
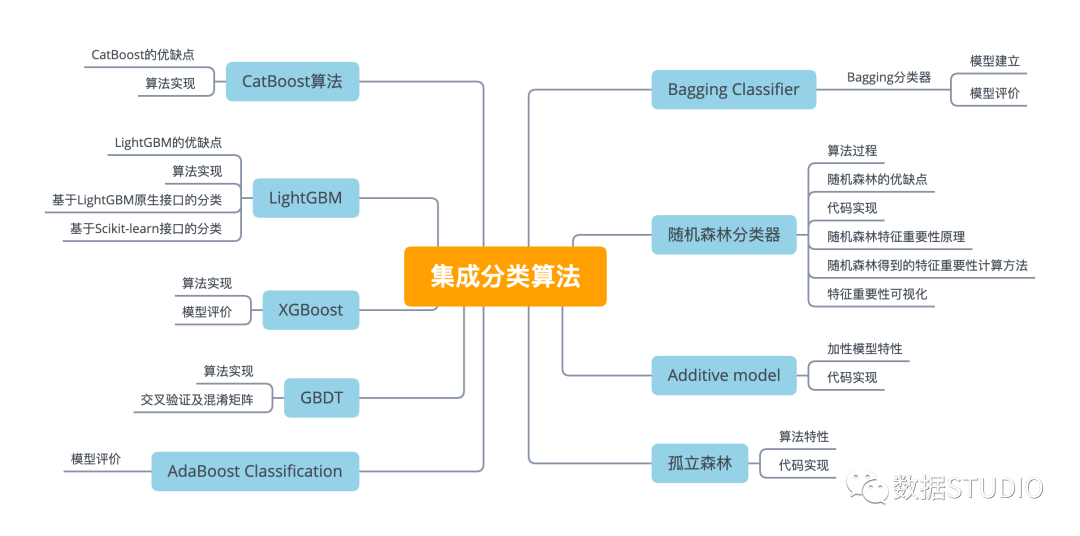
【機(jī)器學(xué)習(xí)】總結(jié)了九種機(jī)器學(xué)習(xí)集成分類(lèi)算法(原理+代碼)
大家好,我是云朵君!
導(dǎo)讀: 本文是分類(lèi)分析(基于Python實(shí)現(xiàn)五大常用分類(lèi)算法(原理+代碼))第二部分,繼續(xù)沿用第一部分的數(shù)據(jù)。會(huì)總結(jié)性介紹集成分類(lèi)算法原理及應(yīng)用,模型調(diào)參數(shù)將不在本次討論范圍內(nèi)。這里沒(méi)有高深的理論,但足以應(yīng)對(duì)面試或簡(jiǎn)單場(chǎng)景應(yīng)用,希望對(duì)你有所幫助。
集成算法(Emseble Learning) 是構(gòu)建多個(gè)學(xué)習(xí)器,然后通過(guò)一定策略結(jié)合把它們來(lái)完成學(xué)習(xí)任務(wù)的,常常可以獲得比單一學(xué)習(xí)顯著優(yōu)越的學(xué)習(xí)器。
它本身不是一個(gè)單獨(dú)的機(jī)器學(xué)習(xí)算法,而是通過(guò)數(shù)據(jù)上構(gòu)建并結(jié)合多個(gè)機(jī)器學(xué)習(xí)器來(lái)完成學(xué)習(xí)任務(wù)。弱評(píng)估器被定義為是表現(xiàn)至少比隨機(jī)猜測(cè)更好的模型,即預(yù)測(cè)準(zhǔn)確率不低于50%的任意模型。
根據(jù)個(gè)體學(xué)習(xí)器的生產(chǎn)方式,目前的集成學(xué)習(xí)方法大致可分為兩大類(lèi),即個(gè)體學(xué)習(xí)器間存在強(qiáng)依賴(lài)關(guān)系、必須串行生產(chǎn)的序列化方法,代表是Boosting。以及個(gè)體間不存在強(qiáng)依賴(lài)關(guān)系、可同時(shí)生產(chǎn)的并行化方法,代表是Bagging,和隨機(jī)森林。
Bagging Classifier
Bagging分類(lèi)器是一種集成元估計(jì)器,它適合原始數(shù)據(jù)集的每個(gè)隨機(jī)子集上的基分類(lèi)器,然后將它們各自的預(yù)測(cè)(通過(guò)投票或平均)聚合成最終的預(yù)測(cè)。
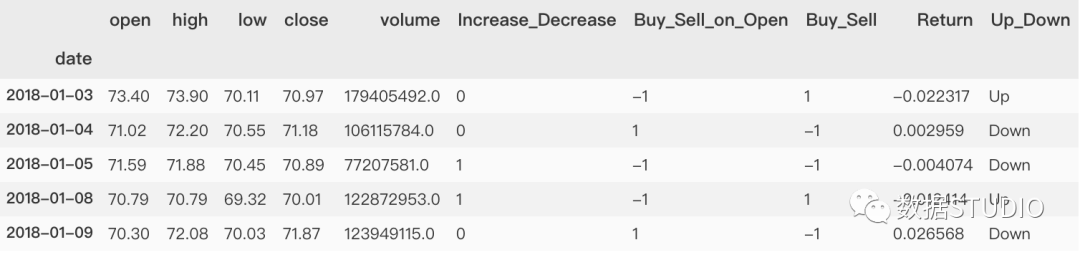
dataset['Up_Down'] = np.where(
dataset['Return'].shift(-1) > dataset['Return'],
'Up','Down')
dataset.head()
模型建立
X = np.array(dataset['open']).reshape(-1, 1)
y = dataset['Up_Down']
# 導(dǎo)入需要的包
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import train_test_split
dt = DecisionTreeClassifier(random_state=1)
bc = BaggingClassifier(base_estimator=dt,
n_estimators=50, random_state=1)
# 劃分訓(xùn)練集及測(cè)試集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 1/4, random_state = 0)
模型評(píng)價(jià)
from sklearn.metrics import accuracy_score
bc.fit(X_train, y_train)
y_pred = bc.predict(X_test)
