
復旦邱錫鵬組最新綜述:A Survey of Transformers!
點擊上方“程序員大白”,選擇“星標”公眾號
重磅干貨,第一時間送達


極市導讀
本文將重心放在對Transformer結構(模塊級別和架構級別)的改良上,包括對Attention模塊的諸多改良、各種位置表示方法等。
轉眼Transformer模型被提出了4年了。依靠弱歸納偏置、易于并行的結構,Transformer已經(jīng)成為了NLP領域的寵兒,并且最近在CV等領域的潛能也在逐漸被挖掘。盡管Transformer已經(jīng)被證明有很好的通用性,但它也存在一些明顯的問題,例如:
1、核心模塊自注意力對輸入序列長度有平方級別的復雜度,這使得Transformer對長序列應用不友好。例如一個簡單的32x32圖像展開就會包括1024個輸入元素,一個長文檔文本序列可能有成千上萬個字,因此有大量現(xiàn)有工作提出了輕量化的注意力變體(例如稀疏注意力),或者采用“分而治之”的思路(例如引入recurrence);
2、與卷積網(wǎng)絡和循環(huán)網(wǎng)絡不同,Transformer結構幾乎沒有什么歸納偏置。這個性質(zhì)雖然帶來很強的通用性,但在小數(shù)據(jù)上卻有更高的過擬合風險,因此可能需要引入結構先驗、正則化,或者使用無監(jiān)督預訓練。
近幾年涌現(xiàn)了很多Transformer的變體,各自從不同的角度來改良Transformer,使其在計算上或者資源需求上更友好,或者修改Transformer的部分模塊機制增大模型容量等等。但是,很多剛接觸Transformer的研究人員很難直觀地了解現(xiàn)有的Transformer變體,例如前陣子有讀者私信我問Transformer相關的問題,聊了一會兒才發(fā)現(xiàn)他不知道Transformer中的layer norm也有pre-LN和post-LN兩種變體。因此,我們認為很有必要對現(xiàn)有的各種Transformer變體做一次整理,于是產(chǎn)生了一篇survey ,現(xiàn)在掛在了arxiv上:http://arxiv.org/abs/2106.04554。
在這篇文章之前,已經(jīng)有一些很好的對PTM和Transformer應用的綜述(例如https//arxiv.org/abs/2003.082711和https://arxiv.org/abs/2012.12556),在這篇文章中,我們把重心放在對Transformer結構(模塊級別和架構級別)的改良上,包括對Attention模塊的諸多改良、各種位置表示方法等。
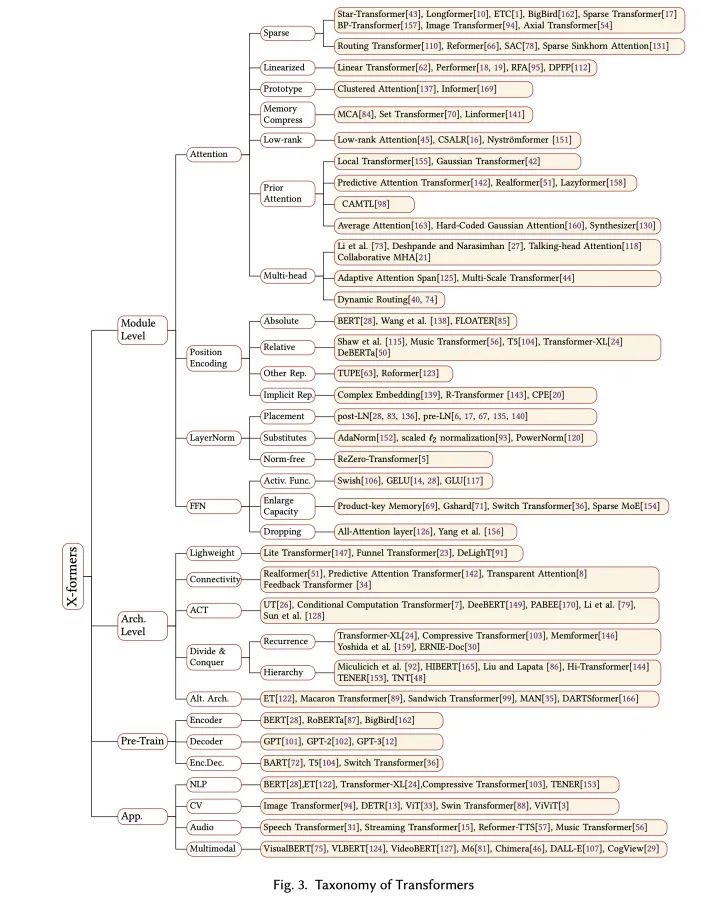
值得一提的是,Google去年放出過一篇關于Transformer的綜述(Efficient Transformers: A Survey,https://arxiv.org/abs/2009.06732),主要關注了Attention模塊的效率問題(這在我們的綜述中也覆蓋了)。雖然是一篇很好的review,但是筆者認為它對于Attention變體的分類有一些模糊,例如作者將Compressive Transformer、ETC和Longformer這一類工作、以及Memory Compressed Attention都歸類為一種基于Memory的改進,筆者認為memory在這幾種方法中各自有不同的含義,使用Memory來概括很難捕捉到方法的本質(zhì)。我們的文章對這幾個方法有不同的分類:
1、Compressive Transformer是一種“分而治之”的架構級別的改進,相當于在Transformer基礎上添加了一個wrapper來增大有效上下文的長度;
2、ETC和Longformer一類方法是一種稀疏注意力的改進,主要思路是對標準注意力代表的全鏈接二分圖的連接作稀疏化的處理;
3、Set Transformer、Memory Compressed Attention、Linformer對應一種對KV memory壓縮的方法,思路是縮短注意力矩陣的寬。
我們希望這篇文章可以給關注Transformer的同行、朋友們提供一個參考,歡迎大家閱讀:
http://arxiv.org/abs/2106.04554
如果有任何疑問或寶貴建議,歡迎通過評論、郵件或私信反饋給我們。
推薦閱讀
國產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關于程序員大白
程序員大白是一群哈工大,東北大學,西湖大學和上海交通大學的碩士博士運營維護的號,大家樂于分享高質(zhì)量文章,喜歡總結知識,歡迎關注[程序員大白],大家一起學習進步!