
ICML 2021杰出論文獎(jiǎng)“臨時(shí)更換”,上海交大校友田淵棟陸昱成等獲提名
點(diǎn)擊上方“視學(xué)算法”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
蕭簫 發(fā)自 凹非寺
量子位 報(bào)道 | 公眾號(hào) QbitAI
今天,ICML 2021論文獎(jiǎng)項(xiàng)公布!
今年參與評(píng)選的共有1184篇論文,數(shù)量為往年最高,共有1篇論文獲杰出論文獎(jiǎng),4篇論文獲提名。

值得一提的是,今年的杰出論文獎(jiǎng)可以說(shuō)是“橫空殺出”,于當(dāng)天空降現(xiàn)場(chǎng),作者來(lái)自多倫多大學(xué)、Google Brain。

此前,在ICML 2021官網(wǎng)上po出的杰出論文獎(jiǎng),還是上交大校友、康奈爾博士生陸昱成(Yucheng Lu)一作的論文:

于當(dāng)天改成了榮譽(yù)提名:

除此之外,同樣來(lái)自上交大的校友、Facebook科學(xué)家田淵棟一作的論文,也獲得了杰出論文獎(jiǎng)榮譽(yù)提名。

值得一提的是,這篇論文原本只是獲得Weak Accept,但經(jīng)過(guò)田淵棟與評(píng)審之間經(jīng)過(guò)“一番辯論”(rebuttal)后,評(píng)審最終將這篇論文改成了Accept。

今年ICML 2021的時(shí)間檢驗(yàn)獎(jiǎng),則頒給了「Bayesian Learning via Stochastic Gradient Langevin Dynamics」,作者分別來(lái)自高通和牛津大學(xué),其中一位還是Hinton的學(xué)生。
一起來(lái)看看。
杰出論文獎(jiǎng)
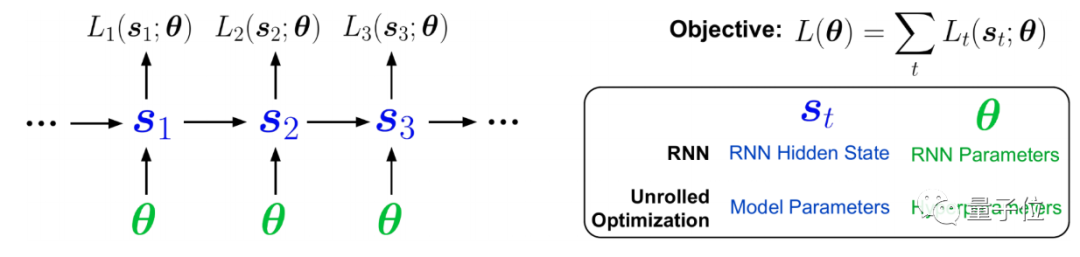
今年的杰出論文獎(jiǎng),題目是Unbiased Gradient Estimation in Unrolled Computation Graphs with Persistent Evolution Strategies,來(lái)自多倫多大學(xué)和Google Brain。
(作者分別為Paul Vicol, Luke Metz, Jascha Sohl-Dickstein)

