
一個專注于目標(biāo)檢測與深度學(xué)習(xí)知識分享的公眾號
人體姿態(tài)估計是當(dāng)前計算機(jī)視覺領(lǐng)域的熱點研究問題。對人體骨架關(guān)節(jié)點進(jìn)行準(zhǔn)確提取并構(gòu)建人體骨架模型,為進(jìn)一步的人體姿態(tài)識別、實時交互游戲等研究與應(yīng)用提供了基礎(chǔ)。
轉(zhuǎn)載自 | 計算機(jī)視覺life
因為在ICIP2019上面和兩位老師搞了一個關(guān)于人體姿態(tài)估計以及動作行為的tutorial,所以最近整理了蠻多人體姿態(tài)估計方面的文章,做了一個總結(jié)和梳理,希望能拋磚引玉。人體姿態(tài)估計是計算機(jī)視覺中一個很基礎(chǔ)的問題。從名字的角度來看,可以理解為對“人體”的姿態(tài)(關(guān)鍵點,比如頭,左手,右腳等)的位置估計。一般我們可以這個問題再具體細(xì)分成4個任務(wù):
- 單人姿態(tài)估計 (Single-Person Skeleton Estimation)
- 多人姿態(tài)估計 (Multi-person Pose Estimation)
- 人體姿態(tài)跟蹤 (Video Pose Tracking)
- 3D人體姿態(tài)估計 (3D Skeleton Estimation)
具體講一下每個任務(wù)的基礎(chǔ)。首先是 單人姿態(tài)估計, 輸入是一個crop出來的行人,然后在行人區(qū)域位置內(nèi)找出需要的關(guān)鍵點,比如頭部,左手,右膝等。常見的數(shù)據(jù)集有MPII, LSP, FLIC, LIP。其中MPII是2014年引進(jìn)的,目前可以認(rèn)為是單人姿態(tài)估計中最常用的benchmark, 使用的是PCKh的指標(biāo)(可以認(rèn)為預(yù)測的關(guān)鍵點與GT標(biāo)注的關(guān)鍵點經(jīng)過head size normalize后的距離)。但是經(jīng)過這幾年的算法提升,整體結(jié)果目前已經(jīng)非常高了(最高的已經(jīng)有93.9%了)。下面是單人姿態(tài)估計的結(jié)果圖(圖片來源于CPM的paper): 單人姿態(tài)估計算法往往會被用來做多人姿態(tài)估計。多人姿態(tài)估計的輸入是一張整圖,可能包含多個行人,目的是需要把圖片中所有行人的關(guān)鍵點都能正確的做出估計。針對這個問題,一般有兩種做法,分別是top-down以及bottom-up的方法。對于top-down的方法,往往先找到圖片中所有行人,然后對每個行人做姿態(tài)估計,尋找每個人的關(guān)鍵點。單人姿態(tài)估計往往可以被直接用于這個場景。對于bottom-up,思路正好相反,先是找圖片中所有parts (關(guān)鍵點),比如所有頭部,左手,膝蓋等。然后把這些parts(關(guān)鍵點)組裝成一個個行人。
單人姿態(tài)估計算法往往會被用來做多人姿態(tài)估計。多人姿態(tài)估計的輸入是一張整圖,可能包含多個行人,目的是需要把圖片中所有行人的關(guān)鍵點都能正確的做出估計。針對這個問題,一般有兩種做法,分別是top-down以及bottom-up的方法。對于top-down的方法,往往先找到圖片中所有行人,然后對每個行人做姿態(tài)估計,尋找每個人的關(guān)鍵點。單人姿態(tài)估計往往可以被直接用于這個場景。對于bottom-up,思路正好相反,先是找圖片中所有parts (關(guān)鍵點),比如所有頭部,左手,膝蓋等。然后把這些parts(關(guān)鍵點)組裝成一個個行人。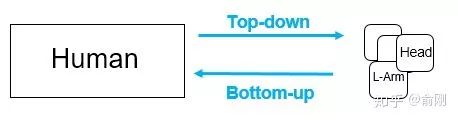 對于測試集來講,主要有COCO, 最近有新出一個數(shù)據(jù)集CrowdPose。下面是CPN算法在COCO上面的結(jié)果:
對于測試集來講,主要有COCO, 最近有新出一個數(shù)據(jù)集CrowdPose。下面是CPN算法在COCO上面的結(jié)果: 如果把姿態(tài)估計往視頻中擴(kuò)展的話,就有了人體姿態(tài)跟蹤的任務(wù)。主要是針對視頻場景中的每一個行人,進(jìn)行人體以及每個關(guān)鍵點的跟蹤。這個問題本身其實難度是很大的。相比行人跟蹤來講,人體關(guān)鍵點在視頻中的temporal motion可能比較大,比如一個行走的行人,手跟腳會不停的擺動,所以跟蹤難度會比跟蹤人體框大。目前主要有的數(shù)據(jù)集是PoseTrack。同時,如果把人體姿態(tài)往3D方面進(jìn)行擴(kuò)展,輸入RGB圖像,輸出3D的人體關(guān)鍵點的話,就是3D 人體姿態(tài)估計。這個有一個經(jīng)典的數(shù)據(jù)集Human3.6M。最近,除了輸出3D的關(guān)鍵點外,有一些工作開始研究3D的shape,比如數(shù)據(jù)集DensePose。長線來講,這個是非常有價值的研究方向。3D人體姿態(tài)估計的結(jié)果圖(來自算法a simple baseline)如下:
如果把姿態(tài)估計往視頻中擴(kuò)展的話,就有了人體姿態(tài)跟蹤的任務(wù)。主要是針對視頻場景中的每一個行人,進(jìn)行人體以及每個關(guān)鍵點的跟蹤。這個問題本身其實難度是很大的。相比行人跟蹤來講,人體關(guān)鍵點在視頻中的temporal motion可能比較大,比如一個行走的行人,手跟腳會不停的擺動,所以跟蹤難度會比跟蹤人體框大。目前主要有的數(shù)據(jù)集是PoseTrack。同時,如果把人體姿態(tài)往3D方面進(jìn)行擴(kuò)展,輸入RGB圖像,輸出3D的人體關(guān)鍵點的話,就是3D 人體姿態(tài)估計。這個有一個經(jīng)典的數(shù)據(jù)集Human3.6M。最近,除了輸出3D的關(guān)鍵點外,有一些工作開始研究3D的shape,比如數(shù)據(jù)集DensePose。長線來講,這個是非常有價值的研究方向。3D人體姿態(tài)估計的結(jié)果圖(來自算法a simple baseline)如下:
