
Transformer模型有多少種變體?復旦邱錫鵬教授團隊做了全面綜述
自提出至今,Transformer 模型已經在自然語言處理、計算機視覺以及其他更多領域「大展拳腳」,學界也提出了各種各樣基于原始模型的變體。但應看到,學界依然缺少系統(tǒng)全面的 Transformer 變體文獻綜述。復旦大學邱錫鵬教授團隊的這篇綜述正好彌補了這一空缺。

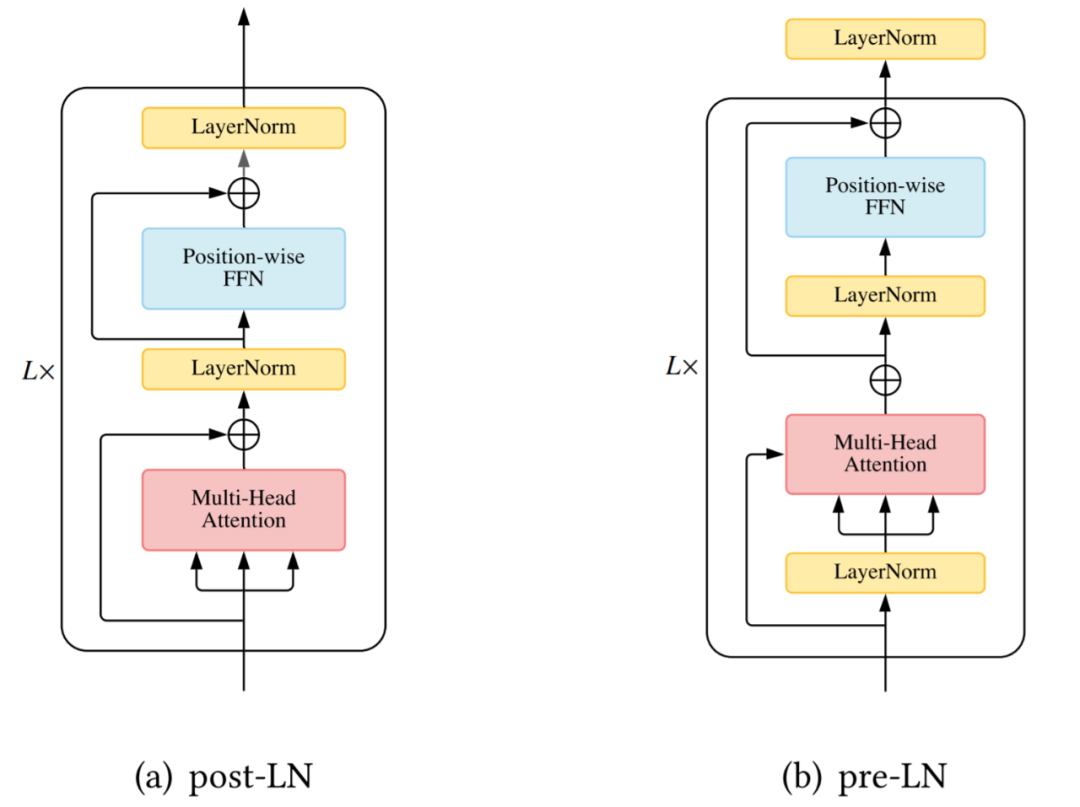
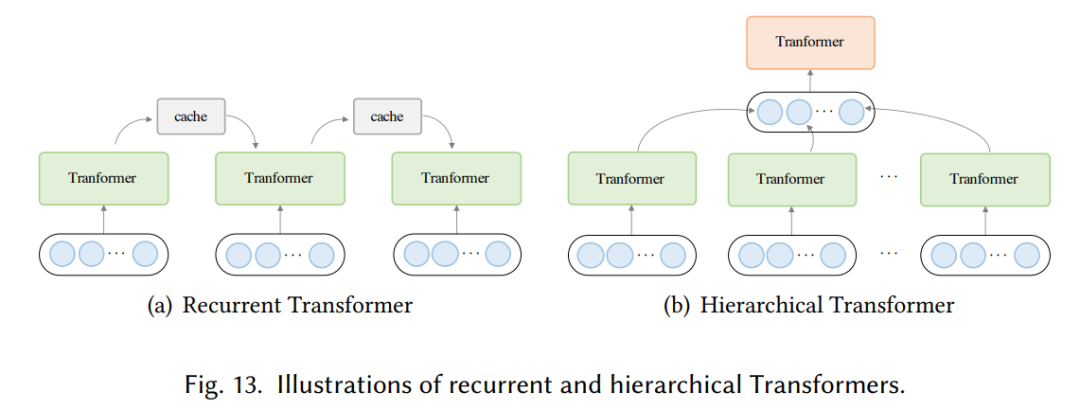