# 模型準(zhǔn)確性評(píng)價(jià)
acc_test = accuracy_score(y_pred, y_test)
print('Test set accuracy of bc: {:.2f}'.format(acc_test))
隨機(jī)森林分類(lèi)器
隨機(jī)森林采用決策樹(shù)作為弱分類(lèi)器,在bagging的樣本隨機(jī)采樣基礎(chǔ)上,?加上了特征的隨機(jī)選擇。有關(guān)隨機(jī)森林詳細(xì)理論詳情可參見(jiàn)集成算法 | 隨機(jī)森林分類(lèi)模型
算法過(guò)程
從樣本集N中有放回隨機(jī)采樣選出n個(gè)樣本。 從所有特征中隨機(jī)選擇k個(gè)特征,對(duì)選出的樣本利用這些特征建立決策樹(shù)(一般是CART方法)。 重復(fù)以上兩步m次,生成m棵決策樹(shù),形成隨機(jī)森林,其中生成的決策樹(shù)不剪枝。 對(duì)于新數(shù)據(jù),經(jīng)過(guò)每棵決策樹(shù)投票分類(lèi)。
隨機(jī)森林的優(yōu)缺點(diǎn)
優(yōu)點(diǎn)
決策樹(shù)選擇部分樣本及部分特征,一定程度上避免過(guò)擬合 。 決策樹(shù)隨機(jī)選擇樣本并隨機(jī)選擇特征,模型具有很好的抗噪能力,性能穩(wěn)定。 能夠處理高維度數(shù)據(jù),并且不用做特征選擇,能夠展現(xiàn)出哪些變量比較重要。 對(duì)缺失值不敏感,如果有很大一部分的特征遺失,仍可以維持準(zhǔn)確度。 訓(xùn)練時(shí)樹(shù)與樹(shù)之間是相互獨(dú)立的,訓(xùn)練速度快,容易做成并行化方法。 隨機(jī)森林有袋外數(shù)據(jù)obb,不需要單獨(dú)劃分交叉驗(yàn)證集。
缺點(diǎn)
可能有很多相似決策樹(shù),掩蓋真實(shí)結(jié)果。 對(duì)小數(shù)據(jù)或低維數(shù)據(jù)可能不能產(chǎn)生很好分類(lèi)。 產(chǎn)生眾多決策樹(shù),算法較慢。
代碼實(shí)現(xiàn)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=30)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print('Accuracy Score: ',
accuracy_score(y_test, y_pred))
print('Accuracy Score Normalized: ',
accuracy_score(y_test, y_pred, normalize=False))
隨機(jī)森林特征重要性原理
袋外數(shù)據(jù)錯(cuò)誤率評(píng)估
RF的數(shù)據(jù)是boostrap的有放回采樣,形成了袋外數(shù)據(jù)。因此可以采用袋外數(shù)據(jù)(OOB)錯(cuò)誤率進(jìn)行特征重要性的評(píng)估。
袋外數(shù)據(jù)錯(cuò)誤率定義為:袋外數(shù)據(jù)自變量值發(fā)生輕微擾動(dòng)后的分類(lèi)正確率與擾動(dòng)前分類(lèi)正確率的平均減少量。
利用Gini系數(shù)計(jì)算特征的重要性
單棵樹(shù)上特征的重要性定義為:特征在所有非葉節(jié)在分裂時(shí)加權(quán)不純度的減少,減少的越多說(shuō)明特征越重要。
隨機(jī)森林得到的特征重要性計(jì)算方法
1、對(duì)于隨機(jī)森林中的每一顆決策樹(shù),使用相應(yīng)的OOB(袋外數(shù)據(jù))數(shù)據(jù)來(lái)計(jì)算它的袋外數(shù)據(jù)誤差,記為 .