 部分主要用于描述在深度學(xué)習(xí)之前,我們是如何處理人體姿態(tài)估計這個問題。從算法角度來講,這部分的工作主要是希望解決單人的人體姿態(tài)估計問題,也有部分工作已經(jīng)開始嘗試做3D的人體姿態(tài)估計。可以粗略的方法分成兩類。第一類是直接通過一個全局feature,把姿態(tài)估計問題當(dāng)成分類或者回歸問題直接求解 [1][2]。但是這類方法的問題在于精度一般,并且可能比較適用于背景干凈的場景。第二類是基于一個graphical model,比如常用pictorial structure model。一般包含unary term,是指對單個part進(jìn)行feature的representation,單個part的位置往往可以使用DPM (Deformable Part-based model)來獲得。同時需要考慮pair-wise關(guān)系來優(yōu)化關(guān)鍵點之間的關(guān)聯(lián)。基于Pictorial Structure,后續(xù)有非常多的改進(jìn),要么在于如何提取更好的feature representation [3][4], 要么在于建模更好的空間位置關(guān)系[5][6]。總結(jié)一下,在傳統(tǒng)方法里面,需要關(guān)注的兩個維度是: feature representation以及關(guān)鍵點的空間位置關(guān)系。特征維度來講,傳統(tǒng)方法一般使用的HOG, Shape Context, SIFT等shallow feature。 空間位置關(guān)系的表示也有很多形式,上面的Pictorial structure model可能只是一種。這兩個維度在深度學(xué)習(xí)時代也是非常至關(guān)重要的,只是深度學(xué)習(xí)往往會把特征提取,分類,以及空間位置的建模都在一個網(wǎng)絡(luò)中直接建模,所以不需要獨(dú)立的進(jìn)行拆解,這樣更方便設(shè)計和優(yōu)化。從2012年AlexNet開始,深度學(xué)習(xí)開始快速發(fā)展,從最早的圖片分類問題,到后來的檢測,分割問題。在2014年,[7]第一次成功引入了CNN來解決單人姿態(tài)估計的問題。因為當(dāng)時的時代背景,整體網(wǎng)絡(luò)結(jié)構(gòu)比較簡單,同時也沿用了傳統(tǒng)骨架的思路。首先是通過slide-window的方式,來對每個patch進(jìn)行分類,找到相應(yīng)的人體關(guān)鍵點。因為直接sliding-window少了很多context信息,所以會有很多FP的出現(xiàn)。所以在pipeline上面加上了一個post-processing的步驟,主要是希望能抑制部分FP,具體實現(xiàn)方式是類似一個空間位置的模型。所以從這個工作來看,有一定的傳統(tǒng)姿態(tài)估計方法的慣性,改進(jìn)的地方是把原來的傳統(tǒng)的feature representation改成了深度學(xué)習(xí)的網(wǎng)絡(luò),同時把空間位置關(guān)系當(dāng)成是后處理來做處理。總體性能在當(dāng)時已經(jīng)差不多跑過了傳統(tǒng)的姿態(tài)估計方法。
部分主要用于描述在深度學(xué)習(xí)之前,我們是如何處理人體姿態(tài)估計這個問題。從算法角度來講,這部分的工作主要是希望解決單人的人體姿態(tài)估計問題,也有部分工作已經(jīng)開始嘗試做3D的人體姿態(tài)估計。可以粗略的方法分成兩類。第一類是直接通過一個全局feature,把姿態(tài)估計問題當(dāng)成分類或者回歸問題直接求解 [1][2]。但是這類方法的問題在于精度一般,并且可能比較適用于背景干凈的場景。第二類是基于一個graphical model,比如常用pictorial structure model。一般包含unary term,是指對單個part進(jìn)行feature的representation,單個part的位置往往可以使用DPM (Deformable Part-based model)來獲得。同時需要考慮pair-wise關(guān)系來優(yōu)化關(guān)鍵點之間的關(guān)聯(lián)。基于Pictorial Structure,后續(xù)有非常多的改進(jìn),要么在于如何提取更好的feature representation [3][4], 要么在于建模更好的空間位置關(guān)系[5][6]。總結(jié)一下,在傳統(tǒng)方法里面,需要關(guān)注的兩個維度是: feature representation以及關(guān)鍵點的空間位置關(guān)系。特征維度來講,傳統(tǒng)方法一般使用的HOG, Shape Context, SIFT等shallow feature。 空間位置關(guān)系的表示也有很多形式,上面的Pictorial structure model可能只是一種。這兩個維度在深度學(xué)習(xí)時代也是非常至關(guān)重要的,只是深度學(xué)習(xí)往往會把特征提取,分類,以及空間位置的建模都在一個網(wǎng)絡(luò)中直接建模,所以不需要獨(dú)立的進(jìn)行拆解,這樣更方便設(shè)計和優(yōu)化。從2012年AlexNet開始,深度學(xué)習(xí)開始快速發(fā)展,從最早的圖片分類問題,到后來的檢測,分割問題。在2014年,[7]第一次成功引入了CNN來解決單人姿態(tài)估計的問題。因為當(dāng)時的時代背景,整體網(wǎng)絡(luò)結(jié)構(gòu)比較簡單,同時也沿用了傳統(tǒng)骨架的思路。首先是通過slide-window的方式,來對每個patch進(jìn)行分類,找到相應(yīng)的人體關(guān)鍵點。因為直接sliding-window少了很多context信息,所以會有很多FP的出現(xiàn)。所以在pipeline上面加上了一個post-processing的步驟,主要是希望能抑制部分FP,具體實現(xiàn)方式是類似一個空間位置的模型。所以從這個工作來看,有一定的傳統(tǒng)姿態(tài)估計方法的慣性,改進(jìn)的地方是把原來的傳統(tǒng)的feature representation改成了深度學(xué)習(xí)的網(wǎng)絡(luò),同時把空間位置關(guān)系當(dāng)成是后處理來做處理。總體性能在當(dāng)時已經(jīng)差不多跑過了傳統(tǒng)的姿態(tài)估計方法。
2014年的另外一個重要的進(jìn)展是引入了MPII的數(shù)據(jù)集。此前的大部分paper都是基于FLIC以及LSP來做評估的,但是在深度學(xué)習(xí)時代,數(shù)據(jù)量還是相對偏少(K級別)。MPII把數(shù)據(jù)量級提升到W級別,同時因為數(shù)據(jù)是互聯(lián)網(wǎng)采集,同時是針對activity來做篩選的,所以無論從難度還是多樣性角度來講,都比原來的數(shù)據(jù)集有比較好的提升。一直到2016年,隨著深度學(xué)習(xí)的爆發(fā),單人姿態(tài)估計的問題也引來了黃金時間。這里需要重點講一下兩個工作,一個工作是Convolutional Pose Machine (CPM)[8],另外一個是Hourglass [9]。