模型效率。應用 Transformer 的一個關鍵挑戰(zhàn)是其處理長序列時的效率低下,這主要是由于自注意力(self-attention)模塊的計算和內存復雜度。改進的方法包括輕量級 attention(例如稀疏 attention 變體)和分而治之的方法(例如循環(huán)和分層機制);
模型泛化。由于 Transformer 是一種靈活的架構,并且對輸入數據的結構偏差幾乎沒有假設,因此很難在小規(guī)模數據上進行訓練。改進方法包括引入結構偏差或正則化,對大規(guī)模未標記數據進行預訓練等;
模型適配。這一系列工作旨在使 Transformer 適應特定的下游任務和應用程序。
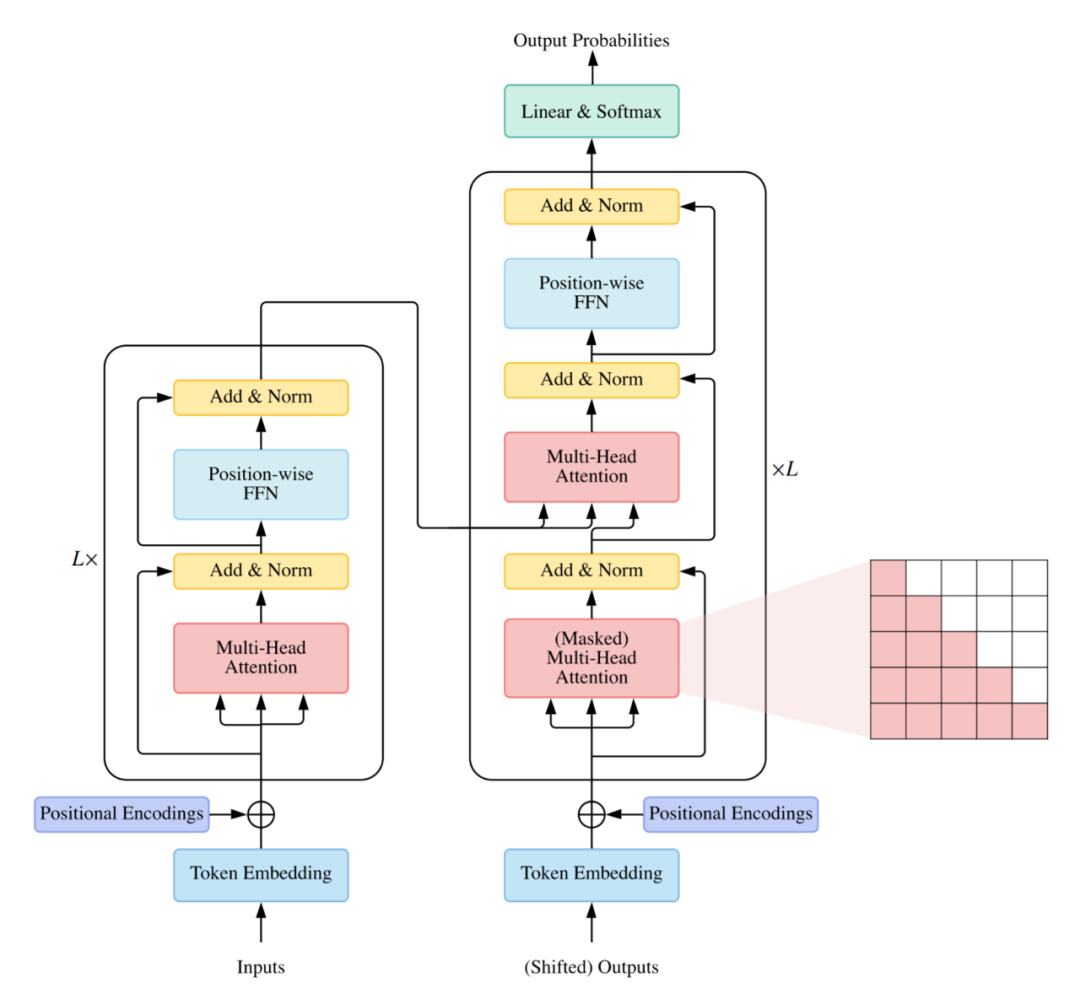
使用編碼器 - 解碼器,通常用于序列到序列建模,例如神經機器翻譯;
僅使用編碼器,編碼器的輸出用作輸入序列的表示,通常用于分類或序列標記問題;
僅使用解碼器,其中也移除了編碼器 - 解碼器 cross-attention 模塊,通常用于序列生成,例如語言建模。
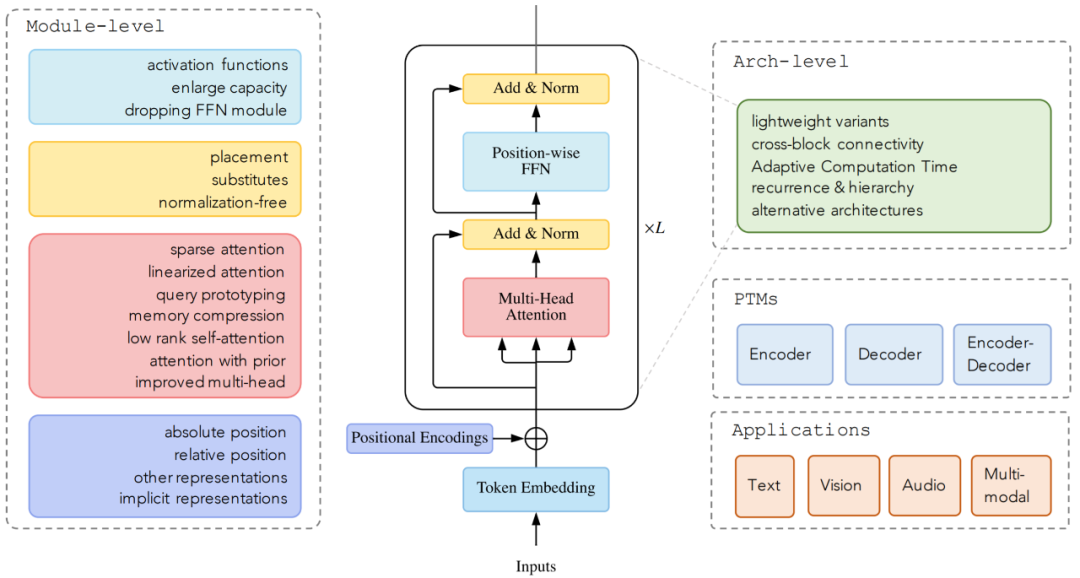
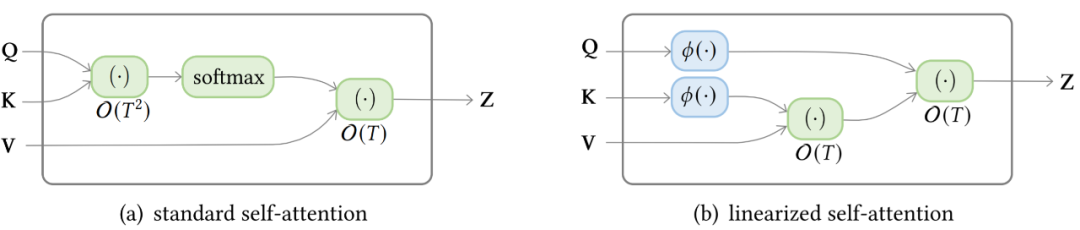
復雜度。self-attention 的復雜度為 O(T^2·D)。因此,attention 模塊在處理長序列時會遇到瓶頸;
