自提出至今,Transformer 模型已經(jīng)在自然語言處理、計(jì)算機(jī)視覺以及其他更多領(lǐng)域「大展拳腳」,學(xué)界也提出了各種各樣基于原始模型的變體。但應(yīng)看到,學(xué)界依然缺少系統(tǒng)全面的 Transformer 變體文獻(xiàn)綜述。復(fù)旦大學(xué)邱錫鵬教授團(tuán)隊(duì)的這篇綜述正好彌補(bǔ)了這一空缺。
自 2017 年 6 月谷歌發(fā)布論文《Attention is All You Need》后,Transformer 架構(gòu)為整個(gè) NLP 領(lǐng)域帶來了極大的驚喜。在誕生至今僅僅四年的時(shí)間里,Transformer 已經(jīng)成為自然語言處理領(lǐng)域的主流模型,基于 Transformer 的預(yù)訓(xùn)練語言模型更是成為主流。隨著時(shí)間的推移,Transformer 還開始了向其他領(lǐng)域的跨界。得益于深度學(xué)習(xí)的發(fā)展,Transformer 在計(jì)算機(jī)視覺(CV)和音頻處理等許多人工智能領(lǐng)域已然殺瘋了,成功地引來了學(xué)界和業(yè)界研究人員的關(guān)注目光。到目前為止,研究者已經(jīng)提出了大量且種類駁雜的 Transformer 變體(又名 X-former),但是仍然缺失系統(tǒng)而全面的 Transformer 變體文獻(xiàn)綜述。去年,谷歌發(fā)布的論文《Efficient Transformers: A Survey》對(duì)高效 Transformer 架構(gòu)展開了綜述,但主要關(guān)注 attention 模塊的效率問題,對(duì) Transformer 變體的分類比較模糊。近日,復(fù)旦大學(xué)計(jì)算機(jī)科學(xué)技術(shù)學(xué)院邱錫鵬教授團(tuán)隊(duì)對(duì)種類繁多的 X-former 進(jìn)行了綜述。首先簡(jiǎn)要介紹了 Vanilla Transformer,提出 X-former 的新分類法。接著從架構(gòu)修改、預(yù)訓(xùn)練和應(yīng)用三個(gè)角度介紹了各種 X-former。最后概述了未來研究的一些潛在方向。
