
實踐|手寫邏輯回歸算法
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
盡管對于機器學習來說,理論是非常重要的內容,但是持續(xù)的理論學習多少會有些審美疲勞。今天,我們就試著用代碼來簡單實現(xiàn)一下邏輯回歸,也方便大家更好地理解邏輯回歸的原理,以及機器學習模型在實踐中是怎么運作的。
一、邏輯回歸算法步驟簡述
構建一個邏輯回歸模型有以下幾步:
收集數(shù)據:采用任意方法收集數(shù)據
準備數(shù)據:由于需要進行距離計算,因此我們要求數(shù)據類型為數(shù)值型。若是結構化數(shù)據格式更佳
分析數(shù)據:采用任意方法對數(shù)據進行分析
訓練算法:大部分時間將用于訓練,訓練的目的是為了找到最佳的分類回歸系數(shù)
測試算法:訓練步驟完成后將對算法進行測試
使用算法:首先我們需要輸入一些數(shù)據,并將其轉換成對應的結構化數(shù)值;接著,基于訓練好的回歸系數(shù)就可以對這些數(shù)值進行簡單的回歸運算,判定它們屬于哪個類別;在這之后,我們就可以在輸出的類別上做一些其它的分析工作。
并且,因為邏輯回歸適用于二元分類,因此,我們這次的這組數(shù)據的預測值僅有0和1(其它類型的數(shù)值也沒關系,但都以0,1表示會比較方便)分別代表二元分類中的negative class 和 possitive class。
二、選擇輸入函數(shù):sigmoid函數(shù)
因為我們已經確定是邏輯回歸模型(若是未知模型的數(shù)據我們還需要從頭推導模型),所以作為分類器的輸出函數(shù)我們選擇邏輯函數(shù),又稱sigmoid函數(shù):
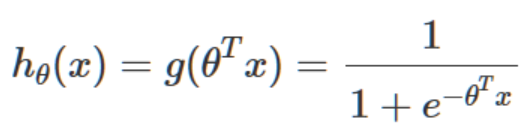
我們將sigmoid函數(shù)的輸入θTx記為z,z由下面這個公式導出:

顯然,x便是我們的輸入變量。
三、選擇優(yōu)化算法:梯度上升法
作為第一次訓練,我們選擇比較簡單的參數(shù)更新方法:梯度上升法,它細分為兩種,一種是精度比較高但消耗比較大的批梯度上升法:

另一種是精度較低但速度較快的隨機梯度上升法:
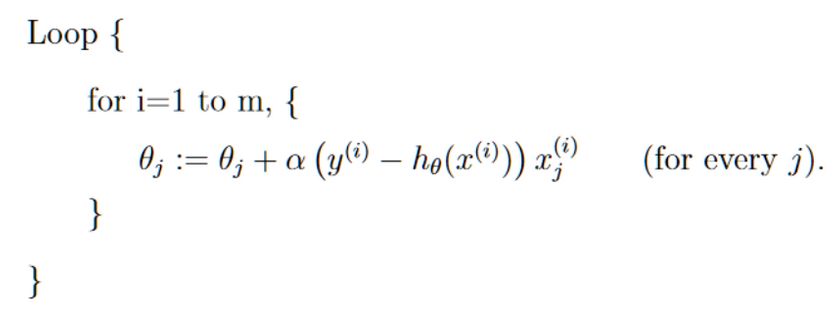
四、觀察數(shù)據集
在數(shù)據集的樣本特征還處在比較的低維的空間(方便我們觀察的空間,像是二維(兩個特征)或者三維(三個特征))的時候,我們可以為數(shù)據集繪制坐標圖形從而對坐標進行簡單地觀察。盡管在現(xiàn)實任務中基本上不可能出現(xiàn)特征空間是二維或者三維的數(shù)據集,但在用代碼實現(xiàn)理論模型的時候,這些簡單的數(shù)據集能夠讓我們非常直觀的看到實現(xiàn)的模型的效果而不需要去借助比較復雜的模型評估方法,換句話說,它們能夠很好的輔助我們實現(xiàn)模型。
在現(xiàn)實任務中我們往往也有在處理數(shù)據前對數(shù)據集進行觀察的必要,不論是制定數(shù)據預處理的策略還是選擇模型的策略,觀察并且了解自己將要處理的數(shù)據集都是非常非常重要的一項工作。
這里我用的數(shù)據集是來自Peter Harrington《機器學習實戰(zhàn)》第五章上的數(shù)據集,github鏈接(https://github.com/pbharrin/machinelearninginaction)
這個數(shù)據集的樣本特征空間只有兩維,分別為x1和x2,標簽僅有正類(1)和負類(0),我們用matplotlib模塊來繪制它在平面直角坐標系上的數(shù)據分布圖像:

數(shù)據集導入和輸出代碼:


函數(shù)loadDataSet將數(shù)據集從testSet.txt逐行讀取并存入兩個矩陣中。testSet中每一行的數(shù)據有三個值,分別是X1,X2和數(shù)據對應的類別標簽。并且,注意到我們在dataMat中的第一個值設置為1,那其實是X0的值,這在這里單純的數(shù)據集輸出中沒有太大的作用,但是會方便之后我們導入模型時的計算。shape函數(shù)讀取矩陣的行數(shù)m和列數(shù)n。
figure建立繪圖平面,addsubplot表示我們要在平面上建立繪制幾個圖表,111說明我們希望繪制一個占整個平面1?1大小的圖表,然后選取第一個圖表。
scatter表示散點圖,參數(shù)marker='s'表示點的形狀為方形,它還可以接收一個參數(shù)s=<NUMBER>來調整點的大小。
五、批梯度上升訓練
得知數(shù)據集的輸出型狀后,我們可以著手構建模型了,這一次我們先使用梯度上升模型。
我們先來構筑sigmoid函數(shù):

表示接收一個輸入inX可以認為是我們在sigmoid函數(shù)中所說的’z’,用sigmoid函數(shù)輸出。
然后構建梯度上升函數(shù):

第一個參數(shù)是全部輸入樣本組成的二維數(shù)組,每一個樣本包含3個特征分別是X0,X1,X2,因此,用mat函數(shù)轉換后的dataMat是一個3 x 100的輸入矩陣。第二個參數(shù)是每一個樣本的標簽組成的矩陣,為了方便計算,我們在轉化它為1 x 100的矩陣后還要用transpose()將其轉置。
變量alpha表示梯度上升中的步長,maxCycles表示我們將要進行的步數(shù),一般來說我們也可以通過設定條件讓程序判斷收斂情況來自行決定合適的步長,但這一步我們暫且先簡化為這樣。weights便是我們希望求得的參數(shù),可以看作是上面給出的梯度上升的數(shù)學模型中的θ,這里我們先將其初始化為一個 3 x 1的矩陣分別對應數(shù)據的3個特征。
然后我們循環(huán)更新weights值,以找到最合適的weights。更新方式便是梯度上升更新:
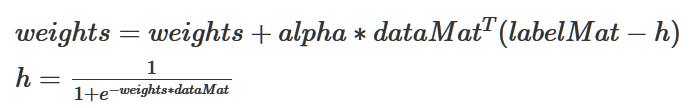
我們可以把它與上面的梯度更新公式對比一下。然后通過500步更新得到目標參數(shù)weights。
我們可以用print輸出看看我們得到的參數(shù):

然后將其繪制到我們一開始做的數(shù)據集表示圖上。


發(fā)現(xiàn)效果不錯。其中,函數(shù)getA()表示將矩陣weights轉換成數(shù)組,如果我們不這么做的話,輸出一下x和y就會發(fā)現(xiàn)這一步的必要性:

我們會發(fā)現(xiàn)y的值是被包裹在兩個[]里面的,實際上可以認為y是一個嵌套了兩層的一維矩陣,這也是為什么,我們要用getA來將weights從矩陣轉換回數(shù)組。
y的計算方式或許也會給人帶來疑問:實際上,我們知道,我們希望得到的是一條將兩個數(shù)據集分開的直線。因此,我們在給出一串連續(xù)的橫坐標(代碼中就是從-3到3每隔0.1取一個橫坐標)組成的向量后,就可以根據直線的方程y=kx+b(轉換成?w2X2=w1X1+w0)
計算這一連串橫坐標對應的y軸坐標,然后將其繪制到散點圖上。
六、隨機梯度上升訓練
因為我們這里的樣本比較小,所以我們的批梯度上升可以很快的就得到我們想要的結果,但實際上,很多數(shù)據集包含的內容都非常巨大,因此,為了能夠快速執(zhí)行分類任務,我們有時候會犧牲一些精度來換取運算的速度。這便是我們的隨機梯度上升法,它的原理我在機器學習理論中的筆記有講,這里就不再贅述:



可以得到我們隨機梯度下降的結果:

發(fā)現(xiàn)結果沒有之前的準確,這是當然的,因為我們犧牲了精度,隨機梯度上升對參數(shù)weights的每一次更新都只用了一個樣本,因此速度上相較批梯度上升會大幅提升。
下面這張圖表示每一次更新回歸參數(shù)X0,X1,X2的值,根據樣本次數(shù),我們總共更新了100次:
繪圖代碼:

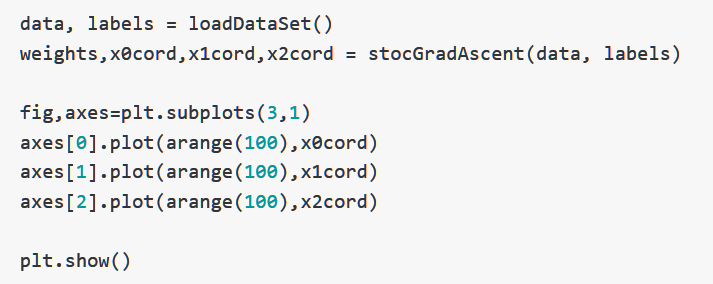
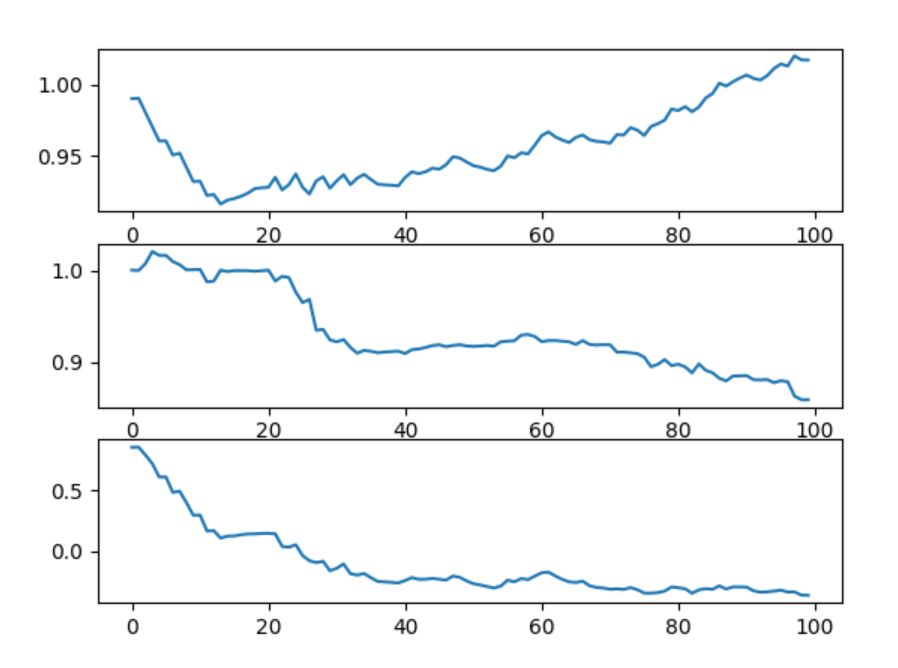
可以看出來,回歸參數(shù)的上下波動非常巨大,并且時常會往與梯度不同的方向更新,X2在開始的幾次更新之后很快達到了穩(wěn)定,但是X0和X1則沒有。
并且,我們可以發(fā)現(xiàn),參數(shù)在趨于穩(wěn)定之后依然會有局部波動,這是因為數(shù)據集中并非所有的數(shù)據都可以確保正確分類(因為數(shù)據集并非線性可分)。
資料來源參考:
Peter Harrington.《機器學習實戰(zhàn)》,人民郵電出版社
數(shù)據集來源 Github:Peter Harrington(https://github.com/pbharrin/machinelearninginaction)
好消息!
小白學視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~