
【Python】時間序列數(shù)據(jù)分析與預測之Python工具匯總
本文中總結了十多種時間序列數(shù)據(jù)分析和預測工具和python庫,在我們處理時間序列項目時,可以翻開本文,根據(jù)需要選擇合適的工具,將會事半功倍!
如果能將這些工具匯總,在以后的項目中將會很受用。這篇文章是一個時間序列工具和包的備忘錄。其中一些是非常有名的,也有些可能是第一次聽說。不過沒關系,先點贊加收藏,希望你以后會發(fā)現(xiàn)這篇文章很有用!
時間序列
時間序列是按時間順序索引的數(shù)據(jù)點序列。這是在連續(xù)時間點對同一變量的觀察。換句話說,它是在一段時間內(nèi)觀察到的一組數(shù)據(jù)。具體可以參考該文章:時間序列定義、均值、方差、自協(xié)方差及相關性、一文解讀時間序列基本概念
數(shù)據(jù)通常繪制為圖表上的一條線,x 軸為時間,y 軸為每個點的值。此外,時間序列有四個主要組成部分:
趨勢 季節(jié)性變化 周期性變化 隨機變化
一般來說,時間序列經(jīng)常被用于經(jīng)濟學、數(shù)學、生物學、物理學、氣象學等許多領域。
時間序列項目示例
股票預測
股票市場預測是一個具有挑戰(zhàn)性和吸引力的話題,其主要目標是開發(fā)多種方法和策略來預測未來的股票價格。有很多不同的技術,從經(jīng)典的算法和統(tǒng)計方法到復雜的神經(jīng)網(wǎng)絡架構。共同點是它們都利用不同的時間序列來實現(xiàn)準確的預測。股市預測方法被業(yè)余投資者、金融科技初創(chuàng)公司和大型對沖基金廣泛使用。
基本面分析著眼于公司的財務報表、管理和行業(yè)趨勢等因素。此外,它還考慮了一些宏觀經(jīng)濟指標,例如通貨膨脹率、GDP、經(jīng)濟狀況等。所有這些指標都是時間相關的,因此可以表示為時間序列。
與基本面分析相比,技術分析使用交易量、價格變化和來自市場本身的其他信息的模式來預測股票未來的表現(xiàn)。投資者在做出投資決定之前了解這兩種方法很重要。
心電異常檢測
心電圖異常檢測是一種檢測心電圖異常的技術。心電圖是一項監(jiān)測心臟電活動的測試。基本上,它是由心臟產(chǎn)生并表示為時間序列的電信號。
心電圖異常檢測是通過將心電圖的正常模式與異常模式進行比較來完成的。心電圖異常有多種類型,可分為以下幾類:
心率異常: 這是指心率在正常范圍內(nèi)的任何變化。這可能是由于心臟問題或如何刺激它。 心律異常:這是指節(jié)律與其正常模式的任何變化。這可能是由于脈沖通過心臟傳導的方式存在問題,或者它們通過心臟傳導的速度存在問題。
從學術研究到商用心電圖機,在這個主題上已經(jīng)做了很多工作,并且有一些有希望的結果。最大的問題是系統(tǒng)應該具有很高的準確性,并且不應該有任何誤報或誤報。這是由于問題的性質(zhì)和錯誤預測的后果。
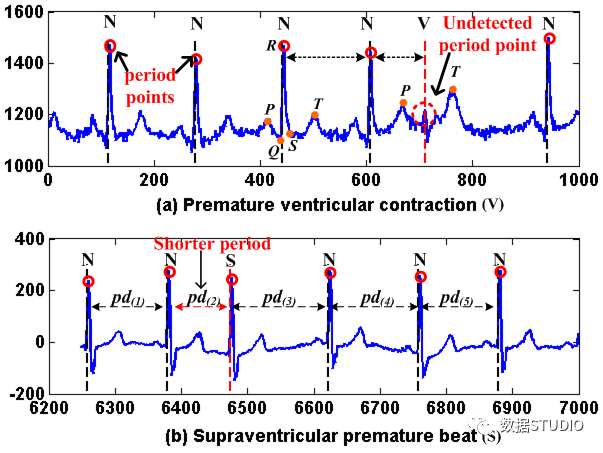
時間序列項目的工具
時間序列在各個行業(yè)中的重要性,已經(jīng)不用多說。接下來看看用于時間序列項目的Python工具都有哪些。
數(shù)據(jù)準備和特征工程工具 數(shù)據(jù)分析和可視化工具 時間序列預測工具
數(shù)據(jù)準備和特征工程
數(shù)據(jù)準備和特征工程是數(shù)據(jù)科學管道中的兩個非常重要的步驟。數(shù)據(jù)準備通常是任何數(shù)據(jù)科學項目的第一步。這是將數(shù)據(jù)轉換為可用于分析和進一步處理的形式的過程。
特征工程是從原始數(shù)據(jù)中提取特征以使其對建模和預測更有用的過程。下面,我們將提到一些用于這些任務的最流行的工具。
Pandas 的時間序列處理

