全連接圖,圖中任意兩個詞之間都有連邊,連邊的權(quán)重衡量了詞之間的關(guān)聯(lián),通過「self-attention來動態(tài)計算」,目標是讓模型自動學習到圖的結(jié)構(gòu)(實際上,圖上的結(jié)點還帶了詞本身的屬性信息,如位置信息等)。
值得注意的是,Transformer在預訓練中的應用一般會拆解為3種方式,「單向的」 (即:Transformer Decoder,使用了masked self-attention防止attend到future信息),如GPT, GPT-2;「雙向的」 (即:Transformer Encoder,兩側(cè)都能attend),如Bert,XLBert等;或者「單雙向都使用」(即:Transformer)。這些編碼器的示意圖如下:
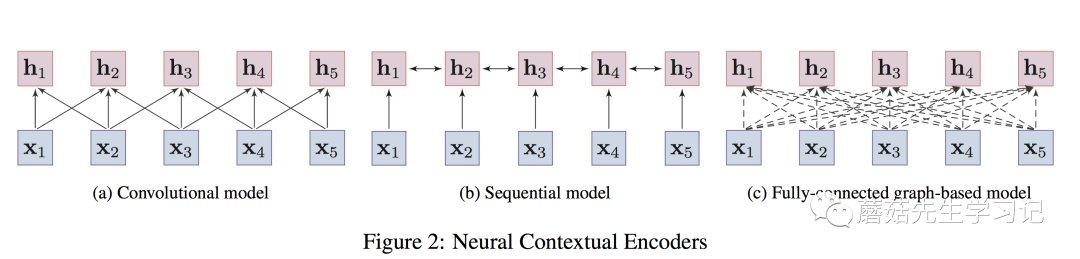
卷積編碼器只能編碼「局部的信息」到目標詞上;
序列模型能夠捕獲整個語句上的依賴關(guān)系,但「長距離依賴」較弱;
圖編碼器任意兩個詞都有連接,能夠捕獲「任意詞之間的依賴關(guān)系」,「不受距離影響。」
預訓練任務對于學習通用的表征非常重要。甚至可以說是「最重要的一環(huán)」,引導著表征學習的整個過程。作者將預訓練任務分為了3種,
「監(jiān)督學習」 (supervised learning):從"輸入-輸出pair"監(jiān)督數(shù)據(jù)中,學習輸入到輸出的映射函數(shù)。
「無監(jiān)督學習」 (unsupervised learning):從無標簽數(shù)據(jù)中學習內(nèi)在的知識,如聚類、隱表征等。
「自監(jiān)督學習」 (self-supervised learning):監(jiān)督學習和無監(jiān)督學習的折中。訓練方式是監(jiān)督學習的方式,但是輸入數(shù)據(jù)的「標簽是模型自己產(chǎn)生的」。
核心思想是,用輸入數(shù)據(jù)的一部分信息以某種形式去預測其另一部分信息(predict any part of the input from other parts in some form)。例如BERT中使用的MLM就是屬于這種,輸入數(shù)據(jù)是句子,通過句子中其它部分的單詞信息來預測一部分masked的單詞信息。
在nlp領(lǐng)域,除了機器翻譯存在大量的監(jiān)督數(shù)據(jù),能夠采用監(jiān)督學習的方式進行預訓練以外(例如CoVe利用機器翻譯預訓練Encoder,并應用于下游任務),大部分預訓練任務都是使用「自監(jiān)督學習」的方式。下面圍繞自監(jiān)督學習,來介紹主流的預訓練任務。
2.3.1 語言模型 (LM)
最著名的預訓練任務是語言模型 (Language Modeling),語言模型是指一類能夠求解句子概率的概率模型,通常通過概率論中的鏈式法則來表示整個句子各個單詞間的聯(lián)合概率。
形式化的,給定文本序列, ,其聯(lián)合概率 可以被分解為:
其中, 是特殊的token,用于標識句子的開頭 (此處應該也要有個標識句子結(jié)尾的特殊token)。 是詞典。
上述式子是典型的概率論中的鏈式法則。鏈式法則中的每個部分 是給定上下文 條件下,當前要預測的詞 在整個詞典上的條件概率分布。這意味著「當前的單詞只依賴于前面的單詞,即單向的或者自回歸的,這是LM的關(guān)鍵原理」,也是這種預訓練任務的特點。因此,LM也稱為auto-regressive LM or unidirectional LM。

