
【強化學(xué)習】DQN 的三種改進在運籌學(xué)中的應(yīng)用
這篇文章主要介紹 DQN 的三種改進:Nature DQN、Double DQN、Dueling DQN 在運籌學(xué)中的應(yīng)用,并給出三者的對比,同時也會給出不同增量學(xué)習下的效果。
這三種具體的改進方式可以從之前的文章中學(xué)習 《【強化學(xué)習】DQN 的各種改進》
背景
(搬運下背景)
假設(shè)有一個客服排班的任務(wù),我們需要為 100 個人安排一個星期的排班問題,并且有以下約束條件:
一天被劃分為 24 個時間段,即每個時間段為 1 個小時; 每個客服一個星期需要上七天班,每次上班八小時; 每個客服兩次上班時間需要間隔 12 小時; 客服值班時,一個星期最早是 0,最晚 24*7 - 1。
評判標準:
現(xiàn)在有每個時間段所需客服人數(shù),我們希望每個時段排班后的人數(shù)與實際人數(shù)盡量相近。
最優(yōu)化問題可以使用啟發(fā)式算法來做,上次用 DQN,這次用深度強化學(xué)習。
Nature DQN
之前給過 DQN 的代碼,但是由于沒有用批處理,所以速度非常慢,這里為了方便大家查看,給出完整版的 Nature DQN 代碼,但是 Double DQN 和 Dueling DQN 的代碼只會放上在前者需要修改的部分。
所以,Double DQN 的改進會加上 Nature DQN 的改進的部分,同理 Dueling DQN 實際上是 Nature DQN、Double DQN、Dueling DQN 三者的縫合怪。
import?random
import?numpy?as?np
import?tensorflow?as?tf
from?tensorflow.keras?import?layers
from?copy?import?deepcopy
from?collections?import?defaultdict,?deque
random.seed(2020)
gpus?=?tf.config.experimental.list_physical_devices(device_type='GPU')
#?GPU?隨使用量增長
tf.config.experimental.set_memory_growth(gpus[0],?True)
#?設(shè)定最大顯存
tf.config.experimental.set_virtual_device_configuration(
????gpus[0],
????[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=1024*16)]
)
person_n?=?10
#?隨機的一個排班需求
act_list?=?[5,?8,?8,?8,?5,?7,?9,?7,?5,?9,?7,?10,?10,?10,?7,?5,?10,?6,?7,?10,?7,?
????????????5,?6,?6,?10,?5,?9,?8,?8,?9,?9,?7,?6,?9,?7,?5,?9,?8,?7,?9,?10,?6,?7,?
????????????6,?6,?5,?8,?8,?9,?7,?8,?9,?8,?7,?7,?8,?9,?8,?7,?8,?9,?7,?10,?7,?5,?
????????????10,?10,?10,?7,?5,?6,?5,?9,?7,?5,?8,?7,?5,?5,?5,?7,?9,?9,?7,?9,?6,?9,?
????????????9,?9,?8,?9,?10,?5,?6,?6,?8,?7,?6,?5,?5,?9,?6,?7,?8,?6,?8,?9,?8,?5,?
????????????5,?8,?8,?6,?7,?9,?9,?10,?7,?8,?6,?6,?9,?6,?5,?6,?7,?5,?5,?8,?6,?5,?
????????????10,?10,?8,?10,?10,?6,?9,?8,?6,?5,?8,?6,?9,?8,?9,?6,?7,?6,?5,?9,?7,?
????????????7,?9,?6,?10,?7,?9,?5,?9,?9,?8,?7,?9,?9,?8,?8,?5]
class?Env():
????def?__init__(self):
????????#?10?個人,?7?天,每個?bar?都可以向左向右移動,也可以不移動?'-1'
????????self.actions_space?=?['{}{}L'.format(i,?j)?for?i?in?range(person_n)?for?j?in?range(7)]?+?\
????????????????????????????????????['{}{}R'.format(i,?j)?for?i?in?range(person_n)?for?j?in?range(7)]?+?['-1']
????????self.n_actions?=?len(self.actions_space)
????????self.act_list?=?act_list
????????self.w_list?=?[i?/?sum(self.act_list)?for?i?in?self.act_list]
????????self.state?=?[[i*24?for?i?in?range(7)]?for?i?in?range(person_n)]
????????self.n_state?=?person_n?*?7?*?24
????????self.punish?=?-1
????????print(self.act_list)
????
