↑ 點(diǎn)擊 藍(lán)字? 關(guān)注極市平臺 來源丨h(huán)ttps://zhuanlan.zhihu.com/p/97449724 本文是一篇多目標(biāo)跟蹤方向的調(diào)研報告,從相關(guān)方向、核心步驟、評價指標(biāo)和最新進(jìn)展等維度出發(fā),對MOT進(jìn)行了全面的介紹,不僅適合作為入門科普,而且能夠幫助大家加深理解。>>>極市 七夕 粉絲福利活動:煉丹師們,七夕這道算法題,你會解嗎?
最近做了一些 多目標(biāo)跟蹤 方向的調(diào)研 ,因此把調(diào)研的結(jié)果以圖片加文字的形式展現(xiàn)出來,希望能幫助到入門這一領(lǐng)域的同學(xué)。也歡迎大家和我討論關(guān)于這一領(lǐng)域的任何問題。
相關(guān)方向
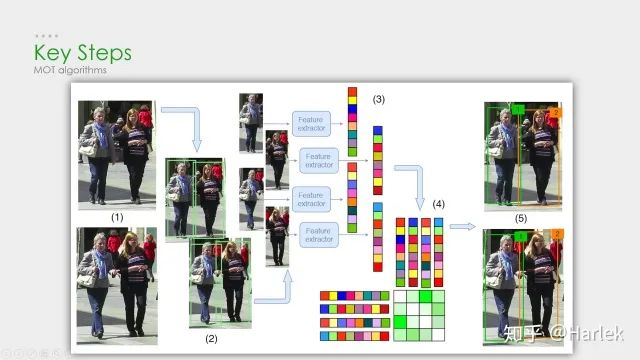
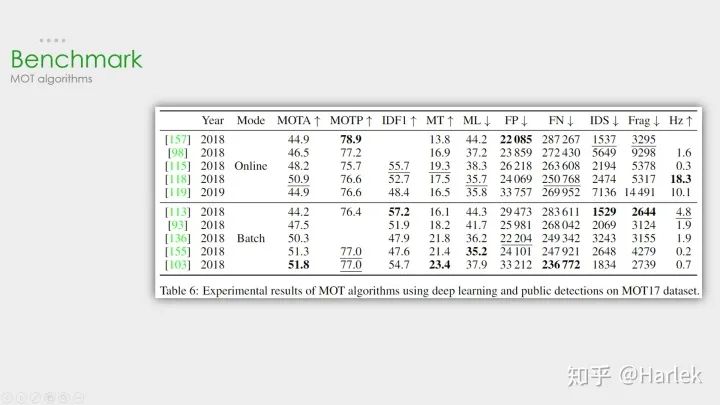
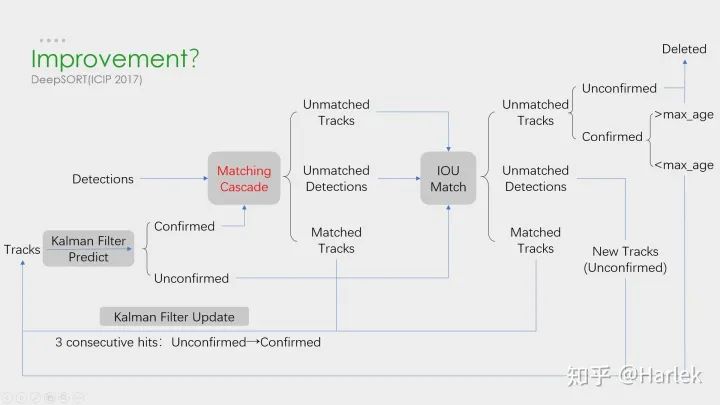
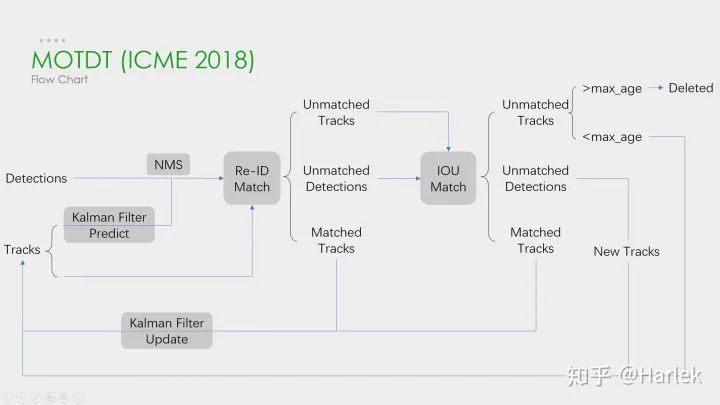
這些是我所了解的多目標(biāo)跟蹤 (MOT)的一些相關(guān)方向。其中單目標(biāo)跟蹤 (VOT/SOT)、目標(biāo)檢測 (detection)、行人重識別 (Re-ID)都是非常熱門的方向。而偏視頻的相關(guān)方向就比較冷門。而且今年五月DukeMTMC因?yàn)殡[私問題不再提供MTMCT的數(shù)據(jù)了,MTMCT的研究也是舉步維艱。 核心步驟 MOT算法的通常工作流程:(1)給定視頻的原始幀;(2)運(yùn)行對象檢測器 以獲得對象的邊界框;(3)對于每個檢測到的物體,計算出不同的特征 ,通常是視覺和運(yùn)動特征;(4)之后,相似度計算步驟 計算兩個對象屬于同一目標(biāo)的概率;(5)最后,關(guān)聯(lián)步驟 為每個對象分配數(shù)字ID。 因此絕大多數(shù)MOT算法無外乎就這四個步驟:①檢測 ②特征提取、運(yùn)動預(yù)測 ③相似度計算 ④數(shù)據(jù)關(guān)聯(lián) 。 其中影響最大的部分在于檢測,檢測結(jié)果的好壞對于最后指標(biāo)的影響是最大的。 但是,多目標(biāo)追蹤的研究重點(diǎn)又在相似度計算 和數(shù)據(jù)關(guān)聯(lián) 這一塊。所以就有一個很大的問題:你設(shè)計出更好的關(guān)聯(lián)算法可能就提升了0.1個點(diǎn),但別人用一些針對數(shù)據(jù)集的trick消除了一些漏檢可能就能漲好幾個點(diǎn)。所以研究更好的數(shù)據(jù)關(guān)聯(lián)的回報收益很低。因此多目標(biāo)追蹤這一領(lǐng)域雖然工業(yè)界很有用,但學(xué)術(shù)界里因?yàn)橹笜?biāo)數(shù)據(jù)集的一些原因,入坑前一定要三思 。 評價指標(biāo) 第一個是傳統(tǒng)的標(biāo)準(zhǔn),現(xiàn)在已經(jīng)沒人用了,就不介紹了。 第二個是06年提出的CLEAR MOT。現(xiàn)在用的最多 的就是MOTA 。但是這個指標(biāo)FN、FP的權(quán)重占比很大,更多衡量的是檢測的質(zhì)量 ,而不是跟蹤的效果 。 第三個是16年提出的ID scores。