結構先驗。Self-attention 對輸入沒有假設任何結構性偏差,甚至指令信息也需要從訓練數據中學習。因此,無預訓練的 Transformer 通常容易在中小型數據集上過擬合。
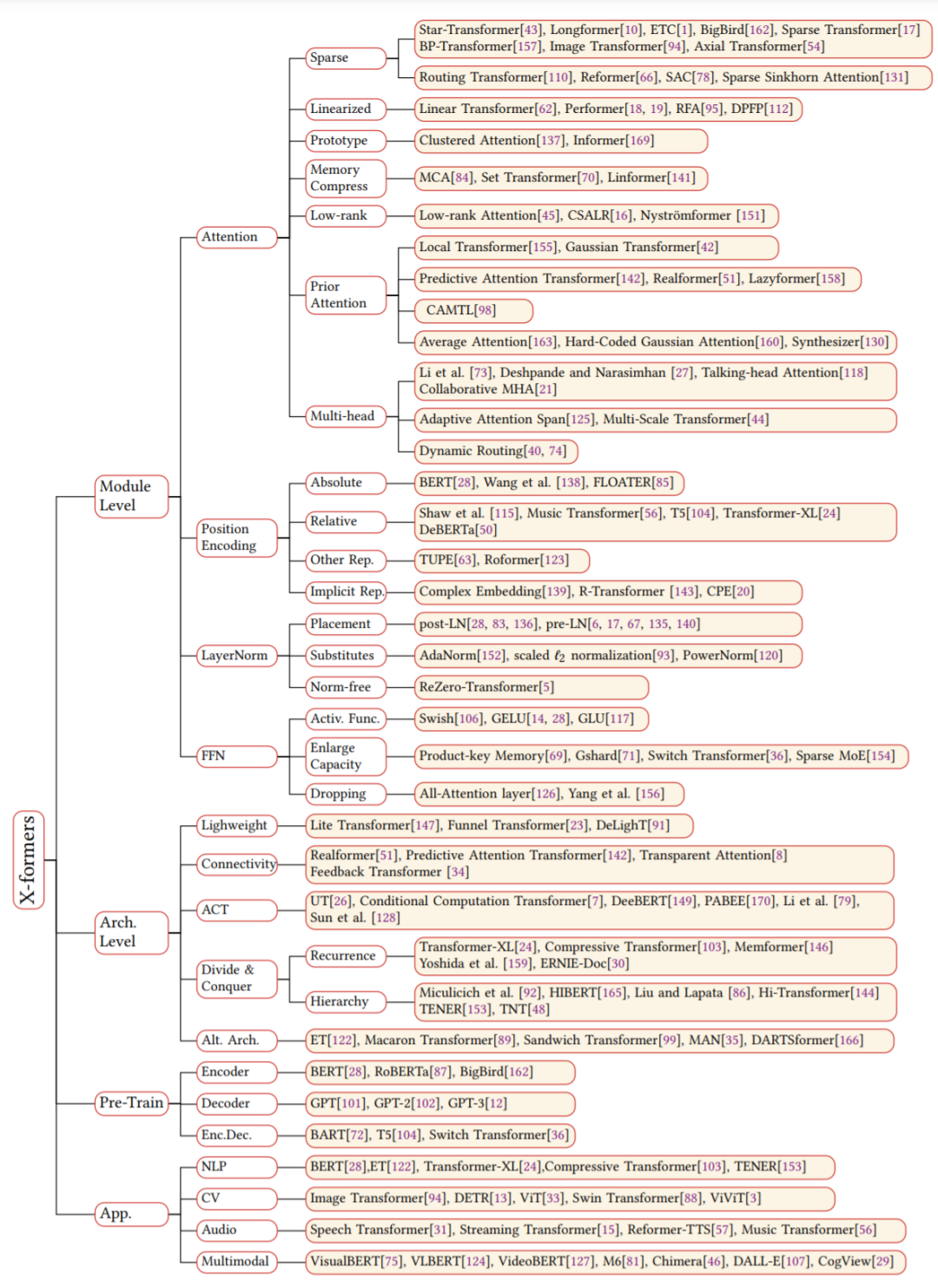
稀疏 attention。將稀疏偏差引入 attention 機制可以降低了復雜性;
線性化 attention。解開 attention 矩陣與內核特征圖,然后以相反的順序計算 attention 以實現(xiàn)線性復雜度;
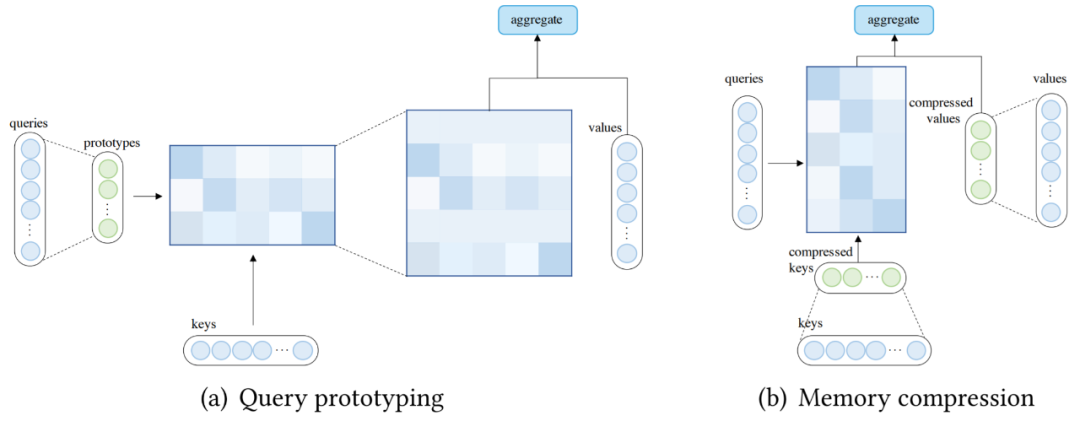
