
原理+代碼|Python實(shí)戰(zhàn)多元線性回歸模型

本文是Python商業(yè)數(shù)據(jù)挖掘?qū)崙?zhàn)的第4篇
前言
「多元線性回歸模型」非常常見,是大多數(shù)人入門機(jī)器學(xué)習(xí)的第一個(gè)案例,盡管如此,里面還是有許多值得學(xué)習(xí)和注意的地方。其中多元共線性這個(gè)問題將貫穿所有的機(jī)器學(xué)習(xí)模型,所以本文會(huì)「將原理知識(shí)穿插于代碼段中」,爭(zhēng)取以不一樣的視角來敘述和講解「如何更好的構(gòu)建和優(yōu)化多元線性回歸模型」。主要將分為兩個(gè)部分:
詳細(xì)原理 Python 實(shí)戰(zhàn)
Python 實(shí)戰(zhàn)
Python 多元線性回歸的模型的實(shí)戰(zhàn)案例有非常多,這里雖然選用的經(jīng)典的房?jī)r(jià)預(yù)測(cè),但貴在的流程簡(jiǎn)潔完整,其中用到的精度優(yōu)化方法效果拔群,能提供比較好的參考價(jià)值。
數(shù)據(jù)探索
本文的數(shù)據(jù)集是經(jīng)過清洗的美國(guó)某地區(qū)的房?jī)r(jià)數(shù)據(jù)集
import?pandas?as?pd
import?numpy?as?np
import?seaborn?as?sns
import?matplotlib.pyplot?as?plt
df?=?pd.read_csv('house_prices.csv')
df.info();df.head()
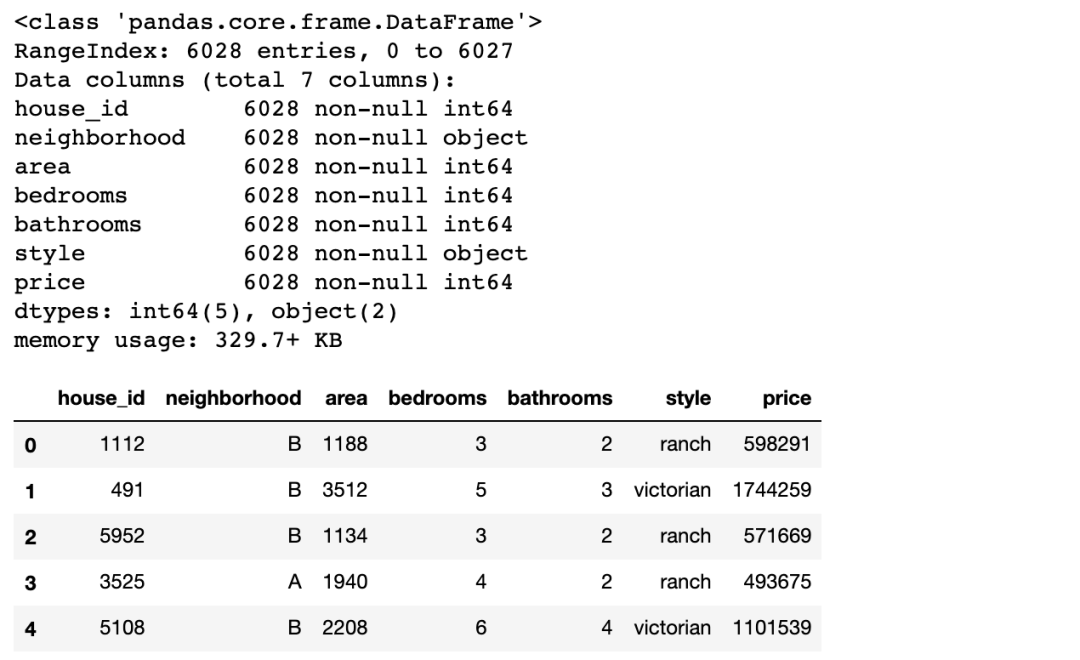 參數(shù)說明:
參數(shù)說明:
neighborhood/area:所屬街區(qū)和面積bedrooms/bathrooms:臥室和浴室style:房屋樣式
多元線性回歸建模
現(xiàn)在我們直接構(gòu)建多元線性回歸模型
from?statsmodels.formula.api?import?ols