CPM是CMU Yaser Sheikh組的工作,后續(xù)非常有名的openpose也是他們的工作。從CPM開始,神經(jīng)網(wǎng)絡(luò)已經(jīng)可以e2e的把feature representation以及關(guān)鍵點的空間位置關(guān)系建模進(jìn)去(隱式的建模),輸入一個圖片的patch, 輸出帶spatial信息的tensor,channel的個數(shù)一般就是人體關(guān)鍵點的個數(shù)(或者是關(guān)鍵點個數(shù)加1)。空間大小往往是原圖的等比例縮放圖。通過在輸出的heatmap上面按channel找最大的響應(yīng)位置(x,y坐標(biāo)),就可以找到相應(yīng)關(guān)鍵點的位置。這種heatmap的方式被廣泛使用在人體骨架的問題里面。這個跟人臉landmark有明顯的差異,一般人臉landmark會直接使用回歸(fully connected layer for regression)出landmark的坐標(biāo)位置。這邊我做一些解釋。首先人臉landmark的問題往往相對比較簡單,對速度很敏感,所以直接回歸相比heatmap來講速度會更快,另外直接回歸往往可以得到sub-pixel的精度,但是heatmap的坐標(biāo)進(jìn)度取決于在spatial圖片上面的argmax操作,所以精度往往是pixel級別(同時會受下采樣的影響)。 但是heatmap的好處在于空間位置信息的保存,這個非常重要。一方面,這個可以保留multi-modal的信息,比如沒有很好的context信息的情況下,是很難區(qū)分左右手的,所以圖片中左右手同時都可能有比較好的響應(yīng),這種heatmap的形式便于后續(xù)的cascade的進(jìn)行refinement優(yōu)化。另外一個方面,人體姿態(tài)估計這個問題本身的自由度很大,直接regression的方式對自由度小的問題比如人臉landmark是比較適合的,但是對于自由度大的姿態(tài)估計問題整體的建模能力會比較弱。相反,heatmap是比較中間狀態(tài)的表示,所以信息的保存會更豐富。后續(xù)2D的人體姿態(tài)估計方法幾乎都是圍繞heatmap這種形式來做的(3D姿態(tài)估計將會是另外一條路),通過使用神經(jīng)網(wǎng)絡(luò)來獲得更好的feature representation,同時把關(guān)鍵點的空間位置關(guān)系隱式的encode在heatmap中,進(jìn)行學(xué)習(xí)。大部分的方法區(qū)別在于網(wǎng)絡(luò)設(shè)計的細(xì)節(jié)。先從CPM開始說起。 整個網(wǎng)絡(luò)會有多個stage,每個stage設(shè)計一個小型網(wǎng)絡(luò),用于提取feature,然后在每個stage結(jié)束的時候,加上一個監(jiān)督信號。中間層的信息可以給后續(xù)層提供context,后續(xù)stage可以認(rèn)為是基于前面的stage做refinement。這個工作在MPII上面的結(jié)果可以達(dá)到88.5,在當(dāng)時是非常好的結(jié)果。
整個網(wǎng)絡(luò)會有多個stage,每個stage設(shè)計一個小型網(wǎng)絡(luò),用于提取feature,然后在每個stage結(jié)束的時候,加上一個監(jiān)督信號。中間層的信息可以給后續(xù)層提供context,后續(xù)stage可以認(rèn)為是基于前面的stage做refinement。這個工作在MPII上面的結(jié)果可以達(dá)到88.5,在當(dāng)時是非常好的結(jié)果。
在2016年的7月份,Princeton的Deng Jia組放出了另外一個非常棒的人體姿態(tài)估計工作,Hourglass。后續(xù)Deng Jia那邊基于Hourglass的想法做了Associate Embedding,以及后續(xù)的CornerNet都是非常好的工作。Hourglass相比CPM的最大改進(jìn)是網(wǎng)絡(luò)結(jié)構(gòu)更簡單,更優(yōu)美。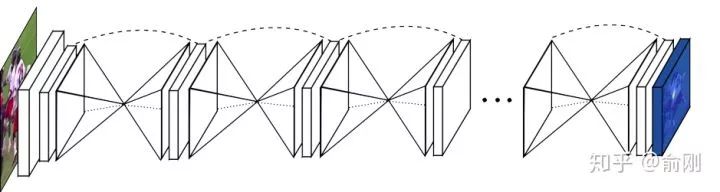 從上圖可以看出,網(wǎng)絡(luò)是重復(fù)的堆疊一個u-shape的structure.
從上圖可以看出,網(wǎng)絡(luò)是重復(fù)的堆疊一個u-shape的structure. 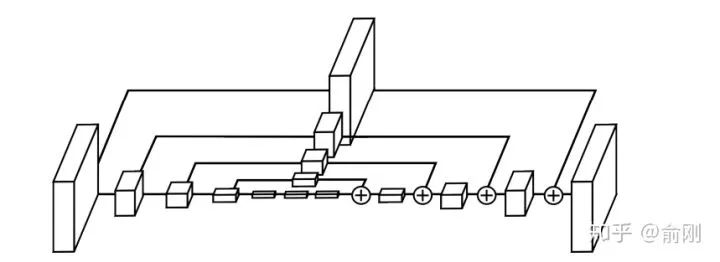 pipeline上面跟CPM很類似。只是結(jié)構(gòu)做了修改。從MPII上的結(jié)果來看,也有明顯的提升,可以達(dá)到90.9的PCKh。這種u-shape的結(jié)構(gòu)其實被廣泛應(yīng)用于現(xiàn)代化的物體檢測,分割等算法中,同時結(jié)果上面來講也是有非常好的提升的。另外,Hourglass這種堆多個module的結(jié)構(gòu),后續(xù)也有一些工作follow用在其他任務(wù)上面。但是Hourglass也是存在一些問題的,具體可以看后續(xù)講解的MSPN網(wǎng)絡(luò)。在CPM以及Hourglass之后,也有很多不錯的工作持續(xù)在優(yōu)化單人姿態(tài)估計算法,比如[10][11]。2016年的下半年還出現(xiàn)了一個非常重要的數(shù)據(jù)集: COCO。這個時間點也是非常好的時間點。一方面,MPII已經(jīng)出現(xiàn)兩年,同時有很多非常好的工作,比如CPM, Hourglass已經(jīng)把結(jié)果推到90+,數(shù)據(jù)集已經(jīng)開始呈現(xiàn)出一定的飽和狀態(tài)。另外一方面,物體檢測/行人檢測方面,算法提升也特別明顯,有了很多很好的工作出現(xiàn),比如Faster R-CNN和SSD。所以COCO的團(tuán)隊在COCO的數(shù)據(jù)集上面引入了多人姿態(tài)估計的標(biāo)注,并且加入到了2016年COCO比賽中,當(dāng)成是一個track。從此,多人姿態(tài)估計成為學(xué)術(shù)界比較active的研究topic。正如前面我在“問題”的部分描述的,多人姿態(tài)估計會分成top-down以及bottom-up兩種模式。我們這邊會先以bottom-up方法開始描述。