2、隨機(jī)地對(duì)袋外數(shù)據(jù)OOB所有樣本的特征X加入噪聲干擾(就可以隨機(jī)的改變樣本在特征X處的值),再次計(jì)算它的袋外數(shù)據(jù)誤差,記為 .
3、假設(shè)隨機(jī)森林中有 棵樹(shù),那么對(duì)于特征X的重要性 ,之所以可以用這個(gè)表達(dá)式來(lái)作為相應(yīng)特征的重要性的度量值是因?yàn)椋喝艚o某個(gè)特征隨機(jī)加入噪聲之后,袋外的準(zhǔn)確率大幅度降低,則說(shuō)明這個(gè)特征對(duì)于樣本的分類(lèi)結(jié)果影響很大,也就是說(shuō)它的重要程度比較高。
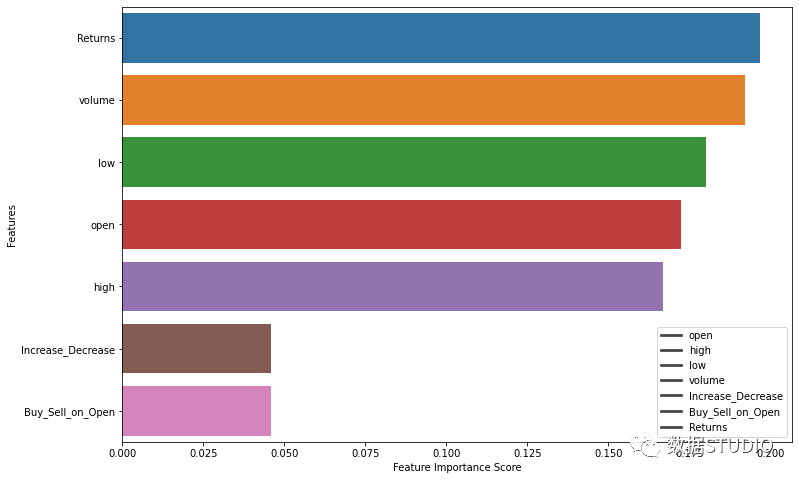
特征重要性可視化
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
feature_imp = pd.Series(
model.feature_importances_,
index=X.columns).sort_values(ascending=False)
fig, ax = plt.subplots(figsize=(12,8))
sns.barplot(x=feature_imp,
y=feature_imp.index)
plt.xlabel('Feature Importance Score')
plt.ylabel('Features')
plt.legend(X)
plt.show()
Additive model
可加模型AM是一種非參數(shù)回歸方法。它是由Jerome H. Friedman和Werner Stuetzle提出的,是ACE算法的重要組成部分。AM使用一維平滑器來(lái)建立一類(lèi)受限的非參數(shù)回歸模型。
廣義加性模型GAM是一種在線(xiàn)性或Logistic回歸模型(或任何其他廣義線(xiàn)性模型)的框架內(nèi),構(gòu)造非單調(diào)的響應(yīng)模型的方法。
加性模型特性
GAM將變量和結(jié)果之間的非線(xiàn)性、非單調(diào)性關(guān)系在一個(gè)線(xiàn)性或Logistic回歸框架中表現(xiàn)出來(lái)。
可以使用評(píng)估標(biāo)準(zhǔn)線(xiàn)性或Logistic回歸時(shí)所使用的度量準(zhǔn)則來(lái)評(píng)價(jià)GAM,如:殘差、偏差、R-平方和偽R-平方。GAM概要還能給出指示,表明哪些變量會(huì)對(duì)模型產(chǎn)生顯著影響。
因?yàn)橄鄬?duì)于標(biāo)準(zhǔn)線(xiàn)性或Logistic回歸模型而言,GAM的復(fù)雜性增加了,所以GAM過(guò)擬合的風(fēng)險(xiǎn)更高。
代碼實(shí)現(xiàn)
X = dataset[['open', 'high', 'low', 'volume', 'close','Returns']].values
y = dataset['Buy_Sell'].values
from pygam import LogisticGAM
# 使用默認(rèn)參數(shù)訓(xùn)練模型
gam = LogisticGAM().fit(X, y)
print(gam.accuracy(X, y))
gam.summary()
0.6515775034293553
LogisticGAM
=============================================== ==========================================================
Distribution: BinomialDist Effective DoF: 42.6805
Link Function: LogitLink Log Likelihood: -458.5615
Number of Samples: 729 AIC: 1002.4841
AICc: 1008.188
UBRE: 3.422
Scale: 1.0
Pseudo R-Squared: 0.0924
==========================================================================================================
Feature Function Lambda Rank EDoF P > x Sig. Code
================================= ==================== ============ ============ ============ ============
s(0) [0.6] 20 12.2 2.76e-01
s(1) [0.6] 20 7.5 1.32e-01
s(2) [0.6] 20 6.3 5.67e-03 **
s(3) [0.6] 20 7.4 6.10e-01
s(4) [0.6] 20 3.7 5.97e-02 .
s(5) [0.6] 20 5.6 6.09e-01
intercept 1 0.0 4.38e-01