Pandas 是一個用于數(shù)據(jù)操作和分析的 Python 庫。它包括用于操作數(shù)值表和時間序列的數(shù)據(jù)結構和方法。此外,它還包含廣泛的功能和特性,可用于處理所有領域的時間序列數(shù)據(jù)。
它支持來自各種文件類型的數(shù)據(jù)輸入,包括 CSV、JSON、Parquet、SQL 數(shù)據(jù)庫表和查詢以及 Microsoft Excel。此外,Pandas 允許各種數(shù)據(jù)操作功能,例如合并、重塑、選擇以及數(shù)據(jù)清理和整理。
一些常用的時間序列特征是:
日期范圍生成和頻率轉換
移動窗口統(tǒng)計
移動窗口線性回歸
日期轉換
滯后等等
NumPy 的時間序列處理

NumPy 是一個 Python 庫,它增加了對巨大的多維數(shù)組和矩陣的支持,以及可以在這些數(shù)組上使用大量高級數(shù)學運算的函數(shù)。它的語法與 MATLAB 非常相似,包括一個高性能的多維數(shù)組對象以及處理這些數(shù)組的能力。
NumPy 的 datetime64 數(shù)據(jù)類型和數(shù)組可以非常方便地表示時間序列中的日期。使用 NumPy 還可以輕松地使用線性代數(shù)運算進行各種時間序列運算。
Datetime 的時間序列處理

日期和時間的表示
日期和時間的算術
日期和時間的比較
使用此工具處理時間序列很簡單。它允許用戶將日期和時間轉換為對象并對其進行操作。例如,只需要幾行代碼,就可以從一種 DateTime 格式轉換為另一種格式,添加到日期的天數(shù)、月數(shù)或年數(shù),或者計算兩個時間對象之間的秒數(shù)差異。
Tsfresh 的時間序列處理

Tsfresh 是一個 Python 包。它會自動計算大量的時間序列特征,稱為特征。該軟件包將來自統(tǒng)計、時間序列分析、信號處理和非線性動力學的既定算法與強大的特征選擇算法相結合,以提供系統(tǒng)的時間序列特征提取。
Tsfresh 包包括一個過濾程序,以防止提取不相關的特征。此過濾程序評估每個特征對回歸或分類任務的解釋能力和重要性。
高級時間序列功能的一些示例是:
傅里葉變換組件
小波變換組件
偏自相關等
數(shù)據(jù)分析和可視化包
數(shù)據(jù)分析和可視化包是幫助數(shù)據(jù)分析師從他們的數(shù)據(jù)中創(chuàng)建圖形和圖表的工具。數(shù)據(jù)分析被定義為清理、轉換和建模數(shù)據(jù)的過程,以便發(fā)現(xiàn)對業(yè)務決策有用的信息。數(shù)據(jù)分析的目標是從數(shù)據(jù)中提取有用的信息并根據(jù)該信息做出決策。
數(shù)據(jù)的圖形表示稱為數(shù)據(jù)可視化。使用圖表和圖形等可視化元素的數(shù)據(jù)可視化工具提供了一種查看和理解數(shù)據(jù)趨勢和模式的簡便方法。
時間序列有大量的數(shù)據(jù)分析和可視化包,這里總結了其中的一些常用的工具。
Matplotlib 的時間序列可視化

用于數(shù)據(jù)可視化的最流行的 Python 包可能是 Matplotlib。它用于創(chuàng)建靜態(tài)、動畫和交互式可視化。使用 Matplotlib 可以做一些事情,例如:
制作適合出版的地塊 創(chuàng)建可以放大、平移和更新的交互式圖形 改變視覺風格和布局
Plotly 時間序列可視化

Plotly 是一個交互式、開源和基于瀏覽器的 Python 和 R 圖形庫。它是一個高級的聲明性圖表庫,具有 30 多種圖表類型,包括科學圖表、3D 圖表、統(tǒng)計圖表、SVG 地圖、金融圖表等等。
除此之外,使用 Plotly 還可以繪制基于時間序列的交互式圖表,例如折線圖、甘特圖、散點圖等。
Statsmodels 時間序列可視化

