
【機(jī)器學(xué)習(xí)】決策樹(shù)代碼練習(xí)
本課程是中國(guó)大學(xué)慕課《機(jī)器學(xué)習(xí)》的“決策樹(shù)”章節(jié)的課后代碼。
課程地址:
https://www.icourse163.org/course/WZU-1464096179
課程完整代碼:
https://github.com/fengdu78/WZU-machine-learning-course
代碼修改并注釋?zhuān)狐S海廣,[email protected]
機(jī)器學(xué)習(xí)練習(xí)7 決策樹(shù)
代碼修改并注釋?zhuān)狐S海廣,[email protected]
1.分類(lèi)決策樹(shù)模型是表示基于特征對(duì)實(shí)例進(jìn)行分類(lèi)的樹(shù)形結(jié)構(gòu)。決策樹(shù)可以轉(zhuǎn)換成一個(gè)if-then規(guī)則的集合,也可以看作是定義在特征空間劃分上的類(lèi)的條件概率分布。
2.決策樹(shù)學(xué)習(xí)旨在構(gòu)建一個(gè)與訓(xùn)練數(shù)據(jù)擬合很好,并且復(fù)雜度小的決策樹(shù)。因?yàn)閺目赡艿臎Q策樹(shù)中直接選取最優(yōu)決策樹(shù)是NP完全問(wèn)題。現(xiàn)實(shí)中采用啟發(fā)式方法學(xué)習(xí)次優(yōu)的決策樹(shù)。
決策樹(shù)學(xué)習(xí)算法包括3部分:特征選擇、樹(shù)的生成和樹(shù)的剪枝。常用的算法有ID3、 C4.5和CART。
3.特征選擇的目的在于選取對(duì)訓(xùn)練數(shù)據(jù)能夠分類(lèi)的特征。特征選擇的關(guān)鍵是其準(zhǔn)則。常用的準(zhǔn)則如下:
(1)樣本集合對(duì)特征的信息增益(ID3)
其中,是數(shù)據(jù)集的熵,是數(shù)據(jù)集的熵,是數(shù)據(jù)集對(duì)特征的條件熵。是中特征取第個(gè)值的樣本子集,是中屬于第類(lèi)的樣本子集。是特征取 值的個(gè)數(shù),是類(lèi)的個(gè)數(shù)。
(2)樣本集合對(duì)特征的信息增益比(C4.5)
其中,是信息增益,是數(shù)據(jù)集的熵。
(3)樣本集合的基尼指數(shù)(CART)
特征條件下集合的基尼指數(shù):
4.決策樹(shù)的生成。通常使用信息增益最大、信息增益比最大或基尼指數(shù)最小作為特征選擇的準(zhǔn)則。決策樹(shù)的生成往往通過(guò)計(jì)算信息增益或其他指標(biāo),從根結(jié)點(diǎn)開(kāi)始,遞歸地產(chǎn)生決策樹(shù)。這相當(dāng)于用信息增益或其他準(zhǔn)則不斷地選取局部最優(yōu)的特征,或?qū)⒂?xùn)練集分割為能夠基本正確分類(lèi)的子集。
5.決策樹(shù)的剪枝。由于生成的決策樹(shù)存在過(guò)擬合問(wèn)題,需要對(duì)它進(jìn)行剪枝,以簡(jiǎn)化學(xué)到的決策樹(shù)。決策樹(shù)的剪枝,往往從已生成的樹(shù)上剪掉一些葉結(jié)點(diǎn)或葉結(jié)點(diǎn)以上的子樹(shù),并將其父結(jié)點(diǎn)或根結(jié)點(diǎn)作為新的葉結(jié)點(diǎn),從而簡(jiǎn)化生成的決策樹(shù)。
import?numpy?as?np
import?pandas?as?pd
import?math
from?math?import?log
創(chuàng)建數(shù)據(jù)
def?create_data():
????datasets?=?[['青年',?'否',?'否',?'一般',?'否'],
???????????????['青年',?'否',?'否',?'好',?'否'],
???????????????['青年',?'是',?'否',?'好',?'是'],
???????????????['青年',?'是',?'是',?'一般',?'是'],
???????????????['青年',?'否',?'否',?'一般',?'否'],
???????????????['中年',?'否',?'否',?'一般',?'否'],
???????????????['中年',?'否',?'否',?'好',?'否'],
???????????????['中年',?'是',?'是',?'好',?'是'],
???????????????['中年',?'否',?'是',?'非常好',?'是'],
???????????????['中年',?'否',?'是',?'非常好',?'是'],
???????????????['老年',?'否',?'是',?'非常好',?'是'],
???????????????['老年',?'否',?'是',?'好',?'是'],
???????????????['老年',?'是',?'否',?'好',?'是'],
???????????????['老年',?'是',?'否',?'非常好',?'是'],
???????????????['老年',?'否',?'否',?'一般',?'否'],
???????????????]