論文鏈接:https://arxiv.org/pdf/2106.04554.pdfTransformer 最初是作為機(jī)器翻譯的序列到序列模型提出的,而后來的研究表明,基于 Transformer 的預(yù)訓(xùn)練模型(PTM) 在各項(xiàng)任務(wù)中都有最優(yōu)的表現(xiàn)。因此,Transformer 已成為 NLP 領(lǐng)域的首選架構(gòu),尤其是 PTM。除了語言相關(guān)的應(yīng)用,Transformer 還被用于 CV、音頻處理,甚至是化學(xué)和生命科學(xué)。由于取得了成功,過去幾年研究者又提出了各種 Transformer 變體(又名 X-former)。這些 X-former 主要從以下三個(gè)不同的角度改進(jìn)了最初的 Vanilla Transformer模型效率。應(yīng)用 Transformer 的一個(gè)關(guān)鍵挑戰(zhàn)是其處理長(zhǎng)序列時(shí)的效率低下,這主要是由于自注意力(self-attention)模塊的計(jì)算和內(nèi)存復(fù)雜度。改進(jìn)的方法包括輕量級(jí) attention(例如稀疏 attention 變體)和分而治之的方法(例如循環(huán)和分層機(jī)制);
模型泛化。由于 Transformer 是一種靈活的架構(gòu),并且對(duì)輸入數(shù)據(jù)的結(jié)構(gòu)偏差幾乎沒有假設(shè),因此很難在小規(guī)模數(shù)據(jù)上進(jìn)行訓(xùn)練。改進(jìn)方法包括引入結(jié)構(gòu)偏差或正則化,對(duì)大規(guī)模未標(biāo)記數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練等;
模型適配。這一系列工作旨在使 Transformer 適應(yīng)特定的下游任務(wù)和應(yīng)用程序。
雖然可以根據(jù)上述角度來組織 X-former,但許多現(xiàn)有的 X-former 可能會(huì)解決一個(gè)或幾個(gè)問題。例如,稀疏 attention 變體不但降低了計(jì)算復(fù)雜度,而且在輸入數(shù)據(jù)上引入了結(jié)構(gòu)先驗(yàn)以緩解小數(shù)據(jù)集上的過度擬合問題。因此,主要根據(jù) X-former 改進(jìn) Vanilla Transformer 的方式進(jìn)行分類更加有條理:架構(gòu)修改、預(yù)訓(xùn)練和應(yīng)用。考慮到本次綜述的受眾可能來自不同的領(lǐng)域,研究者主要關(guān)注的是通用架構(gòu)變體,僅簡(jiǎn)要討論了預(yù)訓(xùn)練和應(yīng)用方面的具體變體。