Statsmodels 是一個 Python 包,它提供了用于估計各種統(tǒng)計模型以及運行統(tǒng)計測試和統(tǒng)計數(shù)據(jù)分析的類和函數(shù)。
它為時間序列分解及其可視化提供了一種非常方便的方法。使用這個包,可以輕松分解任何時間序列并分析其組成部分,例如趨勢、季節(jié)性組成部分以及殘差或噪聲。
statsmodels 庫在名為seasonal_decompose()的函數(shù)中提供了簡單或經(jīng)典分解方法的實現(xiàn)。它要求你指定模型是加法還是乘法。seasonal_decompose() 函數(shù)返回一個結果對象。結果對象以數(shù)組形式提供對趨勢和季節(jié)性系列的訪問。它還提供了對殘差的訪問,殘差是趨勢之后的時間序列,并且去除了季節(jié)性成分。
時間序列預測包
時間序列項目中最重要的部分可能是預測。預測是根據(jù)當前和過去的數(shù)據(jù)預測未來事件的過程。它基于這樣一種假設,即未來可以從過去實現(xiàn)。此外,它假設數(shù)據(jù)中有一些模式可用于預測接下來會發(fā)生什么。
時間序列預測的方法有很多種,從簡單的線性回歸和基于 ARIMA 的方法開始,到復雜的多層神經(jīng)網(wǎng)絡或集成模型。在這里,我們將展示一些支持不同類型模型的包。
使用 Statsmodels 進行時間序列預測
Statsmodels 是我們在數(shù)據(jù)可視化工具一節(jié)中已經(jīng)提到的一個包。但是,這是一個更相關的預測包。基本上,這個包提供了一系列統(tǒng)計模型和假設檢驗。
Statsmodels 包還包括用于時間序列分析的模型類和函數(shù)。自回歸移動平均模型 (ARMA) 和向量自回歸模型 (VAR) 是基本模型的示例。馬爾可夫切換動態(tài)回歸和自回歸是非線性模型的示例。它還包括時間序列描述性統(tǒng)計,例如自相關、偏自相關函數(shù)和周期圖,以及 ARMA 或相關過程的理論性質(zhì)。
Statsmodels[8] 描述了如何使用 Statsmodels 包開始使用時間序列。
使用 Pmdarima 進行時間序列預測