原型和內存壓縮。這類方法減少了查詢或鍵值記憶對的數量,以減少注意力矩陣的大小;
低階 self-Attention。這一系列工作捕獲了 self-Attention 的低階屬性;
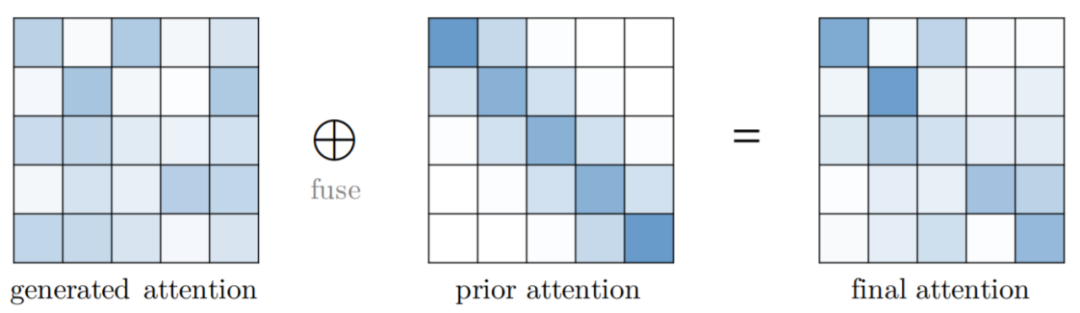
Attention 與先驗。該研究探索了用先驗 attention 分布來補充或替代標準 attention;
改進多頭機制。該系列研究探索了不同的替代多頭機制。
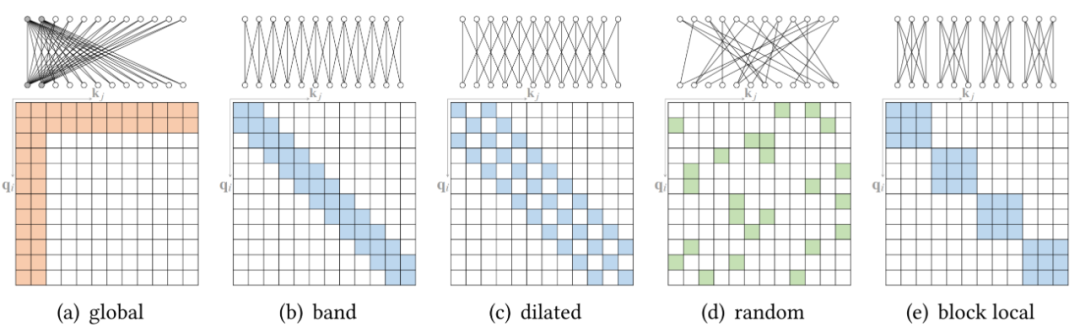
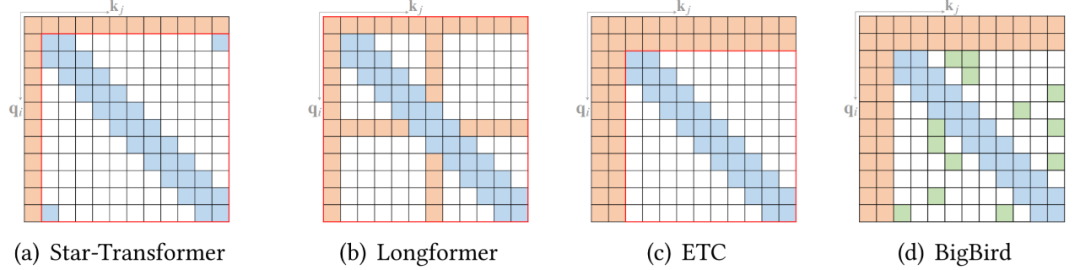