△一作Paul Vicol
這篇論文指出,在一些計(jì)算圖中優(yōu)化參數(shù)的方法存在高方差梯度、偏差、更新緩慢或內(nèi)存使用量大的問(wèn)題。
作者引入了一種稱為Persistent Evolution Strategies (PES) 的方法,將計(jì)算圖劃分為一系列截?cái)嗟恼归_(kāi),并在每次展開(kāi)后執(zhí)行基于進(jìn)化策略的更新步驟。PES可以讓參數(shù)更新速度更快、內(nèi)存使用率更低、無(wú)偏差并具有合理的方差特征。
杰出論文獎(jiǎng)榮譽(yù)提名
1、Optimal Complexity in Decentralized Training
來(lái)自康奈爾大學(xué)。
(作者陸昱成、Christopher De Sa)
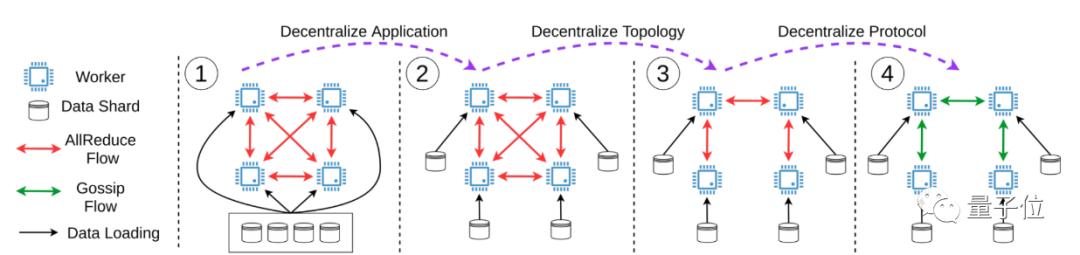
這篇論文給出了去中心化在隨機(jī)非凸環(huán)境下迭代復(fù)雜度的下界。結(jié)果表明,許多現(xiàn)有的分散訓(xùn)練算法如D-PSGD,在已知收斂速度上存在理論差距,但這個(gè)下界是可實(shí)現(xiàn)的。此外,論文還提出了一種名為DeTAG的算法,這是一種實(shí)用的去中心化算法,并在圖像分類(lèi)任務(wù)上與其他去中心化算法進(jìn)行了比較。發(fā)現(xiàn)與Baseline相比,DeTAG在非緩沖數(shù)據(jù)和稀疏網(wǎng)絡(luò)中具有更快的收斂速度。
2、Understanding self-supervised learning dynamics without contrastive pairs
來(lái)自Facebook AI Research、斯坦福大學(xué)。
(作者田淵棟、Xinlei Chen、Surya Ganguli)
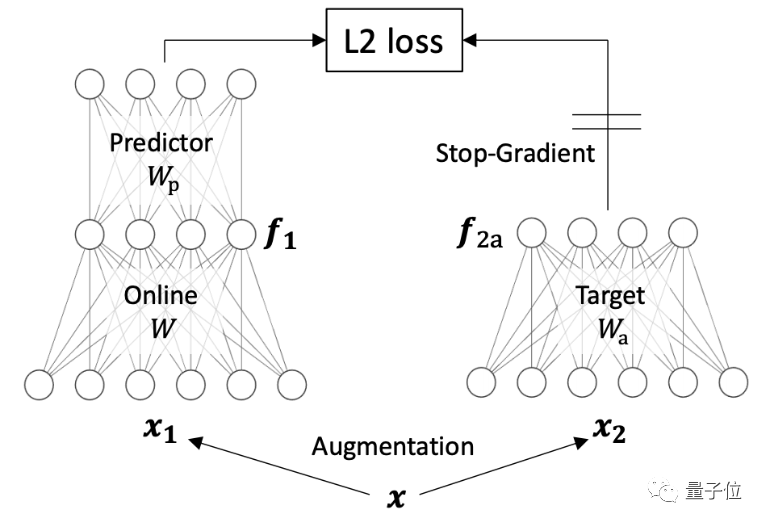
這篇論文提出了一種新的方法Direct Pred,無(wú)需梯度訓(xùn)練,可以直接根據(jù)輸入的統(tǒng)計(jì)信息來(lái)設(shè)置線性預(yù)測(cè)。在ImageNet上,它與更復(fù)雜的BatchNorm預(yù)測(cè)器性能相似。這項(xiàng)研究提供了非對(duì)比SSL方法如何學(xué)習(xí)的概念性簡(jiǎn)介,以及預(yù)測(cè)網(wǎng)絡(luò)、停止梯度、指數(shù)移動(dòng)平均數(shù)和權(quán)重衰減等因素如何發(fā)揮作用。
3、Oops I Took A Gradient: Scalable Sampling for Discrete Distributions
來(lái)自多倫多大學(xué)、Google Brain。
(作者Will Grathwohl, Kevin Swersky, Milad Hashemi, David Duvenaud, Chris Maddison)
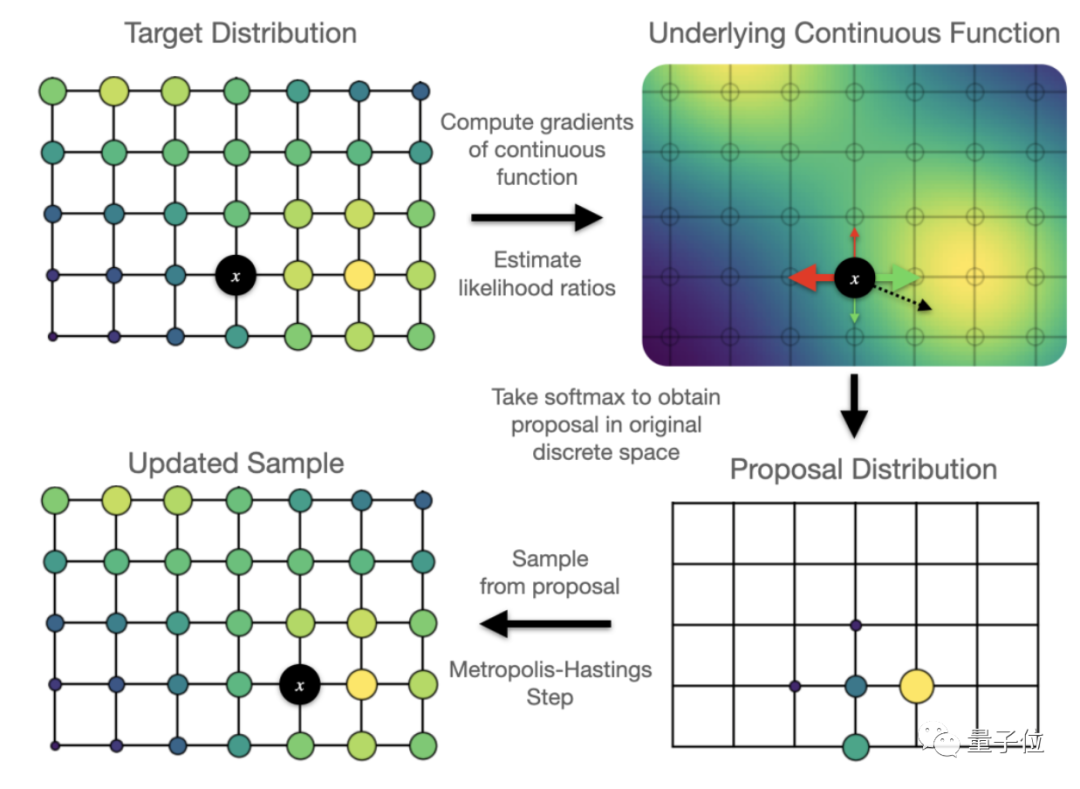
這篇論文提出了一個(gè)可擴(kuò)展的通用近似抽樣策略,利用似然函數(shù),對(duì)離散輸入梯度進(jìn)行Metropolis-Hastings采樣更新。結(jié)果表明,這種策略較其他抽樣方法如隱馬爾科夫模型等在較復(fù)雜環(huán)境下更優(yōu)。此外,這篇論文還對(duì)采樣器進(jìn)行了優(yōu)化,用于訓(xùn)練基于高維離散圖像數(shù)據(jù)的、基于能量的深度模型,較變分自動(dòng)編碼器和基于能量的模型更優(yōu)。
4、Solving high-dimensional parabolic PDEs using the tensor train format
來(lái)自德國(guó)柏林自由大學(xué)、波茨坦大學(xué)。
(作者Lorenz Richter 、Leon Sallandt、Nikolas Nüsken)
這篇論文認(rèn)為,張量訓(xùn)練給拋物偏微分方程提供了一個(gè)更合理的近似框架,將隨機(jī)微分方程和張量格式回歸型方法結(jié)合,以利用潛在的低秩結(jié)構(gòu)實(shí)現(xiàn)壓縮和高校計(jì)算。論文提出了一種新的迭代方案,與最先進(jìn)的神經(jīng)網(wǎng)絡(luò)相比,這種方法在精確度和計(jì)算效率間取得了良好的折中。
時(shí)間檢驗(yàn)獎(jiǎng)
今年的時(shí)間檢驗(yàn)獎(jiǎng)名為Bayesian Learning via Stochastic Gradient Langevin Dynamics。

作者分別是高通荷蘭公司技術(shù)副總裁Max Welling、牛津大學(xué)教授Yee Whye Teh(鄭宇懷),后者曾經(jīng)是Hinton的學(xué)生。
論文主要介紹了一種基于大規(guī)模數(shù)據(jù)集的貝葉斯學(xué)習(xí)方法,并將之應(yīng)用于高斯混合模型、邏輯回歸模型和自然梯度的ICA模型。
這篇論文在Google學(xué)術(shù)上的引用量已經(jīng)達(dá)到了1408次,是2011年的ICML入選論文。
ICML 2021獎(jiǎng)項(xiàng):
最佳論文獎(jiǎng):http://proceedings.mlr.press/v139/vicol21a/vicol21a.pdf
4篇榮譽(yù)提名:https://icml.cc/virtual/2021/awards_detail
時(shí)間檢驗(yàn)獎(jiǎng):https://www.cse.iitk.ac.in/users/piyush/courses/tpmi_winter21/readings/sgld.pdf
參考鏈接:
[1]https://twitter.com/icmlconf/status/1417110371161317378
[2]https://www.cs.cornell.edu/~yucheng/
— 完 —
本文系網(wǎng)易新聞?網(wǎng)易號(hào)特色內(nèi)容激勵(lì)計(jì)劃簽約賬號(hào)【量子位】原創(chuàng)內(nèi)容,未經(jīng)賬號(hào)授權(quán),禁止隨意轉(zhuǎn)載。

點(diǎn)個(gè)在看 paper不斷!