對于上下文 ,可以采用神經(jīng)編碼器 來進行編碼,然后通過一個預測層來預測單詞 的條件概率分布,形式化的:

其中, 是預測層 (比如softmax全連接層),用于輸出當前單詞 在整個詞典上的條件概率分布。目標損失函數(shù)為:

2.3.2 帶掩碼的語言模型(MLM)
MLM主要是從BERT開始流行起來的,能夠解決單向的LM的問題,進行雙向的信息編碼。MLM就好比英文中的完形填空問題,需要借助語句/語篇所有的上下文信息才能預測目標單詞。

具體的做法就是隨機mask掉一些token,使用特殊符號[MASK]來替換真實的token,這個操作相當于告知模型哪個位置被mask了,然后訓練模型通過其它沒有被mask的上下文單詞的信息來預測這些mask掉的真實token。
具體實現(xiàn)時,實際上是個多分類問題,將masked的句子送入上下文編碼器Transformer中進行編碼,「[MASK]特殊token位置對應的最終隱向量」輸入到softmax分類器進行真實的masked token的預測。損失函數(shù)為:

其中, 表示句子 中被mask掉的單詞集合; 是除了masked單詞之外的其它單詞。
MLM的缺點有幾大點:
-
會造成pre-training和fine-tuning之間的「gap」。在fine-tuning時是不會出現(xiàn)pre-training時的特殊字符[MASK]。為了解決這個問題,作者對mask過程做了調(diào)整,即:在隨機挑選到的15%要mask掉的token里頭做了進一步處理。 其中,80%使用[MASK] token替換目標單詞;10%使用隨機的詞替換目標單詞;10%保持目標單詞不變。除了解決gap之外,還有1個好處,即:「預測一個詞匯時」,模型并不知道輸入對應位置的詞匯是否為正確的詞 (10%概率)。 這就迫使「模型更多地依賴于上下文信息去預測目標詞」,并且賦予了模型一定的「糾錯」能力。 
-
MLM「收斂的速度比較慢」,因為訓練過程中,一個句子只有15%的masked單詞進行預測。 -
MLM不是標準的語言模型,其有著自己的「獨立性假設(shè)」,即假設(shè)mask詞之間是相互獨立的。 -
自回歸LM模型能夠通過聯(lián)合概率的鏈式法則來計算句子的聯(lián)合概率,而MLM只能進行「聯(lián)合概率的有偏估計」(mask之間沒有相互獨立)。 MLM的變體有很多種。
2.4 預訓練的延伸方向
預訓練模型延伸出了很多新的研究方向。包括了:
-
基于「知識增強」的預訓練模型,Knowledge-enriched PTMs -
「跨語言或語言特定的」預訓練模型,multilingual or language-specific PTMs -
「多模態(tài)」預訓練模型,multi-modal PTMs -
「領(lǐng)域特定」的預訓練模型,domain-specific PTMs -
「壓縮」預訓練模型,compressed PTMs
2.4.1 基于知識增強的預訓練模型
PTMs主要學習通用語言表征,但是缺乏領(lǐng)域特定的知識。因此可以考慮把外部的知識融入到預訓練過程中,讓模型同時捕獲「上下文信息」和「外部的知識」。
早期的工作主要是將知識圖譜嵌入和詞嵌入一起訓練。從BERT開始,涌現(xiàn)了一些融入外部知識的預訓練任務。代表性工作如:
-
「SentiLR」: 引入word-level的語言學知識,包括word的詞性標簽(part-of-speech tag),以及借助于SentiWordNet獲取到的word的情感極性(sentiment polarity),然后將MLM拓展為label-aware MLM進行預訓練。
包括:給定sentence-level的label,進行word-level的知識的預測 (包括詞性和情
感極性); 基于語言學增強的上下文進行sentence-level的情感傾向預測。
作者的做法挺簡單的,就是把sentence-level label或word-level label進行embed
ding然后加到token embedding/position embedding上,類似BERT的做法。然
后,實驗表明該方法在下游的情感分析任務中能夠達到state-of-the-art水平。
-
「ERNIE (THU)」: 將知識圖譜上預訓練得到的entity embedding融入到文本中相對應的entity mention上來提升文本的表達能力。
具體而言,先利用TransE在KG上訓練學習實體的嵌入,作為外部的知識。然后用
Transformer在文本上提取文本的嵌入,將文本的嵌入以及文本上的實體對應的KG
實體嵌入進行異構(gòu)信息的融合。學習的目標包括MLM中mask掉的token的預測;
以及mask文本中的實體,并預測KG上與之對齊的實體。
類似的工作還包括KnowBERT, KEPLER等,都是通過實體嵌入的方式將知識圖譜上的結(jié)構(gòu)化信息引入到預訓練的過程中。

