
干貨|機器學習算法之集成學習初探
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

一、引子
集成學習作為如今大數(shù)據(jù)比賽中最為常用的學習算法,可以說是所有有進行數(shù)據(jù)挖掘工作的意向的pong友們都應(yīng)該比較關(guān)注的。實際上,我們?nèi)魡为毞Q其為一種“模型”類別是實有不妥的,因為這種學習方式本質(zhì)上,是通過集成單個模型來實現(xiàn)的多模型學習,因此,它更應(yīng)該被稱為是一種學習的“思路”而不是一種“模型”。
下面,我們就開始正式介紹我們的新朋友吧。
二、個體與集成
集成學習(ensemble learning)通過構(gòu)建并結(jié)合多個學習學習器來完成學習任務(wù),有時也被稱為多分類器系統(tǒng)(multi-classifier system)、基于委員會的學習(committee-based learning)
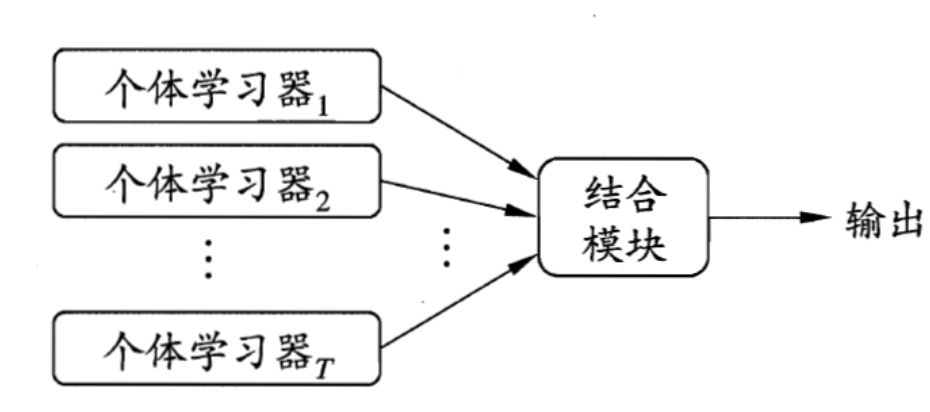
我們可以先用一幅圖來探討一下集成學習的一般結(jié)構(gòu)。
圖中我們可以看出,集成學習先產(chǎn)生一組“個體學習器”(individual learner),再用某種策略將它們結(jié)合起來。通常來說,很多現(xiàn)有的學習算法都足矣從訓練數(shù)據(jù)中產(chǎn)生一個個體學習器,C4.5決策樹,BP神經(jīng)網(wǎng)絡(luò)等等。
一般來說,我們會將這種由個體學習器集成的算法分為兩類,一類是同質(zhì)(homogeneous)的,即集成中僅包含同種類型的額個體學習器,像“決策樹集成”中就僅包含決策樹,“神經(jīng)網(wǎng)絡(luò)集成”中就全是神經(jīng)網(wǎng)絡(luò)。同質(zhì)集成中的個體學習器又稱為基學習器(base learner),相應(yīng)的學習算法也被稱為基學習算法(base learning algorithm)。
第二類就是異質(zhì)(heterogenous)的,相對同質(zhì),異質(zhì)集成中的個體學習其就是由不同的學習算法生成的,這是,個體學習器就被稱為組件學習器(component learner)
三、性能評估
考慮一個簡單的例子,在二分類任務(wù)中,假定三個分類器在三個測試樣本上的表現(xiàn)入下圖所示,其中√代表分類器分類的結(jié)果與實際情況符合,即分類器分類正確,×則代表分類器分類錯誤,集成學習的結(jié)果則由投票法(voting)決出(即“少數(shù)服從多數(shù)”):

可以看出,在a圖中每個分類器只有66.6%的精度的時候,集成學習達到了100%的精度;在b圖中,三個分類器相同導致集成性能沒有提高;c圖中由于每個分類器的精度只有33.3%導致集成學習的效果變得更糟。
由此我們可以看出來,集成學習中對個體學習器的要求應(yīng)該是“好而不同”,即既滿足準確性,又滿足多樣性(diversity),也即是說,學習器既不能太壞,而且學習器與學習器之間也要有差異。
例子雖然具體但未必具有普適性,我們可以做一個稍微簡單的證明:
考慮二分類問題y∈{?1,+1}和真實函數(shù)f,假定基分類器的錯誤率為ε,即對每個基分類器hi有
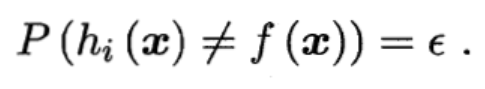
假設(shè)集成通過簡單投票法結(jié)合T個基分類器,若有超過半數(shù)的基分類器正確,則集成分類正確:
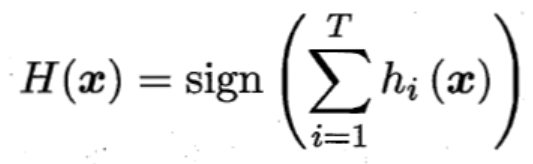
假設(shè)基分類器的錯誤率相互獨立(注意到這是一個相當強的假設(shè)),則由Hoeffding不等式可知,集成的錯誤率為:
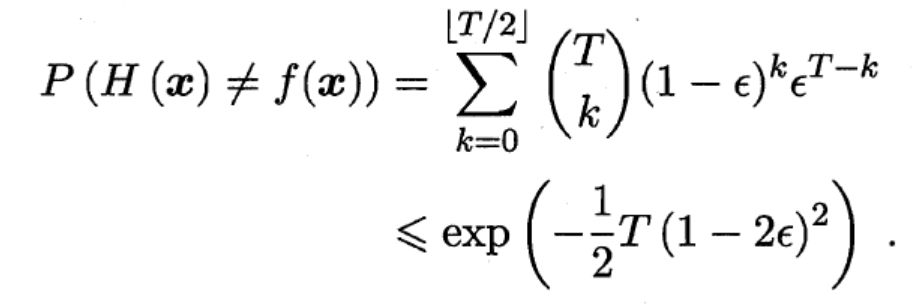

Hoeffding不等式(霍弗丁不等式)是由Wassily Hoeffding在1963年提出并證明的不等式,它的意義是提供一個上限,用于限定隨機變量偏離其期望值的概率。
我們這里不探討Hoeffding不等式的來龍去脈,就簡單的介紹一下,上面那個表達式是怎么由Hoeffding不等式推出來的:
我們假設(shè),拋一枚硬幣其正面朝上的概率為:
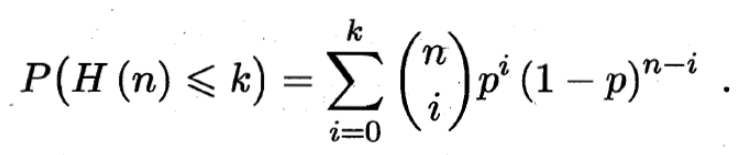
那么對δ>0,k=(p?δ)n,有Hoeffding不等式:
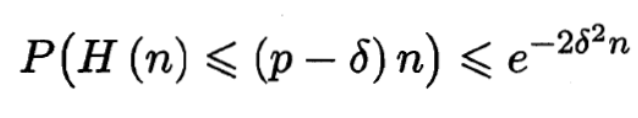
我們的目標是推導出如下式子:
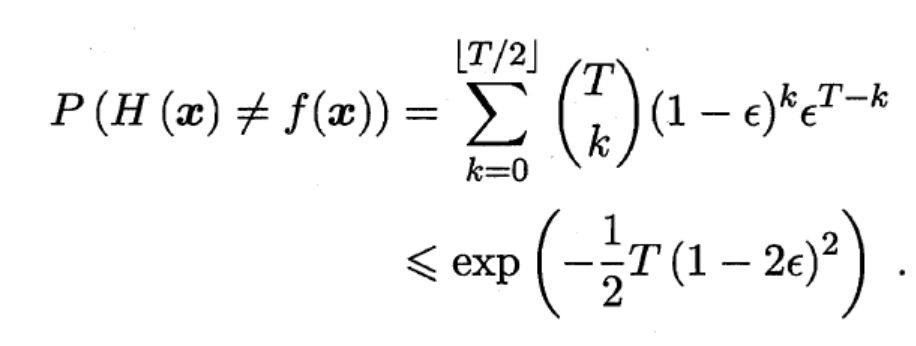
那么,我們知道P(hi(x)≠f(x))=?,H(n)表示硬幣在n次拋擲中朝上的概率,因此P(H(n)≤k)就是這個事件的分布函數(shù)。由H(x)的表達式我們有:
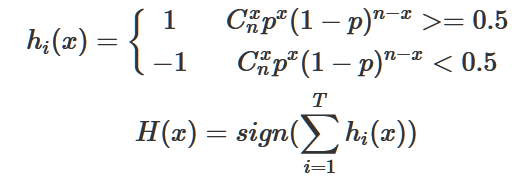
記得我們假設(shè)每個基分類器的錯誤率為?并且相互獨立,這么一來,超過50%的分類器分錯一個事件的概率為:
