
原理+代碼|Python實戰(zhàn)多元線性回歸模型
點擊上方“Python爬蟲與數(shù)據(jù)挖掘”,進行關(guān)注
回復(fù)“書籍”即可獲贈Python從入門到進階共10本電子書
前言
「多元線性回歸模型」非常常見,是大多數(shù)人入門機器學(xué)習(xí)的第一個案例,盡管如此,里面還是有許多值得學(xué)習(xí)和注意的地方。其中多元共線性這個問題將貫穿所有的機器學(xué)習(xí)模型,所以本文會「將原理知識穿插于代碼段中」,爭取以不一樣的視角來敘述和講解「如何更好的構(gòu)建和優(yōu)化多元線性回歸模型」。主要將分為兩個部分:
詳細原理 Python 實戰(zhàn)
Python 實戰(zhàn)
Python 多元線性回歸的模型的實戰(zhàn)案例有非常多,這里雖然選用的經(jīng)典的房價預(yù)測,但貴在的流程簡潔完整,其中用到的精度優(yōu)化方法效果拔群,能提供比較好的參考價值。
數(shù)據(jù)探索
本文的數(shù)據(jù)集是經(jīng)過清洗的美國某地區(qū)的房價數(shù)據(jù)集
import?pandas?as?pd
import?numpy?as?np
import?seaborn?as?sns
import?matplotlib.pyplot?as?plt
df?=?pd.read_csv('house_prices.csv')
df.info();df.head()
 參數(shù)說明:
參數(shù)說明:
neighborhood/area:所屬街區(qū)和面積bedrooms/bathrooms:臥室和浴室style:房屋樣式
多元線性回歸建模
現(xiàn)在我們直接構(gòu)建多元線性回歸模型
from?statsmodels.formula.api?import?ols
??????????????????????#?小寫的?ols?函數(shù)才會自帶截距項,OLS?則不會
?????????#?固定格式:因變量?~?自變量(+?號連接)
lm?=?ols('price?~?area?+?bedrooms?+?bathrooms',?data=df).fit()
lm.summary()