??????????????????????#?小寫的?ols?函數(shù)才會(huì)自帶截距項(xiàng),OLS?則不會(huì)
?????????#?固定格式:因變量?~?自變量(+?號(hào)連接)
lm?=?ols('price?~?area?+?bedrooms?+?bathrooms',?data=df).fit()
lm.summary()
紅框?yàn)槲覀冴P(guān)注的結(jié)果值,其中截距項(xiàng)Intercept的 P 值沒有意義,可以不用管它
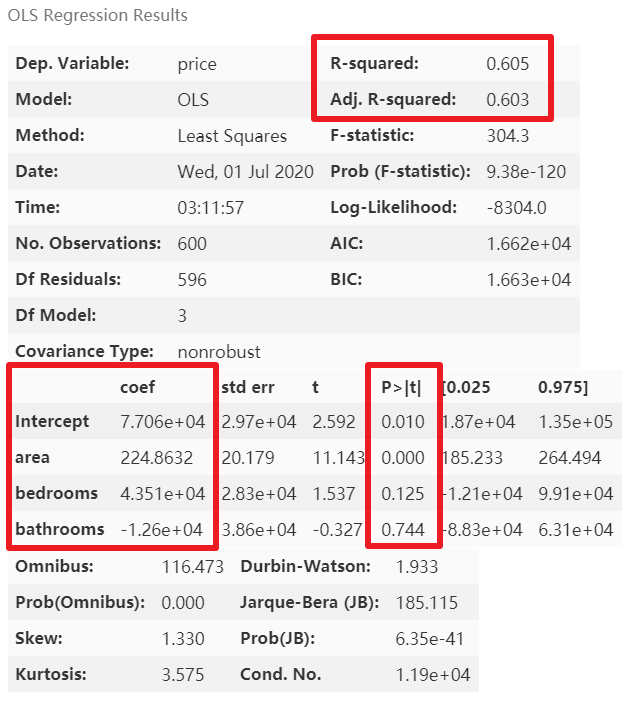
模型優(yōu)化
從上圖可以看到,模型的精度較低,因?yàn)檫€有類別變量neighborhood和style沒有完全利用。這里我們先查看一下類別變量的類別分布情況:
#?類別變量,又稱為名義變量,nominal?variables
nominal_vars?=?['neighborhood',?'style']
for?each?in?nominal_vars:
????print(each,?':')
????print(df[each].agg(['value_counts']).T)??#?Pandas?騷操作
????#?直接?.value_counts().T?無法實(shí)現(xiàn)下面的效果
?????##?必須得?agg,而且里面的中括號(hào)?[]?也不能少
????print('='*35)
虛擬變量的設(shè)置
因?yàn)轭悇e變量無法直接放入模型,這里需要轉(zhuǎn)換一下,而多元線性回歸模型中類別變量的轉(zhuǎn)換最常用的方法之一便是將其轉(zhuǎn)化成虛擬變量。原理其實(shí)非常簡(jiǎn)單,將無法直接用于建模的名義變量轉(zhuǎn)換成可放入模型的虛擬變量的核心就短短八個(gè)字:「四散拆開,非此即彼」。下面用一個(gè)只有 4 行的微型數(shù)據(jù)集輔以說明。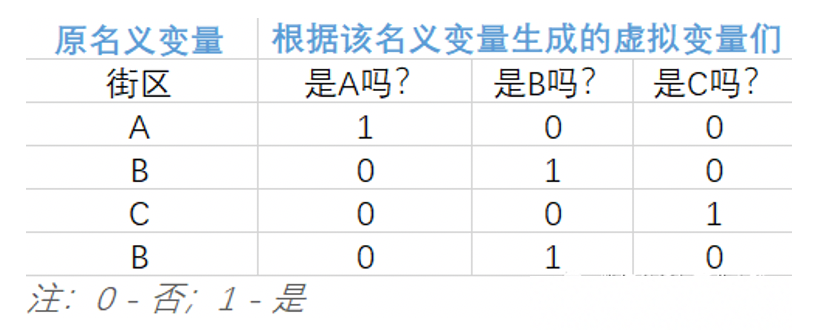 從上表中,不難發(fā)現(xiàn):