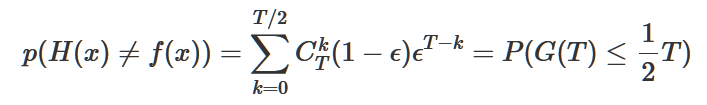
T是分類器總數(shù)。由此我們可以得到
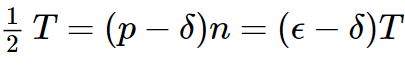
再由Hoeffding不等式得到:
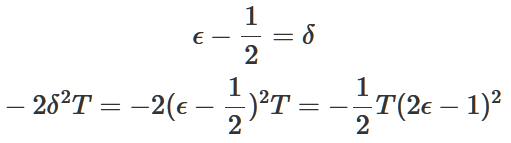
從而推導得出:
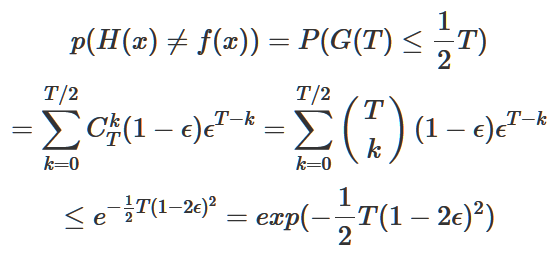
式子得證。
這個式子的意義在于說明,隨著集成中個體分類器數(shù)目T的增大,集成的錯誤率將指數(shù)級下降從而最終趨于0(這里有一個前置條件是個體分類器的錯誤率不能大于50%)。
但有一個問題在于,我們曾假設(shè)各個分類器之間的錯誤率是相互獨立的,而在實際任務(wù)中個體學習器都是被視為解決同一個問題而訓練出來的,這也就意味著它們之間是不可能相互獨立的。換句話說,個體學習器的“準確性”和“多樣性”本身也是存在沖突的。因此,在一般情況下,個體學習器的準確性如果很高,那么想要增加個體學習器的多樣性就必然需要在其準確性上做出一定的犧牲,反之亦然。因此,如何產(chǎn)生“好而不同”的個體學習器,便成為了集成學習研究的核心。
四、總覽
根據(jù)個體學習器的生成方式,周志華教授將目前集成學習方法分為了兩大類,一類是個體學習器之間存在強依賴關(guān)系、必須串行生成的序列化方法,這類方法的代表為提升(Boosting)方法;另一類是個體學習器間不存在強依賴關(guān)系,可同時生成的并行化方法,這類方法的代表為Bagging和隨機森林(Random Forest)。
這一篇簡短的介紹就先到這里,作為集成學習初探,我們就先簡單的介紹一下集成學習的概念,以及集成學習探索的方向,而之后我們關(guān)于集成學習的內(nèi)容,就是對于這兩大類以及其中比較具有代表性的集成學習模型的介紹,這其中包括在目前大數(shù)據(jù)處理中都非常常用的幾個經(jīng)典模型。
好消息!
小白學視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學視覺」公眾號后臺回復(fù):擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學視覺」公眾號后臺回復(fù):Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學視覺」公眾號后臺回復(fù):OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~