紅框為我們關(guān)注的結(jié)果值,其中截距項Intercept的 P 值沒有意義,可以不用管它
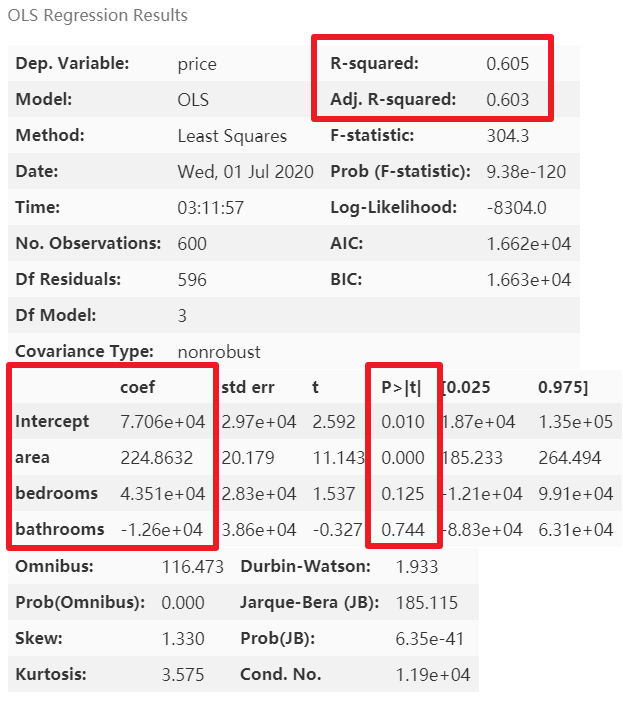
模型優(yōu)化
從上圖可以看到,模型的精度較低,因為還有類別變量neighborhood和style沒有完全利用。這里我們先查看一下類別變量的類別分布情況:
#?類別變量,又稱為名義變量,nominal?variables
nominal_vars?=?['neighborhood',?'style']
for?each?in?nominal_vars:
????print(each,?':')
????print(df[each].agg(['value_counts']).T)??#?Pandas?騷操作
????#?直接?.value_counts().T?無法實現(xiàn)下面的效果
?????##?必須得?agg,而且里面的中括號?[]?也不能少
????print('='*35)
虛擬變量的設(shè)置
因為類別變量無法直接放入模型,這里需要轉(zhuǎn)換一下,而多元線性回歸模型中類別變量的轉(zhuǎn)換最常用的方法之一便是將其轉(zhuǎn)化成虛擬變量。原理其實非常簡單,將無法直接用于建模的名義變量轉(zhuǎn)換成可放入模型的虛擬變量的核心就短短八個字:「四散拆開,非此即彼」。下面用一個只有 4 行的微型數(shù)據(jù)集輔以說明。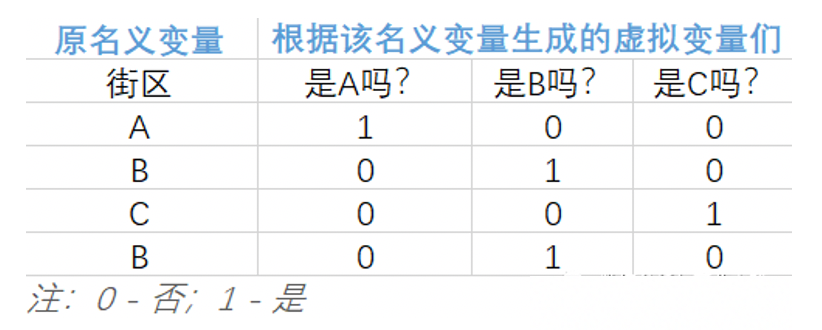 從上表中,不難發(fā)現(xiàn):
從上表中,不難發(fā)現(xiàn):
該名義變量有 n 類,就能拆分出 n 個虛擬變量 巧妙的使用 0 和 1 來達到「用虛擬變量列代替原名義變量所在類別」
接下來要做的就是將生成的虛擬變量們放入多元線性回歸模型,但要注意的是:「轉(zhuǎn)化后的虛擬變量們需要舍棄一個」,才能得到滿秩矩陣。具體原因和有關(guān)線性代數(shù)的解釋可以查看筆者打包好的論文,我們可以理解為,當(dāng)該名義變量可劃分為 n 類時,只需要 n-1 個虛擬變量就已足夠獲知所有信息了。該丟棄哪個,可根據(jù)實際情況來決定。 因此為原數(shù)據(jù)集的某名義變量添加虛擬變量的步驟為:
因此為原數(shù)據(jù)集的某名義變量添加虛擬變量的步驟為:
抽出希望轉(zhuǎn)換的名義變量(一個或多個) pandas的get_dummies函數(shù)與原數(shù)據(jù)集橫向拼接
 注意虛擬變量設(shè)置成功后,需要與原來的數(shù)據(jù)集拼接,這樣才能將其一起放進模型。
注意虛擬變量設(shè)置成功后,需要與原來的數(shù)據(jù)集拼接,這樣才能將其一起放進模型。 再次建模后,發(fā)現(xiàn)模型精度大大提升,但潛在的多元共線性問題也隨之顯現(xiàn)出來
再次建模后,發(fā)現(xiàn)模型精度大大提升,但潛在的多元共線性問題也隨之顯現(xiàn)出來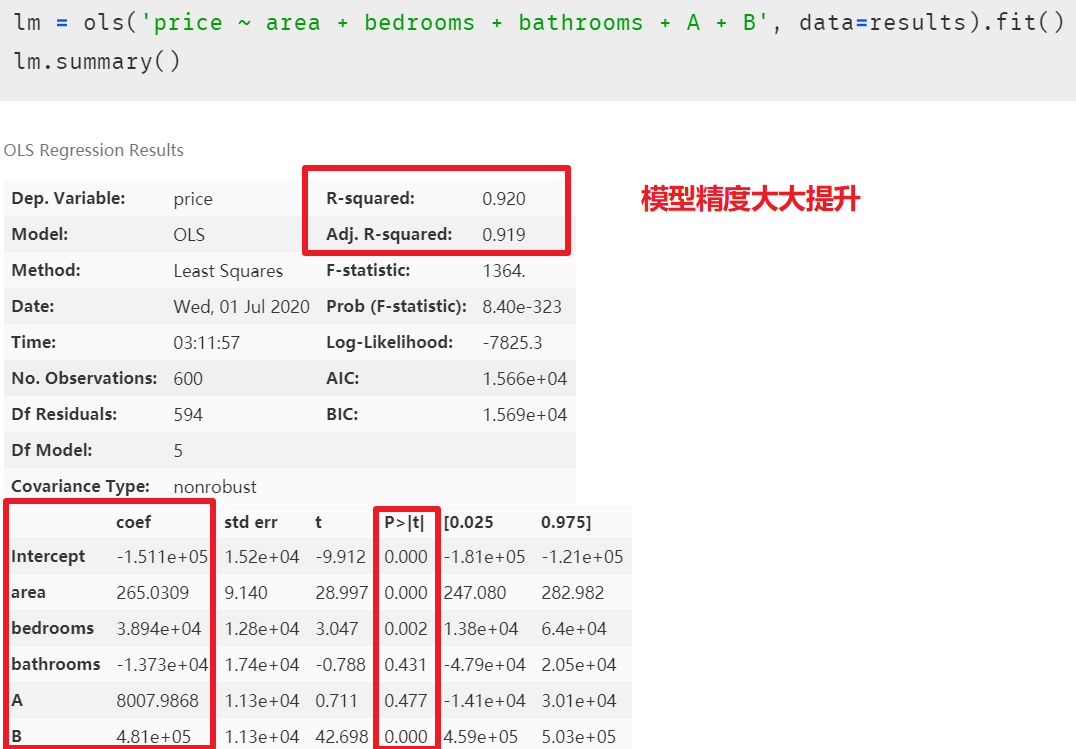 在解釋模型中虛擬變量的系數(shù)之前,我們先消除模型中多元共線性的影響,因為在排除共線性后,模型中的各個自變量的系數(shù)又會改變,最終的多元線性回歸模型的等式又會不一樣。多重線性回歸模型的主要假設(shè)之一是我們的預(yù)測變量(自變量)彼此不相關(guān)。我們希望預(yù)測變量(自變量)與反應(yīng)變量(因變量)相關(guān),而不是彼此之間具有相關(guān)性。
在解釋模型中虛擬變量的系數(shù)之前,我們先消除模型中多元共線性的影響,因為在排除共線性后,模型中的各個自變量的系數(shù)又會改變,最終的多元線性回歸模型的等式又會不一樣。多重線性回歸模型的主要假設(shè)之一是我們的預(yù)測變量(自變量)彼此不相關(guān)。我們希望預(yù)測變量(自變量)與反應(yīng)變量(因變量)相關(guān),而不是彼此之間具有相關(guān)性。方差膨脹因子(Variance Inflation Factor,以下簡稱VIF),是「指解釋變量之間存在多重共線性時的方差與不存在多重共線性時的方差之比」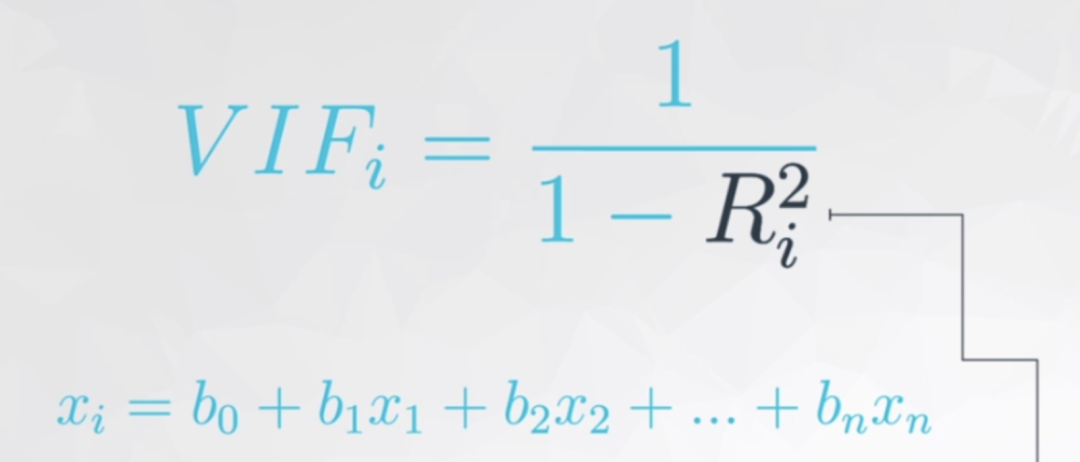 上圖公式可以看出在方差膨脹因子的檢測中:
上圖公式可以看出在方差膨脹因子的檢測中:
每個自變量都會有一個膨脹因子值 ,最后根據(jù)值的大小來選擇是否刪減 「既然 表示相關(guān)性,是誰跟誰的相關(guān)性呢?」 是自變量中的某一變量與除它外剩余的自變量進行多元線性回歸,取回歸結(jié)果,即 模型精度來作為這個變量與剩余自變量的相關(guān)性。聽起來可能有點繞,這里舉一下實例(用 “面積、臥室數(shù)量和浴室數(shù)量” 作為自變量來預(yù)測房價,在進行自變量的方差膨脹因子的檢測時,面積、臥室數(shù)和浴室數(shù)輪流做單獨的因變量,剩下的兩個變量作為自變量,來看看這三個自變量中那個變量對其余兩個變量的解釋性高)越大,如已經(jīng)到了 0.9,那分母就很小, 的值就等于 10,即表示這個自變量已經(jīng)同時解釋了另外的某個或多個自變量,存在多元共線性,可以考慮刪除一些自變量。
越大,顯示共線性越嚴(yán)重。經(jīng)驗判斷方法表明:「當(dāng) ,不存在多重共線性;當(dāng) ,存在較強的多重共線性;當(dāng) ,存在嚴(yán)重多重共線性」。
方差膨脹因子的檢測
我們自己來寫一個方差膨脹因子的檢測函數(shù)
def?vif(df,?col_i):
????"""
????df:?整份數(shù)據(jù)
??? col_i:被檢測的列名
????"""
????cols?=?list(df.columns)
????cols.remove(col_i)
????cols_noti?=?cols
????formula?=?col_i?+?'~'?+?'+'.join(cols_noti)
????r2?=?ols(formula,?df).fit().rsquared
????return?1.?/?(1.?-?r2)
現(xiàn)在進行檢測
test_data?=?results[['area',?'bedrooms',?'bathrooms',?'A',?'B']]
for?i?in?test_data.columns:
????print(i,?'\t',?vif(df=test_data,?col_i=i))
發(fā)現(xiàn)bedrooms和bathrooms存在強相關(guān)性,可能這兩個變量是解釋同一個問題,方差膨脹因子較大的自變量通常是成對出現(xiàn)的。 果然,
