
基于DQN強化學習訓練一個超級瑪麗
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

Author:MyEncyclopedia
上一期 MyEncyclopedia文章 通過代碼學Sutton強化學習:從Q-Learning 演化到 DQN,我們從原理上講解了DQN算法,這一期,讓我們通過代碼來實現(xiàn)DQN 在任天堂經(jīng)典的超級瑪麗游戲中的自動通關吧。本系列將延續(xù)通過代碼學Sutton 強化學習系列,逐步通過代碼實現(xiàn)經(jīng)典深度強化學習應用在各種游戲環(huán)境中。本文所有代碼在?
https://github.com/MyEncyclopedia/reinforcement-learning-2nd/tree/master/super_mario
最終訓練第一關結果動畫
上期詳細講解了DQN中的兩個重要的技術:Target Network 和 Experience Replay,正是有了它們才使得 Deep Q Network在實戰(zhàn)中容易收斂,以下是Deepmind 發(fā)表在Nature 的 Human-level control through deep reinforcement learning 的完整算法流程。
 ? ?
? ?安裝基于OpenAI gym的超級瑪麗環(huán)境執(zhí)行下面的 pip 命令即可。
pip?install?gym-super-mario-bros
我們先來看一下游戲環(huán)境的輸入和輸出。下面代碼采用隨機的action來和游戲交互。有了 組合游戲系列3: 井字棋、五子棋的OpenAI Gym GUI環(huán)境?關于OpenAI Gym 的介紹,現(xiàn)在對于其基本的交互步驟已經(jīng)不陌生了。
import?gym_super_mario_bros
from?random?import?random,?randrange
from?gym_super_mario_bros.actions?import?RIGHT_ONLY
from?nes_py.wrappers?import?JoypadSpace
from?gym?import?wrappers
env?=?gym_super_mario_bros.make('SuperMarioBros-v0')
env?=?JoypadSpace(env,?RIGHT_ONLY)
#?Play?randomly
done?=?False
env.reset()
step?=?0
while?not?done:
????action?=?randrange(len(RIGHT_ONLY))
????state,?reward,?done,?info?=?env.step(action)
????print(done,?step,?info)
????env.render()
????step?+=?1
env.close()
隨機策略的效果如下
注意我們在游戲環(huán)境初始化的時候用了參數(shù) RIGHT_ONLY,它定義成五種動作的list,表示僅使用右鍵的一些組合,適用于快速訓練來完成Mario第一關。
RIGHT_ONLY?=?[
????['NOOP'],
????['right'],
????['right',?'A'],
????['right',?'B'],
????['right',?'A',?'B'],
]
觀察一些 info 輸出內(nèi)容,coins表示金幣獲得數(shù)量,flag_get 表示是否取得最后的旗子,time 剩余時間,以及 Mario 大小狀態(tài)和所在的 x,y位置。
{
???"coins":0,
???"flag_get":False,
???"life":2,
???"score":0,
???"stage":1,
???"status":"small",
???"time":381,
???"world":1,
???"x_pos":594,
???"y_pos":89
}Deep Reinforcement Learning 一般是 end-to-end learning,意味著將游戲的 screen image,即 observed state 直接視為真實狀態(tài) state,喂給神經(jīng)網(wǎng)絡去訓練。于此相反的另一種做法是,通過游戲環(huán)境拿到內(nèi)部狀態(tài),例如所有相關物品的位置和屬性作為模型輸入。這兩種方式的區(qū)別在我看來有兩點。第一點,用觀察到的屏幕像素代替真正的狀態(tài) state,在partially observable 的環(huán)境時可能因為 non-stationarity 導致無法很好的工作,而拿內(nèi)部狀態(tài)利用了額外的作弊信息,在partially observable環(huán)境中也可以工作。第二點,第一種方式屏幕像素維度比較高,輸入數(shù)據(jù)量大,需要神經(jīng)網(wǎng)絡的大量訓練擬合,第二種方式,內(nèi)部真實狀態(tài)往往維度低得多,訓練起來很快,但缺點是因為除了內(nèi)部狀態(tài)往往還需要游戲相關規(guī)則作為輸入,因此generalization能力不如前者強。
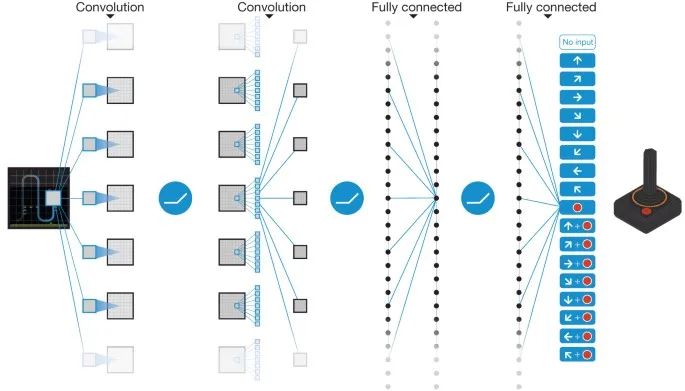 ?
?這里,我們當然采樣屏幕像素的 end-to-end 方式了,自然首要任務是將游戲幀圖像有效處理。超級瑪麗游戲環(huán)境的屏幕輸出是 (240, 256, 3) shape的 numpy array,通過下面一系列的轉換,盡可能的在不影響訓練效果的情況下減小采樣到的數(shù)據(jù)量。
MaxAndSkipFrameWrapper:每4個frame連在一起,采取同樣的動作,降低frame數(shù)量
FrameDownsampleWrapper:將原始的 (240, 256, 3) down sample 到 (84, 84, 1)
ImageToPyTorchWrapper:轉換成適合 pytorch 的 shape (1, 84, 84)?
FrameBufferWrapper:保存最后4次屏幕采樣
NormalizeFloats:Normalize 成 [0., 1.0] 的浮點值
def?wrap_environment(env_name:?str,?action_space:?list)?->?Wrapper:
????env?=?make(env_name)
????env?=?JoypadSpace(env,?action_space)
????env?=?MaxAndSkipFrameWrapper(env)
????env?=?FrameDownsampleWrapper(env)
????env?=?ImageToPyTorchWrapper(env)
????env?=?FrameBufferWrapper(env,?4)
????env?=?NormalizeFloats(env)
????return?env模型比較簡單,三個卷積層后做 softmax輸出,輸出維度數(shù)為離散動作數(shù)。act() 采用了epsilon-greedy 模式,即在epsilon小概率時采取隨機動作來 explore,大于epsilon時采取估計的最可能動作來 exploit。
class?DQNModel(nn.Module):
????def?__init__(self,?input_shape,?num_actions):
????????super(DQNModel,?self).__init__()
????????self._input_shape?=?input_shape
????????self._num_actions?=?num_actions
????????self.features?=?nn.Sequential(
????????????nn.Conv2d(input_shape[0],?32,?kernel_size=8,?stride=4),
????????????nn.ReLU(),
????????????nn.Conv2d(32,?64,?kernel_size=4,?stride=2),
????????????nn.ReLU(),
????????????nn.Conv2d(64,?64,?kernel_size=3,?stride=1),
????????????nn.ReLU()
????????)
????????self.fc?=?nn.Sequential(
????????????nn.Linear(self.feature_size,?512),
????????????nn.ReLU(),
????????????nn.Linear(512,?num_actions)
????????)
????def?forward(self,?x):
????????x?=?self.features(x).view(x.size()[0],?-1)
????????return?self.fc(x)
????def?act(self,?state,?epsilon,?device):
????????if?random()?>?epsilon:
????????????state?=?torch.FloatTensor(np.float32(state)).unsqueeze(0).to(device)
????????????q_value?=?self.forward(state)
????????????action?=?q_value.max(1)[1].item()
????????else:
????????????action?=?randrange(self._num_actions)
????????return?action實現(xiàn)采用了 Pytorch CartPole DQN 的官方代碼,本質(zhì)是一個最大為 capacity 的 list 保存了采樣到的 (s, a, r, s', is_done) ?五元組。
Transition?=?namedtuple('Transition',?('state',?'action',?'reward',?'next_state',?'done'))
class?ReplayMemory:
????def?__init__(self,?capacity):
????????self.capacity?=?capacity
????????self.memory?=?[]
????????self.position?=?0
????def?push(self,?*args):
????????if?len(self.memory)?????????????self.memory.append(None)
????????self.memory[self.position]?=?Transition(*args)
????????self.position?=?(self.position?+?1)?%?self.capacity
????def?sample(self,?batch_size):
????????return?random.sample(self.memory,?batch_size)
????def?__len__(self):
????????return?len(self.memory)我們將 DQN 的邏輯封裝在 DQNAgent 類中。DQNAgent 成員變量包括兩個 DQNModel,一個ReplayMemory。
train() 方法中會每隔一定時間將 Target Network 的參數(shù)同步成現(xiàn)行Network的參數(shù)。在td_loss_backprop()方法中采樣 ReplayMemory 中的五元組,通過minimize TD error方式來改進現(xiàn)行 Network 參數(shù) 。Loss函數(shù)為:
class?DQNAgent():
????def?act(self,?state,?episode_idx):
????????self.update_epsilon(episode_idx)
????????action?=?self.model.act(state,?self.epsilon,?self.device)
????????return?action
????def?process(self,?episode_idx,?state,?action,?reward,?next_state,?done):
????????self.replay_mem.push(state,?action,?reward,?next_state,?done)
????????self.train(episode_idx)
????def?train(self,?episode_idx):
????????if?len(self.replay_mem)?>?self.initial_learning:
????????????if?episode_idx?%?self.target_update_frequency?==?0:
????????????????self.target_model.load_state_dict(self.model.state_dict())
????????????self.optimizer.zero_grad()
????????????self.td_loss_backprop()
????????????self.optimizer.step()
????def?td_loss_backprop(self):
????????transitions?=?self.replay_mem.sample(self.batch_size)
????????batch?=?Transition(*zip(*transitions))
????????state?=?Variable(FloatTensor(np.float32(batch.state))).to(self.device)
????????action?=?Variable(LongTensor(batch.action)).to(self.device)
????????reward?=?Variable(FloatTensor(batch.reward)).to(self.device)
????????next_state?=?Variable(FloatTensor(np.float32(batch.next_state))).to(self.device)
????????done?=?Variable(FloatTensor(batch.done)).to(self.device)
????????q_values?=?self.model(state)
????????next_q_values?=?self.target_net(next_state)
????????q_value?=?q_values.gather(1,?action.unsqueeze(-1)).squeeze(-1)
????????next_q_value?=?next_q_values.max(1)[0]
????????expected_q_value?=?reward?+?self.gamma?*?next_q_value?*?(1?-?done)
????????loss?=?(q_value?-?expected_q_value.detach()).pow(2)
????????loss?=?loss.mean()
????????loss.backward()最后是外層調(diào)用代碼,基本和以前文章一樣。
def?train(env,?args,?agent):
????for?episode_idx?in?range(args.num_episodes):
????????episode_reward?=?0.0
????????state?=?env.reset()
????????while?True:
????????????action?=?agent.act(state,?episode_idx)
????????????if?args.render:
????????????????env.render()
????????????next_state,?reward,?done,?stats?=?env.step(action)
????????????agent.process(episode_idx,?state,?action,?reward,?next_state,?done)
????????????state?=?next_state
????????????episode_reward?+=?reward
????????????if?done:
????????????????print(f'{episode_idx}:?{episode_reward}')
????????????????break
好消息,小白學視覺團隊的知識星球開通啦,為了感謝大家的支持與厚愛,團隊決定將價值149元的知識星球現(xiàn)時免費加入。各位小伙伴們要抓住機會哦!

交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~