因?yàn)槎际腔谄ヅ涞闹笜?biāo),所以能更好的衡量數(shù)據(jù)關(guān)聯(lián) 的好壞。 數(shù)據(jù)集 數(shù)據(jù)集用的最多的是MOTChallenge ,專注于行人追蹤的。 第二個KITTI的是針對自動駕駛的數(shù)據(jù)集,有汽車也有行人,在MOT的論文里用的很少。 還有一些其他比較老的數(shù)據(jù)集現(xiàn)在都不用了。 15年的都是采集的老的數(shù)據(jù)集的視頻做的修正。 16年的是全新的數(shù)據(jù)集,相比于15年的行人密度更高、難度更大。特別注意這個DPM檢測器 ,效果非常的差,全是漏檢和誤檢。 17年的視頻和16年一模一樣,只是提供了三個檢測器 ,相對來說更公平。也是現(xiàn)在論文的主流數(shù)據(jù)集 。 19年的是針對特別擁擠情形的數(shù)據(jù)集,只有CVPR19比賽時才能提交。 這個是MOT16公開檢測器 上的結(jié)果。可以看到從17年開始,MOTA就漲的很慢了。關(guān)注一下這個幀率有20Hz的算法MOTDT也是我后面要講的一個。 這個是MOT16私有檢測器 上的結(jié)果。可以看到檢測器性能的好壞 對于結(jié)果的影響非常重要。SOTA算法換了私有檢測器后性能直接漲了快20個點(diǎn)。 這個是MOT17公開檢測器 上這幾年比較突出的算法。注意因?yàn)檫@個數(shù)據(jù)集用了三個檢測器,所以FP、FN這些指標(biāo)也都幾乎是16數(shù)據(jù)集的三倍。 SORT和DeepSORT 關(guān)鍵算法 從這兩個工業(yè)界關(guān)注度最高 的算法說起。 SORT作為一個粗略的框架,核心就是兩個算法:卡爾曼濾波 和匈牙利匹配 。 卡爾曼濾波 分為兩個過程:預(yù)測 和更新 。預(yù)測過程:當(dāng)一個小車經(jīng)過移動后,且其初始定位和移動過程都是高斯分布時,則最終估計位置分布會更分散,即更不準(zhǔn)確;更新過程:當(dāng)一個小車經(jīng)過傳感器觀測定位,且其初始定位和觀測都是高斯分布時,則觀測后的位置分布會更集中,即更準(zhǔn)確。匈牙利算法 解決的是一個分配問題 。SK-learn庫的linear_assignment___和scipy庫的linear_sum_assignment都實(shí)現(xiàn)了這一算法,只需要輸入cost_matrix即代價矩陣 就能得到最優(yōu)匹配。不過要注意的是這兩個庫函數(shù)雖然算法一樣,但給的輸出格式不同。具體算法步驟也很簡單,是一個復(fù)雜度 DeepSORT的優(yōu)化主要就是基于匈牙利算法里的這個代價矩陣 。它在IOU Match之前做了一次額外的級聯(lián)匹配 ,利用了外觀特征 和馬氏距離 。 外觀特征 就是通過一個Re-ID的網(wǎng)絡(luò)提取的,而提取這個特征的過程和NLP里詞向量的嵌入 過程(embedding)很像,所以后面有的論文也把這個步驟叫做嵌入(起源應(yīng)該不是NLP,但我第一次接觸embedding是從NLP里)。然后是因?yàn)闅W氏距離忽略空間域分布的計算結(jié)果,所以增加里馬氏距離 作為運(yùn)動信息的約束。SORT 這個SORT的流程圖非常重要,可以看到整體可以拆分為兩個部分,分別是匹配過程 和卡爾曼預(yù)測加更新過程 ,都用灰色框標(biāo)出來了。一定要把整個流程弄明白。后面的多目標(biāo)追蹤的大框架基本都由此而來。 