
優(yōu)化!1000元的Python副業(yè)單子,爬取下載美國科研網(wǎng)站數(shù)據(jù)
前情提要
此前已經(jīng)結(jié)單的美國科研數(shù)據(jù)爬蟲(詳情見1000元的Python副業(yè)單子,爬取下載美國科研網(wǎng)站數(shù)據(jù))雖然完結(jié)了,但是還是存在一些缺陷:
方案一爬取效率高,但是需要解析R關(guān)系,而R關(guān)系是手工整理的,且只整理到了2013年以前數(shù)據(jù),2014年起的數(shù)據(jù)就無法解析了; 方案二是每次請求一行數(shù)據(jù),雖然繞過了解析R關(guān)系,能夠達(dá)成目標(biāo),但其最大的缺陷是運(yùn)行時(shí)間太長了,爬蟲部分整整運(yùn)行了近6個(gè)小時(shí),向服務(wù)器發(fā)送了近18萬次請求。
以上缺陷是否可以進(jìn)行優(yōu)化呢?
本著精益求精的態(tài)度,花點(diǎn)時(shí)間將項(xiàng)目進(jìn)行一下優(yōu)化,看看能做到哪一步,Let's go!!!
優(yōu)化方案思路
將上述方案一和方案二進(jìn)行結(jié)合,在爬取全量數(shù)據(jù)時(shí)使用方案一,在解析R關(guān)系是使用方案二,那么就能大大的提高運(yùn)行效率,具體如下:
已知批量獲取的數(shù)據(jù),從第2行開始,若與上一行數(shù)據(jù)相同,則返回的數(shù)據(jù)中將不包括相同數(shù)據(jù),取而代之的是一個(gè)R關(guān)系的參數(shù),此外,還有一個(gè)?參數(shù),代表該行數(shù)據(jù)中,有部分列本身內(nèi)容為空值;那么要解析批量數(shù)據(jù),只需要推導(dǎo)出R與?兩個(gè)參數(shù)所對應(yīng)的規(guī)則; 推導(dǎo)規(guī)則只需要取得不同的R與?兩個(gè)參數(shù)組合數(shù)據(jù)的行樣例,以及其上一行數(shù)據(jù),即可進(jìn)行推導(dǎo); 那么處理步驟應(yīng)為: 1正常請求所有數(shù)據(jù) -> 2匯總數(shù)據(jù),取得R與?兩個(gè)參數(shù)組合對應(yīng)的樣例行 -> 3以單行請求的方式獲取樣例行 -> 4解析樣例行,推導(dǎo)出R與?參數(shù)組合與列的關(guān)系,制作成字典 -> 5正常解析第1步驟取得的所有數(shù)據(jù)行。
具體步驟
爬取全量數(shù)據(jù)
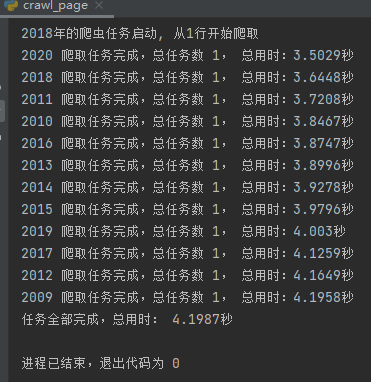
使用此前已經(jīng)完成的crawl_page.py爬蟲,nrows設(shè)置為20000行,即可一次請求完成該步驟,如下圖:
匯總分析已爬取的數(shù)據(jù)(使用jupyter notebook進(jìn)行探索)
obj1?=?ParseData()??#?創(chuàng)建方案一解析對象
#?使用方案1解析對象中的匯總功能,將爬取到的數(shù)據(jù)合并成一個(gè)dataframe
data?=?obj1.make_single_excel()??