????labels?=?[u'年齡',?u'有工作',?u'有自己的房子',?u'信貸情況',?u'類(lèi)別']
????#?返回?cái)?shù)據(jù)集和每個(gè)維度的名稱(chēng)
????return?datasets,?labels
datasets,?labels?=?create_data()
train_data?=?pd.DataFrame(datasets,?columns=labels)
train_data
| 年齡 | 有工作 | 有自己的房子 | 信貸情況 | 類(lèi)別 | |
|---|---|---|---|---|---|
| 0 | 青年 | 否 | 否 | 一般 | 否 |
| 1 | 青年 | 否 | 否 | 好 | 否 |
| 2 | 青年 | 是 | 否 | 好 | 是 |
| 3 | 青年 | 是 | 是 | 一般 | 是 |
| 4 | 青年 | 否 | 否 | 一般 | 否 |
| 5 | 中年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 好 | 否 |
| 7 | 中年 | 是 | 是 | 好 | 是 |
| 8 | 中年 | 否 | 是 | 非常好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 老年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 好 | 是 |
| 12 | 老年 | 是 | 否 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 非常好 | 是 |
| 14 | 老年 | 否 | 否 | 一般 | 否 |
熵
def?calc_ent(datasets):
????data_length?=?len(datasets)
????label_count?=?{}
????for?i?in?range(data_length):
????????label?=?datasets[i][-1]
????????if?label?not?in?label_count:
????????????label_count[label]?=?0
????????label_count[label]?+=?1
????ent?=?-sum([(p?/?data_length)?*?log(p?/?data_length,?2)
????????????????for?p?in?label_count.values()])
????return?ent
條件熵
def?cond_ent(datasets,?axis=0):
????data_length?=?len(datasets)
????feature_sets?=?{}
????for?i?in?range(data_length):
????????feature?=?datasets[i][axis]
????????if?feature?not?in?feature_sets:
????????????feature_sets[feature]?=?[]
????????feature_sets[feature].append(datasets[i])
????cond_ent?=?sum([(len(p)?/?data_length)?*?calc_ent(p)
????????????????????for?p?in?feature_sets.values()])
????return?cond_ent
calc_ent(datasets)
0.9709505944546686
信息增益
def?info_gain(ent,?cond_ent):
????return?ent?-?cond_ent
def?info_gain_train(datasets):
????count?=?len(datasets[0])?-?1
????ent?=?calc_ent(datasets)
????best_feature?=?[]
????for?c?in?range(count):
????????c_info_gain?=?info_gain(ent,?cond_ent(datasets,?axis=c))
????????best_feature.append((c,?c_info_gain))
????????print('特征({})?的信息增益為:?{:.3f}'.format(labels[c],?c_info_gain))
????#?比較大小
????best_?=?max(best_feature,?key=lambda?x:?x[-1])
????return?'特征({})的信息增益最大,選擇為根節(jié)點(diǎn)特征'.format(labels[best_[0]])
info_gain_train(np.array(datasets))
特征(年齡) 的信息增益為:0.083
特征(有工作) 的信息增益為:0.324
特征(有自己的房子) 的信息增益為:0.420
特征(信貸情況) 的信息增益為:0.363
'特征(有自己的房子)的信息增益最大,選擇為根節(jié)點(diǎn)特征'
利用ID3算法生成決策樹(shù)
#?定義節(jié)點(diǎn)類(lèi)?二叉樹(shù)
class?Node:
????def?__init__(self,?root=True,?label=None,?feature_name=None,?feature=None):
????????self.root?=?root
????????self.label?=?label
????????self.feature_name?=?feature_name
????????self.feature?=?feature
????????self.tree?=?{}
????????self.result?=?{
????????????'label:':?self.label,
????????????'feature':?self.feature,
????????????'tree':?self.tree
????????}
????def?__repr__(self):
????????return?'{}'.format(self.result)
????def?add_node(self,?val,?node):
????????self.tree[val]?=?node
????def?predict(self,?features):
????????if?self.root?is?True:
????????????return?self.label
????????return?self.tree[features[self.feature]].predict(features)
class?DTree:
????def?__init__(self,?epsilon=0.1):
????????self.epsilon?=?epsilon
????????self._tree?=?{}
????#?熵
????@staticmethod
????def?calc_ent(datasets):
????????data_length?=?len(datasets)
????????label_count?=?{}
????????for?i?in?range(data_length):
????????????label?=?datasets[i][-1]
????????????if?label?not?in?label_count:
????????????????label_count[label]?=?0
????????????label_count[label]?+=?1
????????ent?=?-sum([(p?/?data_length)?*?log(p?/?data_length,?2)
????????????????????for?p?in?label_count.values()])
????????return?ent
????#?經(jīng)驗(yàn)條件熵
????def?cond_ent(self,?datasets,?axis=0):
????????data_length?=?len(datasets)
????????feature_sets?=?{}
????????for?i?in?range(data_length):
????????????feature?=?datasets[i][axis]
????????????if?feature?not?in?feature_sets:
????????????????feature_sets[feature]?=?[]
????????????feature_sets[feature].append(datasets[i])
????????cond_ent?=?sum([(len(p)?/?data_length)?*?self.calc_ent(p)
????????????????????????for?p?in?feature_sets.values()])
????????return?cond_ent
????#?信息增益
????@staticmethod
????def?info_gain(ent,?cond_ent):
????????return?ent?-?cond_ent
????def?info_gain_train(self,?datasets):
????????count?=?len(datasets[0])?-?1
????????ent?=?self.calc_ent(datasets)
????????best_feature?=?[]
????????for?c?in?range(count):
????????????c_info_gain?=?self.info_gain(ent,?self.cond_ent(datasets,?axis=c))
????????????best_feature.append((c,?c_info_gain))
????????#?比較大小
????????best_?=?max(best_feature,?key=lambda?x:?x[-1])
????????return?best_
????def?train(self,?train_data):
????????"""
????????input:數(shù)據(jù)集D(DataFrame格式),特征集A,閾值eta
????????output:決策樹(shù)T
????????"""
????????_,?y_train,?features?=?train_data.iloc[:,?:
???????????????????????????????????????????????-1],?train_data.iloc[:,
????????????????????????????????????????????????????????????????????-1],?train_data.columns[:
????????????????????????????????????????????????????????????????????????????????????????????-1]
????????#?1,若D中實(shí)例屬于同一類(lèi)Ck,則T為單節(jié)點(diǎn)樹(shù),并將類(lèi)Ck作為結(jié)點(diǎn)的類(lèi)標(biāo)記,返回T
????????if?len(y_train.value_counts())?==?1:
????????????return?Node(root=True,?label=y_train.iloc[0])
????????#?2,?若A為空,則T為單節(jié)點(diǎn)樹(shù),將D中實(shí)例樹(shù)最大的類(lèi)Ck作為該節(jié)點(diǎn)的類(lèi)標(biāo)記,返回T
????????if?len(features)?==?0:
????????????return?Node(
????????????????root=True,
????????????????label=y_train.value_counts().sort_values(
????????????????????ascending=False).index[0])
????????#?3,計(jì)算最大信息增益?同5.1,Ag為信息增益最大的特征
????????max_feature,?max_info_gain?=?self.info_gain_train(np.array(train_data))
????????max_feature_name?=?features[max_feature]
????????#?4,Ag的信息增益小于閾值eta,則置T為單節(jié)點(diǎn)樹(shù),并將D中是實(shí)例數(shù)最大的類(lèi)Ck作為該節(jié)點(diǎn)的類(lèi)標(biāo)記,返回T
????????if?max_info_gain?????????????return?Node(
????????????????root=True,
????????????????label=y_train.value_counts().sort_values(
????????????????????ascending=False).index[0])
????????#?5,構(gòu)建Ag子集
????????node_tree?=?Node(
????????????root=False,?feature_name=max_feature_name,?feature=max_feature)
????????feature_list?=?train_data[max_feature_name].value_counts().index
????????for?f?in?feature_list:
????????????sub_train_df?=?train_data.loc[train_data[max_feature_name]?==
??????????????????????????????????????????f].drop([max_feature_name],?axis=1)
????????????#?6,?遞歸生成樹(shù)
????????????sub_tree?=?self.train(sub_train_df)
????????????node_tree.add_node(f,?sub_tree)
????????#?pprint.pprint(node_tree.tree)
????????return?node_tree
????def?fit(self,?train_data):
????????self._tree?=?self.train(train_data)
????????return?self._tree
????def?predict(self,?X_test):
????????return?self._tree.predict(X_test)
datasets,?labels?=?create_data()
data_df?=?pd.DataFrame(datasets,?columns=labels)
dt?=?DTree()
tree?=?dt.fit(data_df)
tree
{'label:': None, 'feature': 2, 'tree': {'否': {'label:': None, 'feature': 1, 'tree': {'否': {'label:': '否', 'feature': None, 'tree': {}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}, '是': {'label:': '是', 'feature': None, 'tree': {}}}}
dt.predict(['老年',?'否',?'否',?'一般'])
'否'
Scikit-learn實(shí)例
from?sklearn.datasets?import?load_iris
from?sklearn.model_selection?import?train_test_split
from?collections?import?Counter
使用Iris數(shù)據(jù)集,我們可以構(gòu)建如下樹(shù):
#?data
def?create_data():
????iris?=?load_iris()
????df?=?pd.DataFrame(iris.data,?columns=iris.feature_names)
????df['label']?=?iris.target
????df.columns?=?[
????????'sepal?length',?'sepal?width',?'petal?length',?'petal?width',?'label'
????]
????data?=?np.array(df.iloc[:100,?[0,?1,?-1]])
????#?print(data)
????return?data[:,?:2],?data[:,?-1],iris.feature_names[0:2]
X,?y,feature_name=?create_data()
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,?y,?test_size=0.3)
決策樹(shù)分類(lèi)
from?sklearn.tree?import?DecisionTreeClassifier
from?sklearn.tree?import?export_graphviz
import?graphviz
from?sklearn?import?tree
clf?=?DecisionTreeClassifier()
clf.fit(X_train,?y_train,)
clf.score(X_test,?y_test)
0.9666666666666667
一旦經(jīng)過(guò)訓(xùn)練,就可以用 plot_tree函數(shù)繪制樹(shù):
tree.plot_tree(clf)?
[Text(197.83636363636364, 195.696, 'X[0] <= 5.45\ngini = 0.5\nsamples = 70\nvalue = [36, 34]'),
Text(121.74545454545455, 152.208, 'X[1] <= 2.8\ngini = 0.157\nsamples = 35\nvalue = [32, 3]'),
Text(60.872727272727275, 108.72, 'X[0] <= 4.75\ngini = 0.444\nsamples = 3\nvalue = [1, 2]'),
Text(30.436363636363637, 65.232, 'gini = 0.0\nsamples = 1\nvalue = [1, 0]'),
Text(91.30909090909091, 65.232, 'gini = 0.0\nsamples = 2\nvalue = [0, 2]'),
Text(182.61818181818182, 108.72, 'X[0] <= 5.3\ngini = 0.061\nsamples = 32\nvalue = [31, 1]'),
Text(152.1818181818182, 65.232, 'gini = 0.0\nsamples = 29\nvalue = [29, 0]'),
Text(213.05454545454546, 65.232, 'X[1] <= 3.2\ngini = 0.444\nsamples = 3\nvalue = [2, 1]'),
Text(182.61818181818182, 21.744, 'gini = 0.0\nsamples = 1\nvalue = [0, 1]'),
Text(243.4909090909091, 21.744, 'gini = 0.0\nsamples = 2\nvalue = [2, 0]'),
Text(273.92727272727274, 152.208, 'X[1] <= 3.5\ngini = 0.202\nsamples = 35\nvalue = [4, 31]'),
Text(243.4909090909091, 108.72, 'gini = 0.0\nsamples = 31\nvalue = [0, 31]'),
Text(304.3636363636364, 108.72, 'gini = 0.0\nsamples = 4\nvalue = [4, 0]')]
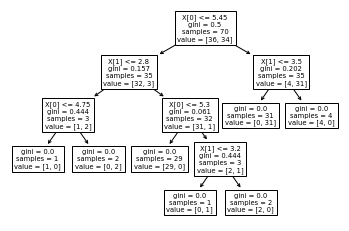
也可以導(dǎo)出樹(shù)
tree_pic?=?export_graphviz(clf,?out_file="mytree.pdf")
with?open('mytree.pdf')?as?f:
????dot_graph?=?f.read()
graphviz.Source(dot_graph)
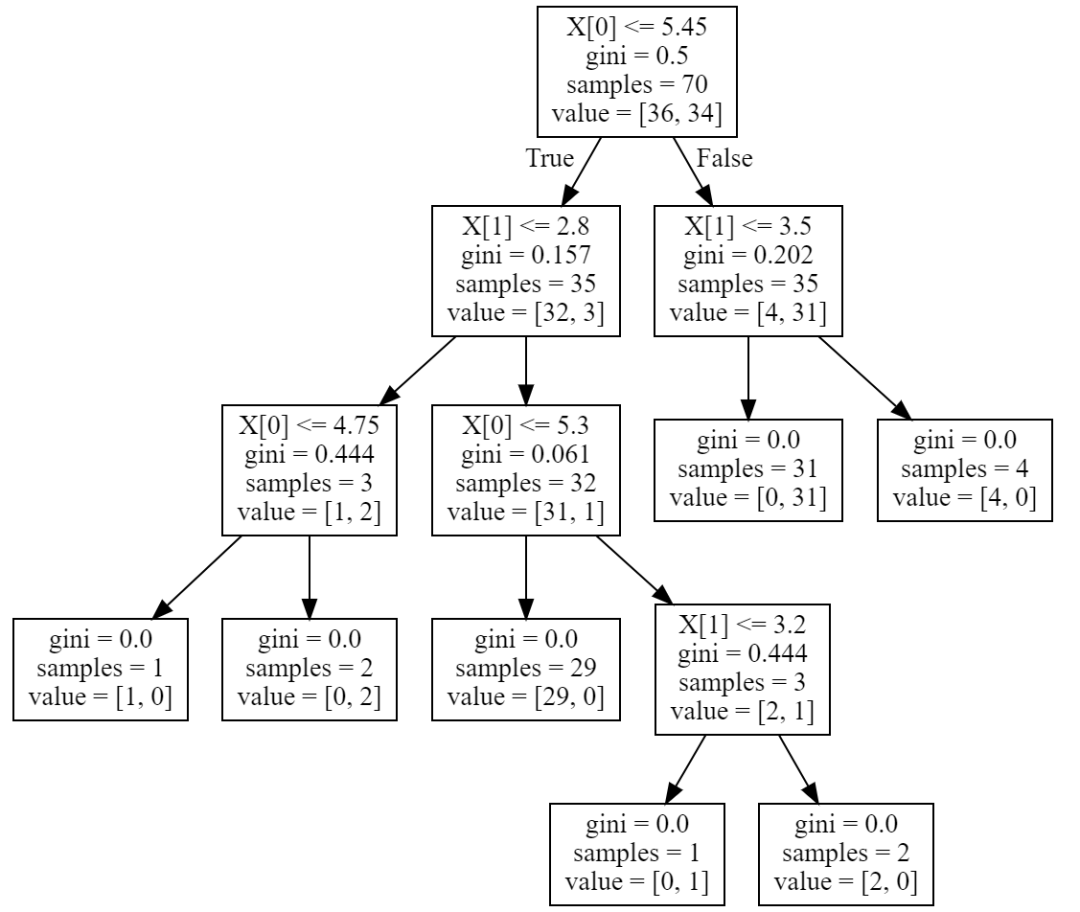
或者,還可以使用函數(shù) export_text以文本格式導(dǎo)出樹(shù)。此方法不需要安裝外部庫(kù),而且更緊湊:
from?sklearn.tree?import?export_text
r?=?export_text(clf,feature_name)
print(r)
|--- sepal width (cm) <= 3.15
| |--- sepal length (cm) <= 4.95
| | |--- sepal width (cm) <= 2.65
| | | |--- class: 1.0
| | |--- sepal width (cm) > 2.65
| | | |--- class: 0.0
| |--- sepal length (cm) > 4.95
| | |--- class: 1.0
|--- sepal width (cm) > 3.15
| |--- sepal length (cm) <= 5.85
| | |--- class: 0.0