關(guān)鍵步驟:軌跡卡爾曼濾波預(yù)測 → 使用匈牙利算法 將預(yù)測后的tracks和當(dāng)前幀中的detecions進(jìn)行匹配(IOU匹配 ) → 卡爾曼濾波更新 對于沒有匹配上的軌跡,也不是馬上就刪掉了,有個T_lost的保存時間,但SORT里把這個時間閾值設(shè)置的是1,也就是說對于沒匹配上的軌跡相當(dāng)于直接刪了。 首先,恒定速度模型不能很好地預(yù)測真實(shí)的動力學(xué),其次,我們主要關(guān)注的是幀到幀的跟蹤,其中對象的重新識別超出了本文的范圍。 DeepSORT 這是DeepSORT算法的流程圖,和SORT基本一樣,就多了級聯(lián)匹配 (Matching Cascade)和新軌跡的確認(rèn) (confirmed)。 這篇文章的機(jī)翻在《DeepSORT》論文翻譯 關(guān)鍵步驟:軌跡卡爾曼濾波預(yù)測 → 使用匈牙利算法 將預(yù)測后的tracks和當(dāng)前幀中的detecions進(jìn)行匹配(級聯(lián)匹配 和IOU匹配 ) → 卡爾曼濾波更新 級聯(lián)匹配 是核心,就是紅色部分,DeepSORT的絕大多數(shù)創(chuàng)新點(diǎn)都在這里面,具體過程看下一張圖。關(guān)于為什么新軌跡要連續(xù)三幀命中才確認(rèn)?個人認(rèn)為有這樣嚴(yán)格的條件和測試集有關(guān)系。因?yàn)闇y試集給的檢測輸入非常的差,誤檢有很多,因此軌跡的產(chǎn)生必須要更嚴(yán)格的條件。 級聯(lián)匹配流程圖里上半部分就是特征提取 和相似度估計 ,也就是算這個分配問題的代價函數(shù)。主要由兩部分組成:代表運(yùn)動模型的馬氏距離 和代表外觀模型的Re-ID特征 。 級聯(lián)匹配流程圖里下半部分數(shù)據(jù)關(guān)聯(lián) 作為流程的主體。為什么叫級聯(lián)匹配,主要是它的匹配過程是一個循環(huán) 。從missing age=0的軌跡(即每一幀都匹配上,沒有丟失過的)到missing age=30的軌跡(即丟失軌跡的最大時間30幀)挨個的和檢測結(jié)果進(jìn)行匹配 。也就是說,對于沒有丟失過的軌跡賦予優(yōu)先匹配 的權(quán)利,而丟失的最久的軌跡最后匹配。 論文關(guān)于參數(shù)λ(運(yùn)動模型的代價占比)的取值是這么說的: 在我們的實(shí)驗(yàn)中,我們發(fā)現(xiàn)當(dāng)相機(jī)運(yùn)動明顯時,將λ= 0設(shè)置是一個合理的選擇。 因?yàn)橄鄼C(jī)抖動明顯,卡爾曼預(yù)測所基于的勻速運(yùn)動模型并不work,所以馬氏距離其實(shí)并沒有什么作用。但注意也不是完全沒用了,主要是通過閾值矩陣(Gate Matrix)對代價矩陣(Cost Matrix)做了一次閾值限制 。 關(guān)于DeepSORT算法的詳細(xì)代碼解讀我比較推薦:目標(biāo)跟蹤初探(DeepSORT) 但關(guān)于卡爾曼濾波的公式講的不是很詳細(xì),具體推導(dǎo)可以看看 Kalman Filter 卡爾曼濾波 改進(jìn)策略 看到這個DeepSORT的流程圖不知道大家可以想到什么優(yōu)化 的地方?其實(shí)有幾個點(diǎn)是很容易想到的。 第一點(diǎn),把Re-ID網(wǎng)絡(luò)和檢測網(wǎng)絡(luò)融合 ,做一個精度和速度的trade off; 第二點(diǎn),對于軌跡段來說,時間越長的軌跡是不是更應(yīng)該得到更多的信任,不僅僅只是級聯(lián)匹配的優(yōu)先級,由此可以引入軌跡評分的機(jī)制 ; 第三點(diǎn),從直覺上來說,檢測和追蹤是兩個相輔相成的問題,良好的追蹤可以彌補(bǔ)檢測的漏檢,良好的檢測可以防止追蹤的軌道飄逸,用預(yù)測來彌補(bǔ)漏檢 這個問題在DeepSORT里也并沒有考慮; 第四點(diǎn),DeepSORT里給馬氏距離也就是運(yùn)動模型設(shè)置的系數(shù)為0,也就是說在相機(jī)運(yùn)動的情況下線性速度模型并不work,所以是不是可以找到更好的運(yùn)動模型 。 最新進(jìn)展 工業(yè)界青睞的算法在學(xué)術(shù)界其實(shí)并不重視,一方面是因?yàn)?strong style="font-weight: bold;color: black;">開源的原因,另一方面可以看到頂會的算法都不是注重速度 的,通常用了很復(fù)雜的模塊和trick 來提升精度。 而且這些trick不是一般意義的trick了,是針對這個數(shù)據(jù)集的或者說針對糟糕檢測器的一些trick, 對于實(shí)際應(yīng)用幾乎沒有幫助。 第一篇論文是基于DeepSORT改進(jìn)的,它的創(chuàng)新點(diǎn)在于引入了軌跡評分機(jī)制 ,時間越久的軌跡可信度就越高,基于這個評分就可以把軌跡產(chǎn)生的預(yù)測框和檢測框放一起做一個NMS,相當(dāng)于是用預(yù)測彌補(bǔ)了漏檢 。 第二篇論文是今年9月份發(fā)在arxiv上的一篇論文,它的工作是把檢測網(wǎng)絡(luò)和嵌入網(wǎng)絡(luò)結(jié)合起來 ,追求的是速度和精度的trade off。 MOTDT 這是剛才列舉的第一篇論文(MOTDT)的流程圖,大概和DeepSORT差不多。這個圖畫的比較簡單,其實(shí)在NMS之前有個基于SqueezeNet的區(qū)域選擇網(wǎng)絡(luò)R-FCN 和軌跡評分的機(jī)制 。這兩個東西的目的就是為了產(chǎn)生一個統(tǒng)一檢測框和預(yù)測框的標(biāo)準(zhǔn)置信度,作為NMS的輸入。 這篇文章的翻譯在《Real-Time Multiple People Tracking With Deeply Learned Candidate Selection And Person Re-ID》論文翻譯 JDE 這是剛才第二篇論文(JDE)里的結(jié)構(gòu)圖。這個方法是基于YOLOv3和MOTDT做的。它網(wǎng)絡(luò)前面都和YOLOv3一樣的,主要就是在特征圖里多提取了一個嵌入(embedding)向量,采取的是類似于交叉熵的triplet loss 。因?yàn)槭嵌嗳蝿?wù)學(xué)習(xí),這篇論文還用了一篇18年的論文提出來的自動學(xué)習(xí)損失權(quán)重方案 :通過學(xué)習(xí)一組輔助參數(shù)自動地對非均勻損失進(jìn)行加權(quán)。最后的結(jié)果是精度上差不太多,F(xiàn)PS高了很多。 這篇文章的翻譯在 《Towards Real-Time Multi-Object Tracking》論文翻譯 未來展望 最后用多目標(biāo)追蹤未來的一些思考作為結(jié)尾,這句話是最近的一篇關(guān)于多目標(biāo)追蹤的綜述里的。 它在最后提出對未來的方向里有這樣一句話,用深度學(xué)習(xí)來指導(dǎo)關(guān)聯(lián)問題 。其實(shí)現(xiàn)在基于檢測的多目標(biāo)追蹤都是檢測模塊用深度學(xué)習(xí),Re-ID模塊用深度學(xué)習(xí),而最核心的數(shù)據(jù)關(guān)聯(lián)模塊要用深度學(xué)習(xí)來解決是很困難的 。現(xiàn)在有一些嘗試是用RNN,但速度慢、效果不好,需要走的路都還很長。 我個人覺得短期內(nèi)要解決實(shí)際問題 ,還是從Re-ID的方面下手思考怎樣提取更有效的特征 會更靠譜,用深度學(xué)習(xí)的方法來處理數(shù)據(jù)關(guān)聯(lián)不是短時間能解決的。 [1] Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In2016 IEEE International Conference on Image Processing (ICIP), pages 3464–3468. IEEE, 2016. [2] Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep associationmetric. In2017 IEEE International Conference on Image Processing (ICIP), pages 3645–3649. IEEE, 2017. [3] Chen Long, Ai Haizhou, Zhuang Zijie, and Shang Chong. Real-time multiple people tracking with deeplylearned candidate selection and person re-identification. InICME, 2018. [4] Zhongdao Wang, Liang Zheng, Yixuan Liu, Shengjin Wang. Towards Real-Time Multi-Object Tracking. arXiv preprint arXiv:1909.12605 [5] Gioele Ciaparrone, Francisco Luque Sánchez, Siham Tabik, Luigi Troiano, Roberto Tagliaferri, Francisco Herrera. Deep Learning in Video Multi-Object Tracking: A Survey. arXiv preprint arXiv:1907.12740
推薦閱讀
添加極市小助手微信 (ID : cvmart2) ,備注: 姓名-學(xué)校/公司-目標(biāo)跟蹤-城市 (如:小極-北大-目標(biāo)跟蹤- 深圳),即可申請加入 極市目標(biāo)跟蹤/目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解 等技術(shù)交流群: 每 月大咖直播分享、真實(shí)項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、 與? 10000+ 來自 港科大、北大、清華、中科院、CMU、騰訊、百度 等名校名企視覺開發(fā)者互動交流 ~ 覺得有用麻煩給個在看啦~ ??