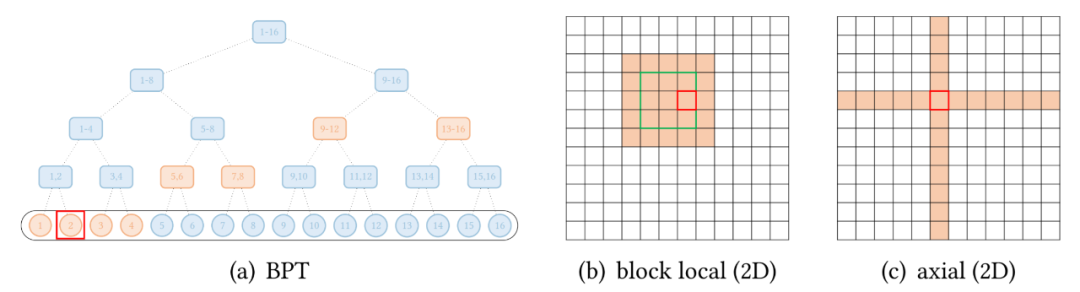
按光柵掃描順序展平圖像像素,然后應用塊局部稀疏 attention; 2D 塊局部 attention,其中查詢塊和內存塊直接排列在 2D 板中,如上圖 (b) 所示。

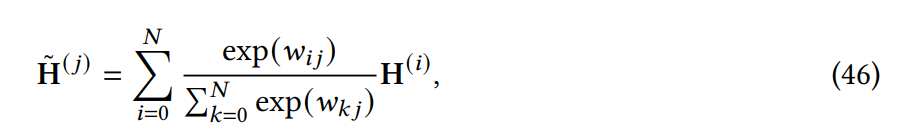
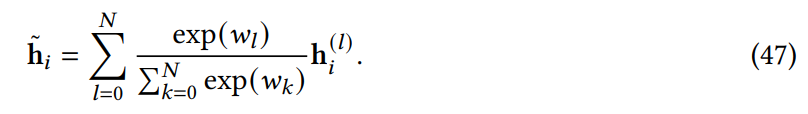
? THE END
轉載請聯(lián)系原公眾號獲得授權
投稿或尋求報道:[email protected]

點個在看 paper不斷!