| |--- sepal length (cm) > 5.85
| | |--- class: 1.0
決策樹(shù)回歸
import?numpy?as?np
from?sklearn.tree?import?DecisionTreeRegressor
import?matplotlib.pyplot?as?plt
#?Create?a?random?dataset
rng?=?np.random.RandomState(1)
X?=?np.sort(5?*?rng.rand(80,?1),?axis=0)
y?=?np.sin(X).ravel()
y[::5]?+=?3?*?(0.5?-?rng.rand(16))
#?Fit?regression?model
regr_1?=?DecisionTreeRegressor(max_depth=2)
regr_2?=?DecisionTreeRegressor(max_depth=5)
regr_1.fit(X,?y)
regr_2.fit(X,?y)
#?Predict
X_test?=?np.arange(0.0,?5.0,?0.01)[:,?np.newaxis]
y_1?=?regr_1.predict(X_test)
y_2?=?regr_2.predict(X_test)
#?Plot?the?results
plt.figure()
plt.scatter(X,?y,?s=20,?edgecolor="black",?c="darkorange",?label="data")
plt.plot(X_test,?y_1,?color="cornflowerblue",?label="max_depth=2",?linewidth=2)
plt.plot(X_test,?y_2,?color="yellowgreen",?label="max_depth=5",?linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision?Tree?Regression")
plt.legend()
plt.show()
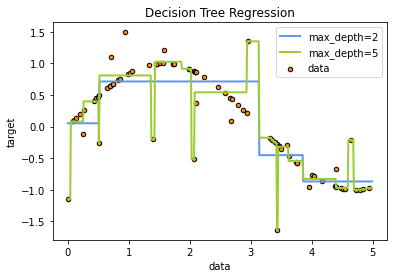
決策樹(shù)調(diào)參
#?導(dǎo)入庫(kù)
from?sklearn.tree?import?DecisionTreeClassifier
from?sklearn?import?datasets
from?sklearn.model_selection?import?train_test_split
import?matplotlib.pyplot?as?plt
from?sklearn.model_selection?import?GridSearchCV
from?sklearn.tree?import?DecisionTreeRegressor
from?sklearn?import?metrics
#?導(dǎo)入數(shù)據(jù)集
X?=?datasets.load_iris()??#?以全部字典形式返回,有data,target,target_names三個(gè)鍵
data?=?X.data
target?=?X.target
name?=?X.target_names
x,?y?=?datasets.load_iris(return_X_y=True)??#?能一次性取前2個(gè)
print(x.shape,?y.shape)
(150, 4) (150,)
#?數(shù)據(jù)分為訓(xùn)練集和測(cè)試集
x_train,?x_test,?y_train,?y_test?=?train_test_split(x,
????????????????????????????????????????????????????y,
????????????????????????????????????????????????????test_size=0.2,
????????????????????????????????????????????????????random_state=100)
#?用GridSearchCV尋找最優(yōu)參數(shù)(字典)
param?=?{
????'criterion':?['gini'],
????'max_depth':?[30,?50,?60,?100],
????'min_samples_leaf':?[2,?3,?5,?10],
????'min_impurity_decrease':?[0.1,?0.2,?0.5]
}
grid?=?GridSearchCV(DecisionTreeClassifier(),?param_grid=param,?cv=6)
grid.fit(x_train,?y_train)
print('最優(yōu)分類(lèi)器:',?grid.best_params_,?'最優(yōu)分?jǐn)?shù):',?grid.best_score_)??#?得到最優(yōu)的參數(shù)和分值
最優(yōu)分類(lèi)器: {'criterion': 'gini', 'max_depth': 30, 'min_impurity_decrease': 0.2, 'min_samples_leaf': 3} 最優(yōu)分?jǐn)?shù): 0.9416666666666665
參考
https://github.com/fengdu78/lihang-code
《統(tǒng)計(jì)學(xué)習(xí)方法》,清華大學(xué)出版社,李航著,2019年出版
https://scikit-learn.org