Vanilla Transformer 是一個(gè)序列到序列的模型,由一個(gè)編碼器和一個(gè)解碼器組成,二者都是相同的塊 ?? 組成的堆棧。每個(gè)編碼器塊主要由一個(gè)多頭 self-attention 模塊和一個(gè)位置前饋網(wǎng)絡(luò)(FFN)組成。為了構(gòu)建更深的模型,每個(gè)模塊周圍都采用了殘差連接,然后是層歸一化模塊。與編碼器塊相比,解碼器塊在多頭 self-attention 模塊和位置方面 FFN 之間額外插入了 cross-attention 模塊。此外,解碼器中的 self-attention 模塊用于防止每個(gè)位置影響后續(xù)位置。Vanilla Transformer 的整體架構(gòu)如下圖所示: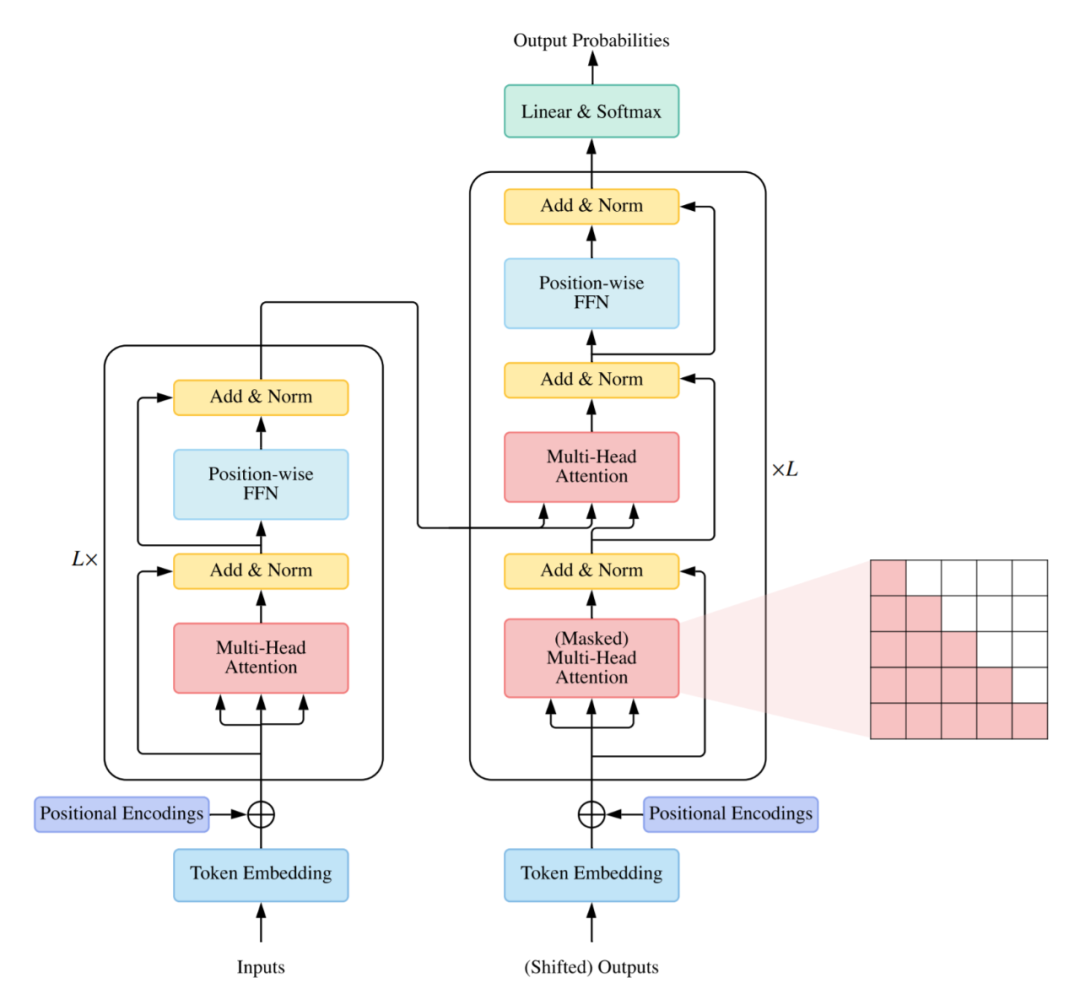
通常有三種不同的方式使用 Transformer 架構(gòu):使用編碼器 - 解碼器,通常用于序列到序列建模,例如神經(jīng)機(jī)器翻譯;
僅使用編碼器,編碼器的輸出用作輸入序列的表示,通常用于分類或序列標(biāo)記問題;
僅使用解碼器,其中也移除了編碼器 - 解碼器 cross-attention 模塊,通常用于序列生成,例如語言建模。
截止目前,領(lǐng)域研究人員從架構(gòu)修改類型、預(yù)訓(xùn)練方法和應(yīng)用這三個(gè)方面提出了各種基于 vanilla Transformer 的變體模型。下圖顯示了 這些變體模型的類別: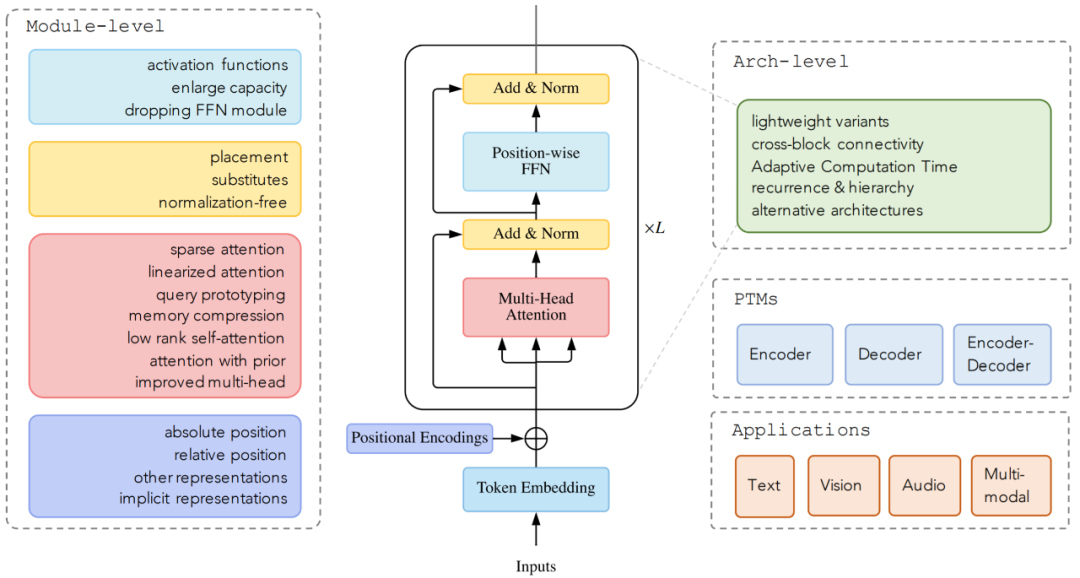
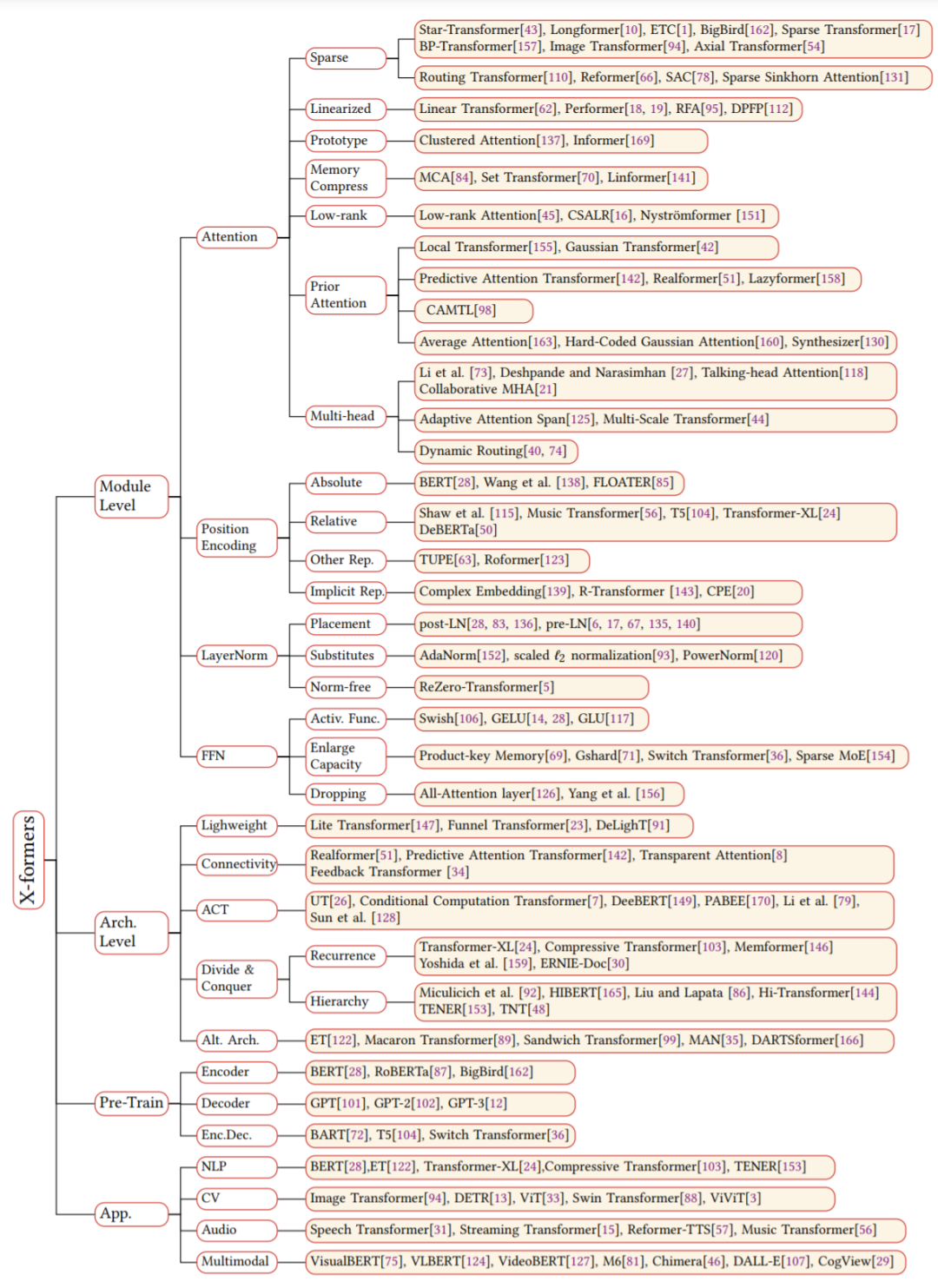
Self-attention 在 Transformer 中非常重要,但在實(shí)際應(yīng)用中存在兩個(gè)挑戰(zhàn):復(fù)雜度。self-attention 的復(fù)雜度為 O(T^2·D)。因此,attention 模塊在處理長(zhǎng)序列時(shí)會(huì)遇到瓶頸;
結(jié)構(gòu)先驗(yàn)。Self-attention 對(duì)輸入沒有假設(shè)任何結(jié)構(gòu)性偏差,甚至指令信息也需要從訓(xùn)練數(shù)據(jù)中學(xué)習(xí)。因此,無預(yù)訓(xùn)練的 Transformer 通常容易在中小型數(shù)據(jù)集上過擬合。
Attention 機(jī)制的改進(jìn)可以分為以下幾個(gè)方向:稀疏 attention。將稀疏偏差引入 attention 機(jī)制可以降低了復(fù)雜性;
線性化 attention。解開 attention 矩陣與內(nèi)核特征圖,然后以相反的順序計(jì)算 attention 以實(shí)現(xiàn)線性復(fù)雜度;
原型和內(nèi)存壓縮。這類方法減少了查詢或鍵值記憶對(duì)的數(shù)量,以減少注意力矩陣的大小;
低階 self-Attention。這一系列工作捕獲了 self-Attention 的低階屬性;
Attention 與先驗(yàn)。該研究探索了用先驗(yàn) attention 分布來補(bǔ)充或替代標(biāo)準(zhǔn) attention;
改進(jìn)多頭機(jī)制。該系列研究探索了不同的替代多頭機(jī)制。
在標(biāo)準(zhǔn)的 self-attention 機(jī)制中,每個(gè) token 都需要 attend 所有其他的 token。然而,據(jù)觀察,對(duì)于經(jīng)過訓(xùn)練的 Transformer,學(xué)習(xí)到的 attention 矩陣 A 在大多數(shù)數(shù)據(jù)點(diǎn)上通常非常稀疏。因此,可以通過結(jié)合結(jié)構(gòu)偏差來限制每個(gè)查詢 attend 的查詢鍵對(duì)的數(shù)量來降低計(jì)算復(fù)雜度。從另一個(gè)角度來看,標(biāo)準(zhǔn) attention 可以被視為一個(gè)完整的二部圖,其中每個(gè)查詢從所有內(nèi)存節(jié)點(diǎn)接收信息并更新其表示。而稀疏 attention 可以看成是一個(gè)稀疏圖,其中刪除了節(jié)點(diǎn)之間的一些連接。基于確定稀疏連接的指標(biāo),研究者將這些方法分為兩類:基于位置和基于內(nèi)容的稀疏 attention。基于位置的稀疏 attention 之一是原子稀疏 attention,如下圖所示主要有五種模式。彩色方塊表示計(jì)算的 attention 分?jǐn)?shù),空白方塊表示放棄的 attention 分?jǐn)?shù)。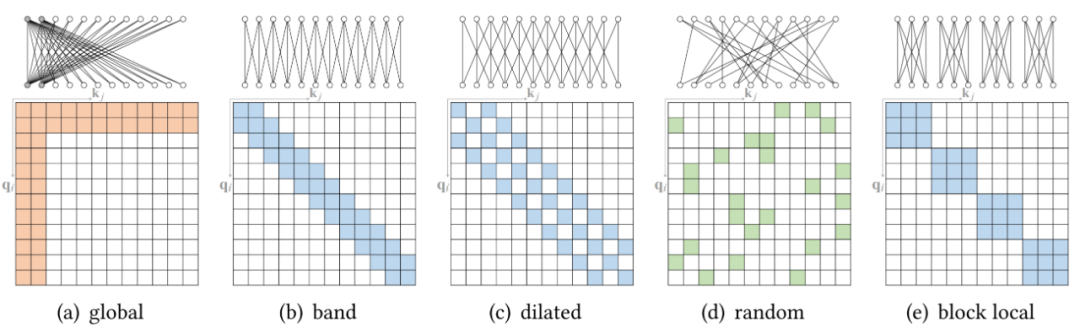
而另一種基于位置的稀疏 attention 是復(fù)合稀疏 attention,下圖顯示了其五種主要模式,其中紅色框表示序列邊界。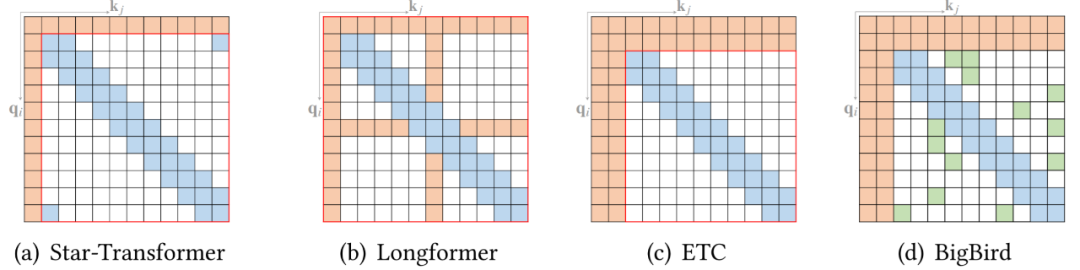
除了上述模式,一些現(xiàn)有的研究已經(jīng)針對(duì)特定數(shù)據(jù)類型探索了擴(kuò)展稀疏模式。下圖(a)展示了全局 attention 擴(kuò)展的抽象視圖,其中全局節(jié)點(diǎn)是分層組織的,任何一對(duì) token 都與二叉樹中的路徑相連。紅色框表示查詢位置,橙色節(jié)點(diǎn) / 方塊表示查詢關(guān)注相應(yīng)的 token。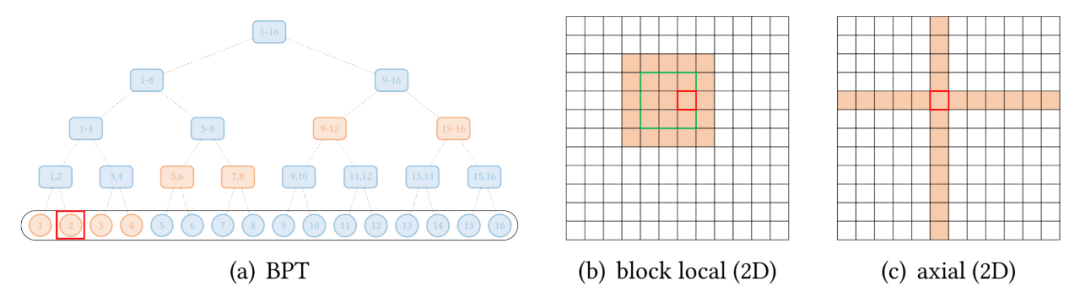
還有一些視覺數(shù)據(jù)的擴(kuò)展。Image Transformer 探索了兩種類型的 attention:- 按光柵掃描順序展平圖像像素,然后應(yīng)用塊局部稀疏 attention;
- 2D 塊局部 attention,其中查詢塊和內(nèi)存塊直接排列在 2D 板中,如上圖 (b) 所示。
視覺數(shù)據(jù)稀疏模式的另一個(gè)例子,Axial Transformer 在圖像的每個(gè)軸上應(yīng)用獨(dú)立的 attention 模塊。每個(gè) attention 模塊沿一個(gè)軸混合信息,同時(shí)保持另一個(gè)軸的信息獨(dú)立,如上圖 (c) 所示。這可以理解為按光柵掃描順序水平和垂直展平圖像像素,然后分別應(yīng)用具有圖像寬度和高度間隙的跨步 attention。下圖顯示了標(biāo)準(zhǔn) self-attention 和線性化 linear-attention 的復(fù)雜度區(qū)別。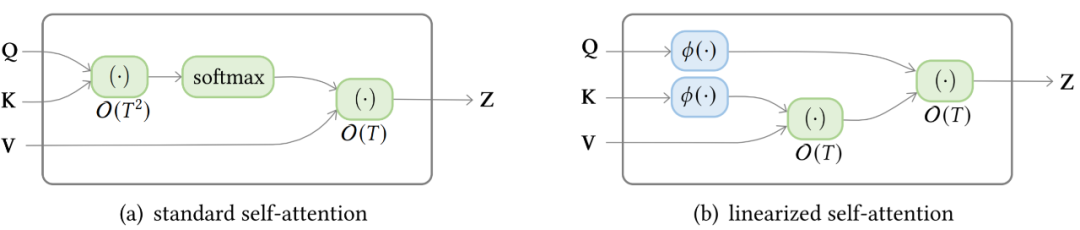
除了使用稀疏 attention 或基于內(nèi)核的線性化 attention 之外,還可以通過減少查詢或鍵值對(duì)的數(shù)量來降低 attention 的復(fù)雜度,這分別引向了查詢?cè)秃蛢?nèi)存壓縮的方法。在查詢?cè)驮O(shè)計(jì)中,幾個(gè)查詢?cè)妥鳛橛?jì)算 attention 分布的主要來源。該模型要么將分布復(fù)制到表示的查詢的位置,要么用離散均勻分布填充這些位置。下圖 (a) 說明了查詢?cè)偷挠?jì)算流程。除了通過查詢?cè)蜏p少查詢數(shù)量外,還可以通過在應(yīng)用 attention 機(jī)制之前減少鍵值對(duì)的數(shù)量(壓縮鍵值內(nèi)存)來降低復(fù)雜度,如下圖(b)所示。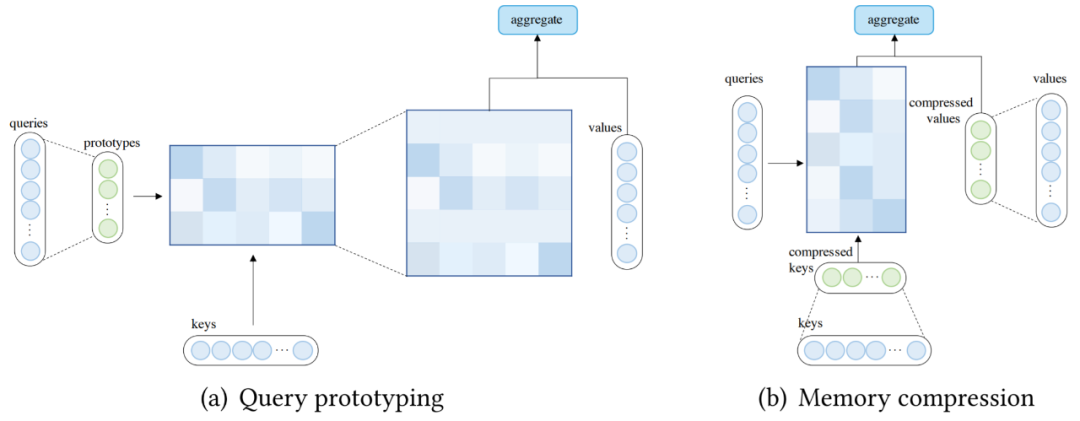
Attention 機(jī)制通常將預(yù)期值輸出為向量的加權(quán)和,其中權(quán)重是值上的 attention 分布。傳統(tǒng)上,分布是從輸入生成的,例如 Vanilla Transformer 中的 softmax(QK?)。一般情況下,attention 分布也可以來自其他來源,也就是先驗(yàn)。先驗(yàn)注意力分布可以補(bǔ)充或替代輸入產(chǎn)生的分布。Attention 的這種表述可以抽象為具有先驗(yàn) attention,如下圖所示。在大多數(shù)情況下,兩個(gè) attention 分布的融合可以通過在應(yīng)用 softmax 之前計(jì)算對(duì)應(yīng)于先驗(yàn) attention 和生成 attention 的分?jǐn)?shù)的加權(quán)和來完成。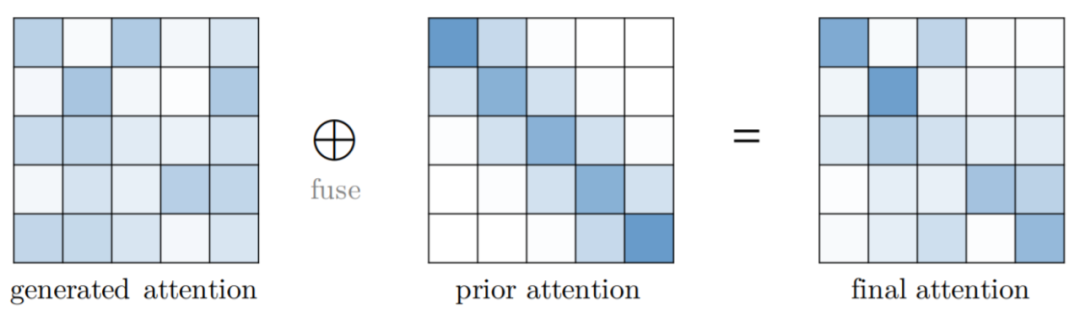
多頭 attention 的吸引力在于能夠共同 attend 來自不同位置的不同表示子空間的信息。然而,沒有機(jī)制可以保證不同的 attention 頭確實(shí)地捕捉到不同的特征。如下圖所示,多頭機(jī)制下三種跨度屏蔽函數(shù)??(??)。橫軸代表距離??,縱軸代表掩碼值。
驗(yàn)證卷積和循環(huán)網(wǎng)絡(luò)不是置換等變是很簡(jiǎn)單的。然而,Transformer 中的 self-attention 模塊和位置前饋層都是置換等變的,這在建模問題時(shí)可能是一個(gè)問題。例如,在對(duì)文本序列建模時(shí),單詞的順序很重要,因此在 Transformer 架構(gòu)中正確編碼單詞的位置至關(guān)重要。因此,需要額外的機(jī)制將位置信息注入到 Transformer 中。一種常見的設(shè)計(jì)是首先使用向量表示位置信息,然后將向量作為附加輸入注入模型。層歸一化 ( Layer Normalization, LN) 以及殘差連接被認(rèn)為是一種穩(wěn)定深度網(wǎng)絡(luò)訓(xùn)練的機(jī)制(如減輕不適定梯度和模型退化)。在 Vanilla Transformer 中,LN 層位于殘差塊之間,被稱為 post-LN 。后來的 Transformer 實(shí)現(xiàn)將 LN 層放在 attention 或 FFN 之前的殘差連接內(nèi),在最后一層之后有一個(gè)額外的 LN 來控制最終輸出的大小,即 pre-LN。Pre-LN 已被許多后續(xù)研究和實(shí)現(xiàn)所采用。pre-LN 和 post-LN 的區(qū)別如下圖所示。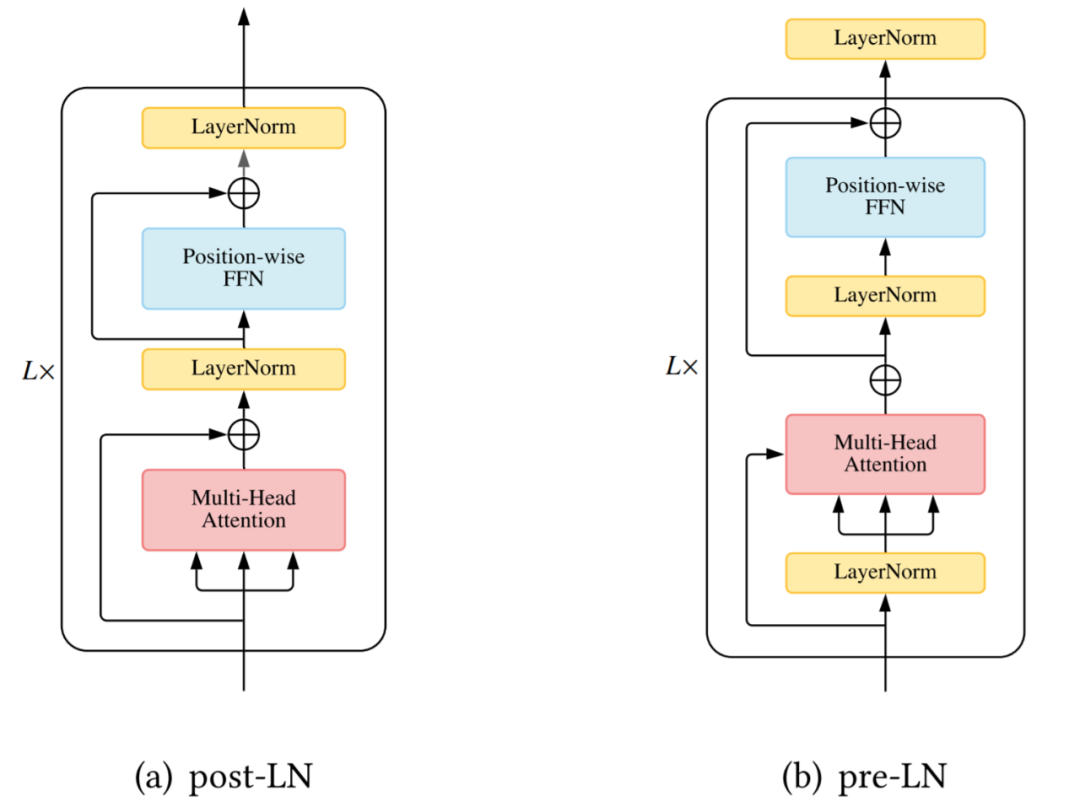
盡管很簡(jiǎn)單,但位置前饋網(wǎng)絡(luò) (feed-forward network, FFN) 層對(duì)于 Transformer 實(shí)現(xiàn)良好性能至關(guān)重要。研究者觀察到簡(jiǎn)單地堆疊 self-attention 模塊會(huì)導(dǎo)致等級(jí)崩潰問題以及 token 均勻性歸納偏差,而前饋層是緩解此問題的重要構(gòu)建塊之一。本節(jié)探索了研究者對(duì) FFN 模塊的修改。在本章中,研究者介紹了架構(gòu)層面的 X-former 變體模型。除了在模塊層面為減輕計(jì)算開銷所做的努力外,領(lǐng)域內(nèi)還出現(xiàn)了一些在更高層面進(jìn)行修改的輕量級(jí) Transformer 模型,如 Lite Transformer、Funnel Transformer 和 DeLighT。 Strengthening Cross-Block Connectivity 在 deep Transformer 編碼器 - 解碼器模型中,解碼器中的 cross-attention 模塊僅利用編碼器的最終輸出,因此誤差信號(hào)必須沿著編碼器的深度進(jìn)行遍歷。這使得 Transformer 更易于受到梯度消失等優(yōu)化問題的影響。Transparent Attention [8] 使用每個(gè) cross-attention 模塊中所有編碼器層(包括嵌入層)上的編碼器表示的加權(quán)和。對(duì)于第 j 個(gè)編碼器塊,cross-attention 應(yīng)表示如下: 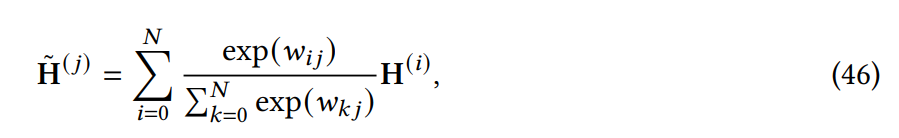
Feedback Transformer[34] 提出在 Transformer 解碼器添加反饋機(jī)制,其中每個(gè)位置均關(guān)注來自所有層的歷史表示的加權(quán)和: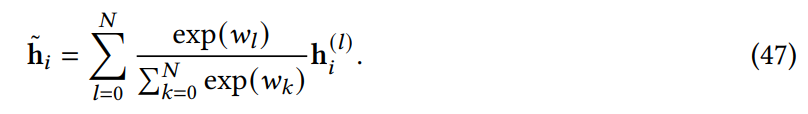
與大多數(shù)神經(jīng)模型一樣,Vanilla Transformer 使用固定(學(xué)習(xí)的)計(jì)算程序來處理每個(gè)輸入。一個(gè)有趣且有發(fā)展?jié)摿Φ男薷氖鞘褂?jì)算時(shí)間以輸入為條件,即在 Transformer 模型中引入自適應(yīng)計(jì)算時(shí)間(Adaptive Computation Time, ACT)。