????def?list_2_str(self,?l):
????????#?拼接完整的?list
????????state_list?=?[[0?for?i?in?range(24*7)]?for?j?in?range(person_n)]
????????for?person?in?range(person_n):
????????????for?i?in?l[person]:
????????????????for?j?in?range(8):
????????????????????state_list[person][i+j]?=?1
????????return?[i?for?state?in?state_list?for?i?in?state]
????
????def?reset(self):
????????self.state?=?[[i*24?for?i?in?range(7)]?for?i?in?range(person_n)]
????????return?self.list_2_str(self.state)
????
????#?給當前排班打分,考慮權(quán)重
????def?reward(self,?tmp_state):
????????#?判斷每個人的排班要間隔?8+12?小時,否則?socre?=?-1000
????????for?i?in?range(person_n):
????????????#?星期天和星期一的排班間隔?8+12?小時
????????????if?(tmp_state[i][0]?+?(24*7-1)?-?tmp_state[i][6])?20:
????????????????return?self.punish
????????????for?j?in?range(6):
????????????????if?(tmp_state[i][j+1]?-?tmp_state[i][j])?20:
????????????????????return?self.punish
????????#?拼接完整的?list
????????state_list?=?[[0]?*?24?*?7]?*?person_n
????????for?person?in?range(person_n):
????????????for?i?in?tmp_state[person]:
????????????????for?j?in?range(8):
????????????????????state_list[person][i+j]?=?1
????????plan_list?=?np.sum(state_list,?axis=0).tolist()
????????s_list?=?[abs(plan_list[i]?-?self.act_list[i])/self.act_list[i]?for?i?in?range(len(plan_list))]
????????#?獎勵越大越好,所以加個負號
????????score?=?1-np.sum([s_list[i]*self.w_list[i]?for?i?in?range(len(s_list))])
????????return?score
????
????def?step(self,?action):
????????actions_str?=?self.actions_space[action]
????????if?actions_str?==?'-1':
????????????return?self.list_2_str(self.state),?self.reward(self.state)
????????else:
????????????num?=?int(actions_str[0])
????????????day?=?int(actions_str[1])
????????????move?=?actions_str[2]
????????????tmp_state?=?deepcopy(self.state)
????????????if?move?==?'R':
????????????????if?tmp_state[num][day]?==?(24*7-8-1):
????????????????????tmp_state[num][day]?=?tmp_state[num][day]?+?1
????????????????????return?self.list_2_str(tmp_state),?self.punish
????????????????tmp_state[num][day]?=?tmp_state[num][day]?+?1
????????????if?move?==?'L':
????????????????if?tmp_state[num][day]?==?0:
????????????????????tmp_state[num][day]?=?tmp_state[num][day]?-?1
????????????????????return?self.list_2_str(tmp_state),?self.punish
????????????????tmp_state[num][day]?=?tmp_state[num][day]?-?1
????????????reward?=?self.reward(tmp_state)
????????????if?reward?==?self.punish:
????????????????return?self.list_2_str(tmp_state),?self.punish
????????????self.state?=?tmp_state
????????????return?self.list_2_str(self.state),?self.reward(self.state)
class?DQNAgent:
????def?__init__(self,?state_size,?action_size):
????????self.state_size?=?state_size
????????self.action_size?=?action_size
????????self.memory?=?deque(maxlen=2000)
????????self.discount_factor?=?0.9
????????self.epsilon?=?1.0??#?exploration?rate
????????self.epsilon_min?=?0.1
????????self.epsilon_decay?=?0.999
????????self.learning_rate?=?0.01
????????#?Nature?DQN?就是創(chuàng)建了兩個?DQN,防止又踢球又當裁判
????????self.model?=?self._build_model()??#?用于選擇動作、更新參數(shù)
????????self.model_Q?=?self._build_model()??#?用于計算 Q 值,定期從 model 中拷貝數(shù)據(jù)。
????
????def?_build_model(self):
????????model?=?tf.keras.Sequential()
????????model.add(layers.Dense((512),?input_shape=(self.state_size,?),?activation='relu'))
????????model.add(layers.BatchNormalization())
????????model.add(layers.Dense((512),?activation='relu'))
????????model.add(layers.BatchNormalization())
????????model.add(layers.Dense((256),?activation='relu'))
????????model.add(layers.BatchNormalization())
????????model.add(layers.Dense((self.action_size),?activation='sigmoid'))
????????model.compile(loss='mse',?optimizer=tf.keras.optimizers.Adam(lr=self.learning_rate))
????????return?model
????
????def?update_model_Q(self):
????????self.model_Q.set_weights(self.model.get_weights())
????
????def?memorize(self,?state,?action,?reward,?next_state):
????????self.memory.append((state,?action,?reward,?next_state))
????
????def?get_action(self,?state):
????????if?np.random.rand()?<=?self.epsilon:
????????????return?random.randrange(self.action_size)
????????act_values?=?self.model.predict(state)
????????act_values?=?act_values[0]
????????max_action?=?np.random.choice(np.where(act_values?==?np.max(act_values))[0])
????????return?max_action??#?returns?action
????
????def?replay(self,?batch_size):
????????minibatch?=?random.sample(self.memory,?batch_size)
????????state_batch?=?[data[0]?for?data?in?minibatch]
????????action_batch?=?[data[1]?for?data?in?minibatch]
????????reward_batch?=?[data[2]?for?data?in?minibatch]
????????next_state_batch?=?[data[3]?for?data?in?minibatch]
????????
????????next_state_batch?=?np.array(next_state_batch)
????????next_state_batch?=?next_state_batch.reshape(batch_size,?self.state_size)
????????next_state_Q_batch?=?self.model_Q.predict(next_state_batch)
????????
????????state_batch?=?np.array(state_batch)
????????state_batch?=?state_batch.reshape(batch_size,?self.state_size)
????????state_Q_batch?=?self.model_Q.predict(state_batch)
????????
????????y_batch?=?[]
????????for?i?in?range(batch_size):
????????????target?=?reward_batch[i]?+?self.discount_factor?*?np.amax(next_state_Q_batch[i])?
????????????target_f?=?state_Q_batch[i]
????????????target_f[action]?=?target
????????????y_batch.append(target_f)
????????
????????y_batch?=?np.array(y_batch)
????????y_batch?=?y_batch.reshape(batch_size,?self.action_size)
????????self.model.fit(state_batch,?y_batch,?epochs=5,?verbose=0)
????????if?self.epsilon?>?self.epsilon_min:
????????????self.epsilon?*=?self.epsilon_decay
????def?load(self,?name):
????????self.model.load_weights(name)
????def?save(self,?name):
????????self.model.save_weights(name)
env?=?Env()
bst_state?=?env.state
agent?=?DQNAgent(env.n_state,?env.n_actions)
episodes?=?1
update_model_Q_freq?=?50
batch_size?=?32
bst_reward?=?-500
for?e?in?range(episodes):
????state?=?env.reset()
????print('----------?',?e,?'?------------')
????for?i?in?range(20000):
????????state?=?np.reshape(state,?[1,?env.n_state])
????????action?=?agent.get_action(state)
????????next_state,?reward?=?env.step(action)
????????next_state?=?np.reshape(next_state,?[1,?env.n_state])
????????if?i?%?update_model_Q_freq?==?0:
????????????agent.update_model_Q()
????????if?reward?!=?env.punish:
????????????state?=?deepcopy(next_state)
????????????agent.memorize(state,?action,?reward,?next_state)
????????if?len(agent.memory)?>?batch_size:
????????????agent.replay(batch_size)
????????if?bst_reward?????????????bst_reward?=?reward
????????????bst_state?=?deepcopy(env.state)
????????????print('episode:?{}/{},?i:{},?reward:?{},?e:?{:.2}'.format(e,?episodes,?i,?bst_reward,?agent.epsilon))
Double DQN
Double DQN 使用當前 Q 網(wǎng)絡(luò)計算每一個 action 對應(yīng)的 q 值,然后記錄最大 q 值對應(yīng)的 max action,然后用目標網(wǎng)絡(luò)和 max action 計算目標 q 值。
em... 這塊看公式比較清楚。
class?DQNAgent:
????...?...
?def?replay(self,?batch_size):
????????minibatch?=?random.sample(self.memory,?batch_size)
????????state_batch?=?[data[0]?for?data?in?minibatch]
????????action_batch?=?[data[1]?for?data?in?minibatch]
????????reward_batch?=?[data[2]?for?data?in?minibatch]
????????next_state_batch?=?[data[3]?for?data?in?minibatch]
????????
????????#?修改了這里
????????next_state_batch?=?np.array(next_state_batch).reshape(batch_size,?self.state_size)
????????cur_state_Q_batch?=?self.model.predict(next_state_batch)
????????max_action_next?=?np.argmax(cur_state_Q_batch,?axis=1)
????????
????????next_state_Q_batch?=?self.model_Q.predict(next_state_batch)
????????
????????state_batch?=?np.array(state_batch).reshape(batch_size,?self.state_size)
????????state_Q_batch?=?self.model_Q.predict(state_batch)
????????
????????y_batch?=?[]
????????for?i?in?range(batch_size):
????????????target?=?reward_batch[i]?+?self.discount_factor?*?next_state_Q_batch[i,?max_action_next[i]]
????????????target_f?=?state_Q_batch[i]
????????????target_f[action]?=?target
????????????y_batch.append(target_f)
????????
????????y_batch?=?np.array(y_batch)
????????y_batch?=?y_batch.reshape(batch_size,?self.action_size)
????????self.model.fit(state_batch,?y_batch,?epochs=5,?verbose=0)
????????if?self.epsilon?>?self.epsilon_min:
????????????self.epsilon?*=?self.epsilon_decay
Dueling DQN
Dueling Network:將 Q 網(wǎng)絡(luò)分成兩個通道,一個輸出 V,一個輸出 A,最后再合起來得到 Q。
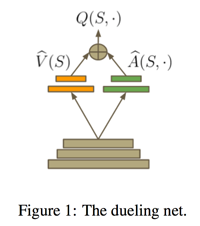
class?DQNAgent:
?...
??
?def?_build_model(self):
????????inputs?=?tf.keras.Input(shape=(self.state_size,?))
????????x?=?layers.Dense(512,?activation='relu')(inputs)
????????x?=?layers.BatchNormalization()(x)
????????x?=?layers.Dense(512,?activation='relu')(x)
????????x?=?layers.BatchNormalization()(x)
????????x?=?layers.Dense(256,?activation='relu')(x)
????????x?=?layers.BatchNormalization()(x)
????????v?=?layers.Dense(1,?activation='sigmoid')(x)
????????a?=?layers.Dense(self.action_size,?activation='sigmoid')(x)
????????a?=?a?-?tf.reduce_mean(a)
????????outputs?=?a?+?v
????????model?=?tf.keras.Model(inputs=inputs,?outputs=outputs)
????????model.compile(loss='mse',?optimizer=tf.keras.optimizers.Adam(lr=self.learning_rate))
????????return?model;
三者對比
放一下三者的對比:
| DQN | Nature DQN | Double DQN | Dueling Net | |
|---|---|---|---|---|
| 訓(xùn)練時長 | 32 | 31 min | 36 min | 38 min |
| 最好結(jié)果 | 0.6394 | 0.6538 | 0.6538 | 0.6538 |
| 收斂情況 | 9k 輪達到 0.6538 | 4.5k 輪達到 0.6538 | 8.5k 次達到 0.652; 1.3k 次達到 0.6538 |
PS:只實驗了一次,結(jié)果僅供參考。
往期精彩回顧
本站知識星球“黃博的機器學(xué)習圈子”(92416895)
本站qq群704220115。
加入微信群請掃碼: