
(附論文)干貨 | 多級特征重復(fù)使用大幅度提升檢測精度
點(diǎn)擊左上方藍(lán)字關(guān)注我們


鏈接:https://link.springer.com/article/10.1007/s00371-019-01787-3
近年來,在利用深度卷積網(wǎng)絡(luò)檢測目標(biāo)方面取得了顯著進(jìn)展。然而,很少有目標(biāo)檢測器實(shí)現(xiàn)高精度和低計算成本。今天分享的干貨,就有研究者提出了一種新的輕量級框架,即多級特性重用檢測器(MFRDet),它可以比兩階段的方法達(dá)到更好的精度。它還可以保持單階段方法的高效率,而且不使用非常深的卷積神經(jīng)網(wǎng)絡(luò)。該框架適用于深度和淺層特征圖中包含的信息的重復(fù)利用,具有較高的檢測精度。
二、背景

(a)僅使用單尺度特征進(jìn)行預(yù)測,(b)整合來自高級和低級特征圖的信息,(c)從不同尺度的特征圖生成預(yù)測,(d)就是今天分享的多層特征重用模塊可以獲得不同尺度的特征圖。
Shot learning
在深度學(xué)習(xí)領(lǐng)域,特別是目標(biāo)檢測領(lǐng)域,數(shù)據(jù)集的建設(shè)是至關(guān)重要的。進(jìn)行了許多優(yōu)秀和有價值的研究,改進(jìn)了多元數(shù)據(jù)集的理論和實(shí)踐。有研究者創(chuàng)建了一種有效的從Web學(xué)習(xí)方法來解決問題的數(shù)據(jù)集偏差,沒有手動注釋。這可能提供了一種幫助zero-shot學(xué)習(xí)的方法。zero-shot學(xué)習(xí)研究的主要問題是目標(biāo)分類問題和目標(biāo)檢測問題。目前,在zero-shot學(xué)習(xí)中仍存在一些需要解決的問題,如domain shift problem, hubness problem和semantic gap問題。zero-shot學(xué)習(xí)通常將視覺特征嵌入其他模態(tài)空間,或?qū)⒍鄠€模型空間映射到一個共同的潛在空間,使用最近鄰思想對看不見目標(biāo)進(jìn)行分類,這對目標(biāo)檢測器有很高的需求。
One-shot學(xué)習(xí)的目的是從一個或只有少數(shù)的訓(xùn)練圖像中學(xué)習(xí)有關(guān)目標(biāo)類別的信息。與zero-shot學(xué)習(xí)不同,One-shot學(xué)習(xí)依賴于先驗(yàn)知識,比如物體識別,它需要對形狀和外觀的先驗(yàn)知識。
三、新框架
SSD分析

SSD和Yolo一樣都是采用一個CNN網(wǎng)絡(luò)來進(jìn)行檢測,但是卻采用了多尺度的特征圖,其基本架構(gòu)如下圖所示。下面將SSD核心設(shè)計理念總結(jié)為以下三點(diǎn):

(1)采用多尺度特征圖用于檢測
所謂多尺度采用大小不同的特征圖,CNN網(wǎng)絡(luò)一般前面的特征圖比較大,后面會逐漸采用stride=2的卷積或者pool來降低特征圖大小,這正如上圖所示,一個比較大的特征圖和一個比較小的特征圖,它們都用來做檢測。這樣做的好處是比較大的特征圖來用來檢測相對較小的目標(biāo),而小的特征圖負(fù)責(zé)檢測大目標(biāo),如下圖所示,8x8的特征圖可以劃分更多的單元,但是其每個單元的先驗(yàn)框尺度比較小。

(2)采用卷積進(jìn)行檢測
與Yolo最后采用全連接層不同,SSD直接采用卷積對不同的特征圖來進(jìn)行提取檢測結(jié)果。對于形狀為  的特征圖,只需要采用
的特征圖,只需要采用  這樣比較小的卷積核得到檢測值。
這樣比較小的卷積核得到檢測值。
(3)設(shè)置先驗(yàn)框
在Yolo中,每個單元預(yù)測多個邊界框,但是其都是相對這個單元本身(正方塊),但是真實(shí)目標(biāo)的形狀是多變的,Yolo需要在訓(xùn)練過程中自適應(yīng)目標(biāo)的形狀。而SSD借鑒了Faster R-CNN中anchor的理念,每個單元設(shè)置尺度或者長寬比不同的先驗(yàn)框,預(yù)測的邊界框(bounding boxes)是以這些先驗(yàn)框?yàn)榛鶞?zhǔn)的,在一定程度上減少訓(xùn)練難度。一般情況下,每個單元會設(shè)置多個先驗(yàn)框,其尺度和長寬比存在差異,如圖5所示,可以看到每個單元使用了4個不同的先驗(yàn)框,圖片中貓和狗分別采用最適合它們形狀的先驗(yàn)框來進(jìn)行訓(xùn)練,后面會詳細(xì)講解訓(xùn)練過程中的先驗(yàn)框匹配原則。

 個類別,SSD其實(shí)需要預(yù)測
個類別,SSD其實(shí)需要預(yù)測  個置信度值,其中第一個置信度指的是不含目標(biāo)或者屬于背景的評分。后面當(dāng)我們說 個類別置信度時,請記住里面包含背景那個特殊的類別,即真實(shí)的檢測類別只有
個置信度值,其中第一個置信度指的是不含目標(biāo)或者屬于背景的評分。后面當(dāng)我們說 個類別置信度時,請記住里面包含背景那個特殊的類別,即真實(shí)的檢測類別只有  個。在預(yù)測過程中,置信度最高的那個類別就是邊界框所屬的類別,特別地,當(dāng)?shù)谝粋€置信度值最高時,表示邊界框中并不包含目標(biāo)。第二部分就是邊界框的location,包含4個值
個。在預(yù)測過程中,置信度最高的那個類別就是邊界框所屬的類別,特別地,當(dāng)?shù)谝粋€置信度值最高時,表示邊界框中并不包含目標(biāo)。第二部分就是邊界框的location,包含4個值  ,分別表示邊界框的中心坐標(biāo)以及寬高。但是真實(shí)預(yù)測值其實(shí)只是邊界框相對于先驗(yàn)框的轉(zhuǎn)換值(paper里面說是offset,但是覺得transformation更合適,參見R-CNN)。先驗(yàn)框位置用
,分別表示邊界框的中心坐標(biāo)以及寬高。但是真實(shí)預(yù)測值其實(shí)只是邊界框相對于先驗(yàn)框的轉(zhuǎn)換值(paper里面說是offset,但是覺得transformation更合適,參見R-CNN)。先驗(yàn)框位置用  表示,其對應(yīng)邊界框用
表示,其對應(yīng)邊界框用  $表示,那么邊界框的預(yù)測值
$表示,那么邊界框的預(yù)測值  其實(shí)是
其實(shí)是  相對于
相對于  的轉(zhuǎn)換值:
的轉(zhuǎn)換值:

中得到邊界框的真實(shí)位置 :
 的4個值進(jìn)行放縮,此時邊界框需要這樣解碼:
的4個值進(jìn)行放縮,此時邊界框需要這樣解碼:

 的特征圖,共有
的特征圖,共有  個單元,每個單元設(shè)置的先驗(yàn)框數(shù)目記為
個單元,每個單元設(shè)置的先驗(yàn)框數(shù)目記為  ,那么每個單元共需要
,那么每個單元共需要  個預(yù)測值,所有的單元共需要
個預(yù)測值,所有的單元共需要  個預(yù)測值,由于SSD采用卷積做檢測,所以就需要 個卷積核完成這個特征圖的檢測過程。
個預(yù)測值,由于SSD采用卷積做檢測,所以就需要 個卷積核完成這個特征圖的檢測過程。新框架(MFRDet)

如上面所述,有許多利用嘗試觀察和充分利用金字塔特征。圖(b)顯示了最常見的模式之一。這種類型經(jīng)過了歷史驗(yàn)證,大大提高了傳統(tǒng)檢測器的性能。但是這種設(shè)計需要多個特征合并過程,從而導(dǎo)致大量額外的計算。
今天分享的框架提出了一種輕量級、高效的多級特征重用(MFR)模塊(如圖(d)所示)。該模塊能夠充分利用不同尺度的特征圖,集成了深、淺層的特征,提高了檢測性能。特征重用模塊可簡要說明如下:
S的選擇:
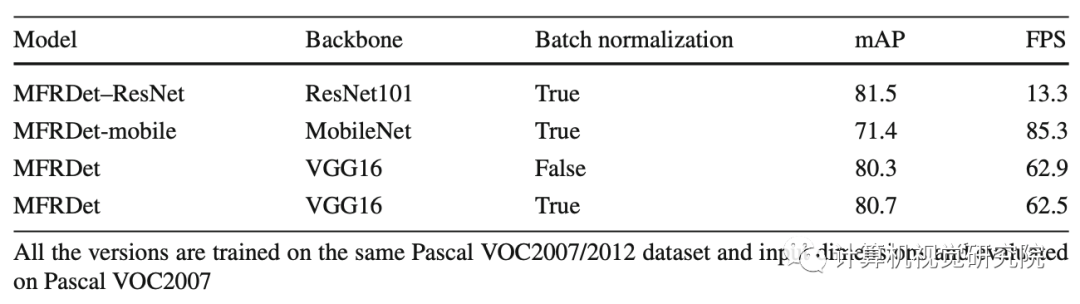
在初步設(shè)計它們時,需要考慮以下幾個關(guān)鍵因素。首先,應(yīng)該選擇要重用的圖層。在傳統(tǒng)的SSD中,作者部署了conv4_3、fc7和另外四個SSD層進(jìn)行預(yù)測。6個選定的特征地圖的比例表包括38×38、19×19、10×10、5×5和1×1。在不同的SSD中,這些層是獨(dú)立的,今天這個研究者不同意。研究者相信,小尺度特征圖中存在的語義信息在尺度變換后的檢測中仍然有效。選擇了六個預(yù)測層和conv5_3層作為框架要重用的源層。從下表中,可以得出一個明確的結(jié)論,即重用conv3_3將降低檢測精度。高分辨率特征圖沒有足夠的高級語義信息,因此放棄了對其信息的重用。

Ti的轉(zhuǎn)換策略:
在傳統(tǒng)的SSD中,規(guī)模為38×38、語義信息很少的淺層conv4_3負(fù)責(zé)小目標(biāo)識別。conv4_3層被設(shè)置為需要包含更深層語義信息的基本層。策略因特征圖的標(biāo)準(zhǔn)而不同。首先,對每個源層應(yīng)用Conv1×1來減小特征尺寸。然后,在Conv1×1層后,通過雙線性插值,將尺度小于38×38的層(四個SSD_layers和fc7層)放入相同大小的38×38中。這樣,所有的源特性都會轉(zhuǎn)換為相同的大小。
Ψt的選擇:
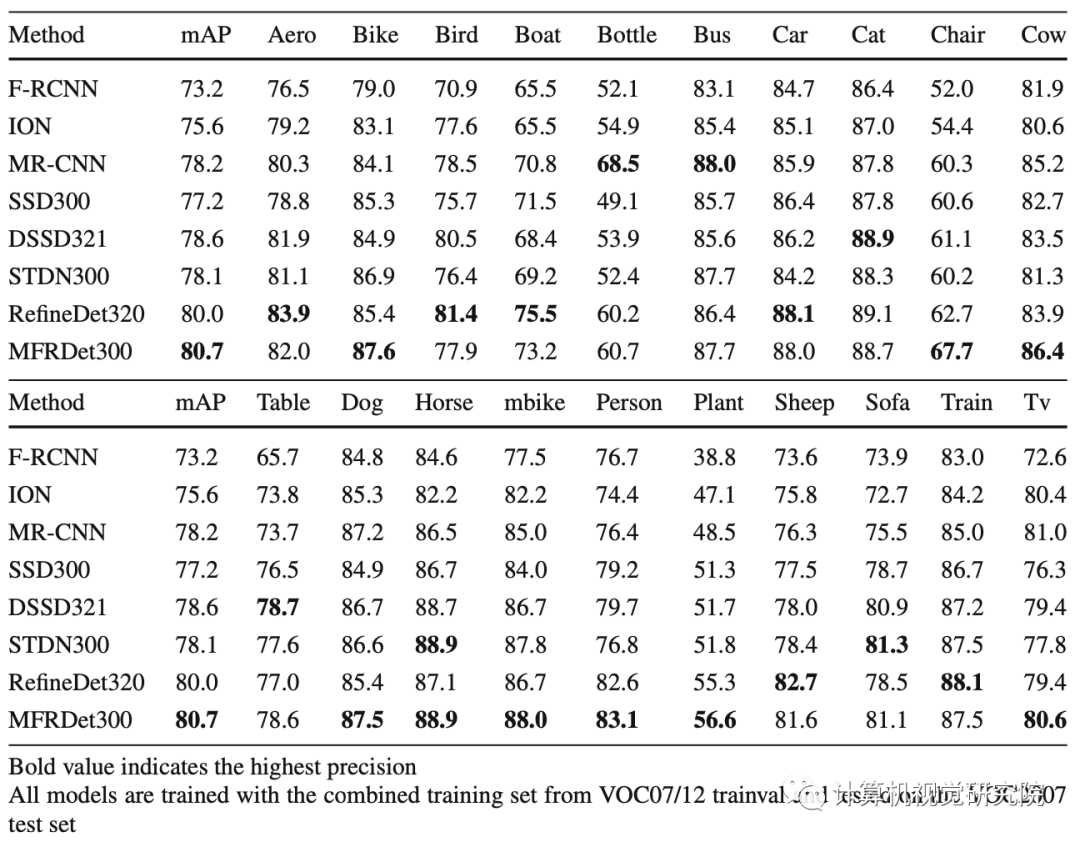
在轉(zhuǎn)換策略Ti的過程完成后,創(chuàng)建了新的變換特征圖。它們是conv4_3、conv5_3、fc7、conv8_2、conv9_2、conv10_2和conv11_2。有兩種方法可以將新轉(zhuǎn)換的特征映射合并在一起。通過實(shí)驗(yàn)驗(yàn)證,這兩種方法都能得到良好的結(jié)果。從上表中,可以了解到連接似乎更適合我們的模型。
四、實(shí)驗(yàn)


在coco數(shù)據(jù)集上的檢測可視化結(jié)果

END
整理不易,點(diǎn)贊三連↓