如下圖 12(a)所示,Universal Transformer (UT) 結(jié)合了深度循環(huán)(recurrence-over-depth)機(jī)制,該機(jī)制使用一個(gè)在深度上共享的模塊來迭代地改進(jìn)所有符號(hào)的表示;圖 12(b)中,Conditional Computation Transformer (CCT) 在每個(gè)自注意力和前饋層添加一個(gè)門控模塊來決定是否跳過當(dāng)前層;圖 12(c)中,與 UT 中使用的動(dòng)態(tài)停機(jī)機(jī)制類似,有一條工作線專門用于調(diào)整每個(gè)輸入的層數(shù)以實(shí)現(xiàn)良好的速度 - 準(zhǔn)確率權(quán)衡,這稱為「提前退出機(jī)制」(early exit mechanism)。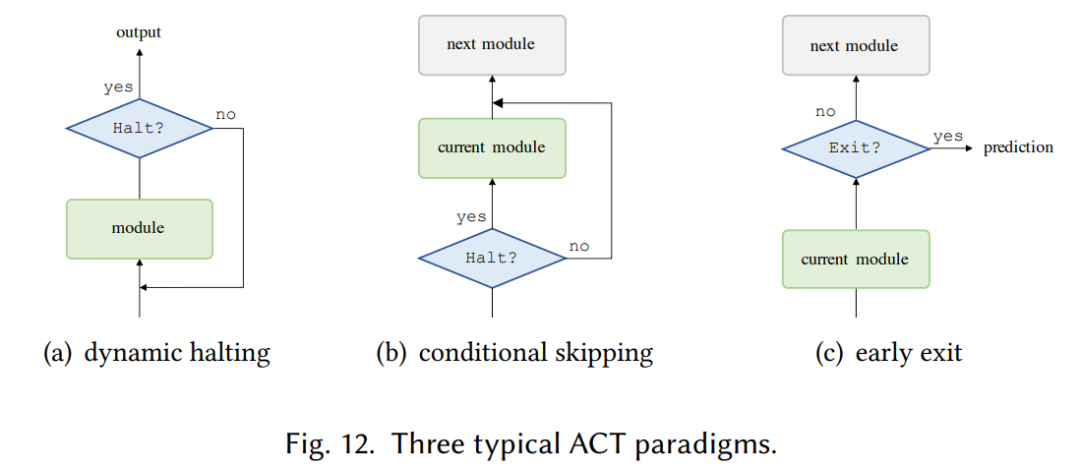
自注意力對(duì)序列長(zhǎng)度的二次復(fù)雜度會(huì)顯著限制一些下游任務(wù)的性能。研究者確定了兩類有具有代表性的方法,分別是循環(huán)和層級(jí) Transformer,具體如下圖 13 所示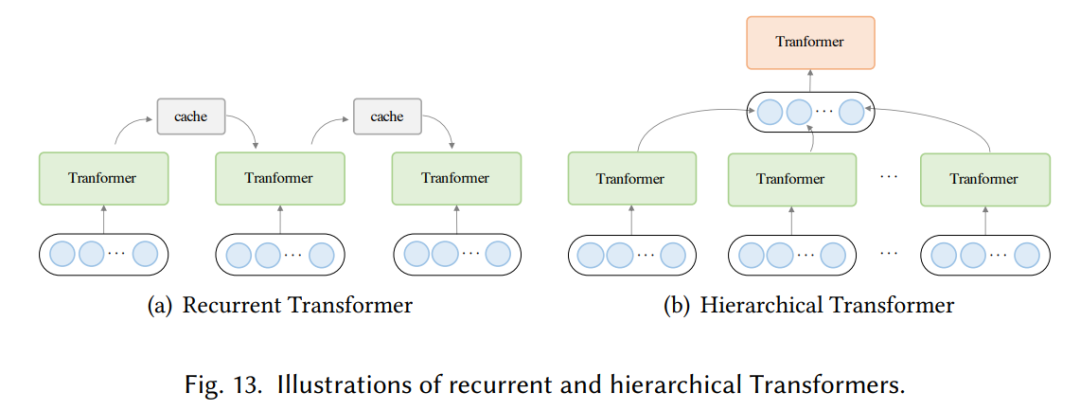
在循環(huán) Transformer 中,維護(hù)一個(gè)高速緩存(cache memory)用來合并歷史信息。在處理一段文本時(shí),該網(wǎng)絡(luò)從緩存中的讀取作為額外輸入。處理完成后,網(wǎng)絡(luò)通過簡(jiǎn)單地復(fù)制隱藏狀態(tài)或使用更復(fù)雜的機(jī)制來寫入內(nèi)存。層級(jí) Transformer 將輸入分層分解為更細(xì)粒度的元素。低級(jí)特征首先被饋入到 Transformer 編碼器,產(chǎn)生輸出表示,然后使用池化或其他操作來聚合以形成高級(jí)特征,然后通過高級(jí) Transformer 進(jìn)行處理。更多細(xì)節(jié)內(nèi)容請(qǐng)參閱原論文。往期精彩:
【原創(chuàng)首發(fā)】機(jī)器學(xué)習(xí)公式推導(dǎo)與代碼實(shí)現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學(xué)習(xí)語義分割理論與實(shí)戰(zhàn)指南.pdf
談中小企業(yè)算法崗面試
算法工程師研發(fā)技能表
真正想做算法的,不要害怕內(nèi)卷
算法工程師的日常,一定不能脫離產(chǎn)業(yè)實(shí)踐
技術(shù)學(xué)習(xí)不能眼高手低
技術(shù)人要學(xué)會(huì)自我營銷
做人不能過擬合
求個(gè)在看