從上表中,不難發(fā)現(xiàn):
該名義變量有 n 類,就能拆分出 n 個(gè)虛擬變量 巧妙的使用 0 和 1 來達(dá)到「用虛擬變量列代替原名義變量所在類別」
接下來要做的就是將生成的虛擬變量們放入多元線性回歸模型,但要注意的是:「轉(zhuǎn)化后的虛擬變量們需要舍棄一個(gè)」,才能得到滿秩矩陣。具體原因和有關(guān)線性代數(shù)的解釋可以查看筆者打包好的論文,我們可以理解為,當(dāng)該名義變量可劃分為 n 類時(shí),只需要 n-1 個(gè)虛擬變量就已足夠獲知所有信息了。該丟棄哪個(gè),可根據(jù)實(shí)際情況來決定。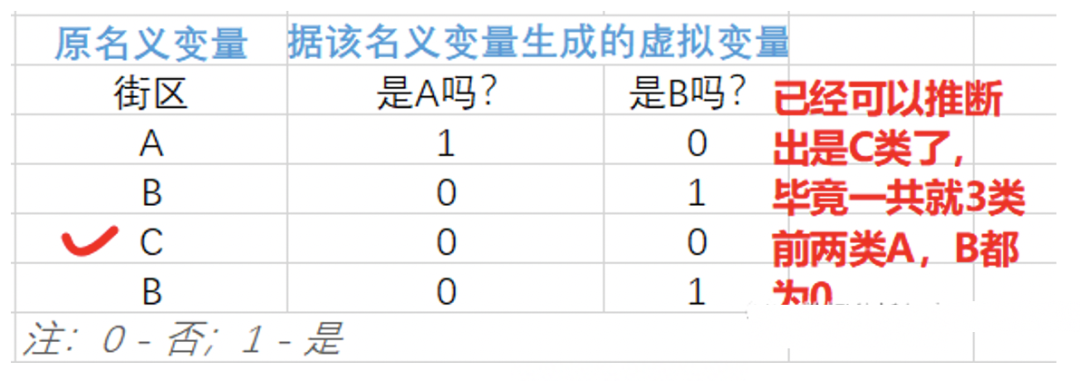 因此為原數(shù)據(jù)集的某名義變量添加虛擬變量的步驟為:
因此為原數(shù)據(jù)集的某名義變量添加虛擬變量的步驟為:
抽出希望轉(zhuǎn)換的名義變量(一個(gè)或多個(gè)) pandas的get_dummies函數(shù)與原數(shù)據(jù)集橫向拼接
 注意虛擬變量設(shè)置成功后,需要與原來的數(shù)據(jù)集拼接,這樣才能將其一起放進(jìn)模型。
注意虛擬變量設(shè)置成功后,需要與原來的數(shù)據(jù)集拼接,這樣才能將其一起放進(jìn)模型。 再次建模后,發(fā)現(xiàn)模型精度大大提升,但潛在的多元共線性問題也隨之顯現(xiàn)出來
再次建模后,發(fā)現(xiàn)模型精度大大提升,但潛在的多元共線性問題也隨之顯現(xiàn)出來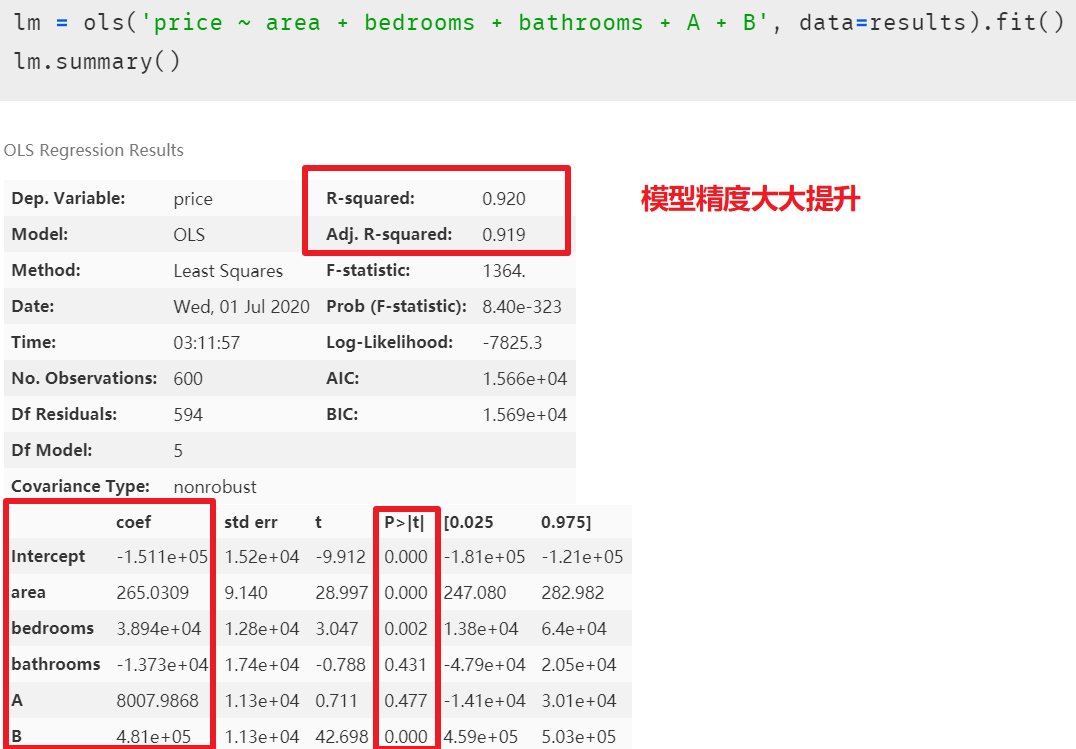 在解釋模型中虛擬變量的系數(shù)之前,我們先消除模型中多元共線性的影響,因?yàn)樵谂懦簿€性后,模型中的各個(gè)自變量的系數(shù)又會(huì)改變,最終的多元線性回歸模型的等式又會(huì)不一樣。多重線性回歸模型的主要假設(shè)之一是我們的預(yù)測(cè)變量(自變量)彼此不相關(guān)。我們希望預(yù)測(cè)變量(自變量)與反應(yīng)變量(因變量)相關(guān),而不是彼此之間具有相關(guān)性。
在解釋模型中虛擬變量的系數(shù)之前,我們先消除模型中多元共線性的影響,因?yàn)樵谂懦簿€性后,模型中的各個(gè)自變量的系數(shù)又會(huì)改變,最終的多元線性回歸模型的等式又會(huì)不一樣。多重線性回歸模型的主要假設(shè)之一是我們的預(yù)測(cè)變量(自變量)彼此不相關(guān)。我們希望預(yù)測(cè)變量(自變量)與反應(yīng)變量(因變量)相關(guān),而不是彼此之間具有相關(guān)性。方差膨脹因子(Variance Inflation Factor,以下簡(jiǎn)稱VIF),是「指解釋變量之間存在多重共線性時(shí)的方差與不存在多重共線性時(shí)的方差之比」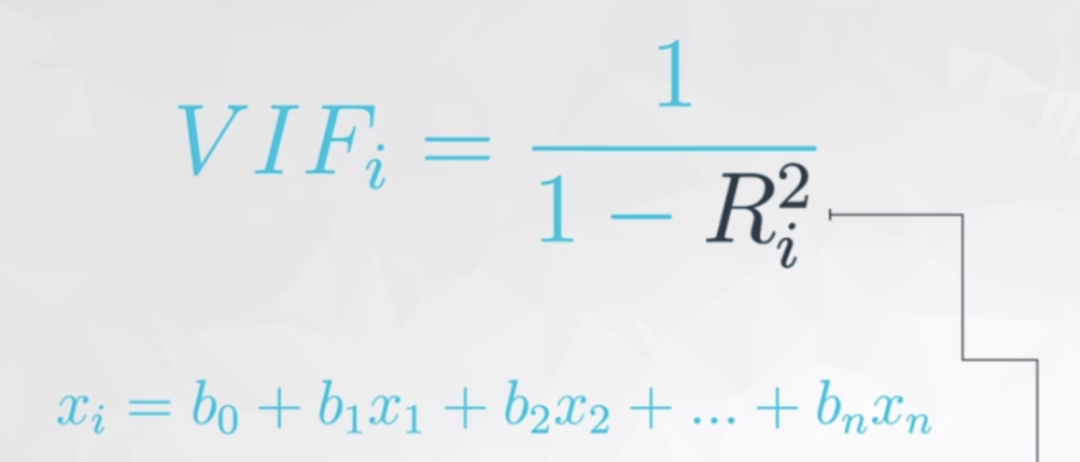 上圖公式可以看出在方差膨脹因子的檢測(cè)中:
上圖公式可以看出在方差膨脹因子的檢測(cè)中:
每個(gè)自變量都會(huì)有一個(gè)膨脹因子值 ,最后根據(jù)值的大小來選擇是否刪減 「既然 表示相關(guān)性,是誰跟誰的相關(guān)性呢?」 是自變量中的某一變量與除它外剩余的自變量進(jìn)行多元線性回歸,取回歸結(jié)果,即 模型精度來作為這個(gè)變量與剩余自變量的相關(guān)性。聽起來可能有點(diǎn)繞,這里舉一下實(shí)例(用 “面積、臥室數(shù)量和浴室數(shù)量” 作為自變量來預(yù)測(cè)房?jī)r(jià),在進(jìn)行自變量的方差膨脹因子的檢測(cè)時(shí),面積、臥室數(shù)和浴室數(shù)輪流做單獨(dú)的因變量,剩下的兩個(gè)變量作為自變量,來看看這三個(gè)自變量中那個(gè)變量對(duì)其余兩個(gè)變量的解釋性高)越大,如已經(jīng)到了 0.9,那分母就很小, 的值就等于 10,即表示這個(gè)自變量已經(jīng)同時(shí)解釋了另外的某個(gè)或多個(gè)自變量,存在多元共線性,可以考慮刪除一些自變量。
越大,顯示共線性越嚴(yán)重。經(jīng)驗(yàn)判斷方法表明:「當(dāng) ,不存在多重共線性;當(dāng) ,存在較強(qiáng)的多重共線性;當(dāng) ,存在嚴(yán)重多重共線性」。
方差膨脹因子的檢測(cè)
我們自己來寫一個(gè)方差膨脹因子的檢測(cè)函數(shù)
def?vif(df,?col_i):
????"""
????df:?整份數(shù)據(jù)
??? col_i:被檢測(cè)的列名
????"""
????cols?=?list(df.columns)
????cols.remove(col_i)
????cols_noti?=?cols
????formula?=?col_i?+?'~'?+?'+'.join(cols_noti)
????r2?=?ols(formula,?df).fit().rsquared
????return?1.?/?(1.?-?r2)
現(xiàn)在進(jìn)行檢測(cè)
test_data?=?results[['area',?'bedrooms',?'bathrooms',?'A',?'B']]
for?i?in?test_data.columns:
????print(i,?'\t',?vif(df=test_data,?col_i=i))
發(fā)現(xiàn)bedrooms和bathrooms存在強(qiáng)相關(guān)性,可能這兩個(gè)變量是解釋同一個(gè)問題,方差膨脹因子較大的自變量通常是成對(duì)出現(xiàn)的。 果然,
果然,bedrooms和bathrooms這兩個(gè)變量的方差膨脹因子較高,這里刪除自變量bedrooms再次進(jìn)行建模
lm?=?ols(formula='price?~?area?+?bathrooms?+?A?+?B',?data=results).fit()
lm.summary()
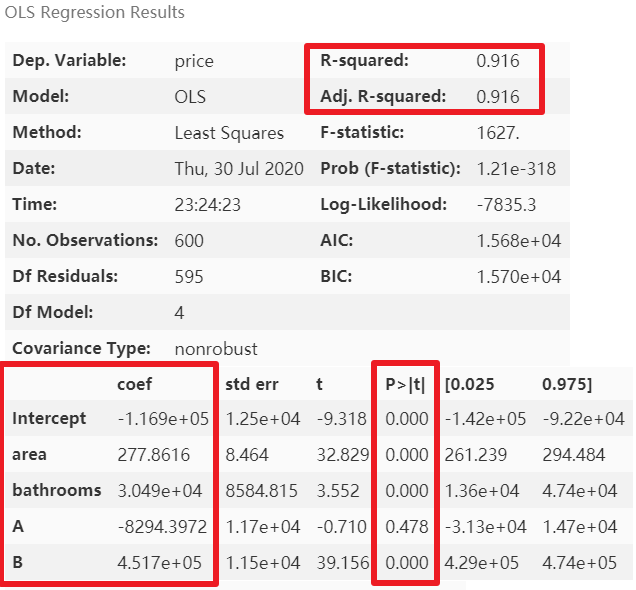 模型精度稍降,但消除了多元共線性后能夠使模型的泛化能力提升。再次進(jìn)行多元共線性檢測(cè)
模型精度稍降,但消除了多元共線性后能夠使模型的泛化能力提升。再次進(jìn)行多元共線性檢測(cè)
test_data?=?results[['area',?'bedrooms',?'A',?'B']]
for?i?in?test_data.columns:
????print(i,?'\t',?vif(df=test_data,?col_i=i))
 那么多元共線性就「只有通過方差膨脹因子才能看的出來嗎?」 其實(shí)并不一定,通過結(jié)合散點(diǎn)圖或相關(guān)稀疏矩陣和模型中自變量的系數(shù)也能看出端倪。下圖是未處理多元共線性時(shí)的自變量系數(shù)。
那么多元共線性就「只有通過方差膨脹因子才能看的出來嗎?」 其實(shí)并不一定,通過結(jié)合散點(diǎn)圖或相關(guān)稀疏矩陣和模型中自變量的系數(shù)也能看出端倪。下圖是未處理多元共線性時(shí)的自變量系數(shù)。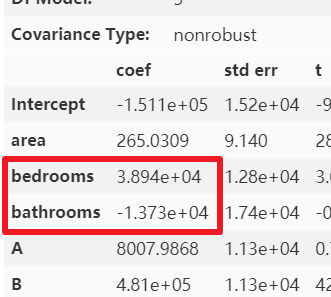 可以很明顯的看出,
可以很明顯的看出,bathrooms的參數(shù)很可能是有問題的,怎么可能bathrooms的數(shù)據(jù)量每增加一個(gè),房屋總價(jià)還減少 1.373*10 的四次方美元呢?簡(jiǎn)單的畫個(gè)散點(diǎn)圖和熱力圖也應(yīng)該知道房屋總價(jià)與bathrooms 個(gè)數(shù)應(yīng)該是成正比例關(guān)系的。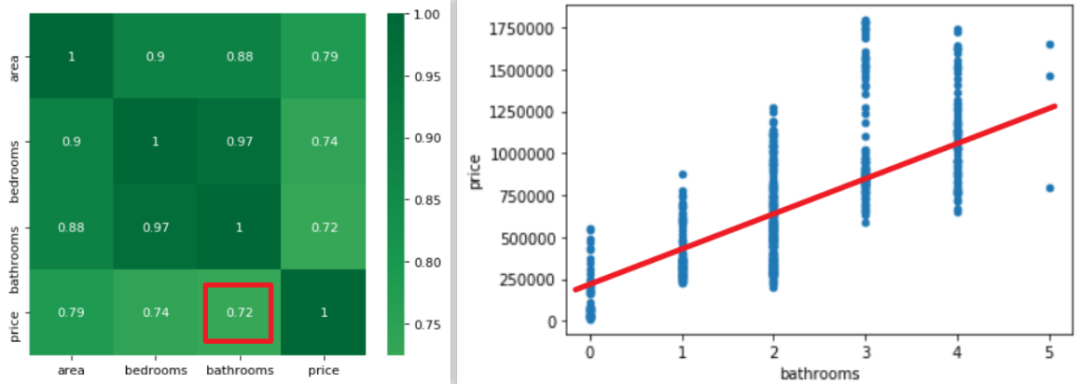
模型解釋
多元線性回歸模型的可解釋性比較強(qiáng),將模型參數(shù)打印出來即可求出因變量與自變量的關(guān)系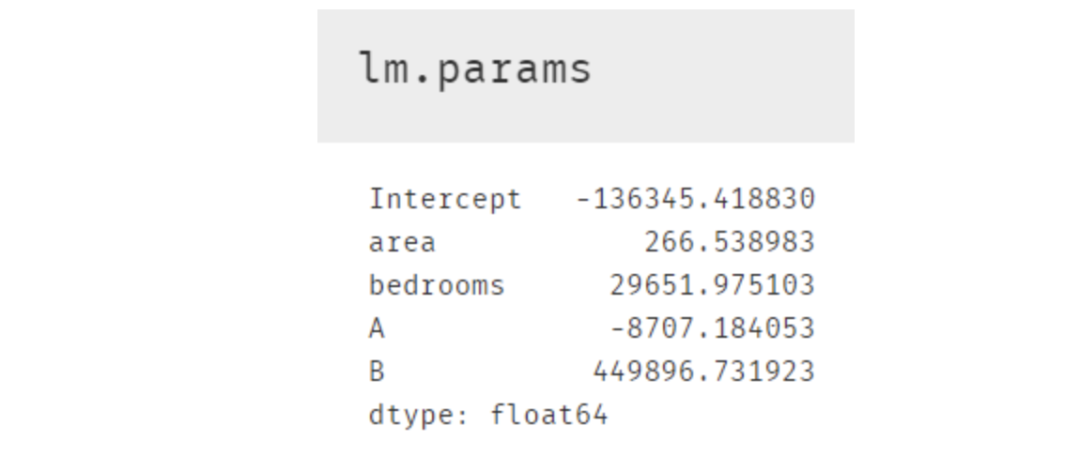 所以最終的建模結(jié)果如下,且該模型的精度為0.916
所以最終的建模結(jié)果如下,且該模型的精度為0.916
另外在等式結(jié)果中,截距項(xiàng)Intercept和area,bedrooms等變量的系數(shù)都還好理解;A,B 這兩個(gè)虛擬變量可能相對(duì)困難些。其實(shí)根據(jù)原理部分的表格來看,如果房屋在 C 區(qū),那等式中 A 和 B 這兩個(gè)字母的值便是 0,所以這便引出了非常重要的一點(diǎn):使用了虛擬變量的多元線性回歸模型結(jié)果中,存在于模型內(nèi)的虛擬變量都是跟被刪除掉的那個(gè)虛擬變量進(jìn)行比較。所以這個(gè)結(jié)果便表示在其他情況完全一樣時(shí)(即除虛擬變量外的項(xiàng))A 區(qū)的房屋比 C 區(qū)低 8707.18 美元,B 區(qū)則比 C 區(qū)貴 449896.73.7 美元。當(dāng)然我們也可以畫個(gè)箱線圖來查看與檢驗(yàn),發(fā)現(xiàn)結(jié)果正如模型中 A 與 B 的系數(shù)那般顯示。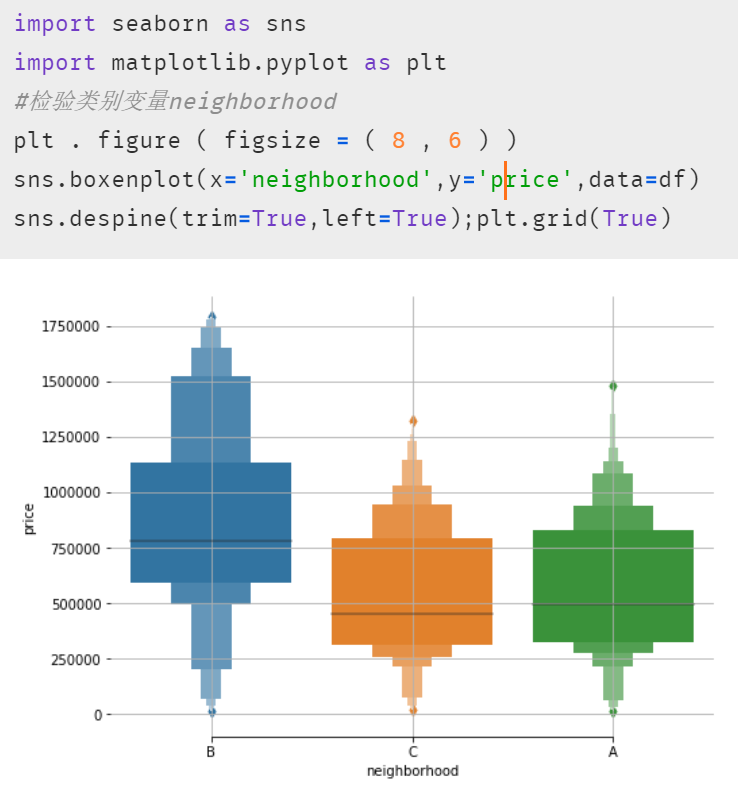
小結(jié)
本文以多元線性回歸為基礎(chǔ)和前提,在因變量房?jī)r(jià)與多個(gè)自變量的實(shí)際觀測(cè)值建立了多元線性回歸模型;分析并檢驗(yàn)各個(gè)預(yù)測(cè)變量對(duì)因變量的綜合線性影響的顯著性,并盡可能的消除多重共線性的影響,篩選出因變量有顯著線性影響的自變量,對(duì)基準(zhǔn)模型進(jìn)行優(yōu)化,并對(duì)各自變量相對(duì)重要性進(jìn)行評(píng)定,進(jìn)而提升了回歸模型的預(yù)測(cè)精度。如果對(duì)本文的源數(shù)據(jù)和代碼感興趣,可以在后臺(tái)回復(fù)數(shù)據(jù)挖掘進(jìn)行獲取,我們下個(gè)案例見。