Pmdarima 是一個統(tǒng)計庫,有助于使用基于 ARIMA 的方法對時間序列進行建模。除此之外,它還具有其他功能,例如:
一組平穩(wěn)性和季節(jié)性的統(tǒng)計檢驗
各種內(nèi)生和外生變壓器,包括 Box-Cox 和傅里葉變換
季節(jié)性時間序列、交叉驗證實用程序和其他工具的分解
也許這個庫最有用的工具是 Auto-Arima 模塊,它在提供的約束內(nèi)搜索所有可能的 ARIMA 模型,并根據(jù) AIC 或 BIC 值返回最佳模型。
這個包不是很常見,這里給出一個簡單的例子:
上下滑動查看更多源碼
import?pmdarima?as?pm
from?pmdarima?import?model_selection
import?matplotlib.pyplot?as?plt
import?numpy?as?np
#?加載數(shù)據(jù)并將其拆分為單獨的部分
data?=?pm.datasets.load_lynx()
train,?test?=?model_selection.train_test_split(data,?train_size=100)
#?fit一些驗證(cv)樣本
arima?=?pm.auto_arima(train,?start_p=1,?start_q=1,?d=0,?max_p=5,?max_q=5,
??????????????????????out_of_sample_size=10,?suppress_warnings=True,
??????????????????????stepwise=True,?error_action='ignore')
#?現(xiàn)在繪制測試集的結果和預測
preds,?conf_int?=?arima.predict(n_periods=test.shape[0],
????????????????????????????????return_conf_int=True)
fig,?axes?=?plt.subplots(2,?1,?figsize=(12,?8))
x_axis?=?np.arange(train.shape[0]?+?preds.shape[0])
axes[0].plot(x_axis[:train.shape[0]],?train,?alpha=0.75)
axes[0].scatter(x_axis[train.shape[0]:],?preds,?alpha=0.4,?marker='o')
axes[0].scatter(x_axis[train.shape[0]:],?test,?alpha=0.4,?marker='x')
axes[0].fill_between(x_axis[-preds.shape[0]:],?conf_int[:,?0],?conf_int[:,?1],
?????????????????????alpha=0.1,?color='b')
#?填寫在模型中"held?out"樣本的部分
axes[0].set_title("Train?samples?&?forecasted?test?samples")
#?現(xiàn)在將實際樣本添加到模型中并創(chuàng)建NEW預測
arima.update(test)
new_preds,?new_conf_int?=?arima.predict(n_periods=10,?return_conf_int=True)
new_x_axis?=?np.arange(data.shape[0]?+?10)
axes[1].plot(new_x_axis[:data.shape[0]],?data,?alpha=0.75)
axes[1].scatter(new_x_axis[data.shape[0]:],?new_preds,?alpha=0.4,?marker='o')
axes[1].fill_between(new_x_axis[-new_preds.shape[0]:],
?????????????????????new_conf_int[:,?0],?new_conf_int[:,?1],
?????????????????????alpha=0.1,?color='g')
axes[1].set_title("Added?new?observed?values?with?new?forecasts")
plt.show()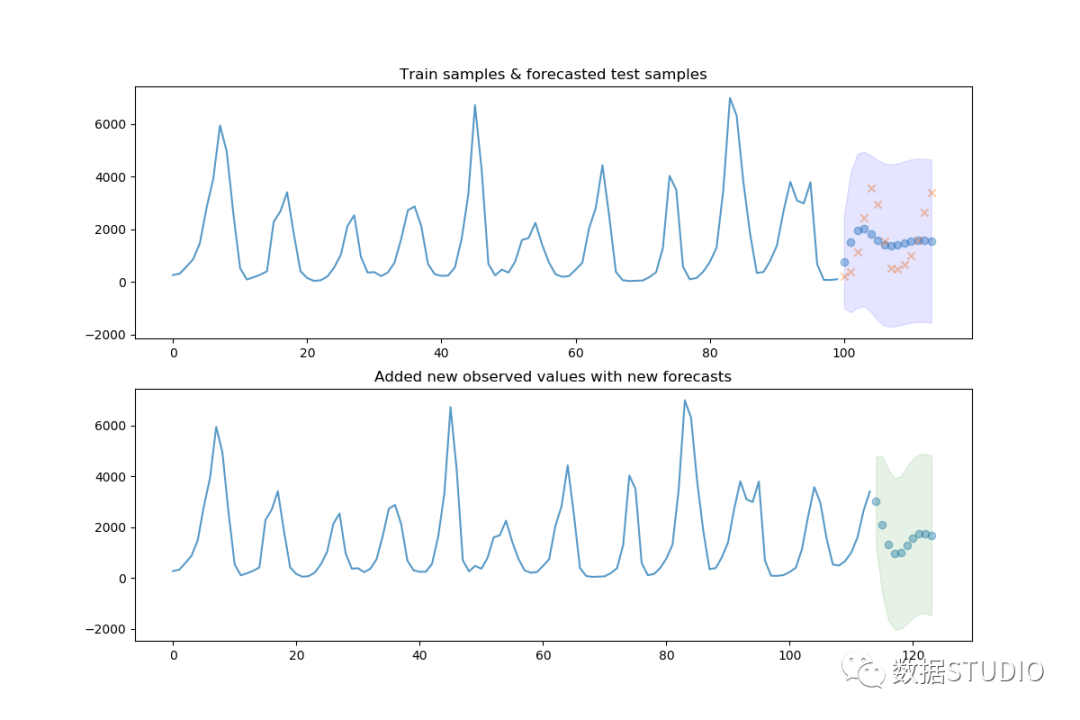
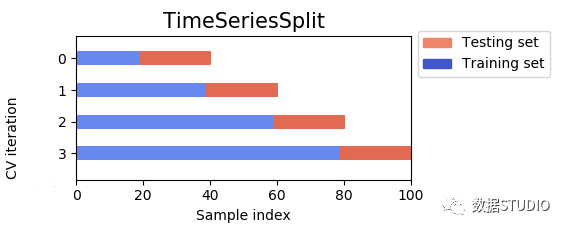
使用 Sklearn 進行時間序列預測

Sklearn 或 Scikit-Learn 無疑是 Python 中最常用的機器學習包之一。它提供了各種分類、回歸和聚類方法,包括隨機森林、支持向量機、k-means 等。除此之外,它還提供了一些與降維、模型選擇、數(shù)據(jù)預處理等相關的實用程序。
除了各種模型之外,對于時間序列,還有一些有用的功能,例如管道、時間序列交叉驗證函數(shù)、用于測量結果的各種指標等。
使用 PyTorch 進行時間序列預測