果然,bedrooms和bathrooms這兩個變量的方差膨脹因子較高,這里刪除自變量bedrooms再次進行建模
lm?=?ols(formula='price?~?area?+?bathrooms?+?A?+?B',?data=results).fit()
lm.summary()
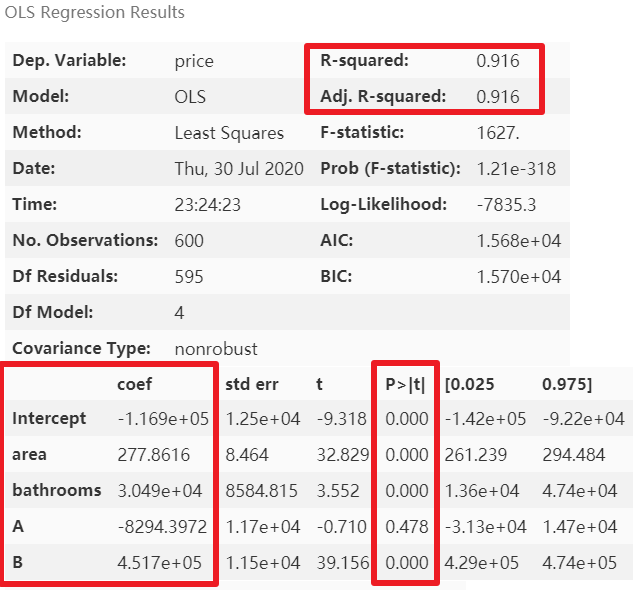 模型精度稍降,但消除了多元共線性后能夠使模型的泛化能力提升。再次進行多元共線性檢測
模型精度稍降,但消除了多元共線性后能夠使模型的泛化能力提升。再次進行多元共線性檢測
test_data?=?results[['area',?'bedrooms',?'A',?'B']]
for?i?in?test_data.columns:
????print(i,?'\t',?vif(df=test_data,?col_i=i))
 那么多元共線性就「只有通過方差膨脹因子才能看的出來嗎?」 其實并不一定,通過結(jié)合散點圖或相關(guān)稀疏矩陣和模型中自變量的系數(shù)也能看出端倪。下圖是未處理多元共線性時的自變量系數(shù)。
那么多元共線性就「只有通過方差膨脹因子才能看的出來嗎?」 其實并不一定,通過結(jié)合散點圖或相關(guān)稀疏矩陣和模型中自變量的系數(shù)也能看出端倪。下圖是未處理多元共線性時的自變量系數(shù)。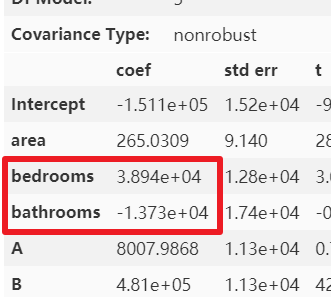 可以很明顯的看出,
可以很明顯的看出,bathrooms的參數(shù)很可能是有問題的,怎么可能bathrooms的數(shù)據(jù)量每增加一個,房屋總價還減少 1.373*10 的四次方美元呢?簡單的畫個散點圖和熱力圖也應(yīng)該知道房屋總價與bathrooms 個數(shù)應(yīng)該是成正比例關(guān)系的。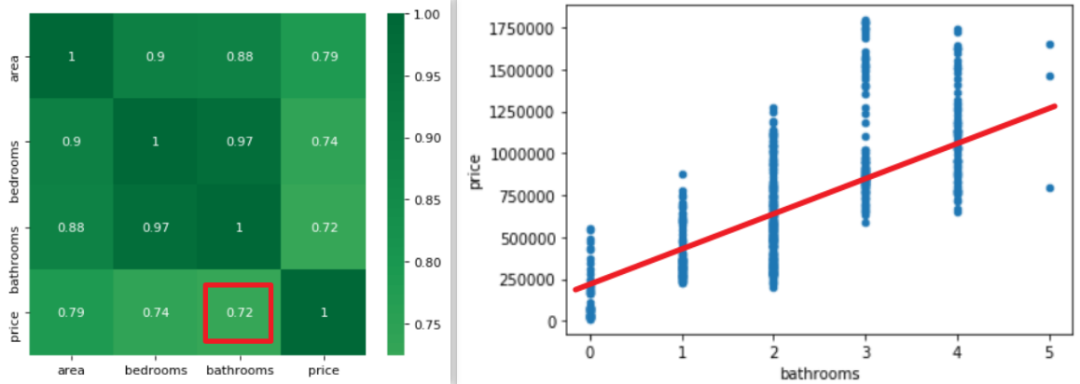
模型解釋
多元線性回歸模型的可解釋性比較強,將模型參數(shù)打印出來即可求出因變量與自變量的關(guān)系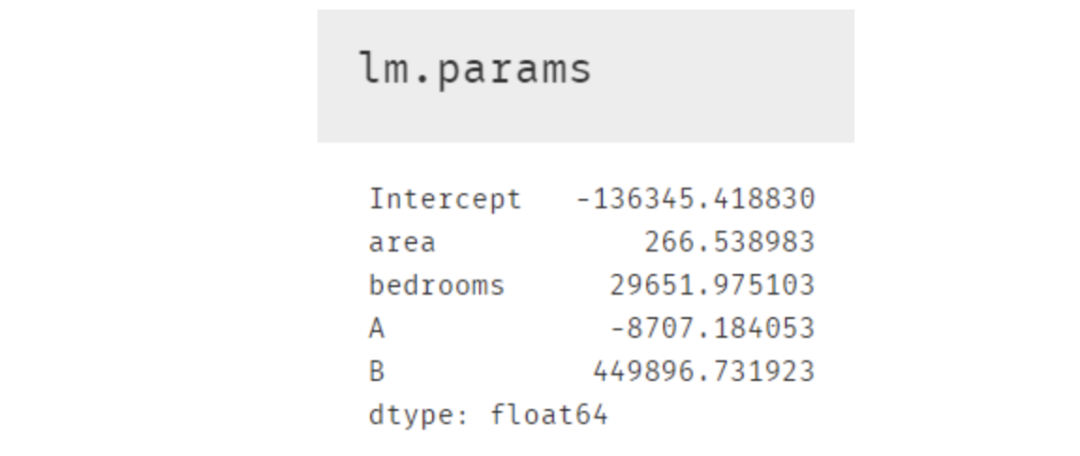 所以最終的建模結(jié)果如下,且該模型的精度為0.916
