
Python 用5行代碼學(xué)機器學(xué)習(xí)—線性回歸
之前Python實用寶典講過許多關(guān)于機器學(xué)習(xí)的文章,比如:
1.Python 短文本自動識別個體是否有自殺傾向
2.如何基于Paddle快速訓(xùn)練一個98%準(zhǔn)確率的抑郁文本預(yù)測模型?
3.[準(zhǔn)確率:98%] 改進樸素貝葉斯自動分類食品安全新聞
4.在泰坦尼克號上你能活下來嗎?Python告訴你
5.準(zhǔn)確率94%!Python 機器學(xué)習(xí)識別微博或推特機器人
等等... 但是這些文章所使用到的機器學(xué)習(xí)模型,讀者在第一次閱讀的時候可能完全不了解或不會使用。
為了解決這樣的問題,我準(zhǔn)備使用scikit-learn給大家介紹一些模型的基礎(chǔ)知識,今天就來講講線性回歸模型。
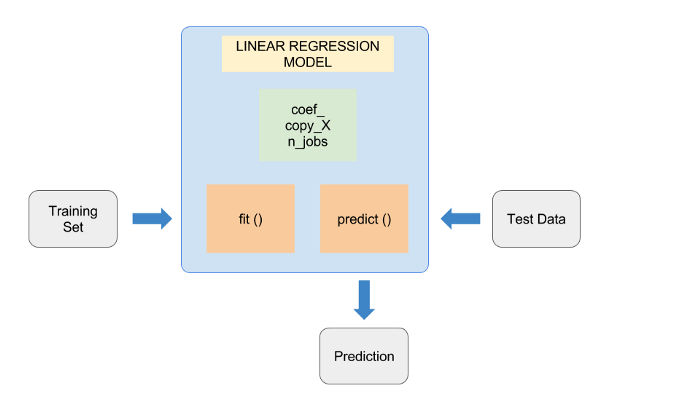
1.準(zhǔn)備
開始之前,你要確保Python和pip已經(jīng)成功安裝在電腦上,如果沒有,可以訪問這篇文章:超詳細(xì)Python安裝指南?進行安裝。
(可選1)?如果你用Python的目的是數(shù)據(jù)分析,可以直接安裝Anaconda:Python數(shù)據(jù)分析與挖掘好幫手—Anaconda,它內(nèi)置了Python和pip.
(可選2)?此外,推薦大家用VSCode編輯器,它有許多的優(yōu)點:Python 編程的最好搭檔—VSCode 詳細(xì)指南。
請選擇以下任一種方式輸入命令安裝依賴:
1. Windows 環(huán)境 打開 Cmd (開始-運行-CMD)。
2. MacOS 環(huán)境 打開 Terminal (command+空格輸入Terminal)。
3. 如果你用的是 VSCode編輯器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install?scikit-learn2.簡單的訓(xùn)練集
冬天快到了,深圳這幾天已經(jīng)準(zhǔn)備開始入冬了。
從生活入手,外界溫度對是否穿外套的影響是具有線性關(guān)系的:
| 外界溫度 | 是否穿外套 |
| 30度 | 不 |
| 25度 | 不 |
| 20度 | 不 |
| 15度 | 是 |
| 10度 | 是 |
現(xiàn)在,考慮這樣的一個問題:如果深圳的溫度是12度,我們應(yīng)不應(yīng)該穿外套?
這個問題很簡單,上述簡單的訓(xùn)練集中,我們甚至不需要機器學(xué)習(xí)就能輕易地得到答案:應(yīng)該。但如果訓(xùn)練集變得稍顯復(fù)雜一些呢:
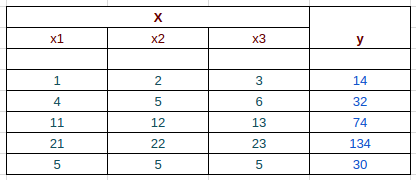
你能看出其中x1, x2, x3和y之間的規(guī)律嗎?
比較難,但是如果你有足夠的數(shù)據(jù)(比如100個),機器學(xué)習(xí)能夠迅速解決這個問題。
為了方便展示機器學(xué)習(xí)的威力,我們在這里生產(chǎn)100個這樣的訓(xùn)練集(公式為: y=x1 + 2*x2 + 3*x3):
from?random import?randint
TRAIN_SET_LIMIT = 1000
TRAIN_SET_COUNT = 100
TRAIN_INPUT = list()
TRAIN_OUTPUT = list()
for?i in?range(TRAIN_SET_COUNT):
????a = randint(0, TRAIN_SET_LIMIT)
????b = randint(0, TRAIN_SET_LIMIT)
????c = randint(0, TRAIN_SET_LIMIT)
????op = a + (2*b) + (3*c)
????TRAIN_INPUT.append([a, b, c])
????TRAIN_OUTPUT.append(op)然后讓線性回歸模型使用該訓(xùn)練集(Training Set)進行訓(xùn)練(fit),然后再給定三個參數(shù)(Test Data),進行預(yù)測(predict),讓它得到y(tǒng)值(Prediction),如下圖所示。
3.訓(xùn)練和測試
為什么我使用sklearn?因為它真的真的很方便。像這樣的訓(xùn)練行為,你只需要3行代碼就能搞定:
from?sklearn.linear_model import?LinearRegression
predictor = LinearRegression(n_jobs=-1)
predictor.fit(X=TRAIN_INPUT, y=TRAIN_OUTPUT)需要注意線性回歸模型(LinearRegression)的參數(shù):
n_jobs:默認(rèn)為1,表示使用CPU的個數(shù)。當(dāng)-1時,代表使用全部CPU
predictor.fit 即訓(xùn)練模型,X是我們在生成訓(xùn)練集時的TRAIN_INPUT,Y即TRAIN_OUTPUT.
訓(xùn)練完就可以立即進行測試了,調(diào)用predict函數(shù)即可:
X_TEST = [[10, 20, 30]]
outcome = predictor.predict(X=X_TEST)
coefficients = predictor.coef_
print('Outcome : {}\nCoefficients : {}'.format(outcome, coefficients))這里的 coefficients 是指系數(shù),即x1, x2, x3.
得到的結(jié)果如下:
Outcome : [ 140.]
Coefficients : [ 1. 2. 3.]驗證一下:10 + 20*2 + 30*3 = 140 完全正確。
如何,機器學(xué)習(xí)模型,用起來其實真的沒你想象中的那么難,大部分人很可能只是卡在了安裝 scikit-learn 的路上...
順便給大家留個小練習(xí),將下列歐式距離,使用線性回歸模型進行表示。
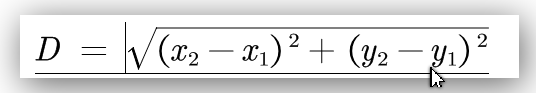
解決思路和本文的方案其實是類似的,只不過需要變通一下。
解決出來的同學(xué)可在后臺回復(fù):加群,將代碼發(fā)給我驗證,領(lǐng)取一份小紅包并進入Python實用寶典的高質(zhì)量學(xué)習(xí)交流群哦。
我們的文章到此就結(jié)束啦,如果你喜歡今天的Python 實戰(zhàn)教程,請持續(xù)關(guān)注Python實用寶典。
原創(chuàng)不易,希望你能在下面點個贊和在看支持我繼續(xù)創(chuàng)作,謝謝!
點擊下方閱讀原文可獲得更好的閱讀體驗
Python實用寶典?(pythondict.com)
不只是一個寶典
歡迎關(guān)注公眾號:Python實用寶典