PyTorch 是一個基于 Python 的深度學習庫,用于快速靈活的實驗。它最初由 Facebook 人工智能研究團隊的研究人員和工程師開發(fā),然后開源。Tesla Autopilot、Uber 的 Pyro 和 Hugging Face 的 Transformers 等深度學習軟件都建立在 PyTorch 之上。
使用 PyTorch,可以構建強大的循環(huán)神經(jīng)網(wǎng)絡模型,例如 LSTM 和 GRU 以及預測時間序列。此外,還有一個具有最先進網(wǎng)絡架構的 PyTorch 預測包(PyTorch Forecasting )。它還包括一個時間序列數(shù)據(jù)集類,用于抽象處理變量轉換、缺失值、隨機子采樣、多個歷史長度和其他類似問題。
PyTorch Forecasting 旨在通過神經(jīng)網(wǎng)絡簡化最先進的時間序列預測,以用于現(xiàn)實世界的案例和研究等。目標是為專業(yè)人士提供具有最大靈活性并為初學者提供合理默認值的高級 API。具體來說,該軟件包提供
一個時間序列數(shù)據(jù)集類,它抽象處理變量轉換、缺失值、隨機子采樣、多個歷史長度等。 一個基本模型類,它提供時間序列模型的基本訓練以及登錄張量板和通用可視化,例如實際與預測和依賴圖 用于時間序列預測的多個神經(jīng)網(wǎng)絡架構,已針對實際部署進行了增強,并具有內(nèi)置的解釋功能 多水平時間序列指標 Ranger 優(yōu)化器用于更快的模型訓練 使用optuna進行超參數(shù)調(diào)整
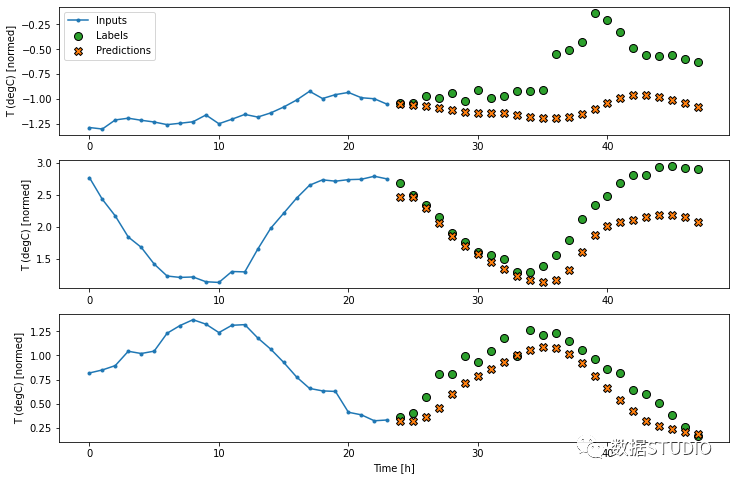
使用 Tensorflow (Keras) 進行時間序列預測

TensorFlow 是一個基于數(shù)據(jù)流圖的機器學習開源軟件庫。它最初由 Google Brain 團隊開發(fā)供內(nèi)部使用,但后來作為開源項目發(fā)布。該軟件庫提供了一組高級數(shù)據(jù)流算子,可以組合起來以自然的方式表達涉及多維數(shù)據(jù)數(shù)組、矩陣和高階張量的復雜計算。它還提供了一些較低級別的原語,例如用于構造自定義運算符或加速執(zhí)行常見操作的內(nèi)核。
Keras 是構建在 TensorFlow 之上的高級 API。使用 Keras 和 TensorFlow,可以構建用于時間序列預測的神經(jīng)網(wǎng)絡模型。下面的教程解釋了使用天氣時間序列數(shù)據(jù)集的時間序列項目的一個示例:
使用 Sktime 進行時間序列預測

Sktime 是一個用于時間序列和機器學習的開源 Python 庫。它包括有效解決時間序列回歸、預測和分類任務所需的算法和轉換工具。創(chuàng)建 Sktime 是為了與 scikit-learn 一起工作,并且可以輕松地為相互關聯(lián)的時間序列任務調(diào)整算法以及構建復合模型。
總體而言,此包提供:
最先進的時間序列預測算法 時間序列的轉換,例如去趨勢或去季節(jié)化等 模型和轉換、模型調(diào)整實用程序和其他有用功能的管道
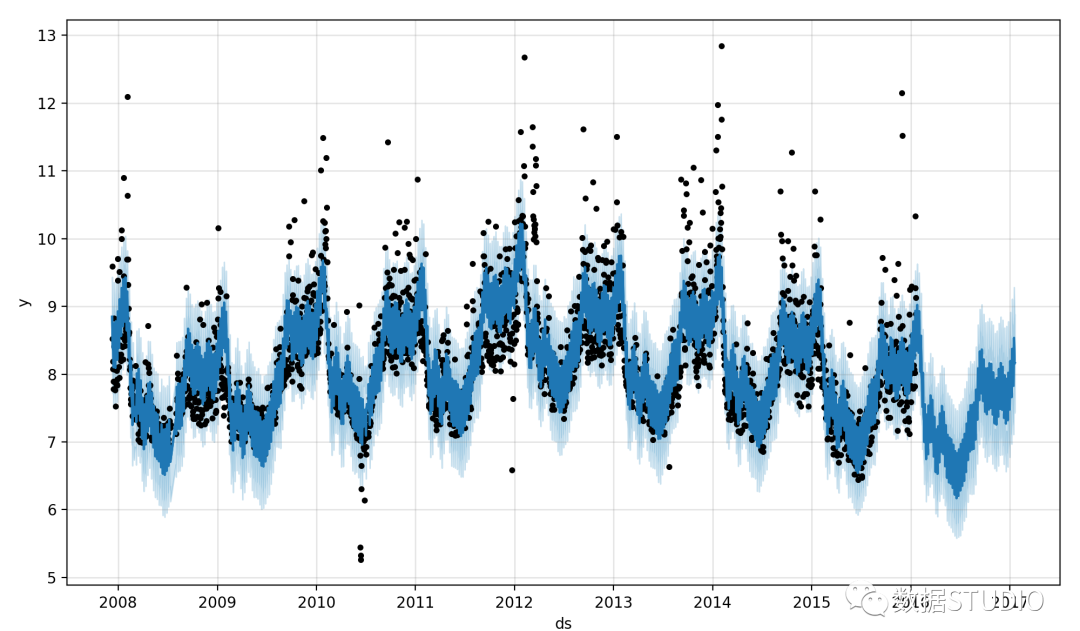
使用 Prophet 進行時間序列預測