==========================================================================================================
Significance codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
AdaBoost Classification
有關(guān)Adaboost理論可以參考集成算法 | AdaBoost,這里特別提出Adaboost分類(lèi)器只適用于二分類(lèi)任務(wù)。
X = dataset[['open', 'high', 'low', 'volume', 'close','Returns']].values
y = dataset['Buy_Sell'].values
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import confusion_matrix
model = AdaBoostClassifier(n_estimators=100)
sss = StratifiedShuffleSplit(n_splits=5, test_size=0.50, random_state=None)
sss.get_n_splits(X, y)
cm_sum = np.zeros((2,2))
for train_index, test_index in sss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
cm_sum = cm_sum + cm
print('\nAda Boost Algorithms')
print('\nConfusion Matrix')
print('_'*20)
print(' Predicted')
print(' pos neg')
print('pos: %i %i' % (cm_sum[1,1], cm_sum[0,1]))
print('neg: %i %i' % (cm_sum[1,1], cm_sum[0,1]))
Ada Boost Algorithms
Confusion Matrix
____________________
Predicted
pos neg
pos: 447 451
neg: 447 451
模型評(píng)價(jià)
from sklearn.metrics import accuracy_score
print('Accuracy Score: ', accuracy_score(y_test, y_pred))
print('Accuracy Score Normalized: ',accuracy_score(y_test, y_pred, normalize=False))
Accuracy Score: 0.5178082191780822
Accuracy Score Normalized: 189
GBDT
梯度提升(Gradient boosting) 是構(gòu)建預(yù)測(cè)模型的最強(qiáng)大技術(shù)之一,它是集成算法中提升法(Boosting)的代表算法。
提升樹(shù)利用加法模型與前向分歩算法實(shí)現(xiàn)學(xué)習(xí)的優(yōu)化過(guò)程。當(dāng)損失函數(shù)是平方誤差損失函數(shù)和指數(shù)損失函數(shù)時(shí),每一步優(yōu)化是很簡(jiǎn)單的。但對(duì)一般損失函數(shù)而言,往往每一步優(yōu)化并不那么容易。針對(duì)這一問(wèn)題,F(xiàn)reidman提出了梯度提升算法。
Gradient Boosting是Boosting中的一大類(lèi)算法,它的思想借鑒于梯度下降法,其基本原理是根據(jù)當(dāng)前模型損失函數(shù)的負(fù)梯度信息來(lái)訓(xùn)練新加入的弱分類(lèi)器,然后將訓(xùn)練好的弱分類(lèi)器以累加的形式結(jié)合到現(xiàn)有模型中。
采用決策樹(shù)作為弱分類(lèi)器的Gradient Boosting算法被稱(chēng)為GBDT,有時(shí)又被稱(chēng)為MART(Multiple Additive Regression Tree)。GBDT中使用的決策樹(shù)通常為CART。
算法實(shí)現(xiàn)
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.metrics import confusion_matrix,accuracy_score
X = dataset[['open', 'high', 'low', 'volume', 'close','Returns']].values
y = dataset['Buy_Sell'].values
model = GradientBoostingClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print('Accuracy Score: ', accuracy_score(y_test, y_pred))
print('Accuracy Score Normalized: ',accuracy_score(y_test, y_pred, normalize=False))
交叉驗(yàn)證及混淆矩陣