-
「K-BERT」 : 將知識圖譜中與句子中的實體相關(guān)的三元組信息作為領(lǐng)域知識注入到句子中,形成樹形拓展形式的句子。然后可以加載BERT的預訓練參數(shù),不需要重新進行預訓練。
也就是說,作者關(guān)注的不是預訓練,而是直接將外部的知識圖譜信息融入到句子
中,并借助BERT已經(jīng)預訓練好的參數(shù),進行下游任務的fine-tune。這里難點在
于,異構(gòu)信息的融合和知識的噪音處理,需要設(shè)計合適的網(wǎng)絡(luò)結(jié)構(gòu)融合不同向量空
間下的embedding;以及充分利用融入的三元組信息(如作者提到的soft position
和visible matrix)。
2.4.2 跨語言或語言特定的預訓練模型
這個方向主要包括了跨語言理解和跨語言生成這兩個方向。
對于「跨語言理解」,傳統(tǒng)的方法主要是學習到多種語言通用的表征,使得同一個表征能夠融入多種語言的相同語義,但是通常需要對齊的弱監(jiān)督信息。但是目前很多跨語言的工作不需要對齊的監(jiān)督信息,所有語言的語料可以一起訓練,每條樣本只對應一種語言。代表性工作包括:
-
「mBERT」:在104種維基百科語料上使用MLM預訓練,即使沒有對齊最終表現(xiàn)也非常不錯,沒有用對齊的監(jiān)督信息。 -
「XLM」:在mBERT基礎(chǔ)上引入了一個翻譯任務,即:目標語言和翻譯語言構(gòu)成的雙語言樣本對輸入到翻譯任務中進行對齊目標訓練。這個模型中用了對齊的監(jiān)督信息。 -
「XLM-RoBERTa」:和mBERT比較像,沒有用對齊的監(jiān)督信息。用了更大規(guī)模的數(shù)據(jù),且只使用MLM預訓練任務,在XNLI, MLQA, and NER.等多種跨語言benchmark中取得了SOA效果。 
對于「跨語言生成」,一種語言形式的句子做輸入,輸出另一種語言形式的句子。比如做機器翻譯或者跨語言摘要。和PTM不太一樣的是,PTM只需要關(guān)注encoder,最后也只需要拿encoder在下游任務中fine-tune,在跨語言生成中,encoder和decoder都需要關(guān)注,二者通常聯(lián)合訓練。代表性的工作包括:
「MASS」:微軟的工作,多種語言語料,每條訓練樣本只對應一種語言。在這些樣本上使用Seq2seq MLM做預訓練。在無監(jiān)督方式的機器翻譯上,效果不錯。
「XNLG」:使用了兩階段的預訓練。第一個階段預訓練encoder,同時使用單語言MLM和跨語言MLM預訓練任務。第二個階段,固定encoder參數(shù),預訓練decoder,使用單語言DAE和跨語言的DAE預訓練任務。這個方法在跨語言問題生成和摘要抽取上表現(xiàn)很好。

多模態(tài)預訓練模型,即:不僅僅使用文本模態(tài),還可以使用視覺模態(tài)等一起預訓練。目前主流的多模態(tài)預訓練模型基本是都是文本+視覺模態(tài),采用的預訓練任務是visual-based MLM,包括masked visual-feature modeling and visual-linguistic matching兩種方式,即視覺特征掩碼和視覺-語言語義對齊和匹配。這里頭關(guān)注幾個關(guān)于image-text的多模態(tài)預訓練模型。
這類預訓練模型主要用于下游視覺問答VQA和視覺常識推理VCR等。
-
「雙流模型」:在雙流模型中文本信息和視覺信息一開始先經(jīng)過兩個獨立的Encoder(Transformer)模塊,然后再通過跨encoder來實現(xiàn)不同模態(tài)信息的融合,代表性工作如:NIPS 2019, 「ViLBERT」和EMNLP 2019, 「LXMERT」。
-
「單流模型」:在單流模型中,文本信息和視覺信息一開始便進行了融合,直接一起輸入到Encoder(Transformer)中,代表性工作如:「VisualBERT」,「ImageBERT」和「VL-BERT」。
2.4.4 模型壓縮方法
預訓練模型的參數(shù)量過大,模型難以部署到線上服務。而模型壓縮能夠顯著減少模型的參數(shù)量并提高計算效率。壓縮的方法包括:
-
「剪枝」(pruning):去除不那么重要的參數(shù)(e.g. 權(quán)重、層數(shù)、通道數(shù)、attention heads)
-
「量化」(weight quantization):使用占位更少(低精度)的參數(shù)
-
「參數(shù)共享」(parameter sharing):相似模型單元間共享參數(shù)
-
「知識蒸餾」(knowledge diistillation):用一些優(yōu)化目標從原始的大型teacher模型中蒸餾出一個小的student模型。通常,teacher模型的輸出概率稱為soft label,大部分蒸餾模型讓student去擬合teacher的soft label來達到蒸餾的目的。
蒸餾之所以work,核心思想是因為「好模型的目標不是擬合訓練數(shù)據(jù),而是學習
如何泛化到新的數(shù)據(jù)」。所以蒸餾的目標是讓學生模型學習到教師模型的泛化能
力,理論上得到的結(jié)果會比單純擬合訓練數(shù)據(jù)的學生模型要好。
當然,模型壓縮通常還會結(jié)合上述多種方法,比如剪枝+蒸餾的融合方法。常見的知識蒸餾的 PTMs如下表所示。
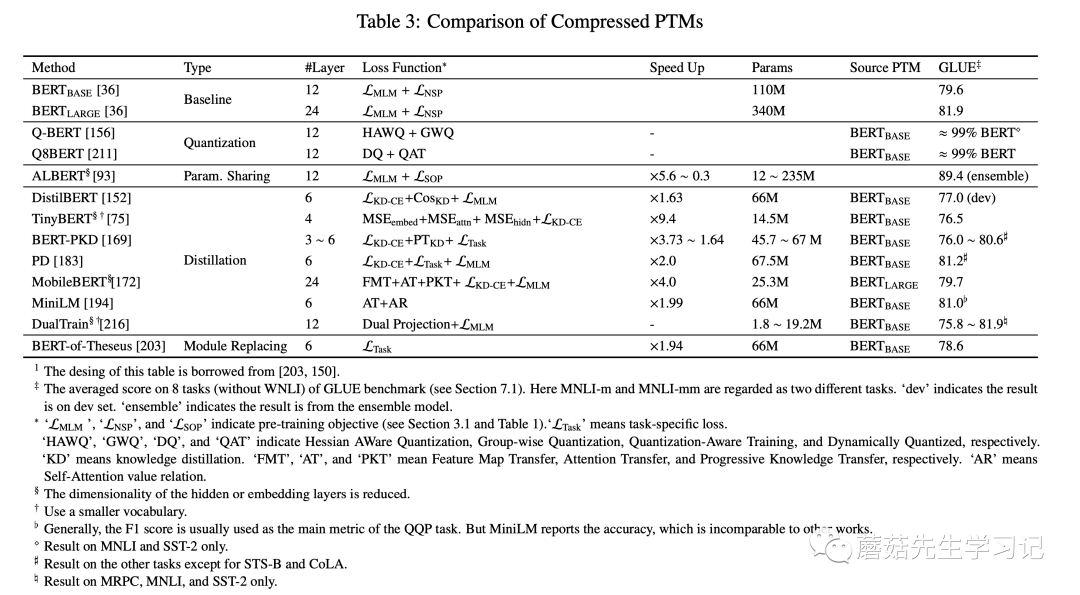
總結(jié)
本文是對邱錫鵬老師2020年的一篇預訓練模型survey的簡單梳理。主要針對survey中提到的四大類預訓練模型的分類體系做了梳洗,「這四大類預訓練模型分類體系為:」
表征的類型,即:是否上下文感知;
編碼器結(jié)構(gòu),如:LSTM、CNN、Transformer;
預訓練任務類型,如:語言模型LM,帶掩碼的語言模型MLM,排列語言模型PLM,對比學習等。
針對特定場景的拓展和延伸。如:知識增強預訓練,多語言預訓練,多模態(tài)預訓練和模型壓縮等。