pipeline上面跟CPM很類似。只是結(jié)構(gòu)做了修改。從MPII上的結(jié)果來看,也有明顯的提升,可以達(dá)到90.9的PCKh。這種u-shape的結(jié)構(gòu)其實被廣泛應(yīng)用于現(xiàn)代化的物體檢測,分割等算法中,同時結(jié)果上面來講也是有非常好的提升的。另外,Hourglass這種堆多個module的結(jié)構(gòu),后續(xù)也有一些工作follow用在其他任務(wù)上面。但是Hourglass也是存在一些問題的,具體可以看后續(xù)講解的MSPN網(wǎng)絡(luò)。在CPM以及Hourglass之后,也有很多不錯的工作持續(xù)在優(yōu)化單人姿態(tài)估計算法,比如[10][11]。2016年的下半年還出現(xiàn)了一個非常重要的數(shù)據(jù)集: COCO。這個時間點也是非常好的時間點。一方面,MPII已經(jīng)出現(xiàn)兩年,同時有很多非常好的工作,比如CPM, Hourglass已經(jīng)把結(jié)果推到90+,數(shù)據(jù)集已經(jīng)開始呈現(xiàn)出一定的飽和狀態(tài)。另外一方面,物體檢測/行人檢測方面,算法提升也特別明顯,有了很多很好的工作出現(xiàn),比如Faster R-CNN和SSD。所以COCO的團(tuán)隊在COCO的數(shù)據(jù)集上面引入了多人姿態(tài)估計的標(biāo)注,并且加入到了2016年COCO比賽中,當(dāng)成是一個track。從此,多人姿態(tài)估計成為學(xué)術(shù)界比較active的研究topic。正如前面我在“問題”的部分描述的,多人姿態(tài)估計會分成top-down以及bottom-up兩種模式。我們這邊會先以bottom-up方法開始描述。
在2016年COCO比賽中,當(dāng)時的第一名就是OpenPose [12]。CMU團(tuán)隊基于CPM為組件,先找到圖片中的每個joint的位置,然后提出Part Affinity Field (PAF)來做人體的組裝。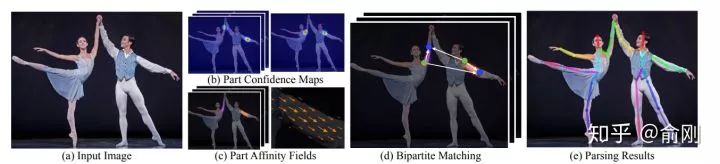 PAF的基本原理是在兩個相鄰關(guān)鍵點之間,建立一個有向場,比如左手腕,左手肘。我們把CPM找到的所有的左手腕以及左手肘拿出來建立一個二分圖,邊權(quán)就是基于PAF的場來計算的。然后進(jìn)行匹配,匹配成功就認(rèn)為是同一個人的關(guān)節(jié)。依次類別,對所有相鄰點做此匹配操作,最后就得到每個人的所有關(guān)鍵點。在當(dāng)時來講,這個工作效果是非常驚艷的,特別是視頻的結(jié)果圖,具體可以參考Openpose的Github官網(wǎng)。在COCO的benchmark test-dev上面的AP結(jié)果大概是61.8。
PAF的基本原理是在兩個相鄰關(guān)鍵點之間,建立一個有向場,比如左手腕,左手肘。我們把CPM找到的所有的左手腕以及左手肘拿出來建立一個二分圖,邊權(quán)就是基于PAF的場來計算的。然后進(jìn)行匹配,匹配成功就認(rèn)為是同一個人的關(guān)節(jié)。依次類別,對所有相鄰點做此匹配操作,最后就得到每個人的所有關(guān)鍵點。在當(dāng)時來講,這個工作效果是非常驚艷的,特別是視頻的結(jié)果圖,具體可以參考Openpose的Github官網(wǎng)。在COCO的benchmark test-dev上面的AP結(jié)果大概是61.8。
- Hourglass + Associative Embedding
在2016年比賽的榜單上面,還有另外一個很重要的工作就是Deng Jia組的Associative Embedding[13]。文章類似Openpose思路,使用bottom-up的方法,尋找part使用了Hourglass的方式來做。關(guān)鍵在于行人的組裝上面,提出了Associative Embedding的想法。大概想法是希望對每個關(guān)鍵點輸出一個embedding,使得同一個人的embedding盡可能相近,不同人的embedding盡可能不一樣。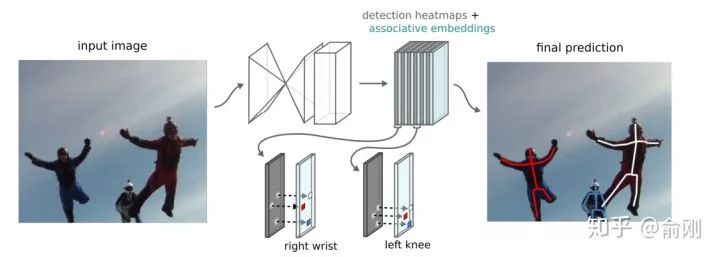 在COCO2016比賽后,這個工作持續(xù)的在提升,文章發(fā)表的時候,COCO test-dev上面的結(jié)果在65.5。除了Openpose以及Associative Embedding之外,bottom-up還有一個工作非常不錯,DeepCut[14]以及DeeperCut[15],他們使用優(yōu)化問題來直接優(yōu)化求解人的組合關(guān)系。
在COCO2016比賽后,這個工作持續(xù)的在提升,文章發(fā)表的時候,COCO test-dev上面的結(jié)果在65.5。除了Openpose以及Associative Embedding之外,bottom-up還有一個工作非常不錯,DeepCut[14]以及DeeperCut[15],他們使用優(yōu)化問題來直接優(yōu)化求解人的組合關(guān)系。
后面一部分章節(jié)我會重點圍繞COCO數(shù)據(jù)集,特別是COCO每年的比賽來描述多人姿態(tài)估計的進(jìn)展。雖然2016年bottom-up是一個豐富時間點,但是從2017年開始,越來的工作開始圍繞top-down展開,一個直接的原因是top-down的效果往往更有潛力。top-down相比bottom-up效果好的原因可以認(rèn)為有兩點。首先是人的recall往往更好。因為top-down是先做人體檢測,人體往往會比part更大,所以從檢測角度來講會更簡單,相應(yīng)找到的recall也會更高。其次是關(guān)鍵點的定位精度會更準(zhǔn),這部分原因是基于crop的框,對空間信息有一定的align,同時因為在做single person estimation的時候,可以獲得一些中間層的context信息,對于點的定位是很有幫助的。當(dāng)然,top-down往往會被認(rèn)為速度比bottom-up會更慢,所以在很多要求實時速度,特別是手機(jī)端上的很多算法都是基于openpose來做修改的。不過這個也要例外,我們自己也有做手機(jī)端上的多人姿態(tài)估計,但是我們是基于top-down來做的,主要原因是我們的人體檢測器可以做的非常快。說完了背景后,在COCO2017年的比賽中,我們的CPN[16]一開始就決定圍繞top-down的算法進(jìn)行嘗試。我們當(dāng)時的想法是一個coarse-to-fine的邏輯,先用一個網(wǎng)絡(luò)出一個coarse的結(jié)果(GlobalNet),然后再coarse的結(jié)果上面做refinement (RefineNet)。