#?R關(guān)系與?關(guān)系用0填充空值,并修改為整數(shù)形式
data['R']?=?data['R'].fillna(0).astype(int)
data['?']?=?data['?'].fillna(0).astype(int)
#?添加年份
data['year']?=?data['year'].astype(int)
data.head()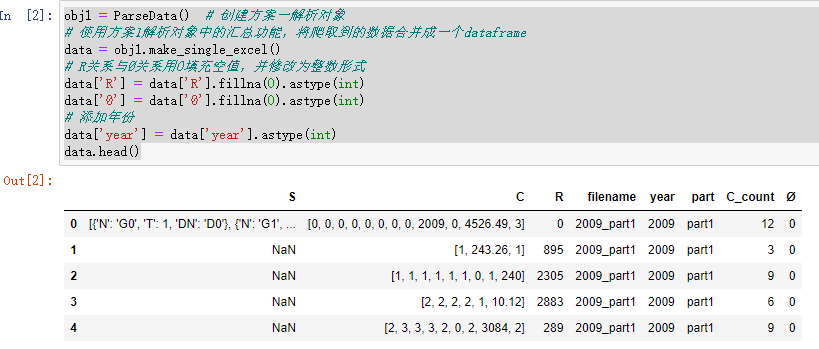
運(yùn)行截圖 #?刪除不需要的列
data?=?data.drop(columns=['S',?'C',?'filename',?'part'])
#?按關(guān)系組合去重,保留第一條不重復(fù)的數(shù)據(jù)
data?=?data.drop_duplicates(['R',?'?'],?keep='first')
#?列重新排序
data?=?data[['R',?'?',?'year']]
#?篩選去除0,?0?關(guān)系,該關(guān)系無需查詢
data?=?data.loc[~((data['R']?==?0)?&?(data['?']?==?0))]
data
近18萬行數(shù)據(jù)中,存在的關(guān)系組合共154種 整理獲取不重復(fù)的關(guān)系組合 首先匯總已經(jīng)爬取到的全量數(shù)據(jù),代碼如下: 要解析上述154種R和?的組合關(guān)系,那么需要這154行數(shù)據(jù),以及其上一行數(shù)據(jù),共308行數(shù)據(jù)進(jìn)行比對解析,因此問題轉(zhuǎn)變?yōu)槿绾稳〉眠@308行數(shù)據(jù)。
前期進(jìn)行頁面分析時(shí),可知每個(gè)請求的第1行都是完整的數(shù)據(jù),因此,只要定位到這154行的上一行位置,然后再請求2次單行數(shù)據(jù)即可獲得需要的數(shù)據(jù)。因此修改了部分PageSpider代碼,滿足該需求:
class?PageSpiderv2(PageSpider):
????"""
????繼承并修改PageSpider對象的部分功能
????"""
????def?make_params(self,?year:?int?=?None,?nrows:?int?=?None,?key:?list?=?None)?->?dict:
????????"""
????????制作請求體中的參數(shù)
????????:param?year:?修改Post參數(shù)中的年份
????????:param?nrows:?修改Post參數(shù)中的count
????????:param?key:?下一頁的關(guān)鍵字RestartTokens,默認(rèn)空,第一次請求時(shí)無需傳入該參數(shù)
????????:return:?dict
????????"""
????????params?=?self.params.copy()
????????if?key:
????????????params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction'][
????????????????'Primary']['Window']['RestartTokens']?=?key
????????if?year:
????????????self.params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Query']['Where'][0][
????????????????'Condition']['In']['Values'][0][0]['Literal']['Value']?=?f'{year}L'
????????if?nrows:
????????????self.params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction'][
????????????'Primary']['Window']['Count']?=?nrows
????????return?params
????def?crawl_page(self,?year:?int,?nrows:?int,?key:?list?=?None):
????????"""
????????按照傳入的參數(shù)單獨(dú)爬取數(shù)據(jù)
????????:param?year:?需要爬取的數(shù)據(jù)的年份
????????:param?nrows:?需要爬取的數(shù)據(jù)的count值
????????:param?key:?下一頁的關(guān)鍵字RestartTokens,默認(rèn)空,第一次請求時(shí)無需傳入該參數(shù)
????????:return:?None
????????"""
????????while?True:??#?創(chuàng)建死循環(huán),直至爬取的結(jié)果是200時(shí)返回response
????????????try:
????????????????res?=?requests.post(url=self.url,?headers=self.headers,?json=self.make_params(year,?nrows,?key),
????????????????????timeout=self.timeout)
????????????except?Exception?as?e:??#?其他異常,打印一下異常信息
????????????????print(f'{self.year}?Error:?{e}')
????????????????time.sleep(5)??#?休息5秒后再次請求
????????????????continue??#?跳過后續(xù)步驟
????????????if?res.status_code?==?200:
????????????????return?res
????????????else:
????????????????time.sleep(5)
def?write_data(data:?dict,?filename:?pl.Path):
????"""
????將爬取到的數(shù)據(jù)寫入TXT文件
????:param?data:?需要寫入的數(shù)據(jù)
????:param?filename:?輸出的文件名稱
????"""
????with?open(filename,?'w',?encoding='utf-8')?as?fin:
????????fin.write(json.dumps(data))
????return?data
#?定義并創(chuàng)建存儲爬取到的R和?組合關(guān)系的文件夾
relation_path?=?pl.Path('./tmp/relation')
if?not?relation_path.is_dir():
????relation_path.mkdir()
"""
遍歷不重復(fù)的R和?組合關(guān)系,逐一爬取數(shù)據(jù),
爬取數(shù)據(jù)的邏輯是:
1.進(jìn)行3次請求
2.第1次請求,根據(jù)index值取到R和?組合關(guān)系的上一行數(shù)據(jù)的RT值,
3.第2、3次請求,獲取R和?組合關(guān)系的上一行與當(dāng)前行,根據(jù)R和?組合關(guān)系創(chuàng)建文件夾,存儲文件
"""
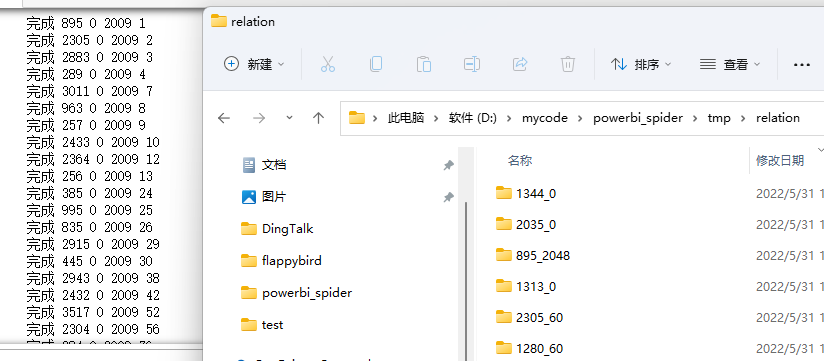
for?idx?in?data.index:
????r,?q,?year?=?data.loc[idx]??#?拆包獲取r,q,year數(shù)據(jù)
????#?定義并創(chuàng)建R和?組合關(guān)系文件夾,文件夾名以R和?組合關(guān)系命名
????out_path?=?relation_path?/?f'{r}_{q}'
????if?not?out_path.is_dir():
????????out_path.mkdir()
????#?第1次爬取,獲取定位的RT值
????req?=?PageSpiderv2(year)
????res?=?json.loads(req.crawl_page(year,?nrows=idx).text)
????key?=?res['results'][0]['result']['data']['dsr']['DS'][0].get('RT')
????#?第2、3次爬取,獲取2行數(shù)據(jù)用于比對,解析R和?組合關(guān)系
????for?n?in?range(2):
????????res?=?json.loads(req.crawl_page(year,?nrows=2,?key=key).text)
????????res?=?write_data(res,?out_path?/?f'{r}_{q}_{n}.txt')
????????key?=?res['results'][0]['result']['data']['dsr']['DS'][0].get('RT')
????print('完成',?r,?q,?year,?idx)
整理數(shù)據(jù)推導(dǎo)出R與?參數(shù)組合與列關(guān)系:
#??參數(shù)的空列數(shù)值字典
blank_col_dict?=?{
????????60:?['Manufacturer?Full?Name',?'Manufacturer?ID',?'City',?'State'],
????????128:?['Payment?Category'],
????????2048:?['Number?of?Events?Reflected']
????}
#?創(chuàng)建方案二的解析對象
obj2?=?ParseDatav2()
#?初始化定義relation_df,第一行為R和?組合為0值,所有列均為1
relation_df?=?pd.DataFrame(['R',?'?']?+?obj2.row.columns.tolist()[:-1])
relation_df[1]?=?1
relation_df.set_index(0,?inplace=True)
relation_df?=?relation_df.T
relation_df[['R',?'?']]?=?[0,?0]
relation_df

#?遍歷爬取到的R和?組合數(shù)據(jù)文件夾,解析R和?組合關(guān)系
for?r_dir?in?relation_path.iterdir():
????r_files?=?list(r_dir.iterdir())
????r,?q?=?r_dir.stem.split('_')
????res0?=?obj2.parse_data(r_files[0])
????res1?=?obj2.parse_data(r_files[1])
????#?兩行數(shù)據(jù)對比,當(dāng)不一致時(shí)是1,否則是0
????res?=?res0?!=?res1
????#?獲取?關(guān)系的空列
????blank_cols?=?blank_col_dict.get(int(q))
????#?如有空列數(shù)據(jù),則將對應(yīng)列值清除
????if?blank_cols:
????????res[blank_cols]?=?False
????res[['R',?'?']]?=?[r,?q]
????res?=?res[['R',?'?']?+?obj2.row.columns.tolist()]
????res?=?res.drop(columns='idx')
????relation_df?=?pd.concat([relation_df,?res])
#?整理組合關(guān)系dataframe
relation_df[['R',?'?']]?=?relation_df[['R',?'?']].astype(int)
relation_df.sort_values(by=['R',?'?'],?inplace=True)
relation_df.set_index(['R',?'?'],?inplace=True)
#?輸出關(guān)系字典
relation_df.to_csv('./cols_dict.csv',?encoding='utf-8')
relation_df
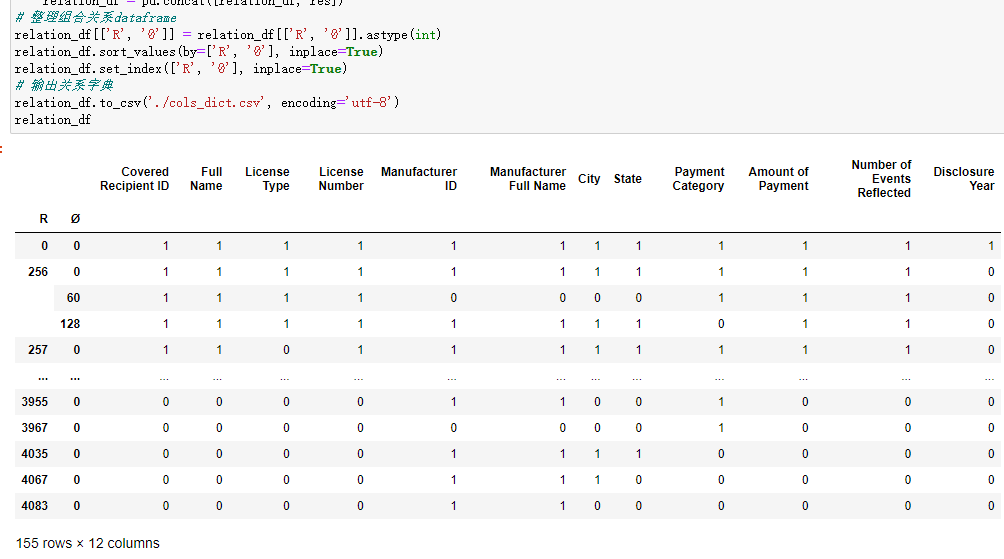
使用解析得到R和?的組合的關(guān)系,解析輸出CSV文件
該步驟因相比第一版增加了?關(guān)系,因此有對ParseData對象的方法進(jìn)行了部分修改,具體詳見代碼,運(yùn)行示例如下:

總結(jié)
本次流程優(yōu)化主要就是希望提高數(shù)據(jù)處理的效率,優(yōu)化后:
全量數(shù)據(jù)請求,用時(shí)僅秒級,可以忽略不計(jì); 在獲取R和?的組合關(guān)系上,使用單線程請求,用時(shí)8分多鐘:
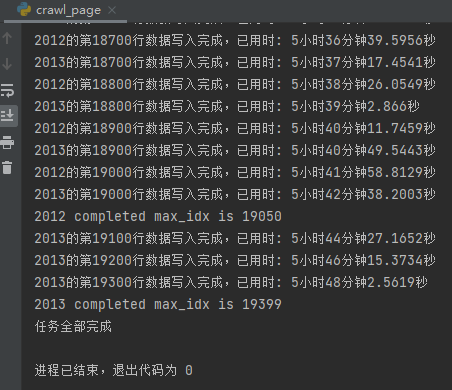
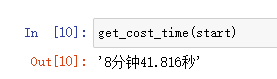 3. 解析輸出文件5分多種
3. 解析輸出文件5分多種
總用時(shí),在15分鐘以內(nèi),與方案二的時(shí)間近6個(gè)小時(shí)相比,效率提升極為明顯:
同時(shí)在本次流程優(yōu)化中并沒有使用到太多新的技術(shù),沒能JS逆向解析出關(guān)系規(guī)則,還是沒能解析,但是通過靈活使用參數(shù),組合不同方案優(yōu)勢,還是能夠極大的提升運(yùn)行效率。
回過頭來看,如果在接單的初期,在嘗試JS逆向失敗后,要是能夠直接想到這個(gè)解決方案,那么5個(gè)小時(shí)的人工查詢R關(guān)系時(shí)間,5個(gè)小時(shí)的單行爬蟲運(yùn)行時(shí)間,可以節(jié)約的時(shí)間大大的有啊!!!嗯,下次一定要提醒自己,要多打開思路,多嘗試不同的方向思考,不要一條道走到黑,也許換個(gè)方向就能取得突破。總而言之,方法總比困難多,還是多思考,多嘗試,多積累經(jīng)驗(yàn)吧!!!
掃碼下方,購買螞蟻老師課程
提供答疑服務(wù),和副業(yè)渠道
抖音每晚直播間購買,便宜100元優(yōu)惠!
