
效果提升4倍!這樣做模型預(yù)測才是真香啊!
↓推薦關(guān)注↓
大家好,前兩天有粉絲問有關(guān)算法預(yù)測的問題。今天我們就以股價預(yù)測為例,分享一下兩種預(yù)測方法:
常規(guī)方式股票預(yù)測 全新方式股票預(yù)測
經(jīng)過驗證,全新方式預(yù)測效果是常規(guī)方式的4倍,喜歡本文記得點(diǎn)贊、收藏、關(guān)注。
1. 常規(guī)方式股票預(yù)測
1.1 數(shù)據(jù)集介紹
本文使用的股價數(shù)據(jù)集來自GitHib:https://github.com/pierpaolo28/Data-Visualization/blob/master/Dash/stock_data.csv。
下載數(shù)據(jù)集后,查看其內(nèi)容,可以看到數(shù)據(jù)集中包含時間、開盤時股價等一系列相關(guān)信息,本文需要預(yù)測的是股價當(dāng)天的最終價格,即 Close 列的數(shù)據(jù):
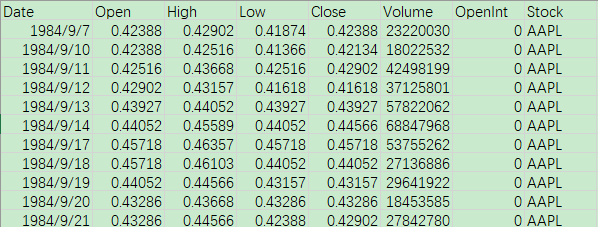
1.2 模型分析
為了預(yù)測股價,我們根據(jù)以下思路構(gòu)建神經(jīng)網(wǎng)絡(luò)模型:
按照時間發(fā)生順序?qū)?shù)據(jù)集進(jìn)行排序 以前五個股票價格數(shù)據(jù)作為輸入,第六個股票價格數(shù)據(jù)作為輸出 滑動時間窗口,在模型的下一個輸入使用第二個到第六個數(shù)據(jù),并將第七個數(shù)據(jù)作為輸出,依此類推,直到到達(dá)最后一個數(shù)據(jù)點(diǎn) 由于我們需要預(yù)測的是一個連續(xù)值,因此損失函數(shù)使用均方誤差值 此外,我們還將在下個環(huán)節(jié)嘗試?yán)梦谋緮?shù)據(jù)集成到歷史股票價格數(shù)據(jù)中,以預(yù)測第二天股價的情況
1.3 使用神經(jīng)網(wǎng)絡(luò)進(jìn)行股價預(yù)測
根據(jù)以上模型的思路,接下來,我們使用 Keras 實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)模型用于預(yù)測股價。
1.導(dǎo)入相關(guān)的包和數(shù)據(jù)集:
import?pandas?as?pd
data2?=?pd.read_csv('content/stock_data.csv')
2.按照前述分析準(zhǔn)備數(shù)據(jù)集,其中輸入是前五天的股票價格,輸出是第六天的股票價格:
x?=?[]
y?=?[]
for?i?in?range(data2.shape[0]-5):
????x.append(data2.loc[i:(i+4)]['Close'].values)
????y.append(data2.loc[i+5]['Close'])
import?numpy?as?np
x?=?np.array(x)
y?=?np.array(y)
3.準(zhǔn)備訓(xùn)練和測試數(shù)據(jù)集,構(gòu)建模型:
from?sklearn.model_selection?import?train_test_split
x_train,?x_test,?y_train,?y_test?=?train_test_split(x,?y,?test_size=0.3)
from?keras.layers?import?Dense
from?keras.models?import?Sequential
model?=?Sequential()
model.add(Dense(100,?input_dim=5,?activation='relu'))
model.add(Dense(1,?activation='linear'))
4.建立模型并進(jìn)行編譯:
model.compile(optimizer='adam',?loss='mean_squared_error')
model.summary()
看以看到,模型的簡要信息輸出如下:
Model:?"sequential"
_________________________________________________________________
Layer?(type)?????????????????Output?Shape??????????????Param?