所以最終的建模結(jié)果如下,且該模型的精度為0.916
另外在等式結(jié)果中,截距項Intercept和area,bedrooms等變量的系數(shù)都還好理解;A,B 這兩個虛擬變量可能相對困難些。其實根據(jù)原理部分的表格來看,如果房屋在 C 區(qū),那等式中 A 和 B 這兩個字母的值便是 0,所以這便引出了非常重要的一點:使用了虛擬變量的多元線性回歸模型結(jié)果中,存在于模型內(nèi)的虛擬變量都是跟被刪除掉的那個虛擬變量進行比較。所以這個結(jié)果便表示在其他情況完全一樣時(即除虛擬變量外的項)A 區(qū)的房屋比 C 區(qū)低 8707.18 美元,B 區(qū)則比 C 區(qū)貴 449896.73.7 美元。當(dāng)然我們也可以畫個箱線圖來查看與檢驗,發(fā)現(xiàn)結(jié)果正如模型中 A 與 B 的系數(shù)那般顯示。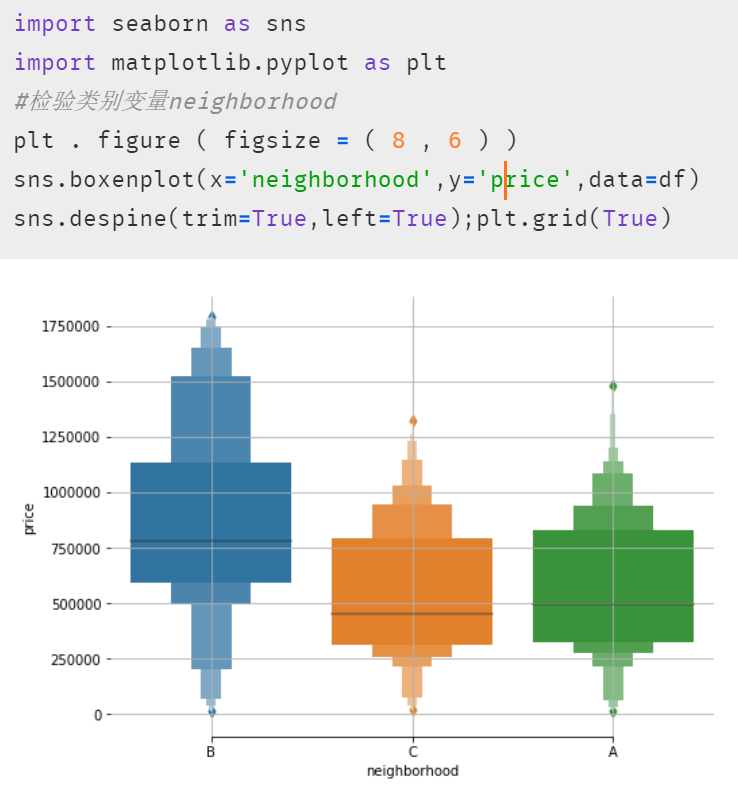
小結(jié)
本文以多元線性回歸為基礎(chǔ)和前提,在因變量房價與多個自變量的實際觀測值建立了多元線性回歸模型;分析并檢驗各個預(yù)測變量對因變量的綜合線性影響的顯著性,并盡可能的消除多重共線性的影響,篩選出因變量有顯著線性影響的自變量,對基準(zhǔn)模型進行優(yōu)化,并對各自變量相對重要性進行評定,進而提升了回歸模型的預(yù)測精度。如果對本文的源數(shù)據(jù)和代碼感興趣,可以在后臺回復(fù)數(shù)據(jù)挖掘進行獲取,我們下個案例見。
-------------------?End?-------------------
往期精彩文章推薦:
【進階篇】Python+Go——帶大家一起另尋途徑提高計算性能
手把手教你用Python做個可視化的“剪刀石頭布”小游戲
Python基礎(chǔ)語法——代碼規(guī)范&判斷語句&循環(huán)語句

歡迎大家點贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請在后臺回復(fù)【入群】
萬水千山總是情,點個【在看】行不行
/今日留言主題/
隨便說一兩句吧~~