具體結(jié)果如下: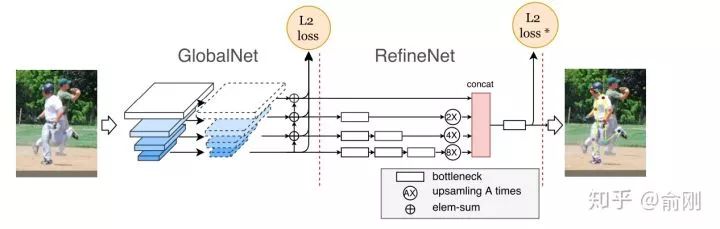 為了處理處理難的樣本,我們在loss上面做了一定的處理,最后的L2 loss我們希望針對難的關(guān)鍵點進(jìn)行監(jiān)督,而不是針對所有關(guān)鍵點uniform的進(jìn)行監(jiān)督,所以我們提出了一個Hard keypoint mining的loss。這個工作最后在COCO test-dev達(dá)到了72.1的結(jié)果 (不使用額外數(shù)據(jù)以及ensemble),獲得了2017年的COCO骨架比賽的第一名。這個工作的另外一個貢獻(xiàn)是比較完備的ablation。我們給出了很多因素的影響。比如top-down的第一步是檢測,我們分析了檢測性能對最后結(jié)果的影響。物體檢測結(jié)果從30+提升到40+(mmAP)的時候,人體姿態(tài)估計能有一定的漲點(1個點左右),但是從40+提升到50+左右,漲點就非常微弱了(0.1-0.2)。另外,我們對data augmentation,網(wǎng)絡(luò)的具體結(jié)構(gòu)設(shè)計都給出了比較完整的實驗結(jié)果。另外,我們開始引入了傳統(tǒng)的ImageNet basemodel (ResNet50)做了backbone,而不是像Openpose或者Hourglass這種非主流的模型設(shè)計結(jié)構(gòu),所以效果上面也有很好的提升。
為了處理處理難的樣本,我們在loss上面做了一定的處理,最后的L2 loss我們希望針對難的關(guān)鍵點進(jìn)行監(jiān)督,而不是針對所有關(guān)鍵點uniform的進(jìn)行監(jiān)督,所以我們提出了一個Hard keypoint mining的loss。這個工作最后在COCO test-dev達(dá)到了72.1的結(jié)果 (不使用額外數(shù)據(jù)以及ensemble),獲得了2017年的COCO骨架比賽的第一名。這個工作的另外一個貢獻(xiàn)是比較完備的ablation。我們給出了很多因素的影響。比如top-down的第一步是檢測,我們分析了檢測性能對最后結(jié)果的影響。物體檢測結(jié)果從30+提升到40+(mmAP)的時候,人體姿態(tài)估計能有一定的漲點(1個點左右),但是從40+提升到50+左右,漲點就非常微弱了(0.1-0.2)。另外,我們對data augmentation,網(wǎng)絡(luò)的具體結(jié)構(gòu)設(shè)計都給出了比較完整的實驗結(jié)果。另外,我們開始引入了傳統(tǒng)的ImageNet basemodel (ResNet50)做了backbone,而不是像Openpose或者Hourglass這種非主流的模型設(shè)計結(jié)構(gòu),所以效果上面也有很好的提升。
2018年的COCO比賽中,我們繼續(xù)沿用top-down的思路。當(dāng)時我們基于CPN做了一些修改,比如把backbone不停的擴(kuò)大,發(fā)現(xiàn)效果提升很不明顯。我們做了一些猜測,原來CPN的兩個stage可能并沒有把context信息利用好,單個stage的模型能力可能已經(jīng)比較飽和了,增加更多stage來做refinement可能是一個解決當(dāng)前問題,提升人體姿態(tài)估計算法uppper-bound的途徑。所以我們在CPN的globalNet基礎(chǔ)上面,做了多個stage的堆疊,類似于Hourglass的結(jié)構(gòu)。 相比Hourglass結(jié)構(gòu),我們提出的MSPN[17]做了如下三個方面的改進(jìn)。首先是Hourglass的每個stage的網(wǎng)絡(luò),使用固定的256 channel,即使中間有下采樣,這種結(jié)構(gòu)對信息的提取并不是很有益。所以我們使用了類似ResNet-50這種標(biāo)準(zhǔn)的ImageNet backbone做為每個stage的網(wǎng)絡(luò)。另外,在兩個相鄰stage上面,我們也加入了一個連接用于更好的信息傳遞。最后,我們對于每個stage的中間層監(jiān)督信號做了不同的處理,前面層的監(jiān)督信號更側(cè)重分類,找到coarse的位置,后面更側(cè)重精確的定位。從最后效果上面來看,我們在COCO test-dev上面一舉跑到了76.1 (單模型不加額外數(shù)據(jù))。
相比Hourglass結(jié)構(gòu),我們提出的MSPN[17]做了如下三個方面的改進(jìn)。首先是Hourglass的每個stage的網(wǎng)絡(luò),使用固定的256 channel,即使中間有下采樣,這種結(jié)構(gòu)對信息的提取并不是很有益。所以我們使用了類似ResNet-50這種標(biāo)準(zhǔn)的ImageNet backbone做為每個stage的網(wǎng)絡(luò)。另外,在兩個相鄰stage上面,我們也加入了一個連接用于更好的信息傳遞。最后,我們對于每個stage的中間層監(jiān)督信號做了不同的處理,前面層的監(jiān)督信號更側(cè)重分類,找到coarse的位置,后面更側(cè)重精確的定位。從最后效果上面來看,我們在COCO test-dev上面一舉跑到了76.1 (單模型不加額外數(shù)據(jù))。
之前我們講的很多人體姿態(tài)估計方面的工作,都在圍繞context來做工作,如何更好的encode和使用這些context是大家工作的重點。到了2019年, MSRA wang jingdong組出了一個很好的工作,提出了spatial resolution的重要性。在這篇工作之前,我們往往會暴力的放大圖片來保留更多信息,同時給出更精準(zhǔn)的關(guān)鍵點定位,比如從256x192拉大到384x288。這樣對效果提升還是很明顯的,但是對于計算量的增加也是非常大的。HRNet從另外一個角度,拋出了一個新的可能性: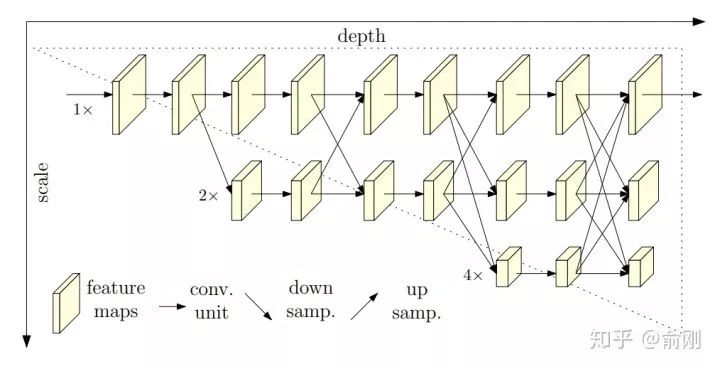 相比傳統(tǒng)的下采樣的網(wǎng)絡(luò)結(jié)構(gòu),這里提出了一種新的結(jié)構(gòu)。分成多個層級,但是始終保留著最精細(xì)的spaital那一層的信息,通過fuse下采樣然后做上采樣的層,來獲得更多的context以及語義層面的信息(比如更大的感受野)。從結(jié)果上面來看,在COCO test-dev上面單模型可以達(dá)到75.5。到此為止,我們重點講述了幾個多人姿態(tài)估計的算法,當(dāng)然中間穿插了不少我們自己的私貨。在多人姿態(tài)估計領(lǐng)域還有很多其他很好的工作,因為篇幅問題,這里我們就略過了。回到2017年,MPI提出了一個新的數(shù)據(jù)集, PoseTrack,主要是希望能幫忙解決視頻中的人體姿態(tài)估計的問題,并且在每年的ICCV或者ECCV上面做challenge比賽。PoseTrack的數(shù)據(jù)集主要還是來源于MPII的數(shù)據(jù)集,標(biāo)注風(fēng)格也很相近。圍繞PoseTrack這個任務(wù),我們重點講一個工作, Simple Baselines。
相比傳統(tǒng)的下采樣的網(wǎng)絡(luò)結(jié)構(gòu),這里提出了一種新的結(jié)構(gòu)。分成多個層級,但是始終保留著最精細(xì)的spaital那一層的信息,通過fuse下采樣然后做上采樣的層,來獲得更多的context以及語義層面的信息(比如更大的感受野)。從結(jié)果上面來看,在COCO test-dev上面單模型可以達(dá)到75.5。到此為止,我們重點講述了幾個多人姿態(tài)估計的算法,當(dāng)然中間穿插了不少我們自己的私貨。在多人姿態(tài)估計領(lǐng)域還有很多其他很好的工作,因為篇幅問題,這里我們就略過了。回到2017年,MPI提出了一個新的數(shù)據(jù)集, PoseTrack,主要是希望能幫忙解決視頻中的人體姿態(tài)估計的問題,并且在每年的ICCV或者ECCV上面做challenge比賽。PoseTrack的數(shù)據(jù)集主要還是來源于MPII的數(shù)據(jù)集,標(biāo)注風(fēng)格也很相近。圍繞PoseTrack這個任務(wù),我們重點講一個工作, Simple Baselines。
Simple Baselines [19]是xiao bin在MSRA的工作。提出了一種非常簡潔的結(jié)構(gòu)可以用于多人姿態(tài)估計以及人體姿態(tài)估計的跟蹤問題。這里重點講一下對于PoseTrack的處理方法: 這里有兩個細(xì)節(jié),首先是會利用上一幀的檢測結(jié)果,merge到新的一幀,避免檢測miss的問題。另外,在兩幀間,會使用OKS based相似度來做人體的關(guān)聯(lián),而不是只是簡單的使用框的overlap,這樣可以更好的利用每個關(guān)鍵點的temporal smooth的性質(zhì)。從結(jié)果上面來看,這個方法也獲得了PoseTrack2018比賽的第一名。到目前位置,我們描述了單人的姿態(tài)估計,多人的姿態(tài)估計,以及簡單講了一下視頻中的人體姿態(tài)跟蹤的問題。最后,我們講一下3D人體姿態(tài)估計的問題,這個我覺得這個是目前非常active的研究方向,也是未來的重要的方向。
這里有兩個細(xì)節(jié),首先是會利用上一幀的檢測結(jié)果,merge到新的一幀,避免檢測miss的問題。另外,在兩幀間,會使用OKS based相似度來做人體的關(guān)聯(lián),而不是只是簡單的使用框的overlap,這樣可以更好的利用每個關(guān)鍵點的temporal smooth的性質(zhì)。從結(jié)果上面來看,這個方法也獲得了PoseTrack2018比賽的第一名。到目前位置,我們描述了單人的姿態(tài)估計,多人的姿態(tài)估計,以及簡單講了一下視頻中的人體姿態(tài)跟蹤的問題。最后,我們講一下3D人體姿態(tài)估計的問題,這個我覺得這個是目前非常active的研究方向,也是未來的重要的方向。
3D人體姿態(tài)估計目前我們先限制在RGB輸入數(shù)據(jù)的情況下,不考慮輸入數(shù)據(jù)本身是RGBD的情況。我們大概可以把這個問題分成兩個子問題:第一個是出人體的3D關(guān)鍵點。相比之前的2D關(guān)鍵點,這里需要給出每個點的3D位置。另外一種是3D shape,可以給出人體的3D surface,可以認(rèn)為是更dense的skeleton信息(比如Densepose, SMPL模型)。先從3D關(guān)鍵點說起。主要的方法可以分成兩類,第一類是割裂的考慮。把3D skeleton問題拆解成2D人體姿態(tài)估計,以及從2D關(guān)鍵點預(yù)測3D關(guān)鍵點兩個步驟。另外一類是joint的2D以及3D的姿態(tài)估計。大部分的基于深度學(xué)習(xí)的3D人體骨架工作是從2017年開始的,主要的上下文是因為2D人體姿態(tài)估計中CPM以及Hourglass給出了很好的效果,使得3D Skeleton成為可能。我們先從3D跟2D skeleton割裂的算法開始說起。首先從2017年deva Ramanan組的一個非常有意思的工作【20】開始說起,3D Human Pose Estimation = 2D Pose Estimation + Matching。從名字可以看出,大致的做法。首先是做2D的人體姿態(tài)估計,然后基于Nearest neighbor最近鄰的match來從training data中找最像的姿態(tài)。2D的姿態(tài)估計算法是基于CPM來做的。3D的match方法是先把training data中的人體3d骨架投射到2D空間,然后把test sample的2d骨架跟這些training data進(jìn)行對比,最后使用最相近的2d骨架對應(yīng)的3D骨架當(dāng)成最后test sample點3D骨架。當(dāng)training數(shù)據(jù)量非常多的時候,這種方法可能可以保證比較好的精度,但是在大部分時候,這種匹配方法的精度較粗,而且誤差很大。隨后,也在17年,另外一個非常有意思的工作【21】發(fā)表在ICCV2017。同樣,從這個工作的名字可以看出,這個工作提出了一個比較simple的baseline,但是效果還是非常明顯。方法上面來講,就是先做一個2d skeleton的姿態(tài)估計,方法是基于Hourglass的,文章中的解釋是較好的效果以及不錯的速度。基于獲得的2d骨架位置,后續(xù)接入兩個fully connected的操作,直接回歸3D坐標(biāo)點。這個做法非常粗暴直接,但是效果還是非常明顯的。在回歸之前,需要對坐標(biāo)系統(tǒng)做一些操作。同樣,從2017年的ICCV開始,已經(jīng)有工作【22】開始把2D以及3d skeleton的估計問題joint一起來做優(yōu)化。這樣的好處其實是非常明顯的。因為很多2d數(shù)據(jù)對于3d來講是有幫助的,同時3D姿態(tài)對于2d位置點估計也能提供額外的信息輔助。2D的MPII, COCO數(shù)據(jù)可以讓算法獲得比較強(qiáng)的前背景點分割能力,然后3D的姿態(tài)估計數(shù)據(jù)集只需要關(guān)注前景的3D骨架估計。這也是目前學(xué)術(shù)界數(shù)據(jù)集的現(xiàn)狀。從實際效果上面來講,joint training的方法效果確實也比割裂的train 2d以及3d skeleton效果要好。從2018年開始,3D skeleton開始往3d shape發(fā)展。原先只需要知道joint點的3D坐標(biāo)位置,但是很多應(yīng)用,比如人體交互,美體,可能需要更dense的人體姿態(tài)估計。這時候就有了一個比較有意思的工作densePose 【23】。這個工作既提出來一個新的問題,也包含新的benchmark以及baseline。相比傳統(tǒng)的SMPL模型,這個工作提出了使用UV map來做估計(同時間也有denseBody類似的工作),可以獲得非常dense的3d姿態(tài)位置,等價于生成了3d shape。當(dāng)然,從3d shape的角度來講,有很多非常不錯的工作,這里就不做重點展開。最后講一下3d人體姿態(tài)估計目前存在的問題。我個人認(rèn)為主要是benchmark。目前最常使用的human 3.6M實際上很容易被overfit,因為subjects數(shù)量太小(實際訓(xùn)練樣本只有5-6人,depend on具體的測試方法,測試樣本更少)。同時,是在受限的實驗室場景錄制,跟真實場景差異太大,背景很干凈,同時前景的動作pose也比較固定。當(dāng)然,3d skeleton的數(shù)據(jù)集的難度非常大,特別是需要采集unconstrained條件下面的數(shù)據(jù)。目前也有一些工作在嘗試用生成的數(shù)據(jù)來提升結(jié)果。
最后,講了這么多的人體姿態(tài)估計,我們最后說一下人體姿態(tài)估計有什么用,這里的人體姿態(tài)估計是一個廣義的人體姿態(tài)估計,包含2D/3D等。首先的一個應(yīng)用是人體的動作行為估計,要理解行人,人體的姿態(tài)估計其實是一個非常重要的中間層信息。目前有蠻多基于人體姿態(tài)估計直接做action recogntion的工作,比如把關(guān)鍵點當(dāng)成graph的節(jié)點,然后是使用graph convolution network來整合各種信息做動作分類。我博士的研究課題是action recognition,我讀完四年博士的一個總結(jié)是action這個問題,如果需要真正做到落地,人體姿態(tài)估計算法是必不可少的組成部分。第二類應(yīng)用是偏娛樂類的,比如人體交互,美體等。比如可以通過3d姿態(tài)估計來虛擬出一個動畫人物來做交互,使用真實人體來控制虛擬人物。另外比如前一段時間比較火熱的瘦腰,美腿等操作背后都可能依賴于人體姿態(tài)估計算法。第三類應(yīng)用是可以做為其他算法的輔助環(huán)節(jié),比如Person ReID可以基于人體姿態(tài)估計來做alignment,姿態(tài)估計可以用來輔助行人檢測,殺掉檢測的FP之類的。深度學(xué)習(xí)帶來了學(xué)術(shù)界以及工業(yè)界的飛速發(fā)展,極大的提升了目前算法的結(jié)果,也使得我們開始關(guān)注并嘗試解決一些更有挑戰(zhàn)性的問題。下面的幾點我是側(cè)重于把人體姿態(tài)估計真正落地到產(chǎn)品中而展開的。當(dāng)然也可以換個維度考慮更長線的研究發(fā)展,這個可能希望以后有機(jī)會再一起討論。
我覺得這個是一個非常重要的研究方向,不管是對2d還是3d。以2d為例,雖然目前數(shù)據(jù)量已經(jīng)非常的大,比如COCO數(shù)據(jù),大概有6w+的圖片數(shù)據(jù)。但是大部分pose都是正常pose,比如站立,走路等。對于一些特殊pose,比如摔倒,翻越等并沒有多少數(shù)據(jù)。或者可以這么理解,這些數(shù)據(jù)的收集成本很高。如果我們可以通過生成數(shù)據(jù)的方法來無限制的生成出各種各樣的數(shù)據(jù)的話,這個對于算法的提升是非常的關(guān)鍵。雖然目前GAN之類的數(shù)據(jù)生成質(zhì)量并不高,但是對于人體姿態(tài)估計這個問題來講其實已經(jīng)夠了,因為我們不需要清晰真實的細(xì)節(jié),更多的是需要多樣性的前景(不同著裝的人)和pose。但是數(shù)據(jù)生成的方式對于人體姿態(tài)估計本身也有一個非常大的挑戰(zhàn),這個可以留做作業(yè),感興趣的同學(xué)可以在留言區(qū)回復(fù)。
這個問題其實是行人檢測的問題。目前市面上沒有能針對擁擠場景很work的行人檢測算法。這個問題的主要瓶頸在于行人檢測的一個后處理步驟:NMS (Non-maximum suppression)。這個其實是從傳統(tǒng)物體檢測方法時代就有的問題。因為目前大部分算法不能區(qū)分一個行人的兩個框還是兩個不同行人的兩個框,所以使用NMS來基于IOU用高分框抑制低分框。這個問題在傳統(tǒng)的DPM以及ACF時代問題并不突出,因為當(dāng)時算法精度遠(yuǎn)沒有達(dá)到需要考慮NMS的問題。但是隨著技術(shù)的進(jìn)步,目前NMS已經(jīng)是一個越來越明顯的瓶頸,或者說也是行人檢測真正落地的一個很重要的障礙。最近我們提出了一個新的數(shù)據(jù)集CrowdHuman,希望引起大家對于遮擋擁擠問題的關(guān)注。從算法上面來講,最近也陸續(xù)開始由蠻多不錯的工作在往這個方向努力,但是離解決問題還是有一定的距離。回到人體姿態(tài)估計這個問題,目前top-down方法依賴于檢測,所以這個問題避免不了。bottom-up可能可以繞開,但是從assemble行人的角度,擁擠場景這個問題也非常有挑戰(zhàn)。
剛剛我們講到,2D以及3D人體姿態(tài)估計可以聯(lián)合training,從而提升整體結(jié)果。同樣,其實可以把人體姿態(tài)估計跟人體相關(guān)的其他任務(wù)一起聯(lián)合做數(shù)據(jù)的標(biāo)注以及訓(xùn)練。這里可以考慮的包括人體分割(human segmentation),人體部位的parse (human parse)等。可以這么理解,human seg本身的標(biāo)注可以認(rèn)為是多邊形的標(biāo)注,我們可以在多邊形輪廓上面進(jìn)行采點,這幾個任務(wù)可以很自然的聯(lián)合起來。人體多任務(wù)的聯(lián)合訓(xùn)練我覺得對于充分理解行人是非常有意義的,同時也可以提升各個任務(wù)本身的精度。當(dāng)然潛在的問題是數(shù)據(jù)標(biāo)注的成本會增加。另外可以考慮的是跨數(shù)據(jù)集的聯(lián)合training,比如某個數(shù)據(jù)集只有skeleton標(biāo)注,有個數(shù)據(jù)集只有seg標(biāo)注等,這個問題其實也是工業(yè)界中很常見的一個問題。
速度永遠(yuǎn)是產(chǎn)品落地中需要重點考慮的問題。目前大部分學(xué)術(shù)paper可能都是在GPU做到差不多實時的水平,但是很多應(yīng)用場景需要在端上,比如手機(jī)的ARM上面進(jìn)行實時高效的處理。我們之前有嘗試過使用我們自己的ThunderNet [24]做人體檢測,然后拼上一個簡化版的CPN來做人體姿態(tài)估計,可以做到端上近似實時的速度,但是效果跟GPU上面還是有一定差距。所以速度的優(yōu)化是非常有價值的。
- UnConstrained 3D skeleton Benchmark
這個我上面也有提到,3D人體姿態(tài)估計急需一個更大更有挑戰(zhàn)的benchmark來持續(xù)推動這個領(lǐng)域的進(jìn)步。隨著很多3d sensor的普及,我理解我們不一定需要依賴傳統(tǒng)的多攝像頭的setting來做采集,這個使得我們能獲得更真實,更wild的數(shù)據(jù)。這里只是從我個人的角度列了一些人體姿態(tài)估計的重要工作,當(dāng)然其中可能miss了很多細(xì)節(jié),很多重要的文獻(xiàn),但是我希望這個是一個引子,吸引更多的同學(xué)來一起投入這個方向,一起來推動這個領(lǐng)域的落地。因為我時刻相信人體姿態(tài)估計的進(jìn)步,將會是我們真正從視覺角度理解行人的非常關(guān)鍵的一步。最后,希望借此也感謝一下我們R4D中做人體姿態(tài)估計的同學(xué),感謝志成、逸倫、文博、斌一、琦翔、禹明、天孜、瑞豪、正雄等等,雖然可能有些同學(xué)已經(jīng)奔赴各地,但是非常感謝各位的付出也懷念和大家一起戰(zhàn)斗的時光。
[1] Randomized Trees for Human Pose Detection, Rogez etc, CVPR 2018
[2] Local probabilistic regression for activity-independent human pose inference, Urtasun etc, ICCV 2009
[3] Strong Appearance and Expressive Spatial Models for Human Pose Estimation, Pishchulin etc, ICCV 2013
[4] Pictorial Structures Revisited: People Detection and Articulated Pose Estimation, Andriluka etc, CVPR 2009
[5] Latent Structured Models for Human Pose Estimation, Ionescu etc, ICCV 2011
[6] Poselet Conditioned Pictorial Structures, Pishchulin etc, CVPR 2013
[7] Learning Human Pose Estimation Features with Convolutional Networks, Jain etc, ICLR 2014
[8] Convolutional Pose Machines, Wei etc, CVPR 2016
[9] Stacked Hourglass Networks for Human Pose Estimation, Newell etc, ECCV 2016
[10] Multi-Context Attention for Human Pose Estimation, Chu etc, CVPR 2017
[11] Deeply Learned Compositional Models for Human Pose Estimation, ECCV 2018
[12] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields, Cao etc, CVPR 2017
[13] Associative Embedding: End-to-End Learning for Joint Detection and Grouping, Newell etc, NIPS 2017
[14] DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation, Pishchulin etc, CVPR 2016
[15] DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model, Insafutdinov, ECCV 2016
[16] Cascaded Pyramid Network for Multi-Person Pose Estimation, Chen etc, CVPR 2017
[17] Rethinking on Multi-Stage Networks for Human Pose Estimation, Li etc, Arxiv 2018
[18] Deep High-Resolution Representation Learning for Human Pose Estimation, Sun etc, CVPR 2019
[19] Simple Baselines for Human Pose Estimation and Tracking, Xiao etc, ECCV 2018
[20] 3D Human Pose Estimation = 2D Pose Estimation + Matching, Chen etc, CVPR 2017
[21] A simple yet effective baseline for 3d human pose estimation, Martinez, ICCV 2017
[22] Compositional Human Pose Regression, Sun etc, ICCV 2017
[23] Densepose: Dense Human Pose Estimation in the Wild, Guler etc, CVPR 2018
[24] ThunderNet: Toward Real-time Generic Object Detection, Qin etc, ICCV 2019
雙一流大學(xué)研究生團(tuán)隊創(chuàng)建,專注于目標(biāo)檢測與深度學(xué)習(xí),希望可以將分享變成一種習(xí)慣!整理不易,點贊三連↓