model = GradientBoostingClassifier(n_estimators=100)
sss = StratifiedShuffleSplit(n_splits=5, test_size=0.50, random_state=None)
sss.get_n_splits(X, y)
cm_sum = np.zeros((2,2))
for train_index, test_index in sss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
cm_sum = cm_sum + cm
print('\nGradient Boosting Algorithms')
print('\nConfusion Matrix')
print('_'*20)
print(' Predicted')
print(' pos neg')
print('pos: %i %i' % (cm_sum[1,1], cm_sum[0,1]))
print('neg: %i %i' % (cm_sum[1,1], cm_sum[0,1]))
Gradient Boosting Algorithms
Confusion Matrix
____________________
Predicted
pos neg
pos: 438 421
neg: 438 421
XGBoost
XGBoost的全稱(chēng)是eXtreme Gradient Boosting,它是經(jīng)過(guò)優(yōu)化的分布式梯度提升庫(kù),旨在高效、靈活且可移植。XGBoost是大規(guī)模并行boosting tree的工具,它是目前最快最好的開(kāi)源boosting tree工具包,比常見(jiàn)的工具包快10倍以上。
在數(shù)據(jù)科學(xué)方面,有大量的Kaggle選手選用XGBoost進(jìn)行數(shù)據(jù)挖掘比賽,是各大數(shù)據(jù)科學(xué)比賽的必殺武器;在工業(yè)界大規(guī)模數(shù)據(jù)方面,XGBoost的分布式版本有廣泛的可移植性,支持在Kubernetes、Hadoop、SGE、MPI、Dask等各個(gè)分布式環(huán)境上運(yùn)行,使得它可以很好地解決工業(yè)界大規(guī)模數(shù)據(jù)的問(wèn)題。
XGBoost vs GBDT核心區(qū)別之一:求解預(yù)測(cè)值的方式不同
GBDT中預(yù)測(cè)值是由所有弱分類(lèi)器上的預(yù)測(cè)結(jié)果的加權(quán)求和,其中每個(gè)樣本上的預(yù)測(cè)結(jié)果就是樣本所在的葉子節(jié) 點(diǎn)的均值。 而XGBT中的預(yù)測(cè)值是所有弱分類(lèi)器上的葉子權(quán)重直接求和得到,計(jì)算葉子權(quán)重是一個(gè)復(fù)雜的過(guò)程。
算法實(shí)現(xiàn)
from xgboost import XGBClassifier
# XGboost 算法
xgb = XGBClassifier(max_depth=5, learning_rate=0.01, n_estimators=2000, colsample_bytree=0.1)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25)
xgb.fit(X_train,y_train)
y_pred = xgb.predict(X_test)
模型評(píng)價(jià)
from sklearn.metrics import mean_squared_error
from sklearn import metrics
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
print('XGBoost Regression Score:', xgb.score(X_test, y_test))
LightGBM
LightGBM是在GBDT算法框架下的一種改進(jìn)實(shí)現(xiàn),是一種基于決策樹(shù)算法的快速、分布式、高性能的GBDT框架,主要說(shuō)解決的痛點(diǎn)是面對(duì)高維度大數(shù)據(jù)時(shí)提高GBDT框架算法的效率和可擴(kuò)展性。
Light主要體現(xiàn)在三個(gè)方面,即更少的樣本、更少的特征、更少的內(nèi)存,分別通過(guò)單邊梯度采樣(Gradient-based One-Side Sampling)、互斥特征合并(Exclusive Feature Bundling)、直方圖算法(Histogram)三項(xiàng)技術(shù)實(shí)現(xiàn)。
另外,在工程上面,LightGBM還在并行計(jì)算方面做了諸多的優(yōu)化,支持特征并行和數(shù)據(jù)并行,并針對(duì)各自的并行方式做了優(yōu)化,減少通信量。
作為GBDT框架內(nèi)的算法,GBDT、XGBoost能夠應(yīng)用的場(chǎng)景LightGBM也都適用,并且考慮到其對(duì)于大數(shù)據(jù)、高維特征的諸多優(yōu)化,在數(shù)據(jù)量非常大、維度非常多的場(chǎng)景更具優(yōu)勢(shì)。近來(lái),有著逐步替代XGBoost成為各種數(shù)據(jù)挖掘比賽baseline的趨勢(shì)。
LightGBM的優(yōu)缺點(diǎn)
優(yōu)點(diǎn)
這部分主要總結(jié)下 LightGBM 相對(duì)于 XGBoost 的優(yōu)點(diǎn),從內(nèi)存和速度兩方面進(jìn)行介紹。
(1)速度更快
LightGBM 采用了直方圖算法將遍歷樣本轉(zhuǎn)變?yōu)楸闅v直方圖,極大的降低了時(shí)間復(fù)雜度; LightGBM 在訓(xùn)練過(guò)程中采用單邊梯度算法過(guò)濾掉梯度小的樣本,減少了大量的計(jì)算; LightGBM 采用了基于 Leaf-wise 算法的增長(zhǎng)策略構(gòu)建樹(shù),減少了很多不必要的計(jì)算量; LightGBM 采用優(yōu)化后的特征并行、數(shù)據(jù)并行方法加速計(jì)算,當(dāng)數(shù)據(jù)量非常大的時(shí)候還可以采用投票并行的策略; LightGBM 對(duì)緩存也進(jìn)行了優(yōu)化,增加了緩存命中率;
(2)內(nèi)存更小
XGBoost使用預(yù)排序后需要記錄特征值及其對(duì)應(yīng)樣本的統(tǒng)計(jì)值的索引,而 LightGBM 使用了直方圖算法將特征值轉(zhuǎn)變?yōu)?bin 值,且不需要記錄特征到樣本的索引,將空間復(fù)雜度從 降低為 ,極大的減少了內(nèi)存消耗; LightGBM 采用了直方圖算法將存儲(chǔ)特征值轉(zhuǎn)變?yōu)榇鎯?chǔ) bin 值,降低了內(nèi)存消耗; LightGBM 在訓(xùn)練過(guò)程中采用互斥特征捆綁算法減少了特征數(shù)量,降低了內(nèi)存消耗。
缺點(diǎn)
可能會(huì)長(zhǎng)出比較深的決策樹(shù),產(chǎn)生過(guò)擬合。因此LightGBM在Leaf-wise之上增加了一個(gè)最大深度限制,在保證高效率的同時(shí)防止過(guò)擬合; Boosting族是迭代算法,每一次迭代都根據(jù)上一次迭代的預(yù)測(cè)結(jié)果對(duì)樣本進(jìn)行權(quán)重調(diào)整,所以隨著迭代不斷進(jìn)行,誤差會(huì)越來(lái)越小,模型的偏差(bias)會(huì)不斷降低。由于LightGBM是基于偏差的算法,所以會(huì)對(duì)噪點(diǎn)較為敏感; 在尋找最優(yōu)解時(shí),依據(jù)的是最優(yōu)切分變量,沒(méi)有將最優(yōu)解是全部特征的綜合這一理念考慮進(jìn)去
參考自LightGBM[1]
算法實(shí)現(xiàn)
LightGBM有兩大類(lèi)接口:LightGBM原生接口 和 scikit-learn接口 ,并且LightGBM能夠?qū)崿F(xiàn)分類(lèi)和回歸兩種任務(wù)。
基于LightGBM原生接口的分類(lèi)
params = {
'learning_rate': 0.1,
'lambda_l1': 0.1,
'lambda_l2': 0.2,
'max_depth': 4,
'objective': 'binary', # 目標(biāo)函數(shù)
}
# 轉(zhuǎn)換為Dataset數(shù)據(jù)格式
train_data = lgb.Dataset(X_train, label=y_train)
validation_data = lgb.Dataset(X_test, label=y_test)
# 模型訓(xùn)練
gbm = lgb.train(params, train_data, valid_sets=[validation_data])
LightGBM原生接口當(dāng)中參數(shù)[2]
基于Scikit-learn接口的分類(lèi)
X = dataset[['open', 'high', 'low', 'volume']].values
y = dataset['Buy_Sell'].values
# 安裝LightGBM依賴(lài)包
# pip install lightgbm
import lightgbm as lgb
from sklearn import metrics
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
model = lgb.LGBMClassifier(num_leaves=31,
learning_rate=0.05,
n_estimators=20)
model.fit(X_train, y_train,
eval_set=[(X_test, y_test)],
eval_metric='l1',
early_stopping_rounds=5)
y_pred = model.predict(X_test, num_iteration=model.best_iteration_)
from sklearn.metrics import mean_squared_error
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
print('LightGBM Score:', model.score(X_test, y_test))
The rmse of prediction is: 0.70224688317
LightGBM Score: 0.50684931506
CatBoost算法
CatBoost(分類(lèi)增強(qiáng))是一種對(duì)決策樹(shù)進(jìn)行梯度增強(qiáng)的算法。是Yandex創(chuàng)造的一種機(jī)器學(xué)習(xí)技術(shù)。因此,它的性能優(yōu)于許多現(xiàn)有的boost,如XGBoost和Light GBM。
CatBoost是在GBDT算法框架下的一種改進(jìn)實(shí)現(xiàn),是一種基于對(duì)稱(chēng)決策樹(shù)(oblivious trees)算法的參數(shù)少、支持類(lèi)別型變量和高準(zhǔn)確性的GBDT框架,主要說(shuō)解決的痛點(diǎn)是高效合理地處理類(lèi)別型特征,這個(gè)從它的名字就可以看得出來(lái),CatBoost是由catgorical和boost組成,另外是處理梯度偏差(Gradient bias)以及預(yù)測(cè)偏移(Prediction shift)問(wèn)題,提高算法的準(zhǔn)確性和泛化能力。
與XGBoost、LightGBM相比,CatBoost的創(chuàng)新點(diǎn)有:
嵌入了自動(dòng)將類(lèi)別型特征處理為數(shù)值型特征的創(chuàng)新算法。首先對(duì)categorical features做一些統(tǒng)計(jì),計(jì)算某個(gè)類(lèi)別特征(category)出現(xiàn)的頻率,之后加上超參數(shù),生成新的數(shù)值型特征(numerical features)。 Catboost還使用了組合類(lèi)別特征,可以利用到特征之間的聯(lián)系,這極大的豐富了特征維度。 采用排序提升的方法對(duì)抗訓(xùn)練集中的噪聲點(diǎn),從而避免梯度估計(jì)的偏差,進(jìn)而解決預(yù)測(cè)偏移的問(wèn)題。 采用了完全對(duì)稱(chēng)樹(shù)作為基模型。
CatBoost主要有以下五個(gè)特性:
無(wú)需調(diào)參即可獲得較高的模型質(zhì)量,采用默認(rèn)參數(shù)就可以獲得非常好的結(jié)果,減少在調(diào)參上面花的時(shí)間。 支持類(lèi)別型變量,無(wú)需對(duì)非數(shù)值型特征進(jìn)行預(yù)處理。 快速、可擴(kuò)展的GPU版本,可以用基于GPU的梯度提升算法實(shí)現(xiàn)來(lái)訓(xùn)練你的模型,支持多卡并行。 提高準(zhǔn)確性,提出一種全新的梯度提升機(jī)制來(lái)構(gòu)建模型以減少過(guò)擬合。 快速預(yù)測(cè),即便應(yīng)對(duì)延時(shí)非常苛刻的任務(wù)也能夠快速高效部署模型。
CatBoost的優(yōu)缺點(diǎn)
優(yōu)點(diǎn)
性能卓越:在性能方面可以匹敵任何先進(jìn)的機(jī)器學(xué)習(xí)算法; 魯棒性/強(qiáng)健性:它減少了對(duì)很多超參數(shù)調(diào)優(yōu)的需求,并降低了過(guò)度擬合的機(jī)會(huì),這也使得模型變得更加具有通用性; 易于使用:提供與scikit集成的Python接口,以及R和命令行界面; 實(shí)用:可以處理類(lèi)別型、數(shù)值型特征; 可擴(kuò)展:支持自定義損失函數(shù)。
缺點(diǎn)
對(duì)于類(lèi)別型特征的處理需要大量的內(nèi)存和時(shí)間; 不同隨機(jī)數(shù)的設(shè)定對(duì)于模型預(yù)測(cè)結(jié)果有一定的影響。
參考CatBoost算法[3]
算法實(shí)現(xiàn)
X = dataset[['open', 'high', 'low', 'volume']].values
y = dataset['Buy_Sell'].values
# pip install catboost
import catboost as cb
from catboost import CatBoostClassifier
from sklearn import metrics
from sklearn.model_selection import train_test_split\
# 調(diào)參,用網(wǎng)格搜索調(diào)出最優(yōu)參數(shù)
# from sklearn.model_selection import GridSearchCV
# params = {'depth': [4, 7, 10],
# 'learning_rate': [0.03, 0.1, 0.15],
# 'l2_leaf_reg': [1, 4, 9],
# 'iterations': [300, 500]}
#cb = cb.CatBoostClassifier()
#cb_model = GridSearchCV(cb, params, scoring="roc_auc", cv=3)
#cb_model.fit(train, y_train)
# 查看最佳分?jǐn)?shù)
# print(cb_model.best_score_)
# 查看最佳參數(shù)
# print(cb_model.best_params_)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
cb = CatBoostClassifier(iterations=5, learning_rate=0.1)
cb.fit(X_train, y_train)
# Categorical features選項(xiàng)的代碼
# cat_features_index = [0, 1, 2]
#clf.fit(train, y_train, cat_features=cat_features_index)
y_pred = cb.predict(X_test)
print('Model is fitted: ' + str(cb.is_fitted()))
print('Model params:')
print(cb.get_params())
print('CatBoost Score:', cb.score(X_test, y_test))
Model is fitted: True
Model params:
{'iterations': 5, 'learning_rate': 0.1}
CatBoost Score: 0.4931506849315068
孤立森林
孤立森林Isolation Forest孤算法是一個(gè)基于Ensemble的快速離群點(diǎn)檢測(cè)方法,具有線(xiàn)性時(shí)間復(fù)雜度和高精準(zhǔn)度,是符合大數(shù)據(jù)處理要求的State-of-the-art算法。由南京大學(xué)周志華教授等人研究開(kāi)發(fā)的算法。
孤立森林的應(yīng)用——異常檢測(cè),可以參見(jiàn):理論結(jié)合實(shí)踐,一文搞定異常檢測(cè)技術(shù)
算法特性
孤立森林適用于連續(xù)數(shù)據(jù)(Continuous numerical data)的異常檢測(cè),與其他異常檢測(cè)算法通過(guò)距離、密度等量化指標(biāo)來(lái)刻畫(huà)樣本間的疏離程度不同,孤立森林算法通過(guò)對(duì)樣本點(diǎn)的孤立來(lái)檢測(cè)異常值。一句話(huà)總結(jié)孤立森林的基本原理:異常樣本相較普通樣本可以通過(guò)較少次數(shù)的隨機(jī)特征分割被孤立出來(lái)。
該算法利用一種名為孤立樹(shù)iTree的二叉搜索樹(shù)結(jié)構(gòu)來(lái)孤立樣本。由于異常值的數(shù)量較少且與大部分樣本的疏離性,因此,異常值會(huì)被更早的孤立出來(lái),也即異常值會(huì)距離iTree的根節(jié)點(diǎn)更近,而正常值則會(huì)距離根節(jié)點(diǎn)有更遠(yuǎn)的距離。此外,相較于LOF,K-means等傳統(tǒng)算法,孤立森林算法對(duì)高緯數(shù)據(jù)有較好的魯棒性。
代碼實(shí)現(xiàn)
X = dataset[['open', 'high', 'low', 'volume']].values
y = dataset['Buy_Sell'].values
# 導(dǎo)入模型
from sklearn import metrics
from sklearn.ensemble import IsolationForest
# 切分訓(xùn)練集合與測(cè)試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
model = IsolationForest()
model.fit(X_test)
"""
IsolationForest(behaviour='old', bootstrap=False, contamination='legacy',
max_features=1.0, max_samples='auto', n_estimators=100,
n_jobs=None, random_state=None, verbose=0)
"""
y_pred = model.predict(X_test)
print('Anomaly Detection Score:')
sklearn_score_anomalies = model.decision_function(X_test)
score = [-1*s + 0.5 for s in sklearn_score_anomalies]
# print(score)
# Anomaly Detection Score:
# [0.5825970683155879, 0.4656309551991878,...]參考資料
LightGBM: https://zhuanlan.zhihu.com/p/99069186
[2]LightGBM原生接口當(dāng)中參數(shù): https://lightgbm.readthedocs.io/en/latest/Parameters.html
[3]CatBoost算法: https://zhuanlan.zhihu.com/p/102540344
往期精彩回顧 本站qq群851320808,加入微信群請(qǐng)掃碼: