
基于深度學(xué)習(xí)的單幅圖像三維物體重建綜述
點擊下方卡片,關(guān)注“新機器視覺”公眾號
重磅干貨,第一時間送達
本文來自開始學(xué)AI
摘要:從單幅圖像中重建三維目標(biāo)是計算機視覺領(lǐng)域的一個重要課題。近年來,利用深度學(xué)習(xí)技術(shù)對單幅圖像進行三維重建取得了顯著的成果。傳統(tǒng)的從單幅圖像重建三維物體的方法需要先驗知識和假設(shè),而且重建的物體被限制在一定的范疇內(nèi)或很難從一幅真實的圖像中完成良好的重建。雖然深度學(xué)習(xí)憑借自身強大的學(xué)習(xí)能力可以很好地解決這些問題,但它也面臨著很多問題。在本文中,我們首先討論了應(yīng)用深度學(xué)習(xí)方法從單一圖像重建三維對象所面臨的挑戰(zhàn)。其次,我們?nèi)婊仡櫫擞糜趩蝹€圖像三維重建的編碼器、解碼器和訓(xùn)練細節(jié)。然后,介紹了近年來單幅圖像三維目標(biāo)重建的常用數(shù)據(jù)集和評價指標(biāo)。為了分析不同的三維重建方法的優(yōu)缺點,我們使用了一系列的實驗進行比較。此外,我們簡單地給出了一些有關(guān)單幅圖像三維重建的應(yīng)用實例。最后,對本文進行了總結(jié),并對未來的研究方向進行了展望。
關(guān)鍵詞:單幅圖像三維重建;深度學(xué)習(xí),計算機視覺,三維形狀表示
1 引言
圖像的三維重建是計算機視覺、醫(yī)學(xué)圖像處理[74,4]和虛擬現(xiàn)實[109]中的一個常見課題。計算機視覺相關(guān)理論和技術(shù)的主要目的是從圖像或多維數(shù)據(jù)中獲取信息,建立人工智能系統(tǒng)。圖像的三維重建是計算機視覺的主要任務(wù)之一,其目的是研究單幅圖像或多幅圖像生成相應(yīng)的三維結(jié)構(gòu)[93,82]。根據(jù)重建目標(biāo)的不同,圖像的三維重建可分為三維場景重建和三維物體重建。單視圖三維場景重建的一大挑戰(zhàn)是從單幅圖像中預(yù)測不可見的部分[38,108,100]。多視點三維場景重建[36,39]和多視點三維物體重建[18]可以整合多幅圖像的信息,彌補單幅圖像預(yù)測不確定性對不可見部分的缺陷。與傳統(tǒng)的多視圖三維重建方法[25,95]和模型[14,45]相比,深度學(xué)習(xí)具有處理大數(shù)據(jù)的能力。因此,近年來有很多將傳統(tǒng)方法與深度學(xué)習(xí)相結(jié)合的研究[114,149,27]。
一些研究回顧了圖像三維重建技術(shù)[32,143]。Ham等人[32]回顧了單幅靜止圖像的三維重建、RGB深度圖像、二維圖像的多視角和視頻序列的方法。Ham等人回顧的方法大多使用傳統(tǒng)的三維重建算法,少數(shù)方法使用深度學(xué)習(xí)技術(shù)。Yuniarti等[143]簡要回顧了基于深度學(xué)習(xí)的單幅或多幅圖像三維重建方法。