=================================================================
dense?(Dense)????????????????(None,?100)???????????????600???????
_________________________________________________________________
dense_1?(Dense)??????????????(None,?1)?????????????????101???????
=================================================================
Total?params:?701
Trainable?params:?701
Non-trainable?params:?0
_________________________________________________________________
可以看到,訓(xùn)練集股價的均方誤差值約為 320,而預(yù)測集股價的均方誤差值約為 330,以這種方式預(yù)測股價存在較大的問題。
在下一部分中,我們將學(xué)習(xí)如何在模型中將股價價格數(shù)據(jù)與新聞標(biāo)題的文本數(shù)據(jù)集成在一起的方式進(jìn)行預(yù)測。
2.全新方式股價預(yù)測
2.1 模型分析
在本節(jié)中,我們將股票歷史價格數(shù)據(jù)與我們要預(yù)測股價的公司最近的相關(guān)新聞標(biāo)題相集成,以提高股價預(yù)測的準(zhǔn)確性。
我們將整合來自多個來源的數(shù)據(jù)——結(jié)構(gòu)化(歷史股價)數(shù)據(jù)和非結(jié)構(gòu)化(新聞標(biāo)題)數(shù)據(jù)——進(jìn)行股價預(yù)測。
模型構(gòu)建策略如下:
將非結(jié)構(gòu)化文本轉(zhuǎn)換為結(jié)構(gòu)化格式的方式類似于在新聞分類中所使用方式 通過神經(jīng)網(wǎng)絡(luò)傳遞文本信息,并提取隱藏層輸出 最后,將隱藏層的輸出傳遞到輸出層,其中輸出層具有一個節(jié)點(diǎn) 以類似的方式,將輸入的歷史價格數(shù)據(jù)通過神經(jīng)網(wǎng)絡(luò)傳遞,以提取隱藏層輸出,然后將其傳遞到輸出層,輸出層具有一個節(jié)點(diǎn) 將兩個神經(jīng)網(wǎng)絡(luò)的輸出相乘以得到最終輸出 最小化最終輸出的平方誤差值
2.2 結(jié)合新聞數(shù)據(jù)預(yù)測股價
根據(jù)以上策略,模型實(shí)現(xiàn)程序如下。
1.從Guardian(https://content.guardianapis.com)提供的 API 中獲取標(biāo)題數(shù)據(jù),如下所示:
from?bs4?import?BeautifulSoup
import?urllib,?json
dates?=?[]
titles?=?[]
for?i?in?range(100):
????try:
????????url?=?'https://content.guardianapis.com/search?from-date=2010-01-01§ion=business&page-size=200&order-by=newest&page='+str(i+1)+'&q=amazon&api-key=207b6047-a2a6-4dd2-813b-5cd006b780d7'
????????response?=?urllib.request.urlopen(url)
????????encoding?=?response.info().get_content_charset('utf8')
????????data?=?json.loads(response.read().decode(encoding))
????????for?j?in?range(len(data['response']['results'])):
????????????dates.append(data['response']['results'][j]['webPublicationDate'])
????????????titles.append(data['response']['results'][j]['webTitle'])
????except:
????????break
2.提取標(biāo)題和日期后,對數(shù)據(jù)進(jìn)行預(yù)處理,以將日期值轉(zhuǎn)換為日期格式,如下所示:
import?pandas?as?pd
data?=?pd.DataFrame(dates,?titles)
data?=?data.reset_index()
data.columns?=?['title','date']
data['date']=data['date'].str[:10]
data['date']=pd.to_datetime(data['date'],?format?=?'%Y-%m-%d')
data?=?data.sort_values(by='date')
data_final?=?data.groupby('date').first().reset_index()
3.對于要預(yù)測股價的每個日期,我們獲得相應(yīng)日期的公司的相關(guān)新聞標(biāo)題,接下來整合兩個數(shù)據(jù)源,如下所示:
data2['Date']?=?pd.to_datetime(data2['Date'],format='%Y-%m-%d')
data3?=?pd.merge(data2,data_final,?left_on?=?'Date',?right_on?=?'date',?how='left')
4.合并數(shù)據(jù)集后,我們將繼續(xù)對文本數(shù)據(jù)進(jìn)行規(guī)范化,首先對數(shù)據(jù)進(jìn)行如下處理:
將文本中的所有單詞都轉(zhuǎn)換為小寫字母,以便可以將 Text和text單詞被視為相同值刪除標(biāo)點(diǎn)符號,使諸如 text.和text被視為相同文本刪除停用詞,例如 a和and,它們不會為文本增加過多上下文
import?nltk
import?re
stop?=?nltk.corpus.stopwords.words('english')
def?preprocess(text):
?????text?=?str(text)
?????text=text.lower()
?????text=re.sub('[^0-9a-zA-Z]+','?',text)
?????words?=?text.split()
?????words2=[w?for?w?in?words?if?(w?not?in?stop)]
?????words4='?'.join(words2)
?????return(words4)
data3['title']?=?data3['title'].apply(preprocess)
5.用連字符 “-” 替換標(biāo)題中的空值:
data3['title']=np.where(data3['title'].isnull(),'-','-'+data3['title'])
6.現(xiàn)在我們已經(jīng)預(yù)處理了文本數(shù)據(jù),為每個單詞分配一個 ID。完成此任務(wù)后,我們可以按照與新聞分類中類似的方法執(zhí)行文本分析,如下所示:
docs?=?data3['title'].values
from?collections?import?Counter
counts?=?Counter()
for?i,review?in?enumerate(docs):
????counts.update(review.split())
words?=?sorted(counts,?key=counts.get,?reverse=True)
vocab_size=len(words)
word_to_int?=?{word:?i?for?i,?word?in?enumerate(words,?1)}
7.既然我們已經(jīng)對所有單詞進(jìn)行了編碼,那么我們在原始文本中將其替換為相應(yīng)的索引值:
encoded_docs?=?[]
for?doc?in?docs:
????encoded_docs.append([word_to_int[word]?for?word?in?doc.split()])
def?vectorize_sequences(sequences,?dimension=vocab_size):
????results?=?np.zeros((len(sequences),?dimension+1))
????for?i,?sequence?in?enumerate(sequences):
????????results[i,?sequence]?=?1.
????return?results
vectorized_docs?=?vectorize_sequences(encoded_docs)
現(xiàn)在我們已經(jīng)對文本進(jìn)行了編碼,接下來,我們將兩個數(shù)據(jù)源集成在一起,以進(jìn)行更好的預(yù)測。
8.首先,準(zhǔn)備訓(xùn)練和測試數(shù)據(jù)集,如下所示:
x1?=?np.array(x)
x2?=?np.array(vectorized_docs[5:])
y?=?np.array(y)
x1_train?=?x1[:2100,:]
x2_train?=?x2[:2100,?:]
y_train?=?y[:2100]
x1_test?=?x1[2100:,:]
x2_test?=?x2[2100:,:]
y_test?=?y[2100:]
通常,當(dāng)模型有多個輸入或多個輸出時,我們將使用函數(shù)式 API 構(gòu)建模型,本例中模型有多個輸入,因此將使用函數(shù)式 API。
9.本質(zhì)上,函數(shù)式 API 打破了順序構(gòu)建模型的過程,可以按照數(shù)據(jù)流的計算順序構(gòu)建模型:
from?keras.layers?import?Dense,?Input
from?keras?import?Model
import?keras.backend?as?K
input1?=?Input(shape=(vectorized_docs.shape[1],))
model?=?(Dense(100,?activation='relu'))(input1)
model?=?(Dense(1,?activation='tanh'))(model)
在前面的代碼中,沒有使用順序建模過程,而是使用 Dense 層定義了層與層之間的連接。輸入的形狀為 2406,因為在上述過濾過程之后剩下 2406 個不同的詞。
10.利用時間窗口策略,取5個股票價格作為輸入并構(gòu)建另一模型:
input2?=?Input(shape=(5,))
model2?=?(Dense(100,?activation='relu'))(input2)
model2?=?(Dense(1,?activation='linear'))(model2)
11.將上述兩個模型的輸出相乘,得到最終結(jié)果:
from?keras.layers?import?multiply
out?=?multiply([model,?model2])
12.我們已經(jīng)定義了輸入、輸出,接下來,就可以按照以下方式構(gòu)建模型:
model?=?Model([input1,?input2],?out)
model.summary()
以上代碼中,我們使用 “Model” 層定義了輸入(作為列表傳遞)和輸出,模型的概要信息輸出如下:
__________________________________________________________________________________________________
Layer?(type)????????????????????Output?Shape?????????Param?
==================================================================================================
input_1?(InputLayer)????????????(None,?2406)?????????0????????????????????????????????????????????
__________________________________________________________________________________________________
input_2?(InputLayer)????????????(None,?5)????????????0????????????????????????????????????????????
__________________________________________________________________________________________________
dense_1?(Dense)?????????????????(None,?100)??????????240700??????input_1[0][0]????????????????????
__________________________________________________________________________________________________
dense_3?(Dense)?????????????????(None,?100)??????????600?????????input_2[0][0]????????????????????
__________________________________________________________________________________________________
dense_2?(Dense)?????????????????(None,?1)????????????101?????????dense_1[0][0]????????????????????
__________________________________________________________________________________________________
dense_4?(Dense)?????????????????(None,?1)????????????101?????????dense_3[0][0]????????????????????
__________________________________________________________________________________________________
multiply_1?(Multiply)???????????(None,?1)????????????0???????????dense_2[0][0]????????????????????
?????????????????????????????????????????????????????????????????dense_4[0][0]????????????????????
==================================================================================================
Total?params:?241,502
Trainable?params:?241,502
Non-trainable?params:?0
__________________________________________________________________________________________________
接下來,將模型架構(gòu)進(jìn)行可視化,如下:
plot_model(model,?show_shapes=True,?show_layer_names=True,?to_file='model.png')
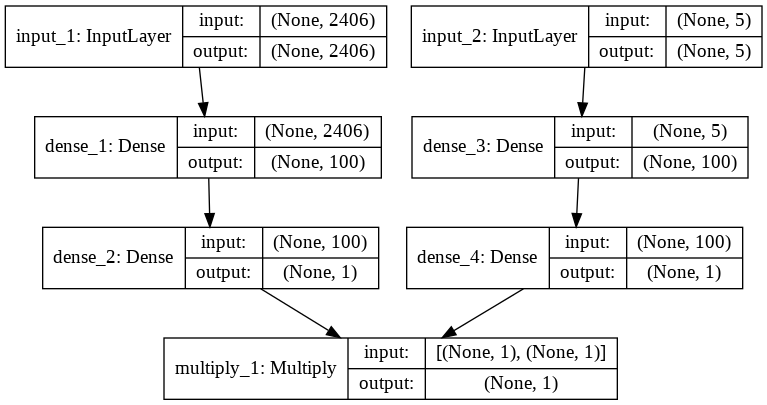
編譯并擬合模型:
model.compile(optimizer='adam',?loss='mean_squared_error')
model.fit(x=[x2_train,?x1_train],?y=y_train,
????????epochs=100,
????????batch_size=32,
????????validation_data=([x2_test,?x1_test],?y_test),
????????verbose=1)
前面的模型在訓(xùn)練集上產(chǎn)生的均方誤差僅約為70,并且可以看出模型過擬合,因為訓(xùn)練數(shù)據(jù)集的損失遠(yuǎn)低于測試數(shù)據(jù)集的損失。
小結(jié)
本節(jié)通過股價預(yù)測為例,學(xué)習(xí)了函數(shù)式API方式來構(gòu)建復(fù)雜神經(jīng)網(wǎng)絡(luò),準(zhǔn)確率提升將近4倍。
長按或掃描下方二維碼,后臺回復(fù):加群,即可申請入群。一定要備注:來源+研究方向+學(xué)校/公司,否則不拉入群中,見諒!
(長按三秒,進(jìn)入后臺)
推薦閱讀
