
常用的聚類(lèi)算法及聚類(lèi)算法評(píng)價(jià)指標(biāo)
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

本文轉(zhuǎn)自:磐創(chuàng)AI
代表:kmeans算法
·指定k個(gè)聚類(lèi)中心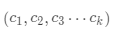
·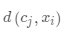 (計(jì)算數(shù)據(jù)點(diǎn)與初始聚類(lèi)中心的距離)
(計(jì)算數(shù)據(jù)點(diǎn)與初始聚類(lèi)中心的距離)
·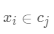 (對(duì)于數(shù)據(jù)點(diǎn)
(對(duì)于數(shù)據(jù)點(diǎn)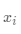 ,找到最近的
,找到最近的 {i}(聚類(lèi)中心),將分配到{i}中)
{i}(聚類(lèi)中心),將分配到{i}中)
·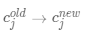 (更新聚類(lèi)中心點(diǎn),
(更新聚類(lèi)中心點(diǎn),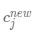 是新類(lèi)別數(shù)值的均值點(diǎn))
是新類(lèi)別數(shù)值的均值點(diǎn))
·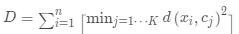 (計(jì)算每一類(lèi)的偏差)
(計(jì)算每一類(lèi)的偏差)
·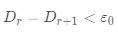 返回
返回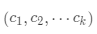
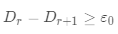 返回第二步
返回第二步
1.2 基于層次的方法
代表:CURE算法
·每個(gè)樣本作為單獨(dú)的一個(gè)類(lèi)別
·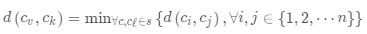
·合并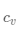 ,
,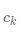 為
為
·遍歷完本次樣本,合并成新的類(lèi)別后,若存在多個(gè)類(lèi)別,則返回第二步
·遍歷完本次樣本,合并成新的類(lèi)別后,若所有樣本為同一類(lèi)別,跳出循環(huán),輸出每層類(lèi)別
1.3 基于網(wǎng)格的方法
代表:STING算法
·將數(shù)據(jù)集合X劃分多層網(wǎng)格結(jié)構(gòu),從某一層開(kāi)始計(jì)算
·查詢(xún)?cè)搶泳W(wǎng)格間的屬性值,計(jì)算屬性值與閾值的關(guān)系,判定網(wǎng)格間的相關(guān)情況,不相關(guān)的網(wǎng)格不作考慮
·如果網(wǎng)格相關(guān),則進(jìn)入下一層的相關(guān)區(qū)域繼續(xù)第二步,直到下一層為最底層
·返回相關(guān)網(wǎng)格結(jié)果
1.4 基于密度的方法
代表:DBSCAN算法
·輸入數(shù)據(jù)集合X,隨機(jī)選取一點(diǎn),并找出這個(gè)點(diǎn)的所有高密度可達(dá)點(diǎn)
·遍歷此點(diǎn)的所有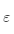 鄰域內(nèi)的點(diǎn),并尋找這些密度可達(dá)點(diǎn),判定某點(diǎn)
鄰域內(nèi)的點(diǎn),并尋找這些密度可達(dá)點(diǎn),判定某點(diǎn)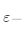 鄰域內(nèi)的點(diǎn),并尋找這些點(diǎn)密度可達(dá)點(diǎn),判定某點(diǎn)的
鄰域內(nèi)的點(diǎn),并尋找這些點(diǎn)密度可達(dá)點(diǎn),判定某點(diǎn)的 鄰域內(nèi)的點(diǎn)數(shù)是否超過(guò)閾值點(diǎn)數(shù),超過(guò)則構(gòu)成核心點(diǎn)
鄰域內(nèi)的點(diǎn)數(shù)是否超過(guò)閾值點(diǎn)數(shù),超過(guò)則構(gòu)成核心點(diǎn)
·掃描數(shù)據(jù)集,尋找沒(méi)有被聚類(lèi)的數(shù)據(jù)點(diǎn),重復(fù)第二步
·輸出劃分的類(lèi),并輸出異常值點(diǎn)(不和其他密度相連)
1.5 神經(jīng)網(wǎng)絡(luò)的方法
代表:SOM算法
·數(shù)據(jù)集合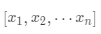 ,權(quán)重向量為
,權(quán)重向量為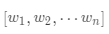 ,
,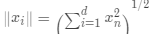 ,歸一化處理
,歸一化處理
·尋找獲勝的神經(jīng)元,找到最小距離,對(duì)于每一個(gè)輸入數(shù)據(jù),找到與之最相匹配的節(jié)點(diǎn)
令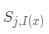 為
為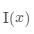 為
為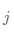 的距離,更新權(quán)重:
的距離,更新權(quán)重: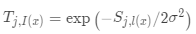
·更新臨近節(jié)點(diǎn),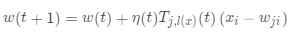 ,其中
,其中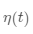 代表學(xué)習(xí)率
代表學(xué)習(xí)率
1.6 基于圖的聚類(lèi)方法
代表:譜聚類(lèi)算法
·計(jì)算鄰接矩陣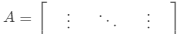 ,度矩陣
,度矩陣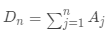 ,
,
·計(jì)算拉普拉及矩陣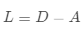
·計(jì)算歸一化拉普拉斯矩陣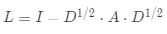
·計(jì)算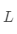 的特征值和特征向量
的特征值和特征向量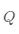
·對(duì)Q矩陣進(jìn)行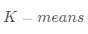 聚類(lèi),得到聚類(lèi)結(jié)果
聚類(lèi),得到聚類(lèi)結(jié)果
一個(gè)好的聚類(lèi)方法可以產(chǎn)生高品質(zhì)簇,是的簇內(nèi)相似度高,簇間相似度低。一般來(lái)說(shuō),評(píng)估聚類(lèi)質(zhì)量有兩個(gè)標(biāo)準(zhǔn),內(nèi)部質(zhì)量評(píng)價(jià)指標(biāo)和外部評(píng)價(jià)指標(biāo)。
2.1 內(nèi)部質(zhì)量評(píng)價(jià)標(biāo)準(zhǔn)
內(nèi)部評(píng)價(jià)指標(biāo)是利用數(shù)據(jù)集的屬性特征來(lái)評(píng)價(jià)聚類(lèi)算法的優(yōu)劣。通過(guò)計(jì)算總體的相似度,簇間平均相似度或簇內(nèi)平均相似度來(lái)評(píng)價(jià)聚類(lèi)質(zhì)量。評(píng)價(jià)聚類(lèi)效果的高低通常使用聚類(lèi)的有效性指標(biāo),所以目前的檢驗(yàn)聚類(lèi)的有效性指標(biāo)主要是通過(guò)簇間距離和簇內(nèi)距離來(lái)衡量。這類(lèi)指標(biāo)常用的有CH(Calinski-Harabasz)指標(biāo)等
CH指標(biāo)
CH指標(biāo)定義為: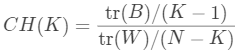
其中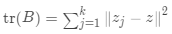 表示類(lèi)間距離差矩陣的跡,
表示類(lèi)間距離差矩陣的跡,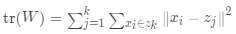 表示類(lèi)內(nèi)離差矩陣的跡,
表示類(lèi)內(nèi)離差矩陣的跡,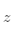 是整個(gè)數(shù)據(jù)集的均值,
是整個(gè)數(shù)據(jù)集的均值,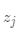 是第個(gè)簇
是第個(gè)簇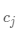 的均值,
的均值,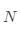 代表聚類(lèi)個(gè)數(shù),
代表聚類(lèi)個(gè)數(shù),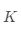 代表當(dāng)前的類(lèi)。
代表當(dāng)前的類(lèi)。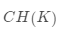 值越大,聚類(lèi)效果越好,
值越大,聚類(lèi)效果越好,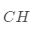 主要計(jì)算簇間距離與簇內(nèi)距離的比值
主要計(jì)算簇間距離與簇內(nèi)距離的比值
簇的凝聚度
簇內(nèi)點(diǎn)對(duì)的平均距離反映了簇的凝聚度,一般使用組內(nèi)誤差平方(SSE)表示: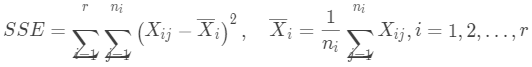
簇的鄰近度
簇的鄰近度用組間平方和(SSB)表示,即簇的質(zhì)心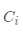 到簇內(nèi)所有數(shù)據(jù)點(diǎn)的總平均值
到簇內(nèi)所有數(shù)據(jù)點(diǎn)的總平均值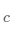 的距離的平方和
的距離的平方和
2.2 外部質(zhì)量評(píng)價(jià)標(biāo)準(zhǔn)
外部質(zhì)量評(píng)價(jià)指標(biāo)是基于已知分類(lèi)標(biāo)簽數(shù)據(jù)集進(jìn)行評(píng)價(jià)的,這樣可以將原有標(biāo)簽數(shù)據(jù)與聚類(lèi)輸出結(jié)果進(jìn)行對(duì)比。外部質(zhì)量評(píng)價(jià)指標(biāo)的理想聚類(lèi)結(jié)果是:具有不同類(lèi)標(biāo)簽的數(shù)據(jù)聚合到不同的簇中,具有相同類(lèi)標(biāo)簽的數(shù)據(jù)聚合相同的簇中。外部質(zhì)量評(píng)價(jià)準(zhǔn)則通常使用熵,純度等指標(biāo)進(jìn)行度量。
熵:
簇內(nèi)包含單個(gè)類(lèi)對(duì)象的一種度量。對(duì)于每一個(gè)簇,首先計(jì)算數(shù)據(jù)的類(lèi)分布,即對(duì)于簇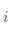 ,計(jì)算簇的成員屬于類(lèi)的概率
,計(jì)算簇的成員屬于類(lèi)的概率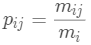
其中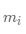 表示簇中所有對(duì)象的個(gè)數(shù),而
表示簇中所有對(duì)象的個(gè)數(shù),而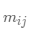 是簇中類(lèi)的對(duì)象個(gè)數(shù)。使用類(lèi)分布,用標(biāo)準(zhǔn)公式:
是簇中類(lèi)的對(duì)象個(gè)數(shù)。使用類(lèi)分布,用標(biāo)準(zhǔn)公式: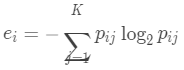
計(jì)算每個(gè)簇的熵,其中K是類(lèi)個(gè)數(shù)。簇集合的總熵用每個(gè)簇的熵的加權(quán)和計(jì)算即: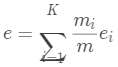
其中是簇的個(gè)數(shù),而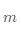 是簇內(nèi)數(shù)據(jù)點(diǎn)的總和
是簇內(nèi)數(shù)據(jù)點(diǎn)的總和
純度:
簇內(nèi)包含單個(gè)類(lèi)對(duì)象的另外一種度量。簇的純度為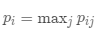 ,而聚類(lèi)總純度為:
,而聚類(lèi)總純度為: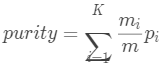
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~