這篇綜述不同于Ham等人或Yuniaart等人的綜述。我們對基于深度學(xué)習(xí)的單幅圖像三維重建方法進行了較為全面的回顧,包括該方法面臨的挑戰(zhàn)、不同三維表示的重建算法、三維重建訓(xùn)練體系等。本文的主要研究目標(biāo)是從單幅圖像中重建三維物體。單幅圖像的三維物體重建問題類似于單幅視圖的三維場景重建問題。由于單幅圖像丟失了大量的三維對象信息,重建結(jié)果具有不確定性。傳統(tǒng)的對單幅圖像進行三維物體重建的方法通常是基于已有模型[5,52],或者使用二維標(biāo)注[49]。這些方法通常局限于某一類物體的重建。例如,假設(shè)照明是固定的,形狀由陰影恢復(fù)[92,20,2]。假設(shè)表面平滑,由紋理恢復(fù)形狀[68]。由于實際數(shù)據(jù)集的復(fù)雜性,這類需要假設(shè)的模型在實際應(yīng)用中效果較差。
近年來,隨著深度學(xué)習(xí)的不斷興起,利用深度神經(jīng)網(wǎng)絡(luò)從單一的二維圖像中重建三維物體成為一個熱門方向[147]。基于深度學(xué)習(xí)的三維物體重建方法是訓(xùn)練神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)二維圖像和三維物體之間的映射關(guān)系。本文的主要動機是提供近年來使用深度學(xué)習(xí)從單個圖像生成三維形狀的概況。重點分析了單幅圖像三維重建面臨的主要挑戰(zhàn)和研究方法。這些挑戰(zhàn)和方法代表了未來深度學(xué)習(xí)在單幅圖像三維重建中需要解決的問題和發(fā)展趨勢。在第2節(jié)中,本文首先討論了基于深度學(xué)習(xí)從單個圖像重建三維對象所面臨的挑戰(zhàn)。在第3節(jié)和第4節(jié)中,我們將分別介紹目前在三維多媒體工具和應(yīng)用中使用的編碼器和解碼器。第5節(jié)介紹了許多文獻中公開的訓(xùn)練細節(jié),包括損失函數(shù)和網(wǎng)絡(luò)訓(xùn)練體系結(jié)構(gòu)。在第6節(jié)中,我們介紹了用于三維重建實驗的數(shù)據(jù)集和評估指標(biāo)。在第7節(jié)中,我們進行了多次對比實驗,分析了不同三維重建方法的優(yōu)缺點。在第8節(jié)中,我們將介紹單幅圖像三維重建的相關(guān)應(yīng)用。第9節(jié)對全文進行了總結(jié),并展望了未來的發(fā)展趨勢。
2 單幅圖像三維物體重建的挑戰(zhàn)
基于深度學(xué)習(xí)的單幅圖像三維重建面臨多重挑戰(zhàn),導(dǎo)致這一方向的發(fā)展仍處于起步階段。一般來說,一個圖像的三維重建主要有以下挑戰(zhàn):(1)重建物體的形狀復(fù)雜性,(2)重建對象的不確定性,(3)重建的細粒度對象,(4)內(nèi)存需求和計算時間,(5)訓(xùn)練數(shù)據(jù)集,(6)選擇性的3 d形狀表示。
2.1 挑戰(zhàn)1:物體的形狀復(fù)雜性
首先,物體形狀復(fù)雜性主要體現(xiàn)在不同類別物體形狀的差異上,存在于對同一類別物體進行個體訓(xùn)練和不同類別物體聯(lián)合訓(xùn)練的重構(gòu)結(jié)果中。因此,一個好的三維重建模型應(yīng)該具備對不同復(fù)雜程度的物體進行表征的能力。此外,模型需要了解不同對象類之間的各種連接,同時在相同的對象類之間保持自己的唯一性。其次,物體的形狀復(fù)雜性也體現(xiàn)在其本身。一個簡單物體的結(jié)構(gòu)通常可以用多個長方體的組合來表示。當(dāng)小部件占整體結(jié)構(gòu)的比例較小時,簡單的物體往往具有較高的重構(gòu)分?jǐn)?shù)。然而,當(dāng)復(fù)雜對象的結(jié)構(gòu)較小,且有細粒度的部件(如槍扳機)時,重構(gòu)結(jié)果往往較差。在這種挑戰(zhàn)下,提高重建的三維物體的分辨率是一個相對簡單的解決方案。
2.2 挑戰(zhàn)2:對象的不確定性
單幅圖像三維重建是一個不適定問題[78]。由于單個圖像丟失了大量的三維信息,且缺乏先驗知識或假設(shè),其重建結(jié)果并不獨特。因此,最近一些研究試圖通過一些輔助手段來預(yù)測正確的形狀[31]。對于人類來說,我們可以根據(jù)自己豐富的經(jīng)驗積累,從單一的RGB圖像中推斷出不可見的3D形狀。這從側(cè)面反映了基于深度學(xué)習(xí)的單幅圖像的三維重建需要足夠的數(shù)據(jù)集來進行訓(xùn)練。
2.3 挑戰(zhàn)3:重構(gòu)細粒度對象
對于大多數(shù)3D重建模型,他們的目標(biāo)是生成具有細粒度的3D對象,而不僅僅是粗略的3D表示。不同的三維形狀表示面臨不同的困難。多媒體工具和應(yīng)用,例如基于體素的三維重建方法,大多數(shù)都面臨較高的內(nèi)存使用量和計算成本。基于網(wǎng)格的方法大多受到網(wǎng)格拓撲結(jié)構(gòu)的限制。對于不同的三維重建方法,在第4節(jié)中給出了相應(yīng)的解決方案。然而,他們都有需要解決的問題。因此,如何從單幅圖像中重建細粒度的三維物體是一個巨大的挑戰(zhàn)。
2.4 挑戰(zhàn)4:內(nèi)存需求和計算時間
對于一個優(yōu)秀的單幅圖像三維物體重建模型來說,參數(shù)應(yīng)該是輕量級的。此外,由于內(nèi)存要求有限,不僅需要從單個圖像中重構(gòu)出正確的細粒度部件形狀,而且需要良好的訓(xùn)練和推理時間。目前,針對這一挑戰(zhàn),第四節(jié)介紹了一些解決方案。
2.5 挑戰(zhàn)5:訓(xùn)練數(shù)據(jù)集
深度神經(jīng)網(wǎng)絡(luò)能夠在大模型、大計算時代發(fā)揮其強大的學(xué)習(xí)能力,這歸功于現(xiàn)有的大數(shù)據(jù)。然而,最近的研究表明,基于深度學(xué)習(xí)的單幅圖像三維物體重建實際上學(xué)習(xí)了識別能力(搜索和聚類)[112],但很少學(xué)習(xí)重建能力。ShapeNet[7]數(shù)據(jù)集是一種常用的三維對象重建數(shù)據(jù)集。整個數(shù)據(jù)集通常分為一個訓(xùn)練集,一個驗證集和一個測試集。由于測試集和訓(xùn)練集中的3D模型高度相似,神經(jīng)網(wǎng)絡(luò)可能會被誤導(dǎo)學(xué)習(xí)識別。此外,野生數(shù)據(jù)集和合成數(shù)據(jù)集之間存在很大的差異。對于未被神經(jīng)網(wǎng)絡(luò)看到的圖像,可能會導(dǎo)致不同的重建結(jié)果,選擇不同的坐標(biāo)系統(tǒng)來重建三維形狀[99]。真實數(shù)據(jù)集中的圖像內(nèi)容比較復(fù)雜,比如遮擋、多類對象、不同的光照等。因此,在一個干凈的合成數(shù)據(jù)集上訓(xùn)練后,很難在真實數(shù)據(jù)集上完成目標(biāo)的三維重建。近年來,很多研究試圖使用紋理數(shù)據(jù)集[16]和nd背景數(shù)據(jù)集來渲染2D圖像[135]。然而,實際渲染的2D圖像集與真實場景的2D圖像集之間仍然存在較大的差異,對渲染的數(shù)據(jù)集進行訓(xùn)練后,模型很難適應(yīng)真實場景中的數(shù)據(jù)集。最后,利用該模型重建的三維形狀較差。因此,如何改進現(xiàn)有的訓(xùn)練數(shù)據(jù)集,使其適合于三維重建是一個具有挑戰(zhàn)性的問題。
2.6 挑戰(zhàn)6:3D形狀表示的選擇性
目前的研究大多選擇不同的三維形狀表示來完成單個圖像的三維重建。基于體素表示的方法可以使用三維卷積神經(jīng)網(wǎng)絡(luò)(CNN),可以重構(gòu)任意拓撲結(jié)構(gòu)的對象。然而,大量的內(nèi)存需求和計算時間限制了大多數(shù)方法的重建結(jié)果的低分辨率。雖然對這一問題提出了很多改進[111,88,103],但重建結(jié)果仍然無法實現(xiàn)超高精度重建。點云表示相對簡單,靈活性高。由于點云不是一個規(guī)則的結(jié)構(gòu),它不能很好地適應(yīng)傳統(tǒng)的3D CNN。網(wǎng)格有助于在三維對象、多媒體工具和應(yīng)用中恢復(fù)模型的細節(jié),其表示精度高。同樣,網(wǎng)格不是一種規(guī)則的幾何數(shù)據(jù)形式,所以它不能直接應(yīng)用3D CNN。目前基于網(wǎng)格的研究大多采用網(wǎng)格模型變形的方法。然而,該方法不能很好地處理未知拓撲對象。雖然有些方法解決了拓撲問題[83,29],但也引入了一些問題。參數(shù)化和隱式曲面表示方法都可以用光滑的表面來表示對象,生成的對象具有更好的視覺吸引力。然而,基于參數(shù)曲面表示的三維重建難以適應(yīng)全局曲面參數(shù)化方法重建多屬復(fù)雜結(jié)構(gòu)對象[101]。用多個局部參數(shù)化曲面逼近三維形狀也面臨曲面之間的拼接問題。基于隱式曲面表示的解碼器需要預(yù)測三維空間中的所有點,這在推理階段非常耗時。使用體元來表示三維形狀可以預(yù)測相對正確的三維結(jié)構(gòu)。由于用于表示三維形狀的體元相對簡單,該方法目前只能重建簡單的三維結(jié)構(gòu)。表面原語使用多個平面貼片來近似三維形狀。該方法雖然簡化了三維表示,但也需要解決平面間的拼接問題。一般來說,這些3D表示有利有弊。
3 二維編碼器
利用深度學(xué)習(xí)技術(shù)對二維圖像進行三維重建是近年來的研究熱點。深度學(xué)習(xí)也被稱為深度神經(jīng)網(wǎng)絡(luò)。深度神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力可以用來完成許多與計算機視覺相關(guān)的任務(wù),如圖像分類[118,44],圖像分割[3,10,11],目標(biāo)識別[144,126,106],圖像超分辨率[54,47,61,665]。深度學(xué)習(xí)方法在二維圖像領(lǐng)域的成功應(yīng)用也促進了三維重建任務(wù)的發(fā)展[91,19,87,48,97,13,24,77,1,151]。一般來說,基于深度學(xué)習(xí)的三維重建模型可以將輸入圖像集表示為I = {I1, I2,…,In},設(shè)對應(yīng)的真三維形狀為Y,重構(gòu)后的三維形狀可通過式(1)進行優(yōu)化:
其中fσ(·)表示重構(gòu)器,包括2D編碼器和3D解碼器,σ表示f(·)參數(shù)集。重構(gòu)器從輸入圖像中重構(gòu)出三維形狀。dis是重建形狀與地真形狀之間距離的度量,當(dāng)兩者達到最小值時表示為L。
在二維編碼器階段,輸入圖像被編碼到一個潛在空間進行特征壓縮。根據(jù)編碼方法,可分為編碼到離散潛空間的圖像和編碼到連續(xù)潛空間的圖像。對輸入圖像進行編碼的方法可進一步分為直接編碼和中間表示編碼。對離散空間進行圖像編碼的常用網(wǎng)絡(luò)有標(biāo)準(zhǔn)卷積(Conv)網(wǎng)絡(luò)、殘差網(wǎng)絡(luò)(ResNet)、遞歸神經(jīng)網(wǎng)絡(luò)(RNN)和全連接(FC)網(wǎng)絡(luò)。將輸入圖像編碼到一個連續(xù)的潛在空間中,通常使用變分自編碼器[55](VAE)的編碼器部分。將輸入圖像編碼到潛在空間的比較結(jié)果如表1所示。

3.1 圖像到離散潛在空間
通過這種方式,編碼器將輸入圖像編碼成一個低維的潛在層向量。然后解碼器將潛在層向量映射到3D形狀。將圖像編碼到離散的潛在空間中,大致可以分為兩種方法。第一種方法是二維卷積神經(jīng)網(wǎng)絡(luò)直接將輸入圖像編碼為一個固定的低維潛在向量。第二種方式,首先對輸入圖像進行編碼以生成一個中間表示(如2.5D表示),然后對中間表示進行類似于第一種方式的編碼。
3.1.1直接編碼
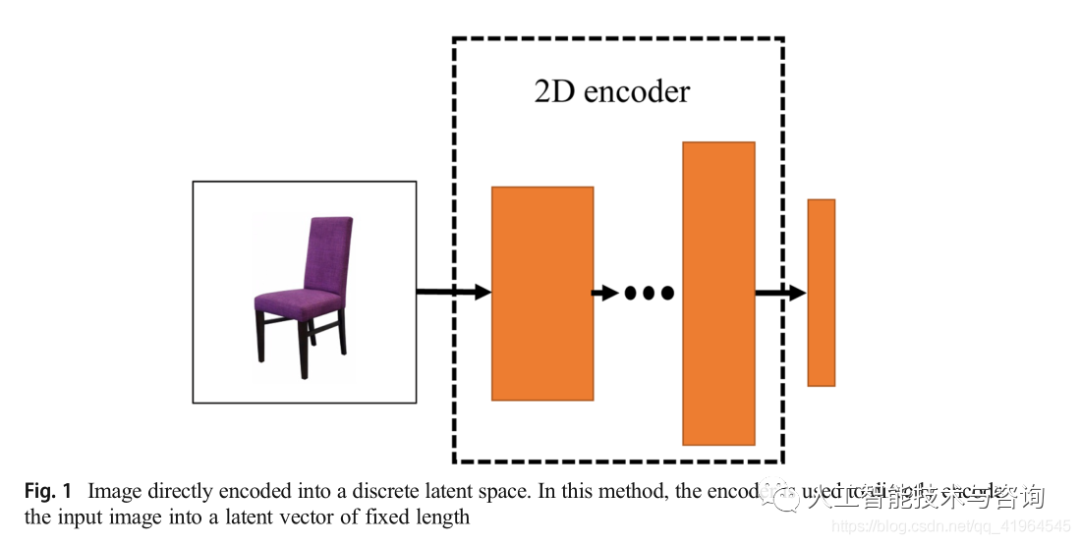
對于大多數(shù)三維物體重建方法,它們直接將輸入圖像編碼到一個低維的離散潛在空間中。編碼示意圖如圖1所示。
Choy等人[15]提出了淺殘差網(wǎng)絡(luò)和深殘差網(wǎng)絡(luò)。淺網(wǎng)絡(luò)使用標(biāo)準(zhǔn)的卷積神經(jīng)網(wǎng)絡(luò)將輸入圖像編碼為低維特征。深度殘差網(wǎng)絡(luò)采用一種快捷連接方式對標(biāo)準(zhǔn)卷積神經(jīng)網(wǎng)絡(luò)進行改進。類似地,Shin等人[99]使用了帶有殘余單元的編碼器。此外,還有關(guān)于循環(huán)2D編碼器的研究[138]。
隨后,Girdhar等人[28]引入了TL-embedding網(wǎng)絡(luò)。在T-network的底部,使用5個標(biāo)準(zhǔn)卷積層將輸入圖像編碼到一個64D嵌入空間中。在T-network的頂部,一個輸入的20×20×20體素網(wǎng)格通過3D自動編碼器編碼到一個64D嵌入空間中,輸出的相同大小的體素網(wǎng)格被解碼。此外,也有很多研究使用標(biāo)準(zhǔn)的卷積網(wǎng)絡(luò)進行直接將輸入圖像編碼到離散的隱藏空間。[137, 86, 115, 136, 122]。除了使用卷積神經(jīng)網(wǎng)絡(luò),一些研究還使用了全連接網(wǎng)絡(luò)[26]。
3.1.2 中間表示編碼
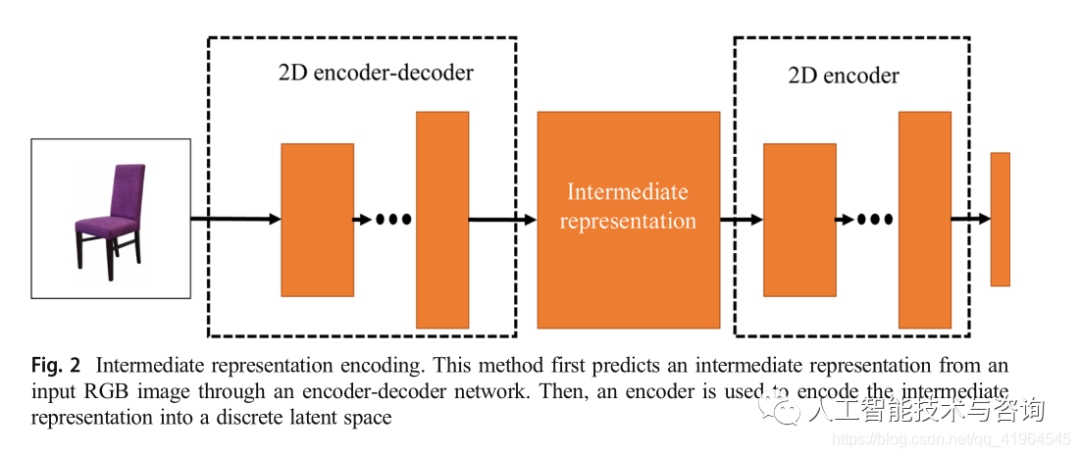
許多研究首先試圖通過2D編碼器-解碼器網(wǎng)絡(luò)生成輸入圖像的中間表示。然后,使用2D編碼器將中間表示編碼為潛在向量,基本編碼圖如圖2所示。Wu等129] 提出了MarrNet。他們首先使用ResNet-18[34]將一張256×256 RGB圖像編碼成多個特征映射。然后,通過解碼器輸出相應(yīng)的中間表示(深度映射、表面法線和輪廓圖像)。然后,中間表示被編碼成一個200維向量。最后,該矢量通過解碼器輸出128×128×128體素網(wǎng)格。此外,也有一些類似的研究[110,130,148]。
3.2 圖像到連續(xù)的潛在空間
與將圖像編碼到離散的潛在空間不同,將圖像編碼到連續(xù)的潛在空間更注重學(xué)習(xí)潛在特征空間中的概率密度函數(shù),基本編碼圖如圖3所示。VAE的編碼器所觀察到的樣本的目標(biāo)分布和產(chǎn)生一個向量意味著均值μ和方差σ參數(shù)化的高斯分布,采樣產(chǎn)生潛在的向量。能夠使用反向傳播技術(shù)優(yōu)化網(wǎng)絡(luò)參數(shù),網(wǎng)絡(luò)需要使用reparameterization技巧,從單位?高斯隨機樣本。Wu等人[128]使用VAE中的編碼器將輸入圖像編碼為一個潛在的表示向量,然后將其輸入到3D生成對抗網(wǎng)絡(luò)(3D GAN)中,完成單個圖像的3D體積重建。此外,也有一些研究使用VAE將圖像編碼到一個連續(xù)的潛空間中[102,071]。
4 3D解碼器
基于神經(jīng)網(wǎng)絡(luò)的2D編碼器從大量數(shù)據(jù)中學(xué)習(xí)將輸入圖像編碼為潛在向量。然后一個3D解碼器將潛在向量轉(zhuǎn)換成三維數(shù)據(jù)。為了從輸入圖像中生成三維形狀,整個網(wǎng)絡(luò)需要將低級圖像特征與高級特征相結(jié)合。基于單幅圖像的三維物體重建方法大多選擇使用低層圖像特征進行推理。但是,這些方法缺乏對對象結(jié)構(gòu)或表達式級別的結(jié)構(gòu)關(guān)系的理解。它們有幾種輸出表示:體素網(wǎng)格、點云、網(wǎng)格、參數(shù)曲面和隱式曲面。此外,一些作品試圖理解對象結(jié)構(gòu)的高級表示,他們將3D對象視為兩個基元(體積基元或表面基元)的集合。進一步的研究試圖在更高的層次上理解各部分之間的對稱關(guān)系[76]。三維解碼器分類如表2所示。
以下內(nèi)容回顧了基于不同3D表示的3D解碼器。為了更好地展示基于不同表示的3D解碼器之間的差異,我們根據(jù)它們的表示水平分別進行評測。
4.1 低級表示的解碼
在低級表示中,研究較多的是離散形式的體素網(wǎng)格、點云和網(wǎng)格,研究較少的是連續(xù)形式的參數(shù)面和隱式面。
4.1.1 基于體素的表示解碼
基于體素表示的三維解碼可分為密集體素解碼、中間表示體素解碼、稀疏體素解碼和其他解碼。
稠密體素解碼?隨著深度學(xué)習(xí)研究的發(fā)展,基于CAD數(shù)據(jù)庫的深度學(xué)習(xí)模型被提出用于單個圖像的三維建模。Wu等人[127]開始提出3D ShapeNets模型,該模型使用深度卷積信念網(wǎng)絡(luò)以數(shù)據(jù)驅(qū)動的方式學(xué)習(xí)所有3D體素的聯(lián)合分布。這項工作是早期使用體素形式的三維形狀表達模型之一。雖然重建結(jié)果比較粗糙,但實驗結(jié)果表明這是一個良好的開端。Choy等[15]先將潛在層向量送入中間模塊(3d long -term memory),再通過殘差網(wǎng)絡(luò)解碼器生成3d形狀(見圖4c)。同樣,Yang等[141]在潛在層向量和解碼器之間引入了注意聚集模塊(AttSets)。這兩種方法都可以利用中間模塊完成單視圖圖像或多視圖圖像的三維重建。此外,Yang等[138]提出了一種循環(huán)三維解碼器來解碼潛在層單元以生成三維體積網(wǎng)格。
與上述方法不同的是,也有一些研究將潛在層向量直接解碼成三維形狀[28,137,86,115,136,26,128,102]。這些方法使用類似的解碼器架構(gòu)(見圖4b)。
中間表示體素解碼?近年來,許多研究在二維圖像和三維形狀預(yù)測之間增加了一個中間表示(2.5D草圖)。與直接從單個二維圖像預(yù)測三維形狀相比,該方法更容易表達三維物體。Wu等人[129]提出了MarrNet,該算法首先估計輸入RGB圖像的2.5D草圖(深度、法線貼圖和輪廓)。隨后,一個3D encoder decoder被用來從中間表示的2.5D草圖估計一個3D形狀。同樣,Sun等人[110]和Wu等人[130]從輸入的RGB圖像中依次估計2.5D表示和3D形狀。與直接從2.5D估算三維形狀的方法不同,Zhang等[148]將2.5D到三維形狀過程分解為部分三維完井和全三維完井兩個階段。他們依次用部分球面圖和著色球面圖來處理深度圖,以代表物體的全部表面。最終,體素重建網(wǎng)絡(luò)將深度圖和修補的球形圖的反投影結(jié)合起來以輸出3D形狀。實驗結(jié)果表明,該網(wǎng)絡(luò)在未經(jīng)訓(xùn)練的類上也能獲得更接近真實的結(jié)果。這些方法重建的三維物體的分辨率可以達到128×128×128,重建結(jié)果也更加詳細。然而,與真實3D模型的外觀相比,還有很大的差距。
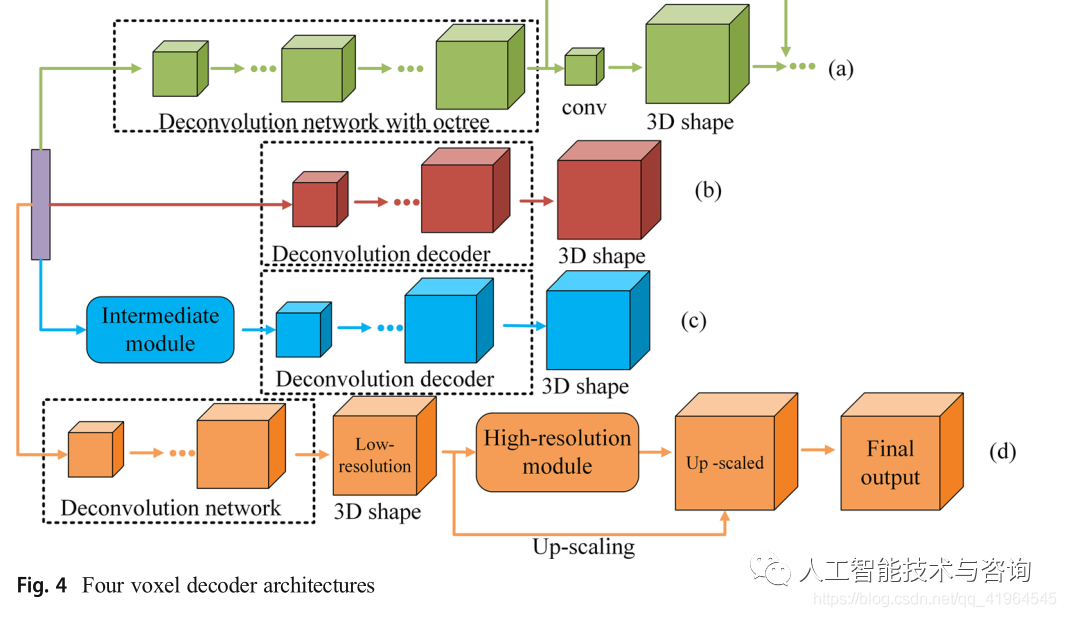
稀疏的體元解碼?在三維空間中,三維形狀的表示與重建對象的表面分辨率密切相關(guān)。近年來,人們提出了一種稀疏體素表示八叉樹的方法[89,119,90]。粗分辨率體素預(yù)測可用于空間中大部分為空且完全被占用的對象。混合部分需要進一步細分。采用八叉樹方法進行體素稀疏表示可以使重建對象的分辨率達到512×512×512。Tatarchenko等[111]提出了八叉樹生成網(wǎng)絡(luò)(OGN)(圖4a)。整個網(wǎng)絡(luò)從某一層開始,卷積網(wǎng)絡(luò)放在八叉樹上運行,直到輸出的分辨率滿足設(shè)定的條件。與密集體素解碼方法相比,OGN可以在有限的存儲空間內(nèi)表示更高分辨率的3D輸出。然而,當(dāng)分辨率增加到一定值時,網(wǎng)絡(luò)很難適應(yīng)大數(shù)據(jù)訓(xùn)練。在這種情況下,模型的性能會下降。同樣,Hane等人[33]也提出了一種分層表面預(yù)測(HSP)網(wǎng)絡(luò)。
其他的解碼?除了使用中間表示法和八叉樹法生成高分辨率三維對象外,還有將三維形狀的生成視為二維預(yù)測的方法[88,103,98]。Richter等[88]在考慮二維預(yù)測而不是三維物體重建后,提出了一種三維幾何的二維編碼方法。為了更有效地表達低分辨率的3D形狀,他們開發(fā)了一種方法,從參考視圖的每個像素預(yù)測整個體素管。此外,6個嵌套深度圖的融合用于擴展生成的3D對象分辨率。Smith等人[103]f i r st通過低分辨率的3D編解碼器重建了一個粗略的3D形狀。然后,利用三維超分辨率網(wǎng)絡(luò)對六幅高分辨率正交深度圖進行恢復(fù)。最后,利用高分辨率深度圖對上采樣的粗糙三維形狀進行切割,完成高分辨率三維形狀(圖4d)。此外,Shen等[98]提出了一種基于傅里葉變換的三維重建方法,在頻域預(yù)測切片,從二維空間重構(gòu)三維形狀。
本文僅做學(xué)術(shù)分享,如有侵權(quán),請聯(lián)系刪文。