
深度學(xué)習(xí)中的那些Trade-off
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號
重磅干貨,第一時(shí)間送達(dá)


極市導(dǎo)讀
在深度學(xué)習(xí)中我們往往想要追求精度、內(nèi)存、通信和計(jì)算四個指標(biāo)都滿足,但現(xiàn)實(shí)總是讓人做出取舍,本文介紹了五個業(yè)內(nèi)常見的trade-off做法。
魚與熊掌不可兼得,深度學(xué)習(xí)領(lǐng)域中的幾個指標(biāo)也相同。
主要的指標(biāo)有如下四個:
(1)精度:自然精度是一個模型最根本的衡量指標(biāo),如果一個模型精度不高,再快,再綠色環(huán)保也無濟(jì)于事。基本上所有刷榜的工作都是用其他所有指標(biāo)換精度:比如用更深的網(wǎng)絡(luò)就是用memory和computation換精度。然而到了實(shí)際應(yīng)用中,尤其是部署側(cè),工程師越來越多的用一些方法適當(dāng)?shù)臏p少精度從而換取更小的內(nèi)存占用或者運(yùn)算時(shí)間
(2)內(nèi)存:Out Of Memory Error恐怕是煉丹師最常見的情況了。內(nèi)存(或者說可以高效訪問的存儲空間)的尺寸是有限的,如果網(wǎng)絡(luò)訓(xùn)練需要的內(nèi)存太大了,可能程序直接就報(bào)錯了,即使不報(bào)錯,也需要把內(nèi)存中的數(shù)據(jù)做個取舍,一部分存到相對較慢的存儲介質(zhì)中(比如host memory)
(3) 通信:隨著網(wǎng)絡(luò)規(guī)模越來越大,分布式訓(xùn)練已經(jīng)是state-of-the-art的網(wǎng)絡(luò)模型必不可少的部分(你見過誰用單卡在ImageNet訓(xùn)練ResNet50?),在大規(guī)模分布式系統(tǒng),通信帶寬比較低,相比于computation或者memory load/sotre,network communication會慢很多,如果可以降低通信量,那么整個網(wǎng)絡(luò)的訓(xùn)練時(shí)間就會有大幅減少:這樣研究員就不會借口調(diào)參,實(shí)際上把模型往服務(wù)器上一扔自己就跑出去浪了。(資本家狂喜)

(4)計(jì)算:雖然我們用的是計(jì)算機(jī),但實(shí)際上恐怕只有很少的時(shí)間用于計(jì)算(computation)了,因?yàn)榇蠖鄶?shù)時(shí)間都在等待數(shù)據(jù)的讀取或者網(wǎng)絡(luò)通信,不過即便如此,對于一些計(jì)算密集型的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)(比如BERT,幾乎都是矩陣乘法),制約我們的往往是設(shè)備的計(jì)算能力(FLOPS),即每秒鐘可以處理多少浮點(diǎn)計(jì)算。
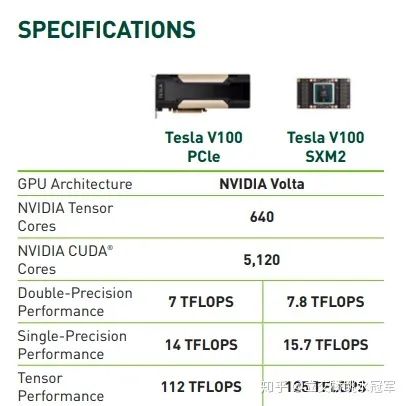
計(jì)算能力是重要指標(biāo),即使多數(shù)情況用不滿
無疑同時(shí)將以上四點(diǎn)做好是我們追求的,但現(xiàn)實(shí)往往很殘酷,需要我們做很多取舍。今天就在這兒介紹一些業(yè)內(nèi)常見的trade-off
(1)計(jì)算換內(nèi)存
很多時(shí)候內(nèi)存是最重要的:計(jì)算慢了我們多等一等就行了,內(nèi)存爆了就徹底訓(xùn)練不了了。在神經(jīng)網(wǎng)絡(luò)訓(xùn)練中,內(nèi)存的占用大頭往往是activation,即神經(jīng)網(wǎng)絡(luò)每層的輸出。我們在訓(xùn)練的時(shí)候需要把這些輸出(activation)記錄下來,因?yàn)槲覀兎聪騻鞑サ臅r(shí)候需要用這些activation計(jì)算梯度。
一個很直觀的想法就是:我們干脆把一堆a(bǔ)ctivation扔掉,到時(shí)候需要他們的時(shí)候再算一遍。這就是checkpoint機(jī)制的想法。雖然這個想法很簡單,但是對于一個特定的神經(jīng)網(wǎng)絡(luò),究竟扔掉/保留哪些activation一直沒有定論,有興趣的同學(xué)可以看一下我之前寫的另一篇文章了解這個專題:
立交橋跳水冠軍:DNN顯存優(yōu)化的終點(diǎn)?Checkmate論文總結(jié)
https://zhuanlan.zhihu.com/p/299861314
(2)通信換內(nèi)存
隨著BERT,GPT的發(fā)展,研究員發(fā)現(xiàn)一件更尷尬的事情:內(nèi)存不夠了,但這次不僅僅是裝不下activation,甚至光是參數(shù)(parame)和參數(shù)對應(yīng)的optimizer都裝不下了。那之前說的checkpoint就不管用了(人家只負(fù)責(zé)省activation)。
這時(shí)候有些讀者會有想法:那如果我一張卡裝不下,就兩張卡來唄。恭喜你!你的想法和世界上最頂尖的程序員一樣!這種做法可以被稱為Model Parallel,即每個分布式節(jié)點(diǎn)存儲不同的參數(shù),feed一樣的數(shù)據(jù)。目前Model Parallel有兩種,粗略來說可以分成intra-layer拆分和inter-layer拆分:
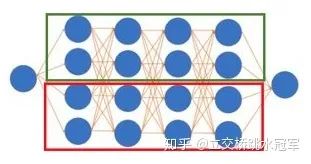
intra-layer拆分,多見于NLP模型
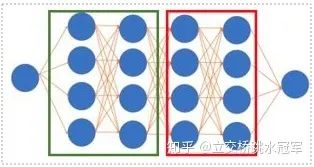
inter-layer拆分,多見于CV模型
上面的例子可能比較抽象,我們來結(jié)合下面的兩個具體工作說一下這兩種model-parallel:
首先是intra-layer的拆分:
我們知道神經(jīng)網(wǎng)絡(luò)是一層一層的,每層可能是一個卷積,一個Pool,或者BN什么的。如果我們對一層進(jìn)行了拆分,那么就是intra-layer的。下面這張圖摘自英偉達(dá)的Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism(https://arxiv.org/abs/1909.08053),描述了如何把兩個很大的矩陣乘法拆開到兩個節(jié)點(diǎn)上來算

本來矩陣乘法是 和 (忽略激活層什么的)。我們知道矩陣乘法有很好的性質(zhì):我們可以把矩陣乘法變成分塊矩陣乘法。因此我們可以把上面的矩陣乘法變成
和
因此如果我們讓第一個節(jié)點(diǎn)計(jì)算 ,第二個節(jié)點(diǎn)計(jì)算 ,最后再累加兩個人的結(jié)果,不就好了?這樣的好處就是第一個節(jié)點(diǎn)只需要存儲A1和B1,第二個只需要A2和B2,相當(dāng)于節(jié)省了一半的空間(和一個節(jié)點(diǎn)存儲A和B相比)
inter-layer拆分:和intra-layer不同,我們只做網(wǎng)絡(luò)層之間的切分。這種切分方式更符合直覺。上面的例子來自PipeDream(https://arxiv.org/abs/1806.03377、PipeDream: Fast and Efficient Pipeline Parallel DNN Training)。假設(shè)我們有5層的神經(jīng)網(wǎng)絡(luò),有四個節(jié)點(diǎn)可以用,那我們可以讓第一個節(jié)點(diǎn)算第一層,第二個節(jié)點(diǎn)算第二層,第三個節(jié)點(diǎn)算第三層,第四個節(jié)點(diǎn)算最后兩層。這樣我們很直接的就把網(wǎng)絡(luò)拆開了,不管第1-5層的具體操作是卷積,BN還是什么,都可以這么搞

但這么拆有一個問題,就是每臺機(jī)器之間都存在數(shù)據(jù)依賴:當(dāng)你發(fā)現(xiàn)第1,2,3節(jié)點(diǎn)在悠閑地打王者,第四節(jié)點(diǎn)在苦逼的干活,你就上去質(zhì)問他們你們?yōu)樯对趧澦克麄儽硎竞軣o辜:我在等第四節(jié)點(diǎn)把結(jié)果算完,然后把梯度傳給我啊

把每個節(jié)點(diǎn)工作的時(shí)間系統(tǒng)的記錄下來,發(fā)現(xiàn)所有時(shí)刻都只有一個人在干活
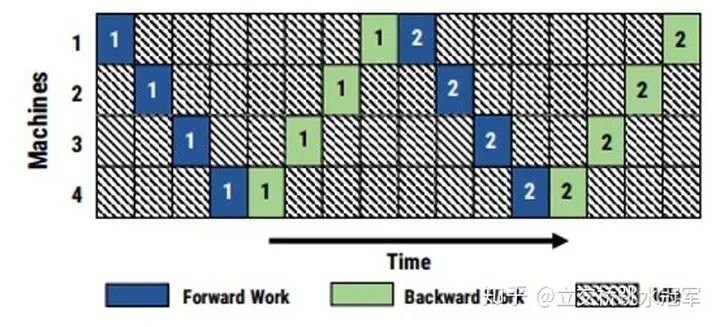
很自然的想法就是,如果每個人都處理不同的batch不就好了?但這樣做可能會引發(fā)精度的問題。有興趣的讀者可以去看PipeDream的論文。
(3)計(jì)算換通信
雖然剛才介紹了模型并行,但目前主流的還是數(shù)據(jù)并行,即每張卡分到同樣的parameter,每次接收不同的input,算完之后每個人把自己的local gradient做一次同步,得到global gradient來更新本地的參數(shù)(如下圖所示)
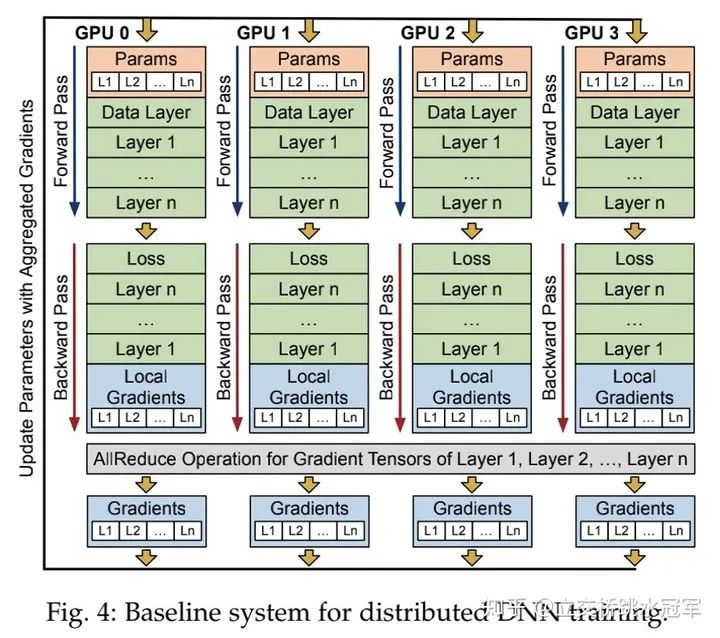
在這種情況下,我們的通信只發(fā)生在gradient allReduce的時(shí)刻(即圖中最下面灰色的框)。雖然它只是訓(xùn)練過程的一部分,但因?yàn)殡S著分布式系統(tǒng)的增大,通信速度和計(jì)算、訪存時(shí)間相比會越來越慢,因此這個allReduce操作逐漸成為了性能瓶頸。
為了打破這個瓶頸,有些研究員嘗試壓縮梯度:每次我們并不通信梯度本身,而是先把梯度做一個壓縮,讓他們的size變小,然后把壓縮后的數(shù)據(jù)做一次傳輸,最后在本地解壓縮這些數(shù)據(jù),從而完成一次梯度的allReduce。其中做的比較好的就是TernGrad(TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning(https://arxiv.org/abs/1705.07878))。這個算法將原來一個N*float32這么大的梯度tensor壓縮成了N*3這么大的tensor,再加一些可以忽略不計(jì)的meta-data。即用(-1,0,1)來表示原本float32的數(shù)值。
(4)顯存換計(jì)算
這方面的例子我沒想到太多,就想到諸如用3個3*3的卷積代替一個7*7的卷積:感受野不變,計(jì)算量減少,但是原本一個activation變成了三個,顯存變大了。
(5)精度換計(jì)算/內(nèi)存/通信
這種方法很“流氓”:深度學(xué)習(xí)模型最重要的就是精度,如果為了計(jì)算、內(nèi)存和通信放棄了精度就很沒道理。
不過得益于神經(jīng)網(wǎng)絡(luò)的超強(qiáng)魯棒性,很多看似大膽的做法可以在顯著降低計(jì)算,內(nèi)存或通信的情況下只掉一點(diǎn)點(diǎn)精度。
這里簡單介紹幾種常見的做法:
量化/用低精度計(jì)算:顯而易見,如果你用Float16代替Float32,那么運(yùn)行速度,需要的內(nèi)存,需要的帶寬基本上都可以直接砍一半 稀疏通信:精度換通信的一種做法:我們每次對梯度做all reduce的時(shí)候并不需要傳所有梯度,只需要選擇一部分(比如數(shù)值比較大)的梯度傳輸就好了 神經(jīng)網(wǎng)絡(luò)的各種剪枝:比如把很小的weight直接刪掉,畢竟對最終結(jié)果沒啥影響
推薦閱讀
國產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營維護(hù)的號,大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識,歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!