Prophet 是 Facebook 核心數(shù)據(jù)科學團隊發(fā)布的開源庫。簡而言之,它包含一個預測時間序列數(shù)據(jù)的程序,該程序基于一個加性模型,該模型將一些非線性趨勢與年度、每周和每日季節(jié)性以及假日效應相結合。它最適用于具有強烈季節(jié)性影響的時間序列和來自多個季節(jié)的歷史數(shù)據(jù)。它通常能夠處理缺失數(shù)據(jù)、趨勢變化和異常值。
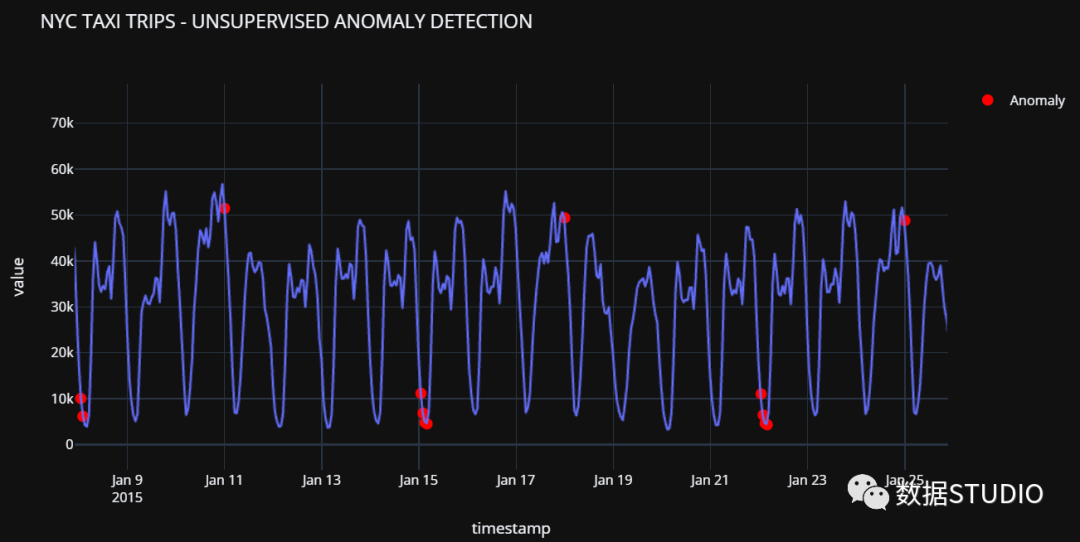
使用 Pycaret 進行時間序列預測

PyCaret 是 Python 中的一個開源機器學習庫,可自動執(zhí)行機器學習工作流。使用 PyCaret,可以用最少的工作和幾行代碼來構建和測試多個機器學習模型。一般用最少的代碼,不需要深入細節(jié),就可以構建一個從 EDA 到部署的端到端機器學習項目。
這個庫有一些有用的時間序列模型,其中包括:
季節(jié)性樸素預測器 ARIMA 多項式趨勢預測器 Lasso Net 具有去季節(jié)化和去趨勢選項以及許多其他選項
使用 AutoTS 進行時間序列預測

近 20 個預定義模型(如 ARIMA、ETS、VECM)可用,并且使用遺傳算法,它可以為給定數(shù)據(jù)集進行預處理、找到最佳模型和模型集成。
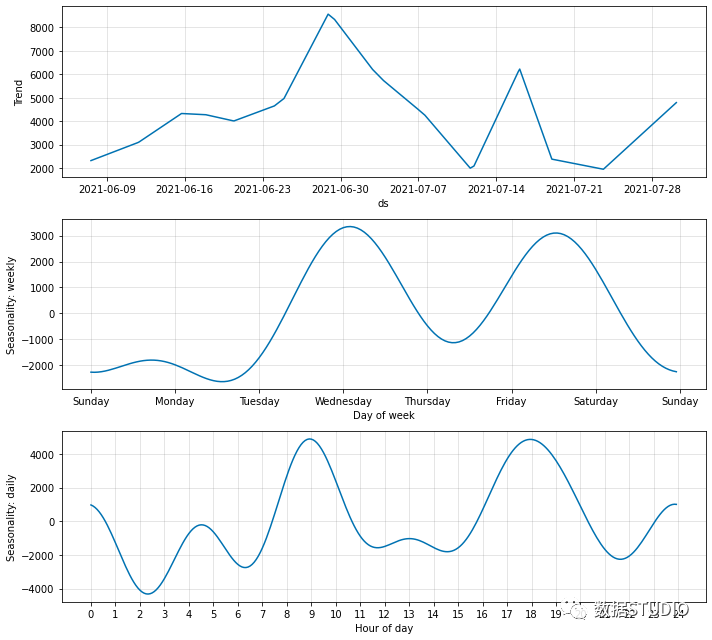
使用 Darts 進行時間序列預測

Darts 是一個 Python 庫,允許對時間序列進行簡單的操作和預測。它包括范圍廣泛的模型,從經(jīng)典的 ES 和 ARIMA 到 RNN 和transformers。所有模型都可以以與 scikit-learn 包中相同的方式使用。
該庫還允許輕松地對模型進行回測、組合來自多個模型的預測以及合并外部數(shù)據(jù)。它支持單變量和多變量模型。可以在此處找到所有可用模型的表以及幾個示例:
# TimeSeries從 Pandas DataFrame創(chuàng)建一個對象,并將其拆分為訓練/驗證系列:
import?pandas?as?pd
import?matplotlib.pyplot?as?plt
from?darts?import?TimeSeries
from?darts.models?import?ExponentialSmoothing
df?=?pd.read_csv('AirPassengers.csv',?delimiter=",")
series?=?TimeSeries.from_dataframe(df,?'Month',?'#Passengers')
train,?val?=?series[:-36],?series[-36:]
#?擬合指數(shù)平滑模型,并對驗證系列的持續(xù)時間進行(概率)預測:
model?=?ExponentialSmoothing()
model.fit(train)
prediction?=?model.predict(len(val),?num_samples=1000)
#?繪制中位數(shù)、第 5 和第 95 個百分位數(shù):
series.plot()
prediction.plot(label='forecast',?low_quantile=0.05,?high_quantile=0.95)
plt.legend()
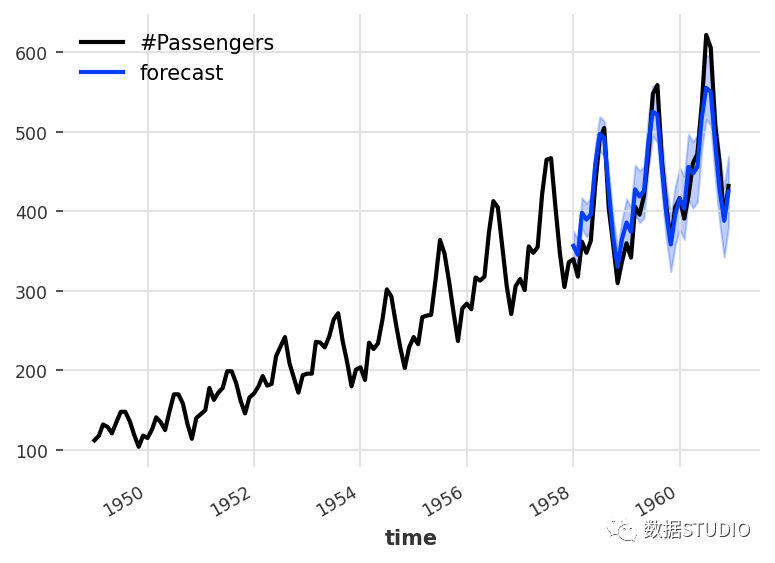
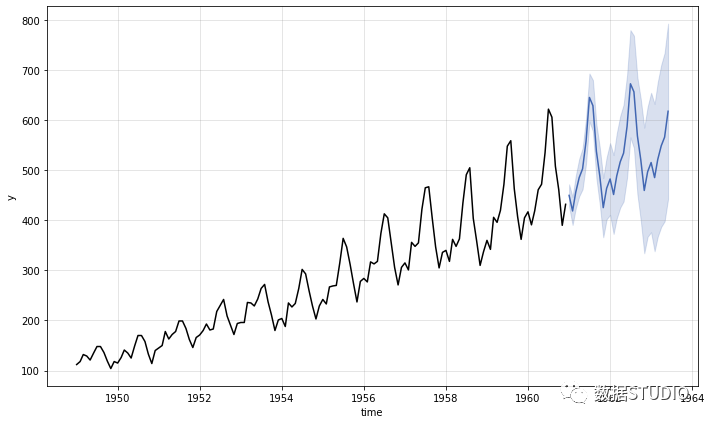
使用 Kats 進行時間序列預測

Kats 是 Facebook 基礎設施數(shù)據(jù)科學團隊發(fā)布的一個包,旨在執(zhí)行時間序列分析。這個包的目標是提供時間序列分析所需的一切,包括檢測、預測、特征提取/嵌入、多變量分析等。
Kats 提供了一套全面的預測工具,例如集成、元學習模型、回測、超參數(shù)調(diào)整和經(jīng)驗預測區(qū)間。此外,它還包括用于檢測時間序列數(shù)據(jù)中的季節(jié)性、異常值、變化點和緩慢趨勢變化的功能。使用 TSFeature 選項,可以生成 65 個具有清晰統(tǒng)計定義的特征,這些特征可用于大多數(shù)機器學習模型。
from?kats.models.sarima?import?SARIMAModel,?SARIMAParams
#?create?SARIMA?param?class
params?=?SARIMAParams(p?=?2,?d=1,?q=1,?
???????trend?=?'ct',?seasonal_order=(1,0,1,12))
#?initiate?SARIMA?model
m?=?SARIMAModel(data=air_passengers_ts,?params=params)
#?fit?SARIMA?model
m.fit()
#?generate?forecast?values
fcst?=?m.predict(steps=30,?freq="MS")
m.plot()
預測庫比較
這里提供了一個包含一些常見功能的表格來比較預測包。表中顯示了一些指標,例如 GitHub 星數(shù)、發(fā)布年份、支持功能等。
| 發(fā)行年份 | GitHub 星星 | 統(tǒng)計與計量經(jīng)濟學 | 機器學習 | 深度學習 | |
|---|---|---|---|---|---|
| Statsmodels | 2010 | 7200 | ? ? | ? | |
| Pmdarima | 2018 | 1100 | ? | ? | |
| Sklearn | 2007 | 50000 | ? | ?? | ? |
| PyTorch | 2016 | 55000 | ? | ?? | |
| TensorFlow | 2015 | 164000 | ? | ?? | |
| Sktime | 2019 | 5000 | ? | ||
| Prophet | 2017 | 14000 | ? | ? | |
| PyCaret | 2020 | 5500 | ? | ? | ? |
| AutoTS | 2020 | 450 | ? | ? | |
| Darts | 2021 | 3800 | ? | ? | ? |
| Kats | 2021 | 3600 | ? | ? |
結論
在這篇文章中,我們描述了時間序列項目最常用的工具、包和庫。使用此工具列表,可以涵蓋幾乎所有與時間序列相關的項目。最重要的是,我們提供了用于預測的庫的比較,其中顯示了一些有趣的統(tǒng)計數(shù)據(jù),例如發(fā)布年份、受歡迎程度以及它支持的模型類型。
上下滑動查看更多
參考資料
Pandas:?https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html
[2]NumPy:?https://numpy.org/
[3]Datetime:?https://docs.python.org/3/library/datetime.html#module-datetime
[4]Tsfresh:?https://tsfresh.readthedocs.io/en/latest/index.html
[5]Matplotlib:?https://matplotlib.org/
[6]Plotly:?https://plotly.com/python/time-series/
[7]Statsmodels:?https://www.statsmodels.org/dev/generated/statsmodels.tsa.seasonal.seasonal_decompose.html
[8]Statsmodels:?https://www.statsmodels.org/stable/tsa.html
[9]pmdarima:?https://alkaline-ml.com/pmdarima/
[10]Sklearn:?https://scikit-learn.org/stable/index.html
[11]PyTorch:?https://github.com/jdb78/pytorch-forecasting
[12]TensorFlow:?https://www.tensorflow.org/tutorials/structured_data/time_series
[13]Sktime:?https://www.sktime.org/en/stable/
[14]Prophet:?https://github.com/facebook/prophet
[15]PyCaret:?https://pycaret.readthedocs.io/en/time_series/api/time_series.html
[16]autots_1280:?https://github.com/winedarksea/AutoTS
[17]Darts:?https://unit8co.github.io/darts/
[18]smaimr1:?https://facebookresearch.github.io/Kats/
[19]smaimr2:?https://github.com/facebookresearch/Kats

往期精彩回顧
適合初學者入門人工智能的路線及資料下載 (圖文+視頻)機器學習入門系列下載 中國大學慕課《機器學習》(黃海廣主講) 機器學習及深度學習筆記等資料打印 《統(tǒng)計學習方法》的代碼復現(xiàn)專輯 機器學習交流qq群955171419,加入微信群請掃碼: