
深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)中的應(yīng)用進(jìn)展與展望
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺(jué)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)
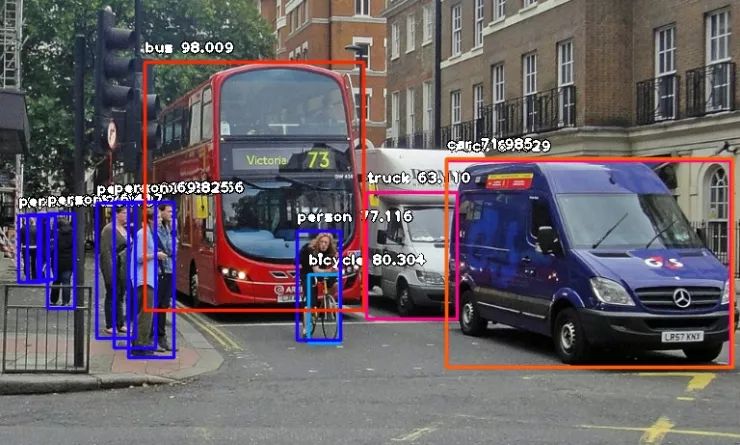 作者:張慧,王坤峰,王飛躍
作者:張慧,王坤峰,王飛躍
來(lái)源:王飛躍科學(xué)網(wǎng)博客
摘要:目標(biāo)視覺(jué)檢測(cè)是計(jì)算機(jī)視覺(jué)領(lǐng)域的一個(gè)重要問(wèn)題,在視頻監(jiān)控、自主駕駛、人機(jī)交互等方面具有重要的研究意義和應(yīng)用價(jià)值.近年來(lái),深度學(xué)習(xí)在圖像分類研究中取得了突破性進(jìn)展,也帶動(dòng)著目標(biāo)視覺(jué)檢測(cè)取得突飛猛進(jìn)的發(fā)展.本文綜述了深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)中的應(yīng)用進(jìn)展與展望.首先對(duì)目標(biāo)視覺(jué)檢測(cè)的基本流程進(jìn)行總結(jié),并介紹了目標(biāo)視覺(jué)檢測(cè)研究常用的公共數(shù)據(jù)集;然后重點(diǎn)介紹了目前發(fā)展迅猛的深度學(xué)習(xí)方法在目標(biāo)視覺(jué)檢測(cè)中的最新應(yīng)用進(jìn)展;最后討論了深度學(xué)習(xí)方法應(yīng)用于目標(biāo)視覺(jué)檢測(cè)時(shí)存在的困難和挑戰(zhàn),并對(duì)今后的發(fā)展趨勢(shì)進(jìn)行展望.
目標(biāo)視覺(jué)檢測(cè)是計(jì)算機(jī)視覺(jué)領(lǐng)域中一個(gè)非常重要的研究問(wèn)題.隨著電子設(shè)備的應(yīng)用在社會(huì)生產(chǎn)和人們生活中越來(lái)越普遍, 數(shù)字圖像已經(jīng)成為不可缺少的信息媒介, 每時(shí)每刻都在產(chǎn)生海量的圖像數(shù)據(jù).與此同時(shí),對(duì)圖像中的目標(biāo)進(jìn)行精確識(shí)別變得越來(lái)越重要[1].我們不僅關(guān)注對(duì)圖像的簡(jiǎn)單分類, 而且希望能夠準(zhǔn)確獲得圖像中存在的感興趣目標(biāo)及其位置[2], 并將這些信息應(yīng)用到視頻監(jiān)控、自主駕駛等一系列現(xiàn)實(shí)任務(wù)中, 因此目標(biāo)視覺(jué)檢測(cè)技術(shù)受到了廣泛關(guān)注[3].
目標(biāo)視覺(jué)檢測(cè)具有巨大的實(shí)用價(jià)值和應(yīng)用前景.應(yīng)用領(lǐng)域包括智能視頻監(jiān)控、機(jī)器人導(dǎo)航、數(shù)碼相機(jī)中自動(dòng)定位和聚焦人臉的技術(shù)、飛機(jī)航拍或衛(wèi)星圖像中道路的檢測(cè)、車載攝像機(jī)圖像中的障礙物檢測(cè)等.同時(shí), 目標(biāo)視覺(jué)檢測(cè)也是眾多高層視覺(jué)處理和分析任務(wù)的重要前提, 例如行為分析、事件檢測(cè)、場(chǎng)景語(yǔ)義理解等都要求利用圖像處理和模式識(shí)別技術(shù), 檢測(cè)出圖像中存在的目標(biāo), 確定這些目標(biāo)對(duì)象的語(yǔ)義類型, 并且標(biāo)出目標(biāo)對(duì)象在圖像中的具體區(qū)域[4].
在自然環(huán)境條件下, 目標(biāo)視覺(jué)檢測(cè)經(jīng)常遇到以下幾個(gè)方面的挑戰(zhàn):
1) 類內(nèi)和類間差異
對(duì)于很多物體, 它們自身就存在很大的差異性, 同類物體的不同實(shí)例在顏色、材料、形狀等方面可能存在巨大的差異, 很難訓(xùn)練一個(gè)能夠包含所有類內(nèi)變化的特征描述模型.另外, 不同類型物體之間又可能具有很大的相似性, 甚至非專業(yè)人員從外觀上很難區(qū)分它們.類內(nèi)差異可能很大, 而類間差異可能很小, 給目標(biāo)視覺(jué)檢測(cè)提出了挑戰(zhàn).
2) 圖像采集條件
在圖像采集過(guò)程中, 由于環(huán)境、光照、天氣、拍攝視角和距離的不同、物體自身的非剛體形變以及可能被其他物體部分遮擋, 導(dǎo)致物體在圖像中的表觀特征具有很大的多樣性, 對(duì)視覺(jué)算法的魯棒性提出了很高要求.
3) 語(yǔ)義理解的差異
對(duì)同一幅圖像, 不同的人可能會(huì)有不同的理解, 這不僅與個(gè)人的觀察視角和關(guān)注點(diǎn)有關(guān), 也與個(gè)人的性格、心理狀態(tài)和知識(shí)背景等有關(guān), 這明顯增加了從仿生或類腦角度來(lái)研究視覺(jué)算法的難度.
4) 計(jì)算復(fù)雜性和自適應(yīng)性
目標(biāo)視覺(jué)檢測(cè)的計(jì)算復(fù)雜性主要來(lái)自于待檢測(cè)目標(biāo)類型的數(shù)量、特征描述子的維度和大規(guī)模標(biāo)記數(shù)據(jù)集的獲取.由于在真實(shí)世界中存在大量的目標(biāo)類型, 每種類型都包含大量的圖像, 同時(shí)識(shí)別每種類型需要很多視覺(jué)特征, 這導(dǎo)致高維空間稀疏的特征描述[4].另外, 目標(biāo)模型經(jīng)常從大規(guī)模標(biāo)記數(shù)據(jù)集中學(xué)習(xí)得到, 在許多情況下, 數(shù)據(jù)采集和標(biāo)注很困難, 需要耗費(fèi)大量的人力物力.這些情況導(dǎo)致目標(biāo)檢測(cè)的計(jì)算復(fù)雜性很高, 需要設(shè)計(jì)高效的目標(biāo)檢測(cè)算法.同時(shí), 在動(dòng)態(tài)變化的環(huán)境中, 為了提高目標(biāo)檢測(cè)精度, 還需要探索合適的機(jī)制來(lái)自動(dòng)更新視覺(jué)模型, 提高模型對(duì)復(fù)雜環(huán)境的自適應(yīng)能力.
為了克服上述挑戰(zhàn), 已經(jīng)提出了許多目標(biāo)視覺(jué)檢測(cè)算法, 它們?cè)谀繕?biāo)區(qū)域建議、圖像特征表示、候選區(qū)域分類等步驟采用了不同的處理策略.近年來(lái), 隨著深度學(xué)習(xí)技術(shù)的發(fā)展, 很多基于深度學(xué)習(xí)的目標(biāo)視覺(jué)檢測(cè)方法陸續(xù)被提出, 在精度上顯著優(yōu)于傳統(tǒng)方法, 成為最新的研究熱點(diǎn).本文首先介紹目標(biāo)視覺(jué)檢測(cè)的基本流程, 然后重點(diǎn)介紹深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)中的應(yīng)用進(jìn)展.
本文內(nèi)容安排如下:
第1節(jié)介紹目標(biāo)視覺(jué)檢測(cè)的基本流程;
第2節(jié)對(duì)目標(biāo)視覺(jué)檢測(cè)研究常用的公共數(shù)據(jù)集進(jìn)行概述;
第3節(jié)介紹深度學(xué)習(xí)技術(shù)在目標(biāo)視覺(jué)檢測(cè)中的最新應(yīng)用進(jìn)展;
第4節(jié)討論深度學(xué)習(xí)技術(shù)應(yīng)用于目標(biāo)視覺(jué)檢測(cè)時(shí)存在的困難和挑戰(zhàn), 并對(duì)今后的發(fā)展趨勢(shì)進(jìn)行展望;
第5節(jié)對(duì)本文進(jìn)行總結(jié).
1 目標(biāo)視覺(jué)檢測(cè)的基本流程
目標(biāo)視覺(jué)檢測(cè)的根本問(wèn)題是估計(jì)特定類型目標(biāo)出現(xiàn)在圖像中的哪些位置.如圖 1所示, 目標(biāo)視覺(jué)檢測(cè)技術(shù)在流程上大致分為三個(gè)步驟:區(qū)域建議(Region proposal)、特征表示(Feature representation)和區(qū)域分類(Region classification).首先對(duì)圖像中可能的目標(biāo)位置提出建議, 也就是提出一些可能含有目標(biāo)的候選區(qū)域.然后采用合適的特征模型得到特征表示.最后借助分類器判斷各個(gè)區(qū)域中是否含有特定類型的目標(biāo), 并且通過(guò)一些后處理操作, 例如非極大值抑制、邊框位置回歸等, 得到最終的目標(biāo)邊框.該基本流程被許多工作所采用, 例如文獻(xiàn)[5]提出的HOG-SVM檢測(cè)方法、文獻(xiàn)[6]提出的Selective search區(qū)域建議方法、目前在PASCAL VOC、MS COCO、ImageNet等數(shù)據(jù)集上取得領(lǐng)先精度的Faster R-CNN[7]檢測(cè)方法以及Faster R-CNN采用的特征表示和區(qū)域分類方法ResNet[8]等.
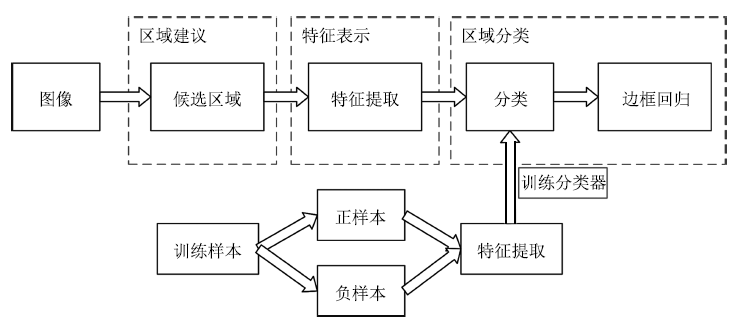
圖 1 目標(biāo)視覺(jué)檢測(cè)的基本流程
Figure 1 Basic procedure for object detection
本節(jié)接下來(lái)從區(qū)域建議、特征表示和區(qū)域分類三個(gè)方面來(lái)總結(jié)目標(biāo)視覺(jué)檢測(cè)的關(guān)鍵技術(shù).
1.1 區(qū)域建議
目標(biāo)檢測(cè)要求獲得目標(biāo)的位置和尺度信息, 這需要借助區(qū)域建議來(lái)實(shí)現(xiàn).區(qū)域建議是指在輸入圖像中搜尋特定類型目標(biāo)的可能區(qū)域的一種策略.傳統(tǒng)的區(qū)域建議策略包括三種[4]:基于滑動(dòng)窗的區(qū)域建議、基于投票機(jī)制的區(qū)域建議和基于圖像分割的區(qū)域建議.
1.1.1 基于滑動(dòng)窗的區(qū)域建議
基于滑動(dòng)窗的方法是在輸入圖像所有可能的子窗口中執(zhí)行目標(biāo)檢測(cè)算法來(lái)定位潛在的目標(biāo).在文獻(xiàn)[5]中, 檢測(cè)窗口是一個(gè)給定大小的矩形框, 在整幅圖像的所有位置和尺度上進(jìn)行掃描, 并對(duì)區(qū)域分類結(jié)果做非極大值抑制.基于滑動(dòng)窗的區(qū)域建議方法采用窮舉搜索, 原理簡(jiǎn)單, 易于實(shí)現(xiàn), 但是計(jì)算復(fù)雜性高, 太過(guò)耗時(shí).于是一些研究者提出加快窗口搜索的方法. Lampert等[9]提出了一種高效的子窗口搜索策略(簡(jiǎn)稱為ESS), 采用分支限界法來(lái)減少搜索范圍.但是它的性能在很大程度上取決于輸入圖像中的物體, 當(dāng)沒(méi)有物體出現(xiàn)時(shí),該算法退化到窮舉搜索. An等[10]提出一種改進(jìn)的ESS算法. Wei等[11]提出一種在直方圖維度上具有常數(shù)復(fù)雜度的滑動(dòng)窗口策略. Van de Sande等[12]引入圖像分割信息, 將其作為目標(biāo)假設(shè)區(qū)域, 從而只對(duì)這些假設(shè)區(qū)域進(jìn)行目標(biāo)檢測(cè).
1.1.2 基于投票機(jī)制的區(qū)域建議
基于投票機(jī)制的方法主要用于基于部件的模型, 通常投票機(jī)制的實(shí)現(xiàn)可歸納為兩步[13-14]: 1) 找到輸入圖像與模型中各個(gè)局部區(qū)域最匹配的區(qū)域, 并最大化所有局部區(qū)域的匹配得分; 2) 利用拓?fù)湓u(píng)價(jià)方法取得最佳的結(jié)構(gòu)匹配.由于投票機(jī)制是一種貪心算法, 可能得不到最優(yōu)的拓?fù)浼僭O(shè), 并且部件匹配通常采用窮舉搜索來(lái)實(shí)現(xiàn), 計(jì)算代價(jià)很高.
1.1.3 基于圖像分割的區(qū)域建議
基于圖像分割的區(qū)域建議建立在圖像分割的基礎(chǔ)上, 分割的圖像區(qū)域就是目標(biāo)的位置候選.語(yǔ)義分割是一種最直接的圖像分割方法, 需要對(duì)每個(gè)像素所屬的目標(biāo)類型進(jìn)行標(biāo)注[15].目前主要采用的方法是概率圖模型, 例如采用CRF[16]或MRF[17]方法來(lái)鼓勵(lì)相鄰像素之間的標(biāo)記一致性.圖像分割是一個(gè)耗時(shí)而又復(fù)雜的過(guò)程, 而且很難將單個(gè)目標(biāo)完整地分割出來(lái).
不同于以上策略, 文獻(xiàn)[6]先將圖片分割成若干小區(qū)域, 然后再聚合, 通過(guò)對(duì)聚合后的區(qū)域打分并排序,獲得較有可能是目標(biāo)區(qū)域的窗口.文獻(xiàn)[18-19]中采用生成大量窗口并打分, 然后過(guò)濾掉低分的方法.文獻(xiàn)[20]對(duì)這些方法進(jìn)行了討論和比較.這些方法存在的主要問(wèn)題是, 采樣數(shù)目較少時(shí)召回率不高、定位精度較低等.對(duì)于一個(gè)目標(biāo)檢測(cè)系統(tǒng)來(lái)說(shuō), 少量的候選區(qū)域不僅可以減少運(yùn)行時(shí)間, 而且使得檢測(cè)準(zhǔn)確率更高, 因此保證采樣數(shù)目少的情況下召回率仍然很高是至關(guān)重要的.為了解決這些問(wèn)題, 一些研究者開(kāi)始采用深度學(xué)習(xí)方法來(lái)產(chǎn)生候選區(qū)域.在MultiBox[21-22]中, 通過(guò)采用深度神經(jīng)網(wǎng)絡(luò)回歸模型定位出若干可能的包圍邊框.在Deepbox[23]中, Kuo等采用訓(xùn)練卷積神經(jīng)網(wǎng)絡(luò)模型來(lái)給通過(guò)EdgeBoxes[19]產(chǎn)生的候選區(qū)域進(jìn)行排序.在DeepProposal[24]中, Ghodrati等評(píng)估了用卷積神經(jīng)網(wǎng)絡(luò)產(chǎn)生目標(biāo)候選區(qū)域的質(zhì)量, 發(fā)現(xiàn)最后一層卷積層可以以很高的召回率找到感興趣的目標(biāo), 但是定位精度很低, 而第一層網(wǎng)絡(luò)可以很好地定位目標(biāo), 但是召回率很低.基于此發(fā)現(xiàn), 他們?cè)O(shè)計(jì)了一種通過(guò)多層CNN特征由粗到細(xì)地串聯(lián)來(lái)產(chǎn)生候選區(qū)域的方法.文獻(xiàn)[7]提出區(qū)域建議網(wǎng)絡(luò)(Region proposal network, RPN), 把產(chǎn)生候選區(qū)域和區(qū)域分類聯(lián)合到一個(gè)深度神經(jīng)網(wǎng)絡(luò), 通過(guò)端到端訓(xùn)練, 在提高精度的同時(shí)降低了計(jì)算時(shí)間.最近, Gidaris等[25]使用概率預(yù)測(cè)方式來(lái)進(jìn)一步提高目標(biāo)檢測(cè)的定位精度, 不同于邊框位置回歸的方法, 該方法首先將搜索區(qū)域劃分成若干個(gè)水平區(qū)域和豎直區(qū)域, 然后給搜索區(qū)域的每列或每行分配概率, 利用這些概率信息來(lái)不斷迭代獲得更精確的檢測(cè)框.
1.2 特征表示
特征表示是實(shí)現(xiàn)目標(biāo)視覺(jué)檢測(cè)必備的步驟, 選擇合適的特征模型將圖像區(qū)域映射為特征向量, 然后利用從訓(xùn)練樣本學(xué)習(xí)到的分類器對(duì)該特征向量進(jìn)行分類, 判斷其所屬類型.特征的表達(dá)能力直接影響分類器精度,決定了算法的最終性能.特征模型主要分為手工設(shè)計(jì)的特征和自動(dòng)學(xué)習(xí)的特征.
1.2.1 手工設(shè)計(jì)的特征
在深度學(xué)習(xí)熱潮之前, 主要采用手工設(shè)計(jì)的特征.手工特征數(shù)目繁多, 可以分為三大類:基于興趣點(diǎn)檢測(cè)的方法、基于密集提取的方法和基于多種特征組合的方法.
1) 基于興趣點(diǎn)檢測(cè)的方法
興趣點(diǎn)檢測(cè)方法通過(guò)某種準(zhǔn)則, 選擇具有明確定義并且局部紋理特征比較明顯的像素、邊緣和角點(diǎn)等[3].其中Sobel、Prewitt、Roberts、Canny和LoG (Laplacian of Gaussian)等是典型的邊緣檢測(cè)算子[26-29].而Harris、FAST (Features from accelerated segment test)、CSS (Curvature scale space)和DOG (Difference of Gaussian)等是典型的角點(diǎn)檢測(cè)算子[30-32].興趣點(diǎn)檢測(cè)方法通常具有一定的幾何不變性, 能夠以較小的計(jì)算代價(jià)得到有意義的表達(dá).
2) 基于密集提取的方法
密集提取方法主要提取局部特征.區(qū)別于顏色直方圖等全局特征, 局部特征有利于處理目標(biāo)部分遮擋問(wèn)題.常用的局部特征有SIFT (Scale-invariant feature transform)[33]、HOG (Histogram of oriented gradient)[5]、Haar-like[34]和LBP (Local binary pattern)[35-36]等.局部特征包含的信息豐富、獨(dú)特性好, 并且具有較強(qiáng)的不變性和可區(qū)分性, 能夠最大程度地對(duì)圖像進(jìn)行底層描述.但是其計(jì)算一般比較復(fù)雜, 近些年圖像的局部特征正在向快速和低存儲(chǔ)方向發(fā)展.
3) 基于多種特征組合的方法
手工特征具有良好的可擴(kuò)展性, 將興趣點(diǎn)檢測(cè)與密集提取相結(jié)合的多種特征組合方法, 能夠彌補(bǔ)利用單一特征進(jìn)行目標(biāo)表示的不足. DPM (Deformable part-based model)[2]提出了一種有效的多種特征組合模型, 被廣泛應(yīng)用于目標(biāo)檢測(cè)任務(wù)并取得了良好效果, 例如行人檢測(cè)[37-38]、人臉檢測(cè)[39-40]和人體姿態(tài)估計(jì)[41]等.另外, 文獻(xiàn)[42]提出了一種改進(jìn)的DPM方法, 大大提升了檢測(cè)速度.
依靠手工設(shè)計(jì)特征, 需要豐富的專業(yè)知識(shí)并且花費(fèi)大量的時(shí)間.特征的好壞在很大程度上還要依靠經(jīng)驗(yàn)和運(yùn)氣, 往往整個(gè)算法的測(cè)試和調(diào)節(jié)工作都集中于此, 需要手工完成, 十分費(fèi)力.與之相比, 近年來(lái)受到廣泛關(guān)注的深度學(xué)習(xí)理論中的一個(gè)重要觀點(diǎn)就是手工設(shè)計(jì)的特征描述子作為視覺(jué)計(jì)算的第一步, 往往過(guò)早地丟失掉有用信息, 而直接從圖像中學(xué)習(xí)到與任務(wù)相關(guān)的特征表示, 比手工設(shè)計(jì)特征更加有效[3].
1.2.2 自動(dòng)學(xué)習(xí)的特征
近年來(lái), 深度學(xué)習(xí)在圖像分類和目標(biāo)檢測(cè)等領(lǐng)域取得了突破性進(jìn)展, 成為目前最有效的自動(dòng)特征學(xué)習(xí)方法.深度學(xué)習(xí)模型具有強(qiáng)大的表征和建模能力, 通過(guò)監(jiān)督或非監(jiān)督的方式, 逐層自動(dòng)地學(xué)習(xí)目標(biāo)的特征表示,將原始數(shù)據(jù)經(jīng)過(guò)一系列非線性變換, 生成高層次的抽象表示, 避免了手工設(shè)計(jì)特征的繁瑣低效.深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)中的研究現(xiàn)狀是本文的核心內(nèi)容, 將在第3節(jié)進(jìn)行詳細(xì)介紹.
1.3 區(qū)域分類
區(qū)域分類是指把候選區(qū)域的特征向量作為分類器輸入, 預(yù)測(cè)候選區(qū)域所屬的目標(biāo)類型.分類器在目標(biāo)檢測(cè)中的作用可以概括為:先利用訓(xùn)練數(shù)據(jù)集進(jìn)行模型學(xué)習(xí), 然后利用學(xué)習(xí)到的模型對(duì)新的候選區(qū)域進(jìn)行類型預(yù)測(cè).分類器一般是利用監(jiān)督學(xué)習(xí)方法訓(xùn)練得到的, 常用的有支持向量機(jī)(Support vector machine, SVM)、Adaboost、隨機(jī)森林、神經(jīng)網(wǎng)絡(luò)等.目前, 圖像識(shí)別任務(wù)中廣泛采用一對(duì)多(One-vs-others)的分類器訓(xùn)練方式[43], 就是把其中一類模式作為正樣本, 其余模式作為負(fù)樣本, 針對(duì)每一類模式分別訓(xùn)練一個(gè)分類器; 在測(cè)試階段, 將圖像特征分別輸入到所有的分類器, 選擇分類器響應(yīng)最大的一類模式作為類型預(yù)測(cè). Girshick等[44]就是采用這種方式, 提取候選區(qū)域的特征表示, 利用一對(duì)多SVM分類器實(shí)現(xiàn)對(duì)PASCAL VOC圖像集20種目標(biāo)的檢測(cè).
2 目標(biāo)視覺(jué)檢測(cè)的公共數(shù)據(jù)集
為了促進(jìn)目標(biāo)視覺(jué)檢測(cè)的研究進(jìn)展, 建設(shè)大規(guī)模的公共數(shù)據(jù)集成為必然要求.目前, 目標(biāo)視覺(jué)檢測(cè)研究常用的公共數(shù)據(jù)集有ImageNet、PASCAL VOC、SUN和MS COCO等.下面將從這些數(shù)據(jù)集包含的圖像數(shù)目、類型數(shù)目、每類樣本數(shù)等方面對(duì)它們進(jìn)行介紹.直觀對(duì)比如圖 2所示.
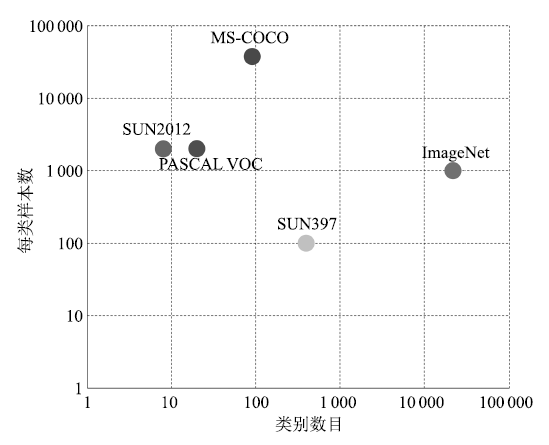
圖 2 幾種公共數(shù)據(jù)集的對(duì)比圖
Figure 2 Comparison of several common datasets
1) ImageNet數(shù)據(jù)集[45]
該數(shù)據(jù)集是目前世界上最大的圖像分類數(shù)據(jù)集, 包含1 400萬(wàn)幅圖像、2.2萬(wàn)個(gè)類型, 平均每個(gè)類型包含1 000幅圖像.此外, ImgeNet還建立了一個(gè)包含1 000類物體, 有120萬(wàn)圖像的數(shù)據(jù)集, 并將該數(shù)據(jù)集作為圖像識(shí)別競(jìng)賽的數(shù)據(jù)平臺(tái).
2) PASCAL VOC數(shù)據(jù)集[46]
2005 ~ 2012年, 該數(shù)據(jù)集每年都發(fā)布關(guān)于圖像分類、目標(biāo)檢測(cè)和圖像分割等任務(wù)的數(shù)據(jù)集, 并在相應(yīng)數(shù)據(jù)集上舉行算法競(jìng)賽, 極大地推動(dòng)了計(jì)算機(jī)視覺(jué)領(lǐng)域的研究進(jìn)展.該數(shù)據(jù)集最初只提供了4個(gè)類型的圖像,到2007年穩(wěn)定在20個(gè)類; 測(cè)試圖像的數(shù)量從最初的1 578幅, 到2011年穩(wěn)定在11 530幅.雖然該數(shù)據(jù)集類型數(shù)目比較少, 但是由于圖像中物體變化極大, 每幅圖像可能包含多個(gè)不同類型目標(biāo)對(duì)象, 并且目標(biāo)尺度變化很大, 因而檢測(cè)難度非常大.
3) SUN數(shù)據(jù)集[47]
該數(shù)據(jù)集是一個(gè)覆蓋較大場(chǎng)景、位置、物體變化的數(shù)據(jù)集, 其中的場(chǎng)景名主要是從WorldNet中描述場(chǎng)景、位置、環(huán)境等任何具體的名詞得來(lái). SUN數(shù)據(jù)集包含兩個(gè)評(píng)測(cè)集:一個(gè)是場(chǎng)景識(shí)別數(shù)據(jù)集, 稱為SUN 397, 共包含397類場(chǎng)景, 每類至少包含100幅圖像, 總共有108 754幅圖像; 另一個(gè)評(píng)測(cè)集為物體檢測(cè)數(shù)據(jù)集,稱為SUN 2012, 包含16 873幅圖像.
4) MS COCO數(shù)據(jù)集[48]
該數(shù)據(jù)集包含約30多萬(wàn)幅圖像、200多萬(wàn)個(gè)標(biāo)注物體、91個(gè)物體類型.雖然比ImageNet和SUN包含的類型少, 但是每一類物體的圖像多, 另外圖像中包含精確的分割信息, 是目前每幅圖像平均包含目標(biāo)數(shù)最多的數(shù)據(jù)集. MS COCO不但能夠用于目標(biāo)視覺(jué)檢測(cè)研究, 還能夠用來(lái)研究圖像中目標(biāo)之間的上下文關(guān)系.
3 深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)中的應(yīng)用進(jìn)展
3.1 深度學(xué)習(xí)簡(jiǎn)介
深度學(xué)習(xí)模型具有強(qiáng)大的表征和建模能力, 通過(guò)監(jiān)督或非監(jiān)督的訓(xùn)練方式, 能夠逐層、自動(dòng)地學(xué)習(xí)目標(biāo)的特征表示, 實(shí)現(xiàn)對(duì)物體層次化的抽象和描述. 1986年, Rumelhart等[49]提出人工神經(jīng)網(wǎng)絡(luò)的反向傳播(Back propagation, BP)算法. BP算法指導(dǎo)機(jī)器如何從后一層獲取誤差而改變前一層的內(nèi)部參數(shù), 深度學(xué)習(xí)能夠利用BP算法發(fā)現(xiàn)大數(shù)據(jù)中的復(fù)雜結(jié)構(gòu), 把原始數(shù)據(jù)通過(guò)一些簡(jiǎn)單的非線性函數(shù)變成高層次的抽象表達(dá)[50], 使計(jì)算機(jī)自動(dòng)學(xué)習(xí)到模式特征, 從而避免了手工設(shè)計(jì)特征的繁瑣低效問(wèn)題. Hinton等[51-52]于2006年首次提出以深度神經(jīng)網(wǎng)絡(luò)為代表的深度學(xué)習(xí)技術(shù), 引起學(xué)術(shù)界的關(guān)注.之后, Bengio[53]、LeCun[54]和Lee[55]等迅速開(kāi)展了重要的跟進(jìn)工作, 開(kāi)啟了深度學(xué)習(xí)研究的熱潮.深度學(xué)習(xí)技術(shù)首先在語(yǔ)音識(shí)別領(lǐng)域取得了突破性進(jìn)展[56].在圖像識(shí)別領(lǐng)域, Krizhevsky等[57]于2012年構(gòu)建深度卷積神經(jīng)網(wǎng)絡(luò), 在大規(guī)模圖像分類問(wèn)題上取得了巨大成功.隨后在目標(biāo)檢測(cè)任務(wù)中, 深度學(xué)習(xí)方法[7, 44, 58]也超過(guò)了傳統(tǒng)方法。
目前應(yīng)用于圖像識(shí)別和分析研究的深度學(xué)習(xí)模型主要包括堆疊自動(dòng)編碼器(Stacked auto-encoders, SAE)[53]、深度信念網(wǎng)絡(luò)(Deep belief network, DBN)[51-52]和卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural networks, CNN)[59]等.
SAE模型的實(shí)質(zhì)是多個(gè)自動(dòng)編碼器(Auto-encoder, AE)的堆疊.一個(gè)自動(dòng)編碼器是由編碼器和解碼器兩部分組成, 能夠盡可能復(fù)現(xiàn)輸入信號(hào).作為一種無(wú)監(jiān)督學(xué)習(xí)的非線性特征提取方法, 其輸出與輸入具有相同的維度, 隱藏層則被用來(lái)進(jìn)行原始數(shù)據(jù)的特征表示或編碼. SAE模型將前一層自動(dòng)編碼器的輸出作為后一層自動(dòng)編碼器的輸入, 逐層地對(duì)自動(dòng)編碼器進(jìn)行預(yù)訓(xùn)練, 然后利用BP算法對(duì)整個(gè)網(wǎng)絡(luò)進(jìn)行微調(diào).目前基于SAE的擴(kuò)展模型有很多, 例如, 堆疊去噪自動(dòng)編碼器(Stacked denoising autoencoders, SDA)[60], 以及堆疊卷積自動(dòng)編碼器(Stacked convolutional auto-encoders, SCAE)[61].
DBN類似于SAE, 它的基本單元是受限玻爾茲曼機(jī)(Restricted Boltzmann machines, RBM), 整個(gè)網(wǎng)絡(luò)的訓(xùn)練分為兩個(gè)階段:預(yù)訓(xùn)練和全局微調(diào).首先以原始輸入為可視層, 訓(xùn)練一個(gè)單層的RBM, 該RBM訓(xùn)練完成后,其隱層輸出作為下一層RBM的輸入, 繼續(xù)訓(xùn)練下一層RBM.以此類推, 逐層訓(xùn)練, 直至將所有RBM訓(xùn)練完成,通過(guò)這種貪婪式的無(wú)監(jiān)督訓(xùn)練, 使整個(gè)DBN模型得到一個(gè)比較好的初始值, 然后加入數(shù)據(jù)標(biāo)簽對(duì)整個(gè)網(wǎng)絡(luò)進(jìn)行有監(jiān)督的微調(diào), 進(jìn)一步改善網(wǎng)絡(luò)性能.
CNN是圖像和視覺(jué)識(shí)別中的研究熱點(diǎn), 近年來(lái)取得了豐碩成果. 圖 3給出了由LeCun等[59]提出的用于數(shù)字手寫體識(shí)別的CNN網(wǎng)絡(luò)結(jié)構(gòu), CNN通常包含卷積層、池化層和全連接層.卷積層通過(guò)使用多個(gè)濾波器與整個(gè)圖像進(jìn)行卷積, 可以得到圖像的多個(gè)特征圖表示; 池化層實(shí)際上是一個(gè)下采樣層, 通過(guò)求局部區(qū)域的最大值或平均值來(lái)達(dá)到降采樣的目的, 進(jìn)一步減少特征空間; 全連接層用于進(jìn)行高層推理, 實(shí)現(xiàn)最終分類. CNN的權(quán)值共享和局部連接大大減少了參數(shù)的規(guī)模, 降低了模型的訓(xùn)練復(fù)雜度, 同時(shí)卷積操作保留了圖像的空間信息, 具有平移不變性和一定的旋轉(zhuǎn)、尺度不變性. 2012年, Krizhevsky等[57]將CNN模型用于ImageNet大規(guī)模視覺(jué)識(shí)別挑戰(zhàn)賽(ImageNet large scale visual recognition challenge, ILSVRC)的圖像分類問(wèn)題, 使錯(cuò)誤率大幅降低, 在國(guó)際上引起了對(duì)CNN模型的高度重視, 也因此推動(dòng)了目標(biāo)視覺(jué)檢測(cè)的研究進(jìn)展.
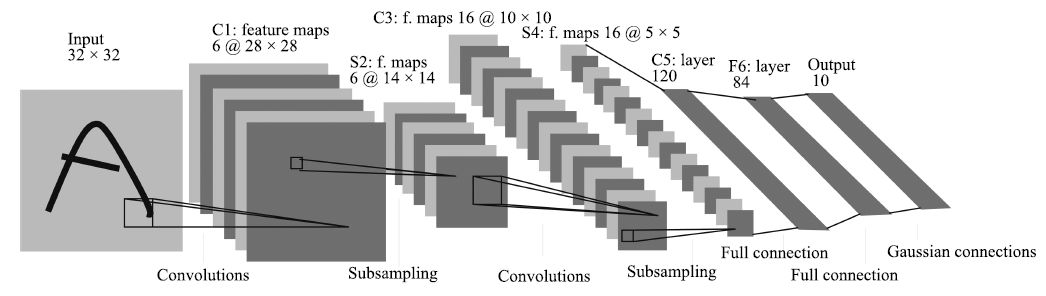
圖 3 卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)[59]
Figure 3 Basic structure of convolutional neural network[59]
3.2 AlexNet及其改進(jìn)模型
隨著深度學(xué)習(xí)的發(fā)展, 人們將深度學(xué)習(xí)應(yīng)用于圖像分類和目標(biāo)檢測(cè)任務(wù)中, 在許多公開(kāi)競(jìng)賽中取得了明顯優(yōu)于傳統(tǒng)方法的結(jié)果. Krizhevsky等[57]提出了一種新型卷積神經(jīng)網(wǎng)絡(luò)模型AlexNet, 隨后其他研究者相繼提出ZFNet[62]、VGG[63]、GoogLeNet[64]和ResNet[8]等改進(jìn)模型, 進(jìn)一步提高了模型精度. 表 1顯示了幾種經(jīng)典CNN模型在圖像分類任務(wù)中的性能對(duì)比. ILSVRC的圖像分類錯(cuò)誤率每年都在被刷新, 如圖 4所示.隨著模型變得越來(lái)越深, 圖像分類的Top-5錯(cuò)誤率也越來(lái)越低, 目前已經(jīng)降低到3.08%附近[65].而在同樣的ImageNet數(shù)據(jù)集上, 人眼的辨識(shí)錯(cuò)誤率大約在5.1%.盡管這些模型都是針對(duì)圖像分類來(lái)做的, 但是都在解決一個(gè)最根本的問(wèn)題, 即更強(qiáng)大的特征表示.采用這些CNN模型得到更強(qiáng)大的特征表示, 然后應(yīng)用到目標(biāo)檢測(cè)任務(wù), 可以獲得更高的檢測(cè)精度.
表 1 經(jīng)典CNN模型在ILSVRC圖像分類任務(wù)上的性能對(duì)比
Table 1 Performance comparison of classical CNN model in image classification task of ILSVRC
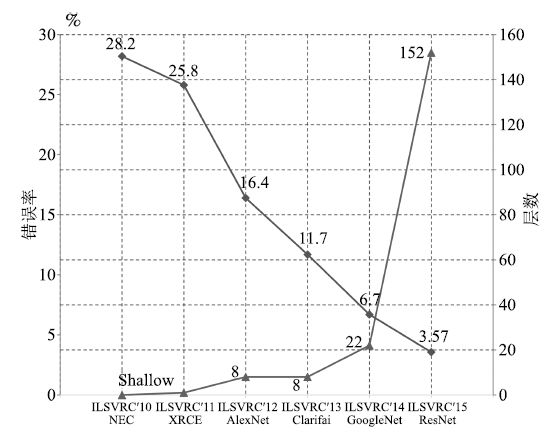
圖 4 ILSVRC圖像分類任務(wù)歷年冠軍方法的Top-5錯(cuò)誤率(下降曲線)和網(wǎng)絡(luò)層數(shù)(上升曲線)
Figure 4 Top-5 error rate (descent curve) and network layers (rise curve) of the champion methods each year in image classification task of ILSVRC
AlexNet[57]在ILSVRC 2012圖像分類任務(wù)上取得了Top-5錯(cuò)誤率16.4%, 明顯優(yōu)于基于傳統(tǒng)方法的第2名的結(jié)果(Top-5錯(cuò)誤率26.2%). AlexNet神經(jīng)網(wǎng)絡(luò)由5個(gè)卷積層、最大池化層、Dropout層和3個(gè)全連接層組成,網(wǎng)絡(luò)能夠?qū)? 000個(gè)圖像類型進(jìn)行分類.由于AlexNet的成功, 許多研究人員開(kāi)始關(guān)注和改進(jìn)CNN結(jié)構(gòu). Zeiler等[62]通過(guò)可視化AlexNet網(wǎng)絡(luò), 發(fā)現(xiàn)第1層濾波器是非常高頻和低頻信息的混合, 很少覆蓋中間頻率.并且由于第2層卷積采用比較大的步長(zhǎng), 導(dǎo)致第2層出現(xiàn)混疊失真(Aliasing artifacts).為了解決這些問(wèn)題, 他們將第1層濾波器的尺寸從11 × 11減小到7 × 7, 將步長(zhǎng)從4減小到2, 形成ZFNet模型. ZFNet在網(wǎng)絡(luò)的第1層和第2層保留了更多信息, 降低了分類錯(cuò)誤率.
Simonyan等[63]隨后提出VGG網(wǎng)絡(luò), 探索在網(wǎng)絡(luò)參數(shù)總數(shù)基本不變的情況下, CNN隨著層數(shù)的增加, 導(dǎo)致其性能的變化.不同于AlexNet, VGG采用的濾波器尺寸是3 × 3, 通過(guò)將多個(gè)3 × 3濾波器堆疊的方式來(lái)代替一個(gè)大尺寸的濾波器, 因?yàn)槎鄠€(gè)3 × 3尺寸的卷積層比一個(gè)大尺寸濾波器卷積層具有更高的非線性, 使模型更有判別能力, 而且多個(gè)3 × 3尺寸的卷積層比一個(gè)大尺寸的濾波器有更少的參數(shù).通過(guò)加入1 × 1卷積層, 在不影響輸入輸出維數(shù)的情況下, 進(jìn)一步增加網(wǎng)絡(luò)的非線性表達(dá)能力.
Szegedy等[64]提出了一種新的深度CNN模型GoogLeNet, 習(xí)慣上稱為Inception-v1.只利用了比AlexNet[57]少12倍的參數(shù), 但分類錯(cuò)誤率更低. GoogLeNet采用Inception結(jié)構(gòu), 上一層的輸出經(jīng)過(guò)1×1 、3×3、5×5 的卷積層和3×3的池化層, 然后拼接在一起作為Inception的輸出.并且在3×3 、5 × 5卷積層之前采用1×1卷積層來(lái)降維, 既增加了網(wǎng)絡(luò)的深度, 又減少了網(wǎng)絡(luò)參數(shù). Inception結(jié)構(gòu)既提高了網(wǎng)絡(luò)對(duì)尺度的適應(yīng)性, 又提高了網(wǎng)絡(luò)計(jì)算資源的利用率.但是深度網(wǎng)絡(luò)在訓(xùn)練時(shí), 由于模型參數(shù)在不斷更新, 各層輸入的概率分布在不斷變化, 因此必須使用較小的學(xué)習(xí)率和較好的參數(shù)初值, 導(dǎo)致網(wǎng)絡(luò)訓(xùn)練很慢, 同時(shí)也導(dǎo)致采用飽和的非線性激活函數(shù)(例如Sigmoid)時(shí)訓(xùn)練困難.為了解決這些問(wèn)題, 又出現(xiàn)了GoogLeNet的續(xù)作Inception-v2[66].它加入了批規(guī)范化(Batch normalization)處理, 將每一層的輸出都進(jìn)行規(guī)范化, 保持各層輸入的分布穩(wěn)定, 使得梯度受參數(shù)初值的影響減小.批規(guī)范化加快了網(wǎng)絡(luò)訓(xùn)練速度, 并且在一定程度上起到正則化的作用. Inception-v2在ILSVRC 2012圖像分類任務(wù)上的Top-5錯(cuò)誤率降低到4.8%.隨著Szegedy等研究GoogLeNet的深入, 網(wǎng)絡(luò)的復(fù)雜度也逐漸提高. Inception-v3[67]變得更加復(fù)雜, 它通過(guò)將大的濾波器拆解成若干個(gè)小的濾波器的堆疊, 在不降低網(wǎng)絡(luò)性能的基礎(chǔ)上, 增加了網(wǎng)絡(luò)的深度和非線性. Inception-v3在ILSVRC 2012圖像分類任務(wù)上的Top-5錯(cuò)誤率降低到3.5%.
2015年, He等[8]提出了深度高達(dá)上百層的殘差網(wǎng)絡(luò)ResNet, 網(wǎng)絡(luò)層數(shù)(152層)比以往任何成功的神經(jīng)網(wǎng)絡(luò)的層數(shù)多5倍以上, 在ImageNet測(cè)試集上的圖像分類錯(cuò)誤率低至3.57%. ResNet使用一種全新的殘差學(xué)習(xí)策略來(lái)指導(dǎo)網(wǎng)絡(luò)結(jié)構(gòu)的設(shè)計(jì), 重新定義了網(wǎng)絡(luò)中信息流動(dòng)的方式, 重構(gòu)了網(wǎng)絡(luò)學(xué)習(xí)的過(guò)程, 很好地解決了深度神經(jīng)網(wǎng)絡(luò)層數(shù)與錯(cuò)誤率之間的矛盾(即網(wǎng)絡(luò)達(dá)到一定層數(shù)后, 更深的網(wǎng)絡(luò)導(dǎo)致更高的訓(xùn)練和測(cè)試錯(cuò)誤率). ResNet具有很強(qiáng)的通用性, 不但在圖像分類任務(wù), 而且在ImageNet數(shù)據(jù)集的目標(biāo)檢測(cè)、目標(biāo)定位任務(wù)以及MS COCO數(shù)據(jù)集的目標(biāo)檢測(cè)和分割任務(wù)上都取得了當(dāng)時(shí)最好的競(jìng)賽成績(jī).此后, Szegedy等[65]通過(guò)將Inception結(jié)構(gòu)與ResNet結(jié)構(gòu)相結(jié)合, 提出了Inception-ResNet-v1和Inception-ResNet-v2兩種混合網(wǎng)絡(luò), 極大地加快了訓(xùn)練速度, 并且性能也有所提升.除了這種混合結(jié)構(gòu), 他們還設(shè)計(jì)了一個(gè)更深更優(yōu)化的Inception-v4網(wǎng)絡(luò), 單純依靠Inception結(jié)構(gòu), 達(dá)到與Inception-ResNet-v2相近的性能. Szegedy等[65]將3個(gè)Inception-ResNet-v2網(wǎng)絡(luò)和1個(gè)Inception-v4網(wǎng)絡(luò)相集成, 在ILSVRC 2012圖像分類任務(wù)上的Top-5錯(cuò)誤率降低到3.08%.
3.3 深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)中的應(yīng)用
深度學(xué)習(xí)技術(shù)的發(fā)展, 極大推動(dòng)了目標(biāo)視覺(jué)檢測(cè)研究.目標(biāo)檢測(cè)與圖像分類最主要的不同在于目標(biāo)檢測(cè)關(guān)注圖像的局部結(jié)構(gòu)信息, 而圖像分類關(guān)注圖像的全局表達(dá).與圖像分類一樣, 目標(biāo)檢測(cè)的輸入也是整幅圖像.目標(biāo)檢測(cè)和圖像分類在特征表示和分類器設(shè)計(jì)上有很大的相通性.
接下來(lái), 我們從基于區(qū)域建議的方法和無(wú)區(qū)域建議的方法兩方面來(lái)介紹深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)中的研究現(xiàn)狀.
3.3.1 基于區(qū)域建議(Proposal-based)的方法
Girshick等[44]提出的R-CNN (Region-based convolutional neural networks)方法, 是近年來(lái)基于深度學(xué)習(xí)的目標(biāo)檢測(cè)研究的重要參考方法. R-CNN將目標(biāo)區(qū)域建議(Region proposal)和CNN相結(jié)合, 在PASCAL VOC 2012上的檢測(cè)平均精度mAP (Mean average precision)達(dá)到53.3%, 比傳統(tǒng)方法有了明顯改進(jìn). R-CNN的基本流程如圖 5所示, 首先對(duì)每一幅輸入圖像, 采用選擇性搜索(Selective search)[6]來(lái)提取候選區(qū)域; 然后用CNN網(wǎng)絡(luò)從每個(gè)區(qū)域提取一個(gè)固定長(zhǎng)度的特征向量, 這里采用AlexNet[57]結(jié)構(gòu), 圖像經(jīng)過(guò)5個(gè)卷積層和2個(gè)全連接層, 得到一個(gè)4 096維的特征向量; 接著把提取到的特征向量送入支持向量機(jī)進(jìn)行分類.由于一些區(qū)域存在高度交疊, Girshick等采用非極大值抑制(Non-maximum suppression)來(lái)舍棄那些與更高得分區(qū)域的IoU (Intersection-over-Union)過(guò)大的區(qū)域.為了得到更精確的結(jié)果, 還采用了邊框回歸方法來(lái)進(jìn)一步改善檢測(cè)結(jié)果.在R-CNN模型的訓(xùn)練過(guò)程中, 由于目標(biāo)檢測(cè)標(biāo)注數(shù)據(jù)集的規(guī)模不夠, Girshick等先將網(wǎng)絡(luò)在大規(guī)模數(shù)據(jù)集ImageNet上進(jìn)行預(yù)訓(xùn)練, 然后用N+1 類(N個(gè)目標(biāo)類和1個(gè)背景類)的輸出層來(lái)替換1 000類的Softmax層, 再針對(duì)目標(biāo)檢測(cè)任務(wù), 用PASCAL VOC數(shù)據(jù)集進(jìn)行微調(diào).這種方法很好地解決了訓(xùn)練數(shù)據(jù)不足的問(wèn)題, 進(jìn)一步提升了檢測(cè)精度.得益于CNN的參數(shù)共享以及更低維度的特征, 整個(gè)檢測(cè)算法更加高效.但是, R-CNN也存在一些不容忽視的問(wèn)題: 1) 候選區(qū)域之間的交疊使得特征被重復(fù)提取, 造成了嚴(yán)重的速度瓶頸, 降低了計(jì)算效率; 2) 將候選區(qū)域直接縮放到固定大小, 破壞了物體的長(zhǎng)寬比, 可能導(dǎo)致物體的局部細(xì)節(jié)損失; 3) 使用邊框回歸有助于提高物體的定位精度, 但是如果待檢測(cè)物體存在遮擋, 該方法將難以奏效.
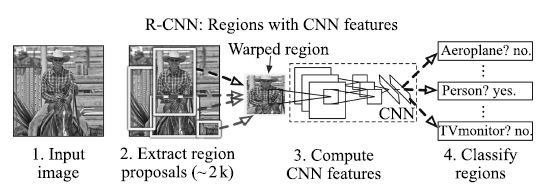
圖 5 R-CNN的計(jì)算流程[44]
Figure 5 Calculation flow of R-CNN[44]
He等[68]針對(duì)R-CNN速度慢{以及要求輸入圖像塊尺寸固定}的問(wèn)題, 提出空間金字塔池化(Spatial pyramid pooling, SPP)模型.在R-CNN中, 要將提取到的目標(biāo)候選區(qū)域變換到固定尺寸, 再輸入到卷積神經(jīng)網(wǎng)絡(luò), He等加入了一個(gè)空間金字塔池化層來(lái)避免了這個(gè)限制. SPP-net網(wǎng)絡(luò)不論輸入圖像的尺寸大小, 都能產(chǎn)生固定長(zhǎng)度的特征表示. SPP-net是對(duì)整幅圖像提取特征, 在最后一層卷積層得到特征圖后, 再針對(duì)每個(gè)候選區(qū)域在特征圖上進(jìn)行映射, 由此得到候選區(qū)域的特征.因?yàn)楹蜻x區(qū)域的尺寸各不相同, 導(dǎo)致它們映射所得到的特征圖大小也不同, 但CNN的全連接層需要固定維度的輸入, 因此引入了空間金字塔池化層來(lái)把特征轉(zhuǎn)換到相同的維度.空間金字塔池化的思想來(lái)源于空間金字塔模型(Spatial pyramid model, SPM)[43], 它采用多個(gè)尺度的池化來(lái)替代原來(lái)單一的池化. SPP層用不同大小的池化窗口作用于卷積得到的特征圖, 池化窗口的大小和步長(zhǎng)根據(jù)特征圖的尺寸進(jìn)行動(dòng)態(tài)計(jì)算. SPP-net對(duì)于一幅圖像的所有候選區(qū)域, 只需要進(jìn)行一次卷積過(guò)程,避免了重復(fù)計(jì)算, 顯著提高了計(jì)算效率, 而且空間金字塔池化層使得檢測(cè)網(wǎng)絡(luò)可以處理任意尺寸的圖像, 因此可以采用多尺度圖像來(lái)訓(xùn)練網(wǎng)絡(luò), 從而使得網(wǎng)絡(luò)對(duì)目標(biāo)的尺度有很好的魯棒性.該方法在速度上比R-CNN提高24 ~ 102倍, 并且在PASCAL VOC 2007和Caltech 101數(shù)據(jù)集上取得了當(dāng)時(shí)最好的成績(jī).但是它存在以下缺點(diǎn): 1) SPP-net的檢測(cè)過(guò)程是分階段的, 在提取特征后用SVM分類, 然后還要進(jìn)一步進(jìn)行邊框回歸, 這使得訓(xùn)練過(guò)程復(fù)雜化; 2) CNN提取的特征存儲(chǔ)需要的空間和時(shí)間開(kāi)銷大; 3) 在微調(diào)階段, SPP-net只能更新空間金字塔池化層后的全連接層, 而不能更新卷積層, 這限制了檢測(cè)性能的提升.
后來(lái), Girshick等[58]對(duì)R-CNN和SPP-net進(jìn)行了改進(jìn), 提出能夠?qū)崿F(xiàn)特征提取、區(qū)域分類和邊框回歸的端到端聯(lián)合訓(xùn)練的Fast R-CNN算法, 計(jì)算流程如圖 6所示.與R-CNN類似, Fast R-CNN首先在圖像中提取感興趣區(qū)域(Regions of Interest, RoI); 然后采用與SPP-net相似的處理方式, 對(duì)每幅圖像只進(jìn)行一次卷積, 在最后一個(gè)卷積層輸出的特征圖上對(duì)每個(gè)RoI進(jìn)行映射, 得到相應(yīng)的RoI的特征圖, 并送入RoI池化層(相當(dāng)于單層的SPP層, 通過(guò)該層把各尺寸的特征圖統(tǒng)一到相同的大小); 最后經(jīng)過(guò)全連接層得到兩個(gè)輸出向量, 一個(gè)進(jìn)行Softmax分類, 另一個(gè)進(jìn)行邊框回歸.在微調(diào)階段, Fast R-CNN采用一種新的層級(jí)采樣方法, 先采樣圖像, 再?gòu)牟蓸映龅膱D像中對(duì)RoI進(jìn)行采樣, 同一幅圖像的RoI共享計(jì)算和內(nèi)存, 使得訓(xùn)練更加高效. Fast R-CNN采用Softmax分類與邊框回歸一起進(jìn)行訓(xùn)練, 省去了特征存儲(chǔ), 提高了空間和時(shí)間利用率, 同時(shí)分類和回歸任務(wù)也可以共享卷積特征, 相互促進(jìn).與R-CNN相比, 在訓(xùn)練VGG網(wǎng)絡(luò)時(shí), Fast R-CNN的訓(xùn)練階段快9倍, 測(cè)試階段快213倍; 與SPP-net相比, Fast R-CNN的訓(xùn)練階段快3倍, 測(cè)試階段快10倍, 并且檢測(cè)精度有一定提高.然而, Fast R-CNN仍然存在速度上的瓶頸, 就是區(qū)域建議步驟耗費(fèi)了整個(gè)檢測(cè)過(guò)程的大量時(shí)間.
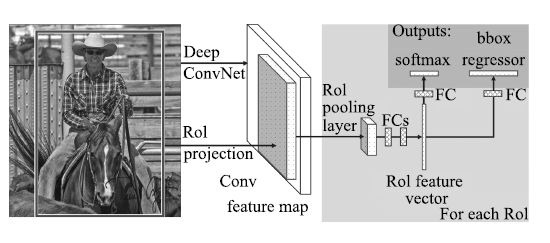
圖 6 Fast R-CNN的計(jì)算流程[58]
Figure 6 Calculation flow of Fast R-CNN[58]
為了解決區(qū)域建議步驟消耗大量計(jì)算資源, 導(dǎo)致目標(biāo)檢測(cè)不能實(shí)時(shí)的問(wèn)題, Ren等[7]提出區(qū)域建議網(wǎng)絡(luò)(Region proposal network, RPN), 并且把RPN和Fast R-CNN融合到一個(gè)統(tǒng)一的網(wǎng)絡(luò)(稱為Faster R-CNN), 共享卷積特征. RPN將一整幅圖像作為輸入, 輸出一系列的矩形候選區(qū)域.它是一個(gè)全卷積網(wǎng)絡(luò)模型, 通過(guò)在與Fast R-CNN共享卷積層的最后一層輸出的特征圖上滑動(dòng)一個(gè)小型網(wǎng)絡(luò), 這個(gè)網(wǎng)絡(luò)與特征圖上的小窗口全連接, 每個(gè)滑動(dòng)窗口映射到一個(gè)低維的特征向量, 再輸入給兩個(gè)并列的全連接層, 即分類層(cls layer)和邊框回歸層(reg layer), 由于網(wǎng)絡(luò)是以滑動(dòng)窗的形式來(lái)進(jìn)行操作, 所以全連接層的參數(shù)在所有空間位置是共享的.因此該結(jié)構(gòu)由一個(gè)卷積層后連接兩個(gè)并列的1×1卷積層實(shí)現(xiàn), 如圖 7所示.對(duì)于每個(gè)小窗口, 以中心點(diǎn)為基準(zhǔn)點(diǎn)選取k (作者采用k=9 )個(gè)不同尺度、不同長(zhǎng)寬比的Anchor.對(duì)于每個(gè)Anchor, 分類層輸出2個(gè)值, 分別表示其屬于目標(biāo)的概率與屬于背景的概率; 邊框回歸層輸出4個(gè)值, 表示其坐標(biāo)位置. RPN的提出, 以及與Fast R-CNN進(jìn)行卷積特征的共享, 使得區(qū)域建議步驟的計(jì)算代價(jià)很小.與以前的方法相比, 提取的候選區(qū)域數(shù)量大幅減少, 同時(shí)改進(jìn)了候選區(qū)域的質(zhì)量, 從而提高了整個(gè)目標(biāo)檢測(cè)網(wǎng)絡(luò)的性能, 幾乎可以做到實(shí)時(shí)檢測(cè).在PASCAL VOC 2007和2012、MS COCO等數(shù)據(jù)集上, Faster R-CNN取得了當(dāng)時(shí)最高的檢測(cè)精度.但是由于深度特征丟失了物體的細(xì)節(jié)信息, 造成定位性能差, Faster R-CNN對(duì)小尺寸物體的檢測(cè)效果不好.
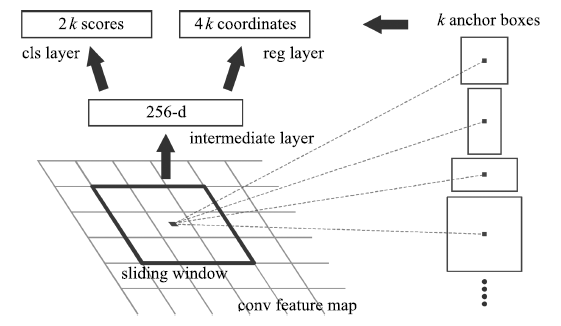
圖 7 區(qū)域建議網(wǎng)絡(luò)的基本結(jié)構(gòu)[7]
Figure 7 Basic structure of region proposal network[7]
Bell等[69]提出的ION (Inside-outside net)也是基于區(qū)域建議的目標(biāo)檢測(cè)方法.為了提高檢測(cè)精度, ION同時(shí)利用RoI的內(nèi)部和外部信息.其中內(nèi)部信息是指多尺度的信息提取.不同于以前的方法將最后一層卷積層輸出作為特征圖, Bell等將不同卷積層的特征連接在一起, 作為一個(gè)多尺度特征用來(lái)預(yù)測(cè), 這樣做的目的是對(duì)于一些很小的物體, 不會(huì)丟失在低層的高分辨率信息. RoI的外部信息是指上下文信息, 在視覺(jué)識(shí)別中上下文信息具有很重要的作用.為了得到上下文特征, Bell等采用沿著圖像的橫軸或縱軸獨(dú)立地使用RNN的方法, 并把它們的輸出組合在一起, 重復(fù)該過(guò)程得到的輸出作為上下文特征.最后把這兩種特征組合在一起, 并調(diào)整到固定的大小輸入到全連接層, 進(jìn)行Softmax分類和邊框回歸.該方法在檢測(cè)小物體上的性能比以前的方法更好, 在PASCAL VOC 2012目標(biāo)檢測(cè)任務(wù)上將平均精度mAP從73.9 %提高到76.4 %, 在MS COCO 2015目標(biāo)檢測(cè)任務(wù)上取得第3名的成績(jī).
Yang等[70]為了處理不同尺度的目標(biāo), 并且提高對(duì)候選區(qū)域的計(jì)算效率, 提出了兩個(gè)策略, 統(tǒng)稱為SDP-CRC.一個(gè)策略是采用與尺度相關(guān)的池化層(Scale-dependent pooling, SDP), 由于不同尺寸的物體可能在不同的卷積層上得到不同的響應(yīng), 小尺寸物體會(huì)在淺層得到強(qiáng)響應(yīng), 而大尺寸物體可能在深層得到強(qiáng)響應(yīng).基于這一思想, SDP根據(jù)每個(gè)候選區(qū)域的尺寸, 從對(duì)應(yīng)的卷積特征圖上池化特征.對(duì)于小尺度的候選區(qū)域, 從第三層卷積特征圖上池化特征; 對(duì)于中等尺度的候選區(qū)域, 從第四層卷積特征圖上池化特征; 對(duì)于大尺度的候選區(qū)域, 從第五層卷積特征圖上池化特征.另一個(gè)策略是采用級(jí)聯(lián)拒絕分類器(Cascaded rejection classifier, CRC), 快速排除一些明顯不包含目標(biāo)的候選區(qū)域, 只保留那些更可能包含目標(biāo)的候選區(qū)域, 交由Fast R-CNN做最終分類.與Fast R-CNN相比, 該方法能夠更加準(zhǔn)確地檢測(cè)小尺寸目標(biāo), 在平均檢測(cè)精度和檢測(cè)速度上都有很大提升.
為了提高Fast R-CNN訓(xùn)練時(shí)的效率, Shrivastava等[71]提出了困難樣本在線挖掘(Online hard example mining, OHEM)的思想, 該方法利用Bootstrapping[72]技術(shù), 對(duì)隨機(jī)梯度下降算法進(jìn)行修改, 使得在訓(xùn)練過(guò)程中加入在線挖掘困難樣本的策略. OHEM機(jī)制的加入提高了Fast R-CNN方法在PASCAL VOC 2007和2012上的檢測(cè)精度.
在Faster R-CNN基礎(chǔ)上, Kong等[73]提出了HyperNet, 計(jì)算流程如圖 8所示.通過(guò)把不同卷積層得到的特征圖像聚集起來(lái)得到超特征(Hyper feature)來(lái)獲得質(zhì)量更高的候選區(qū)域.由于不同卷積層的輸出尺寸不同, 較淺層的特征圖像分辨率較高, 邊框定位精度高, 但是召回率低; 較深層的特征圖像分辨率低, 對(duì)小尺寸物體的邊框定位精度低, 但是這些特征有利于提高召回率.因此, 他們通過(guò)多層特征的融合, 解決了對(duì)小物體很難提取到精細(xì)特征的問(wèn)題.該方法在每幅圖像中僅提取100個(gè)候選區(qū)域, 在PASCAL VOC 2007和2012數(shù)據(jù)集上獲得了很好的檢測(cè)效果.

圖 8 HyperNet的計(jì)算流程[73]
Figure 8 Calculation flow of HyperNet[73]
許多基于區(qū)域建議的目標(biāo)檢測(cè)方法存在一個(gè)共同問(wèn)題, 就是有一部分子網(wǎng)絡(luò)需要重復(fù)計(jì)算.例如最早提出的R-CNN, 每一個(gè)候選區(qū)域都要經(jīng)歷一次CNN網(wǎng)絡(luò)提取特征, 這導(dǎo)致目標(biāo)檢測(cè)速度非常慢.之后提出的Fast R-CNN和Faster R-CNN等方法, 在最后一個(gè)卷積層通過(guò)RoI pooling把每一個(gè)候選區(qū)域變成一個(gè)尺寸一致的特征圖, 但是對(duì)于每一個(gè)特征圖, 還要經(jīng)過(guò)若干次全連接層才能得到結(jié)果.于是, Dai等[74]提出了一種新的基于區(qū)域的全卷積網(wǎng)絡(luò)檢測(cè)方法R-FCN.為了給網(wǎng)絡(luò)引入平移變化, 用專門的卷積層構(gòu)建位置敏感的分?jǐn)?shù)圖(Position-sensitive score maps), 編碼感興趣區(qū)域的相對(duì)空間位置信息.該網(wǎng)絡(luò)解決了Faster R-CNN由于重復(fù)計(jì)算全連接層而導(dǎo)致的耗時(shí)問(wèn)題, 實(shí)現(xiàn)了讓整個(gè)網(wǎng)絡(luò)中所有的計(jì)算都可以共享.
最近, Kim等[75]提出PVANET網(wǎng)絡(luò), 在TITAN X上實(shí)現(xiàn)了基于輕量級(jí)模型的目標(biāo)檢測(cè), 處理一幅圖像僅需要46 ms, 在PASCAL VOC 2012數(shù)據(jù)集上的檢測(cè)平均精度達(dá)到82.5 %.為了減少網(wǎng)絡(luò)參數(shù), PVANET采用了Concatenated ReLU[76]結(jié)構(gòu), 在不損失精度的情況下使通道數(shù)減少一半, 并在拼接操作之后加入了尺度變化和偏移.網(wǎng)絡(luò)中還加入了Inception[64]模型來(lái)更有效地捕捉各種尺度的物體, 以及HyperNet[73]中多尺度特征融合的思想, 來(lái)增加對(duì)細(xì)節(jié)的提取.
3.3.2 無(wú)區(qū)域建議(Proposal-free)的方法
基于區(qū)域建議的目標(biāo)檢測(cè)方法不能利用局部目標(biāo)在整幅圖像中的空間信息, 所以一些研究者開(kāi)展了無(wú)區(qū)域建議的目標(biāo)檢測(cè)研究, 主要采用回歸的思想.早期提出的無(wú)區(qū)域建議的方法, 檢測(cè)效果不太理想.
DPM模型[2]是一種性能較好的傳統(tǒng)目標(biāo)檢測(cè)模型.它對(duì)目標(biāo)內(nèi)在部件進(jìn)行結(jié)構(gòu)化建模, 可以更好地適應(yīng)非剛體目標(biāo)的較大形變, 大大提高了檢測(cè)性能.但是DPM模型的構(gòu)建需要關(guān)于物體結(jié)構(gòu)的先驗(yàn)知識(shí)(例如部件個(gè)數(shù)), 并且模型訓(xùn)練也比較復(fù)雜. Szegedy等[1]將目標(biāo)檢測(cè)看做一個(gè)回歸問(wèn)題, 估計(jì)圖像中的目標(biāo)位置和目標(biāo)類型概率.作者通過(guò)采用基于深度神經(jīng)網(wǎng)絡(luò)(Deep neural network, DNN)的回歸來(lái)輸出目標(biāo)包圍窗口的二元掩膜(Mask), 從掩膜中提取目標(biāo)窗口.該方法的運(yùn)行框架如圖 9所示, 網(wǎng)絡(luò)中采用的卷積神經(jīng)網(wǎng)絡(luò)是AlexNet結(jié)構(gòu), 但是用回歸層代替最后一層.基于DNN的回歸不僅能學(xué)習(xí)到有利于分類的特征表示, 還能捕獲到很強(qiáng)的目標(biāo)幾何信息, Szegedy等還采用DNN定位器進(jìn)一步提高了定位準(zhǔn)確度.由于用單一的掩膜很難區(qū)分出識(shí)別的前景是單個(gè)物體還是粘連的多個(gè)物體, 作者采用了多個(gè)掩膜, 為每種掩膜訓(xùn)練一個(gè)單獨(dú)的DNN, 這也使得網(wǎng)絡(luò)訓(xùn)練復(fù)雜度很高, 很難擴(kuò)展到多種目標(biāo)類型.
圖 9 基于DNN回歸的目標(biāo)檢測(cè)框架[1]
Figure 9 Object detection framework based on DNN regression[1]
Sermanet等[77]提出Overfeat模型, 把一個(gè)卷積神經(jīng)網(wǎng)絡(luò)同時(shí)用于分類、定位和檢測(cè)這幾個(gè)不同的任務(wù).卷積層作為特征提取層保持不變, 只需要針對(duì)不同的任務(wù)改變網(wǎng)絡(luò)的最后幾層為分類或回歸層. Overfeat的模型結(jié)構(gòu)與AlexNet結(jié)構(gòu)[57]基本相同.其中, 前面5個(gè)卷積層為不同任務(wù)的共享層, 其余的層則根據(jù)任務(wù)進(jìn)行相應(yīng)的調(diào)整, 并對(duì)網(wǎng)絡(luò)做了一些改動(dòng).為了避免圖像的某些位置被忽略, Sermanet等采用偏置池化層來(lái)替換最后一層池化層, 既實(shí)現(xiàn)了池化操作, 也減小了采樣間隔. Overfeat訓(xùn)練分類模型時(shí)只使用單個(gè)尺度(221×221 )進(jìn)行訓(xùn)練, 測(cè)試時(shí)使用多個(gè)尺度輸入圖像, 沒(méi)有使用AlexNet中的對(duì)比歸一化.對(duì)于檢測(cè)問(wèn)題, 傳統(tǒng)的方法是采用不同尺寸的滑動(dòng)窗對(duì)整幅圖像進(jìn)行密集采樣, 然后對(duì)每一個(gè)采樣所得的圖像塊進(jìn)行檢測(cè), 從而確定目標(biāo)物體的位置. Overfeat使用CNN來(lái)進(jìn)行滑動(dòng)窗操作, 避免了對(duì)各圖像塊的單獨(dú)操作, 提高了算法效率; 而且將全連接層看作卷積層, 使得輸入圖像的尺寸不受限制.但是Overfeat對(duì)于較小尺寸目標(biāo)的識(shí)別依然存在困難.
近年來(lái), Redmon等[78]提出了一種新的無(wú)區(qū)域建議的目標(biāo)檢測(cè)方法, 稱為YOLO (You only look once).作為一種統(tǒng)一的、實(shí)時(shí)的檢測(cè)框架, YOLO的檢測(cè)速度非常快, 可以達(dá)到45 fps (Frame per second). YOLO用一個(gè)單一的卷積網(wǎng)絡(luò)直接基于整幅圖像來(lái)預(yù)測(cè)包圍邊框的位置及所屬類型, 首先將一幅圖像分成S×S 個(gè)網(wǎng)格,每個(gè)網(wǎng)格要預(yù)測(cè)B個(gè)邊框, 每個(gè)邊框除了要回歸自身的位置之外, 還要附帶預(yù)測(cè)一個(gè)置信度.置信度不僅反映了包含目標(biāo)的可信程度, 也反映了預(yù)測(cè)位置的準(zhǔn)確度.另外對(duì)每個(gè)網(wǎng)格還要預(yù)測(cè)C個(gè)類型的條件概率, 將這些預(yù)測(cè)結(jié)果編碼為一個(gè)S×S×(B×5+C)維的張量(Tensor).整個(gè)網(wǎng)絡(luò)的結(jié)構(gòu)類似于GoogLeNet, 包含24個(gè)卷積層和2個(gè)全連接層, 卷積層用來(lái)從圖像中提取特征, 全連接層預(yù)測(cè)邊框的位置坐標(biāo)和類型概率. YOLO模型通過(guò)采用空間限制, 減少了對(duì)同一目標(biāo)的重復(fù)檢測(cè), 大大提高了效率, 能夠達(dá)到實(shí)時(shí)的效果.但是YOLO的整體性能不如Fast R-CNN和Faster R-CNN, 并且對(duì)于相鄰的目標(biāo)和成群的小尺寸目標(biāo)(例如成群的鳥(niǎo))的檢測(cè)效果不好, 對(duì)于新的或異常尺度的目標(biāo)泛化能力較差.
與YOLO類似, Najibi等[79]提出的G-CNN模型也著重于檢測(cè)速度的提升.該方法將目標(biāo)檢測(cè)模型轉(zhuǎn)化為迭代回歸問(wèn)題, 通過(guò)對(duì)整個(gè)圖像進(jìn)行不同尺度的網(wǎng)格劃分得到初始檢測(cè)框, 然后采用分段回歸模型多次迭代, 不斷提高邊框準(zhǔn)確度. G-CNN使用了約180個(gè)初始邊框, 經(jīng)過(guò)5次迭代達(dá)到與Fast R-CNN相當(dāng)?shù)臋z測(cè)精度,但是計(jì)算速度比Fast R-CNN快5倍.
針對(duì)YOLO存在的不足, Liu等[80]提出SSD模型, 在提高mAP的同時(shí)兼顧實(shí)時(shí)性的要求. SSD使用卷積神經(jīng)網(wǎng)絡(luò)對(duì)圖像進(jìn)行卷積后, 在不同層次的特征圖上生成一系列不同尺寸和長(zhǎng)寬比的邊框.在測(cè)試階段, 該網(wǎng)絡(luò)對(duì)每一個(gè)邊框中分別包含各個(gè)類型的物體的可能性進(jìn)行預(yù)測(cè), 并且調(diào)整邊框來(lái)適應(yīng)目標(biāo)物體的形狀.在PASCAL VOC、MS COCO和ILSVRC數(shù)據(jù)集上的實(shí)驗(yàn)顯示, SSD在保證精度的同時(shí), 其速度要比用候選區(qū)域的方法快很多.與YOLO相比, 即使是在輸入圖像較小的情況下, SSD也能取得更高的精度.例如輸入300×300 尺寸的PASCAL VOC 2007測(cè)試圖像, 在單臺(tái)Nvidia Titan X上的處理速度達(dá)到58 fps, 平均精度mAP達(dá)到72.1%;如果輸入圖像尺寸為500×500 , 平均精度mAP達(dá)到75.1%.
與基于候選區(qū)域的方法相比, YOLO定位準(zhǔn)確率低且召回率不高.因此, Redmon等[81]提出了改進(jìn)的YOLO模型, 記作YOLOv2, 主要目標(biāo)是在保持分類準(zhǔn)確率的同時(shí)提高召回率和定位準(zhǔn)確度.通過(guò)采用多尺度訓(xùn)練、批規(guī)范化和高分辨率分類器等多種策略, 提升了檢測(cè)準(zhǔn)確率的同時(shí)速度超過(guò)其他檢測(cè)方法, 例如Faster R-CNN和SSD. Redmon等還提出了一種新的聯(lián)合訓(xùn)練算法, 同時(shí)在檢測(cè)數(shù)據(jù)集和分類數(shù)據(jù)集上訓(xùn)練物體檢測(cè)器, 用檢測(cè)數(shù)據(jù)集的數(shù)據(jù)學(xué)習(xí)物體的準(zhǔn)確位置, 用分類數(shù)據(jù)集的數(shù)據(jù)增加分類的類別量, 提升健壯性,采用這種方法訓(xùn)練出來(lái)的YOLO9000模型可以實(shí)時(shí)地檢測(cè)超過(guò)9 000種物體分類.
3.3.3 總結(jié)
基于區(qū)域建議的目標(biāo)檢測(cè)方法, 特別是R-CNN系列方法(包括R-CNN、SPPnet、Fast R-CNN和Faster R-CNN等), 取得了非常好的檢測(cè)精度, 但是在速度方面還達(dá)不到實(shí)時(shí)檢測(cè)的要求.在不損失精度的情況下實(shí)現(xiàn)實(shí)時(shí)檢測(cè), 或者在提高檢測(cè)精度的同時(shí)兼顧速度, 逐漸成為目標(biāo)檢測(cè)的研究趨勢(shì). R-FCN比Faster R-CNN計(jì)算效率更高, 在檢測(cè)精度和速度上平衡的很好. PVANET是一種輕量級(jí)的網(wǎng)絡(luò)結(jié)構(gòu), 通過(guò)調(diào)整和結(jié)合最新的技術(shù)達(dá)到最小化計(jì)算資源的目標(biāo).無(wú)區(qū)域建議的方法(例如YOLO)雖然能夠達(dá)到實(shí)時(shí)的效果, 但是其檢測(cè)精度與Faster R-CNN相比有很大的差距. SSD對(duì)YOLO進(jìn)行了改進(jìn), 同時(shí)兼顧檢測(cè)精度和實(shí)時(shí)性的要求, 在滿足實(shí)時(shí)性的條件下, 縮小了與Faster R-CNN檢測(cè)精度的差距. YOLOv2在檢測(cè)精度和速度上都超過(guò)了SSD.一些目標(biāo)視覺(jué)檢測(cè)方法在公共數(shù)據(jù)集上的性能對(duì)比如圖 10所示.

圖 10 一些目標(biāo)視覺(jué)檢測(cè)方法在公共數(shù)據(jù)集上的性能比較
Figure 10 Performance comparison of some object visual detection methods on public datasets
4 思考與展望
近年來(lái), 由于深度學(xué)習(xí)技術(shù)的迅猛發(fā)展和應(yīng)用, 目標(biāo)視覺(jué)檢測(cè)研究取得了很大進(jìn)展.未來(lái)若干年, 基于深度學(xué)習(xí)的目標(biāo)視覺(jué)檢測(cè)研究仍然是該領(lǐng)域的主流研究方向.不同于傳統(tǒng)方法利用手工設(shè)計(jì)的特征, 可能忽視掉一些重要的特征信息, 深度學(xué)習(xí)方法可以通過(guò)端到端訓(xùn)練自動(dòng)學(xué)習(xí)與任務(wù)相關(guān)的特征, 通過(guò)多層的非線性變換獲得圖像的高層次抽象表示.盡管深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)領(lǐng)域取得了一定成功, 但是還存在一些問(wèn)題:
1) 深度學(xué)習(xí)理論還不完善
深度學(xué)習(xí)的優(yōu)勢(shì)之一是能夠自動(dòng)學(xué)習(xí)表達(dá)能力強(qiáng)的抽象特征, 不需要由專家手工進(jìn)行特征設(shè)計(jì)和選擇.但是, 將深度學(xué)習(xí)模型應(yīng)用于目標(biāo)檢測(cè)時(shí)還缺乏足夠的理論支撐, 學(xué)習(xí)到的模型的可解釋性較弱.目前的研究通常是把深度學(xué)習(xí)模型當(dāng)作一個(gè)黑盒子(Black box)來(lái)直接使用, 對(duì)于如何選擇和構(gòu)建模型、如何確定模型的深度以及深度學(xué)習(xí)的本質(zhì)等基本問(wèn)題還沒(méi)有給出很好的解釋.理論的不完善導(dǎo)致研究時(shí)缺乏充分的原理性指導(dǎo), 在設(shè)計(jì)新的模型時(shí)往往只能憑借經(jīng)驗(yàn)和運(yùn)氣. Pepik等[82]利用Pascal 3D+[83]數(shù)據(jù)集對(duì)R-CNN方法進(jìn)行分析, 結(jié)果表明卷積神經(jīng)網(wǎng)絡(luò)對(duì)于場(chǎng)景和目標(biāo)的各種外觀因素的變化不具有視覺(jué)不變性, 目前大多數(shù)深度學(xué)習(xí)方法在處理多目標(biāo)遮擋和小尺寸目標(biāo)等困難問(wèn)題時(shí)效果還不是很好, 增加額外的訓(xùn)練數(shù)據(jù)并不能克服這些缺陷, 有必要對(duì)模型結(jié)構(gòu)做出改變.因此必須進(jìn)一步完善深度學(xué)習(xí)理論, 為改進(jìn)模型結(jié)構(gòu)、加速模型訓(xùn)練和提高檢測(cè)效果等提供指導(dǎo).
2) 大規(guī)模多樣性數(shù)據(jù)集還很缺乏
深度學(xué)習(xí)模型主要是數(shù)據(jù)驅(qū)動(dòng)的, 依賴于大規(guī)模多樣性的標(biāo)記數(shù)據(jù)集.對(duì)一個(gè)特定的任務(wù), 增加訓(xùn)練數(shù)據(jù)的規(guī)模和多樣性, 可以提高深度學(xué)習(xí)模型的泛化能力, 避免過(guò)擬合.但是目前缺乏可用于目標(biāo)檢測(cè)的大規(guī)模多樣性數(shù)據(jù)集, 即便是最大的公共數(shù)據(jù)集也只提供了很有限的標(biāo)記類型, 比如PASCAL VOC有20個(gè)類型, MS COCO有80個(gè)類型, ImageNet有1 000個(gè)類型.由人工采集和標(biāo)注含有大量目標(biāo)類型的大規(guī)模多樣性數(shù)據(jù)集非常費(fèi)時(shí)耗力, 并且由于光照、天氣、復(fù)雜背景、目標(biāo)外觀、攝像機(jī)視角和物體遮擋等導(dǎo)致的復(fù)雜性和挑戰(zhàn)性, 同一類型目標(biāo)在不同圖像中可能看起來(lái)非常不同, 使得人工標(biāo)注變得困難甚至容易出錯(cuò).雖然可以采用眾包方法(例如Amazon MTurk[84])進(jìn)行數(shù)據(jù)標(biāo)注, 但是同樣要耗費(fèi)大量的人力財(cái)力, 并且標(biāo)注困難.另外在一些特殊領(lǐng)域(例如在醫(yī)療和軍事等領(lǐng)域)很難獲得大規(guī)模實(shí)際圖像.標(biāo)記數(shù)據(jù)集的不足, 可能導(dǎo)致訓(xùn)練出的目標(biāo)檢測(cè)模型的可靠性和魯棒性達(dá)不到要求.目前許多目標(biāo)檢測(cè)模型都采用先在ImageNet數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練, 再針對(duì)具體任務(wù)進(jìn)行微調(diào)的方式.如果針對(duì)具體的目標(biāo)檢測(cè)任務(wù), 有大規(guī)模多樣性的標(biāo)記數(shù)據(jù)集可供使用, 那么目標(biāo)檢測(cè)效果可以得到進(jìn)一步提高.
為了解決上述問(wèn)題, 我們認(rèn)為可以采用平行視覺(jué)[85-86]的思路進(jìn)行研究. 2016年, 王坤峰等[85]將復(fù)雜系統(tǒng)建模與調(diào)控的ACP (Artificial societies, computational experiments, and parallel execution)理論[87-89]推廣到視覺(jué)計(jì)算領(lǐng)域, 提出平行視覺(jué)的基本框架和關(guān)鍵技術(shù).其核心是利用人工場(chǎng)景來(lái)模擬和表示復(fù)雜挑戰(zhàn)的實(shí)際場(chǎng)景, 通過(guò)計(jì)算實(shí)驗(yàn)進(jìn)行各種視覺(jué)模型的設(shè)計(jì)與評(píng)估, 最后借助平行執(zhí)行來(lái)在線優(yōu)化視覺(jué)系統(tǒng), 實(shí)現(xiàn)對(duì)復(fù)雜環(huán)境的智能感知與理解. 圖 11顯示了平行視覺(jué)的基本框架.為了解決復(fù)雜環(huán)境下的目標(biāo)視覺(jué)檢測(cè)問(wèn)題, 我們可以按照平行視覺(jué)的ACP三步曲開(kāi)展研究.
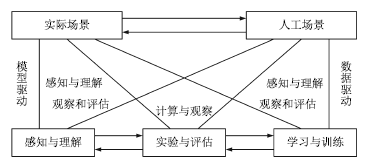
圖 11 平行視覺(jué)的基本框架[85]
Figure 11 Basic framework of parallel vision[85]
1) 人工場(chǎng)景(Artificial scenes)
構(gòu)建色彩逼真的人工場(chǎng)景, 模擬實(shí)際場(chǎng)景中可能出現(xiàn)的環(huán)境條件, 自動(dòng)得到精確的目標(biāo)位置、尺寸和類型等標(biāo)注信息, 生成大規(guī)模多樣性數(shù)據(jù)集.另外, 實(shí)際場(chǎng)景通常不可重復(fù), 而人工場(chǎng)景具有可重復(fù)性, 通過(guò)固定一些物理模型和參數(shù), 改變另外一些, 可以定制圖像生成要素, 以便從各種角度評(píng)價(jià)視覺(jué)算法.人工場(chǎng)景可以不受現(xiàn)有實(shí)際場(chǎng)景的限制, 預(yù)見(jiàn)未來(lái)的實(shí)際場(chǎng)景, 為視覺(jué)算法設(shè)計(jì)與評(píng)估提供超前信息.總之, 人工場(chǎng)景能夠提供一種可靠的數(shù)據(jù)來(lái)源, 是對(duì)實(shí)際場(chǎng)景數(shù)據(jù)的有效補(bǔ)充.
2) 計(jì)算實(shí)驗(yàn)(Computational experiments)
結(jié)合人工場(chǎng)景數(shù)據(jù)集和實(shí)際場(chǎng)景數(shù)據(jù)集, 進(jìn)行全面充分的計(jì)算實(shí)驗(yàn), 把計(jì)算機(jī)變成視覺(jué)計(jì)算實(shí)驗(yàn)室, 設(shè)計(jì)和評(píng)價(jià)視覺(jué)算法, 提高其在復(fù)雜環(huán)境下的性能.與基于實(shí)際場(chǎng)景的實(shí)驗(yàn)相比, 在人工場(chǎng)景中實(shí)驗(yàn)過(guò)程可控、可觀、可重復(fù), 并且可以真正地產(chǎn)生實(shí)驗(yàn)大數(shù)據(jù), 用于知識(shí)提取和算法優(yōu)化.計(jì)算實(shí)驗(yàn)包含兩種操作模式, 即學(xué)習(xí)與訓(xùn)練、實(shí)驗(yàn)與評(píng)估.學(xué)習(xí)與訓(xùn)練是針對(duì)視覺(jué)算法設(shè)計(jì)而言, 實(shí)驗(yàn)與評(píng)估是針對(duì)視覺(jué)算法評(píng)價(jià)而言.兩種操作模式都需要結(jié)合人工場(chǎng)景數(shù)據(jù)集和實(shí)際場(chǎng)景數(shù)據(jù)集, 能夠增加實(shí)驗(yàn)的深度和廣度.
3) 平行執(zhí)行(Parallel execution)
將視覺(jué)算法在實(shí)際場(chǎng)景與人工場(chǎng)景中平行執(zhí)行, 使模型訓(xùn)練和評(píng)估在線化、長(zhǎng)期化, 通過(guò)實(shí)際與人工之間的虛實(shí)互動(dòng), 持續(xù)優(yōu)化視覺(jué)系統(tǒng).由于應(yīng)用環(huán)境的復(fù)雜性、挑戰(zhàn)性和變化性, 不存在一勞永逸的解決方案,只能接受這些困難, 在系統(tǒng)運(yùn)行過(guò)程中不斷調(diào)節(jié)和改善.平行執(zhí)行基于物理和網(wǎng)絡(luò)空間的大數(shù)據(jù), 以人工場(chǎng)景的在線構(gòu)建和利用為主要手段, 通過(guò)在線自舉(Online bootstrapping)或困難實(shí)例挖掘(Hard example mining), 自動(dòng)挖掘?qū)е乱曈X(jué)算法失敗或性能不佳的實(shí)例, 利用它們重新調(diào)節(jié)視覺(jué)算法和系統(tǒng), 提高對(duì)動(dòng)態(tài)變化環(huán)境的自適應(yīng)能力.
目前, 已經(jīng)有一些工作基于人工場(chǎng)景數(shù)據(jù)進(jìn)行目標(biāo)檢測(cè)模型的訓(xùn)練.例如, Peng等[90]利用3D CAD模型自動(dòng)合成2D圖像, 使用這種虛擬圖像數(shù)據(jù)來(lái)擴(kuò)大深度卷積神經(jīng)網(wǎng)絡(luò)的訓(xùn)練集非常有效, 尤其是在真實(shí)的訓(xùn)練數(shù)據(jù)很有限或不能很好地匹配目標(biāo)領(lǐng)域的情況下, 避免了代價(jià)昂貴的大規(guī)模手工標(biāo)注. Johnson-Roberson等[91]利用游戲引擎生成逼真的虛擬圖像, 用于目標(biāo)檢測(cè)模型的訓(xùn)練.實(shí)驗(yàn)表明, 在KITTI數(shù)據(jù)集上, 使用大規(guī)模的虛擬圖像集訓(xùn)練的模型比基于較小規(guī)模的真實(shí)世界數(shù)據(jù)集訓(xùn)練的檢測(cè)器精度更高.但是, 已有的工作主要集中在人工場(chǎng)景和計(jì)算實(shí)驗(yàn), 忽視了平行執(zhí)行.我們認(rèn)為, 將視覺(jué)算法在實(shí)際場(chǎng)景與人工場(chǎng)景中平行執(zhí)行,持續(xù)優(yōu)化視覺(jué)系統(tǒng), 提高其在復(fù)雜環(huán)境下的魯棒性和適應(yīng)性是非常重要的.
許多機(jī)器學(xué)習(xí)算法假設(shè)訓(xùn)練數(shù)據(jù)與測(cè)試數(shù)據(jù)具有相同的數(shù)據(jù)分布以及特征空間[92], 然而使用ACP時(shí)會(huì)遇到虛擬數(shù)據(jù)與真實(shí)數(shù)據(jù)的分布差異問(wèn)題.遷移學(xué)習(xí)[93]能夠很好解決分布差異問(wèn)題.通過(guò)遷移學(xué)習(xí), 我們能夠運(yùn)用ACP中人工模擬出的虛擬數(shù)據(jù)來(lái)不斷提高模型的精準(zhǔn)度與魯棒性.
另外, 在深度學(xué)習(xí)模型自身方面, 如何提高模型的可解釋性, 改善模型結(jié)構(gòu), 設(shè)計(jì)新的優(yōu)化方法, 降低模型訓(xùn)練和應(yīng)用時(shí)的計(jì)算復(fù)雜性, 提高計(jì)算效率, 得到更加有用(More effective)和更加有效的(More efficient)深度學(xué)習(xí)模型, 這些問(wèn)題都需要深入研究.目前, 基于候選區(qū)域的目標(biāo)檢測(cè)方法精度最高, 而基于回歸的SSD方法在實(shí)時(shí)性上表現(xiàn)最好, 如何將這兩類方法相結(jié)合, 借鑒和吸收彼此的優(yōu)點(diǎn), 在檢測(cè)精度和速度上取得新的突破還有待研究.
5 結(jié)論
目標(biāo)視覺(jué)檢測(cè)在計(jì)算機(jī)視覺(jué)領(lǐng)域具有重要的研究意義和應(yīng)用價(jià)值, 深度學(xué)習(xí)是目前最熱門的機(jī)器學(xué)習(xí)方法, 被廣泛研究和應(yīng)用.本文綜述了深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)中的應(yīng)用進(jìn)展與展望.首先說(shuō)明了目標(biāo)視覺(jué)檢測(cè)的基本流程和常用的公共數(shù)據(jù)集, 然后重點(diǎn)介紹了深度學(xué)習(xí)方法在目標(biāo)視覺(jué)檢測(cè)中的最新應(yīng)用進(jìn)展, 最后對(duì)深度學(xué)習(xí)在目標(biāo)視覺(jué)檢測(cè)研究中的困難和挑戰(zhàn)進(jìn)行了分析, 對(duì)未來(lái)的發(fā)展趨勢(shì)進(jìn)行了思考與展望.
在今后的工作中, 還需要進(jìn)一步完善深度學(xué)習(xí)理論, 提高目標(biāo)視覺(jué)檢測(cè)的精度和效率.另外, 平行視覺(jué)作為一種新的智能視覺(jué)計(jì)算方法學(xué), 通過(guò)人工場(chǎng)景提供大規(guī)模多樣性的標(biāo)記數(shù)據(jù)集, 通過(guò)計(jì)算實(shí)驗(yàn)全面設(shè)計(jì)和評(píng)價(jià)目標(biāo)視覺(jué)檢測(cè)方法, 通過(guò)平行執(zhí)行在線優(yōu)化視覺(jué)系統(tǒng), 能夠激發(fā)深度學(xué)習(xí)的潛力.我們相信, 深度學(xué)習(xí)與平行視覺(jué)相結(jié)合, 必將大力推動(dòng)目標(biāo)視覺(jué)檢測(cè)的研究和應(yīng)用進(jìn)展.
參考文獻(xiàn)
1 Szegedy C, Toshev A, Erhan D. Deep neural networks for object detection. In: Proceedings of the 2013 Advances in Neural Information Processing Systems (NIPS). Harrahs and Harveys, Lake Tahoe, USA: MIT Press, 2013, 2553-2561.
2 Felzenszwalb P F, Girshick R B, McAllester D, Ramanan D. Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
3 Huang Kai-Qi, Ren Wei-Qiang, Tan Tie-Niu. A review on image object classification and detection. Chinese Journal of Computers, 2014, 37(6): 1225-1240.
( 黃凱奇, 任偉強(qiáng), 譚鐵牛. 圖像物體分類與檢測(cè)算法綜述. 計(jì)算機(jī)學(xué)報(bào), 2014, 37(6): 1225-1240.)
4 Zhang X, Yang Y H, Han Z G, Wang H, Gao C. Object class detection: a survey. ACM Computing Surveys (CSUR), 2013, 46(1): Article No. 10.
5 Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). San Diego, CA, USA: IEEE, 2005, 1:886-893
6 Uijlings J R R, van de Sande K E A, Gevers T, Smeulders A W M. Selective search for object recognition. International Journal of Computer Vision, 2013, 104(2): 154-171.
7 Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
8 He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, Nevada, USA: IEEE, 2016. 770-778
9 Lampert C H, Blaschko M B, Hofmann T. Beyond sliding windows: object localization by efficient subwindow search. In: Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Anchorage, Alaska, USA: IEEE, 2008. 1-8
10 An S J, Peursum P, Liu W Q, Venkatesh S. Efficient algorithms for subwindow search in object detection and localization. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Miami, Florida, USA: IEEE, 2009. 264-271
11 Wei Y C, Tao L T. Efficient histogram-based sliding window. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). San Francisco, CA, USA: IEEE, 2010. 3003-3010
12 Van de Sande K E A, Uijlings J R R, Gevers T, Smeulders A W M. Segmentation as selective search for object recognition. In: Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV). Barcelona, Spain: IEEE, 2011. 1879-1886
13 Shotton J, Blake A, Cipolla R. Multiscale categorical object recognition using contour fragments. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(7): 1270-1281.
14 Leibe B, Leonardis A, Schiele B. Robust object detection with interleaved categorization and segmentation. International Journal of Computer Vision, 2008, 77(1-3): 259-289.
15 Arbelaez P, Maire M, Fowlkes C, Malik J. Contour detection and hierarchical image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(5): 898-916.
16 Shotton J, Winn J, Rother C, Criminisi A. TextonBoost: joint appearance, shape and context modeling for multi-class object recognition and segmentation. In: Proceedings of the 9th European Conference on Computer Vision (ECCV). Berlin, Heidelberg, Germany: Springer, 2006. 1-15
17 Verbeek J, Triggs B. Region classification with Markov field aspect models. In: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Minneapolis, Minnesota, USA: IEEE, 2007. 1-8
18 Cheng M M, Zhang Z M, Lin W Y, Torr P. BING: binarized normed gradients for objectness estimation at 300fps. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, USA: IEEE, 2014. 3286-3293
19 Zitnick C L, Dollár P. Edge boxes:locating object proposals from edges. In: Proceedings of the 13th European Conference on Computer Vision (ECCV). Zurich, Switzerland:Springer, 2014. 391-405
20 Hosang J, Benenson R, Schiele B. How good are detection proposals, really? arXiv:1406.6962, 2014.
21 Szegedy C, Reed S, Erhan D, Anguelov D, Ioffe S. Scalable, high-quality object detection. arXiv:1412.1441, 2014.
22 Erhan D, Szegedy C, Toshev A, Anguelov D. Scalable object detection using deep neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, Ohio, USA: IEEE, 2014. 2155-2162
23 Kuo W C, Hariharan B, Malik J. Deepbox: learning objectness with convolutional networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 2479-2487
24 Ghodrati A, Diba A, Pedersoli M, Tuytelaars T, Van Gool L. Deepproposal: hunting objects by cascading deep convolutional layers. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 2578-2586
25 Gidaris S, Komodakis N. Locnet: improving localization accuracy for object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 789-798
26 Lawrence G R. Machine Perception of Three-dimensional Solids[Ph.D. dissertation], Massachusetts Institute of Technology, USA, 1963.
27 Canny J. A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986, PAMI-8(6): 679-698.
28 Marr D, Hildreth E. Theory of edge detection. Proceedings of the Royal Society B: Biological Sciences, 1980, 207(1167): 187-217.
29 Pellegrino F A, Vanzella W, Torre V. Edge detection revisited. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2004, 34(3): 1500-1518.
30 Harris C, Stephens M. A combined corner and edge detector. In: Proceedings of the 4th Alvey Vision Conference. Manchester, UK: University of Sheffield Printing Unit, 1988. 147-151
31 Rosten E, Porter R, Drummond T. Faster and better: a machine learning approach to corner detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(1): 105-119.
32 Lowe D G. Object recognition from local scale-invariant features. In: Proceedings of the 7th IEEE International Conference on Computer Vision (ICCV). Kerkyra, Greece: IEEE, 1999, 2:1150-1157
33 Lowe D G. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004, 60(2): 91-110.
34 Papageorgiou C P, Oren M, Poggio T. A general framework for object detection. In: Proceedings of the 6th International Conference on Computer Vision (ICCV). Bombay, India: IEEE, 1998. 555-562
35 Ojala T, Pietikäinen M, Harwood D. Performance evaluation of texture measures with classification based on Kullback discrimination of distributions. In: Proceedings of the 12th IAPR International Conference on Pattern Recognition, Conference A: Computer Vision and Image Processing. Jerusalem, Israel, Palestine: IEEE, 1994, 1:582-585
36 Ojala T, Pietikäinen M, Harwood D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognition, 1996, 29(1): 51-59.
37 Yan J J, Lei Z, Yi D, Li S Z. Multi-pedestrian detection in crowded scenes: a global view. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, Rhode Island, USA: IEEE, 2012. 3124-3129
38 Yan J J, Zhang X C, Lei Z, Liao S C, Li S Z. Robust multi-resolution pedestrian detection in traffic scenes. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Portland, Oregon, USA: IEEE, 2013. 3033-3040
39 Yan J J, Zhang X C, Lei Z, Yi D, Li S Z. Structural models for face detection. In: Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG). Shanghai, China: IEEE, 2013. 1-6
40 Zhu X X, Ramanan D. Face detection, pose estimation, and landmark localization in the wild. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, Rhode Island, USA: IEEE, 2012. 2879-2886
41 Yang Y, Ramanan D. Articulated pose estimation with flexible mixtures-of-parts. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI, USA: IEEE, 2011. 1385-1392
42 Yan J J, Lei Z, Wen L Y, Li S Z. The fastest deformable part model for object detection. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, Ohio, USA: IEEE, 2014. 2497-2504
43 Lazebnik S, Schmid C, Ponce J. Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. In:Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). New York, NY, USA: IEEE, 2006. 2169-2178
44 Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, Ohio, USA: IEEE, 2014. 580-587
45 Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z H, Karpathy A, Khosla A, Bernstein M, Berg A C, Fei-Fei L. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3): 211-252.
46 Everingham M, Van Gool L, Williams C K I, Winn J, Zisserman A. The PASCAL visual object classes (VOC) challenge. International Journal of Computer Vision, 2010, 88(2): 303-338.
47 Xiao J X, Hays J, Ehinger K A, Oliva A, Torralba A. Sun database: large-scale scene recognition from abbey to zoo. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). San Francisco, CA, USA: IEEE, 2010. 3485-3492
48 Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick C L. Microsoft COCO: common objects in context. In: Proceedings of the 13th European Conference on Computer Vision (ECCV). Zurich, Switzerland:Springer, 2014. 740-755
49 Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors. Nature, 1986, 323(6088): 533-536.
50 LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436-444.
51 Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504-507.
52 Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7): 1527-1554.
53 Bengio Y, Lamblin P, Popovici D, Larochelle H. Greedy layer-wise training of deep networks. In: Proceedings of the 19th International Conference on Neural Information Processing Systems. Cambridge, MA, USA: MIT Press, 2006. 153-160
54 LeCun Y, Chopra S, Hadsell R, Ranzato M, Huang F. A tutorial on energy-based learning. Predicting Structured Data. Cambridge, MA, USA: MIT Press, 2006.
55 Lee H, Ekanadham C, Ng A Y. Sparse deep belief net model for visual area V2. In: Proceedings of the 2007 Advances in Neural Information Processing Systems (NIPS). Vancouver, British Columbia, Canada:MIT Press, 2007. 873-880
56 Hinton G, Deng L, Yu D, Dahl G E, Mohamed A R, Jaitly N, Senior A, Vanhoucke V, Nguyen P, Sainath T N, Kingsbury B. Deep neural networks for acoustic modeling in speech recognition:the shared views of four research groups. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
57 Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: MIT Press, 2012. 1097-1105
58 Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile:IEEE, 2015. 1440-1448
59 Lecun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
60 Vincent P, Larochelle H, Bengio Y, Manzagol P A. Extracting and composing robust features with denoising Autoencoders. In:Proceedings of the 25th IEEE International Conference on Machine Learning (ICML). Helsinki, Finland: IEEE, 2008. 1096-1103
61 Masci J, Meier U, Cire?an D, Schmidhuber J. Stacked convolutional auto-encoders for hierarchical feature extraction. In:Proceedings of the 21th International Conference on Artificial Neural Networks. Berlin, Heidelberg, Germany: Springer, 2011. 52-59
62 Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of the 13th European Conference on Computer Vision (ECCV). Zurich, Switzerland:Springer, 2014. 818-833
63 Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556, 2014.
64 Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, Massachusetts, USA: IEEE, 2015. 1-9
65 Szegedy C, Ioffe S, Vanhoucke V, Alemi A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. arXiv:1602.07261, 2016.
66 Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv:1502.03167, 2015.
67 Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. arXiv:1512.00567, 2015.
68 He K, Zhang X, Ren S, Sun J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In: Proceedings of the 2014 European Conference on Computer Vision (ECCV). Zurich, Switzerland: Springer, 2014. 346-361
69 Bell S, Lawrence Zitnick C, Bala K, Girshick R. Inside-outside net: detecting objects in context with skip pooling and recurrent neural networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA:IEEE, 2016. 2874-2883
70 Yang F, Choi W, Lin Y Q. Exploit all the layers: fast and accurate CNN object detector with scale dependent pooling and cascaded rejection classifiers. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 2129-2137
71 Shrivastava A, Gupta A, Girshick R. Training region-based object detectors with online hard example mining. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 761-769
72 Sung K K. Learning and Example Selection for Object and Pattern Detection[Ph.D. dissertation], Massachusetts Institute of Technology, USA, 1996.
73 Kong T, Yao A B, Chen Y R, Sun F C. Hyper Net:towards accurate region proposal generation and joint object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 845-853
74 Dai J F, Li Y, He K M, Sun J. R-FCN:object detection via region-based fully convolutional networks. In: Proceedings of the 2016 Advances in Neural Information Processing Systems (NIPS). Barcelona, Spain: MIT Press, 2016. 379-387
75 Kim K H, Hong S, Roh B, Cheon Y, Park M. PVANET: deep but lightweight neural networks for real-time object detection. arXiv: 1608.08021, 2016.
76 Shang W L, Sohn K, Almeida D, Lee H. Understanding and improving convolutional neural networks via concatenated rectified linear units. In: Proceedings of the 33rd International Conference on Machine Learning (ICML). New York, USA: IEEE, 2016. 2217-2225
77 Sermanet P, Eigen D, Zhang X, Mathieu M, Fergus R, LeCun Y. Overfeat: integrated recognition, localization and detection using convolutional networks. arXiv:1312.6229, 2013.
78 Redmon J, Divvala S, Girshick R, Farhadi A. You only look once:unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 779-788
79 Najibi M, Rastegari M, Davis L S. G-CNN:an iterative grid based object detector. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 2369-2377
80 Liu W, Anguelov D, Erhan D, Szegedy C, Reed S E, Fu C Y, Berg A C. SSD: single shot multibox detector. In: Proceedings of the 14th European Conference on Computer Vision (ECCV). Amsterdam, Netherlands:Springer, 2016. 21-37
81 Redmon J, Farhadi A. YOLO9000: better, faster, stronger. arXiv:1612.08242, 2016.
82 Pepik B, Benenson R, Ritschel T, Schiele B. What is holding back convnets for detection? In: Proceedings of the 2015 German Conference on Pattern Recognition. Cham, Germany:Springer, 2015. 517-528
83 Xiang Y, Mottaghi R, Savarese S. Beyond PASCAL:a benchmark for 3d object detection in the wild. In: Proceedings of the 2014 IEEE Winter Conference on Applications of Computer Vision (WACV). Steamboat Springs, Colorado, USA: IEEE, 2014. 75-82
84 Amazon Mechanical Turk[Online], available: https://www.mturk.com/, February 13, 2017
85 Wang Kun-Feng, Gou Chao, Wang Fei-Yue. Parallel vision: an ACP-based approach to intelligent vision computing. Acta Automatica Sinica, 2016, 42(10): 1490-1500.
( 王坤峰, 茍超, 王飛躍. 平行視覺(jué):基于ACP的智能視覺(jué)計(jì)算方法. 自動(dòng)化學(xué)報(bào), 2016, 42(10): 1490-1500.)
86 Wang K F, Gou C, Zheng N N, Rehg J M, Wang F Y. Parallel vision for perception and understanding of complex scenes: methods, framework, and perspectives. Artificial Intelligence Review[Online], available:https://link.springer.com/article/10.1007/s10462-017-9569-z, July 18, 2017
87 Wang Fei-Yue. Parallel system methods for management and control of complex systems. Control and Decision, 2004, 19(5): 485-489, 514.
( 王飛躍. 平行系統(tǒng)方法與復(fù)雜系統(tǒng)的管理和控制. 控制與決策, 2004, 19(5): 485-489, 514.)
88 Wang F Y. Parallel control and management for intelligent transportation systems: concepts, architectures, and applications. IEEE Transactions on Intelligent Transportation Systems, 2010, 11(3): 630-638.
89 Wang Fei-Yue. Parallel control:a method for data-driven and computational control. Acta Automatica Sinica, 2013, 39(4): 293-302.
( 王飛躍. 平行控制:數(shù)據(jù)驅(qū)動(dòng)的計(jì)算控制方法. 自動(dòng)化學(xué)報(bào), 2013, 39(4): 293-302.)
90 Peng X C, Sun B C, Ali K, Saenko K. Learning deep object detectors from 3D models. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1278-1286
91 Johnson-Roberson M, Barto C, Mehta R, Sridhar S N, Rosaen K, Vasudevan R. Driving in the matrix: can virtual worlds replace human-generated annotations for real world tasks? arXiv: 1610.01983, 2016.
92 Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345-1359.
93 Taylor M E, Stone P. Transfer learning for reinforcement learning domains: a survey. The Journal of Machine Learning Research, 2009, 10: 1633-1685.
本文僅做學(xué)術(shù)分享,如有侵權(quán),請(qǐng)聯(lián)系刪文。