
基于深度學習的多目標跟蹤(MOT)技術(shù)一覽
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
導讀
?本文是一篇多目標跟蹤方向的調(diào)研報告,從相關(guān)方向、核心步驟、評價指標和最新進展等維度出發(fā),對MOT進行了全面的介紹,不僅適合作為入門科普,而且能夠幫助大家加深理解。
最近做了一些多目標跟蹤方向的調(diào)研,因此把調(diào)研的結(jié)果以圖片加文字的形式展現(xiàn)出來,希望能幫助到入門這一領(lǐng)域的同學。也歡迎大家和我討論關(guān)于這一領(lǐng)域的任何問題。
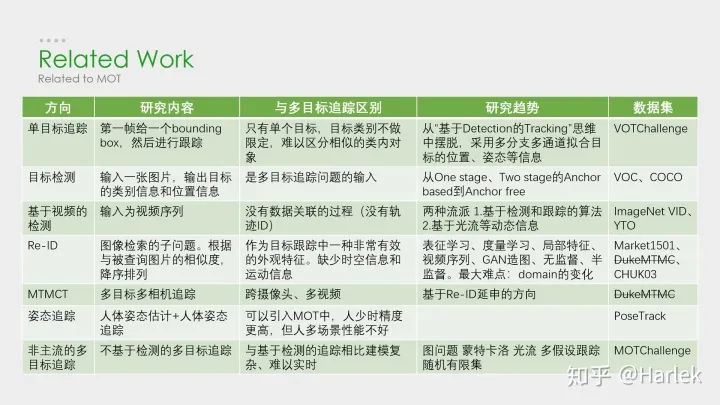
相關(guān)方向
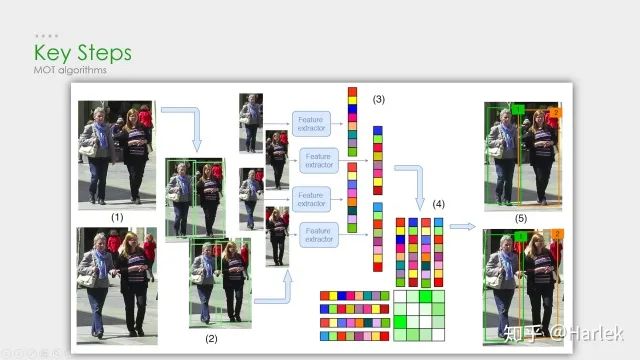
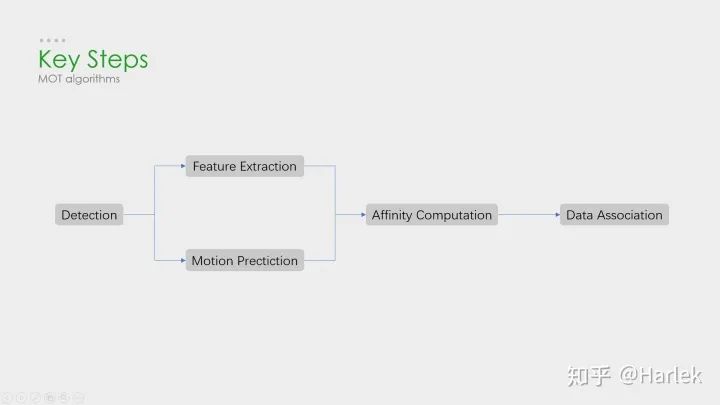
核心步驟
評價指標

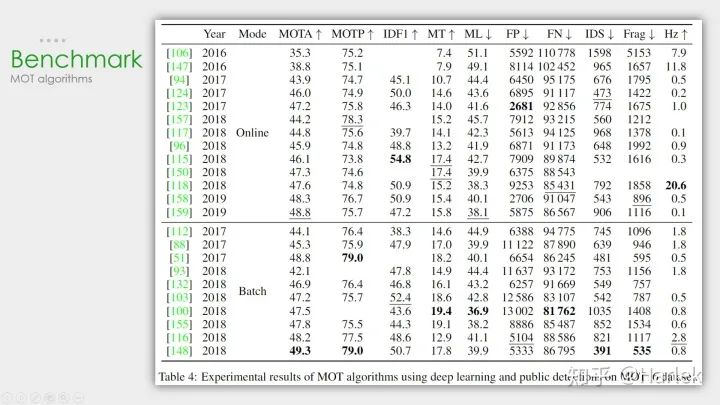
數(shù)據(jù)集


SORT和DeepSORT
關(guān)鍵算法
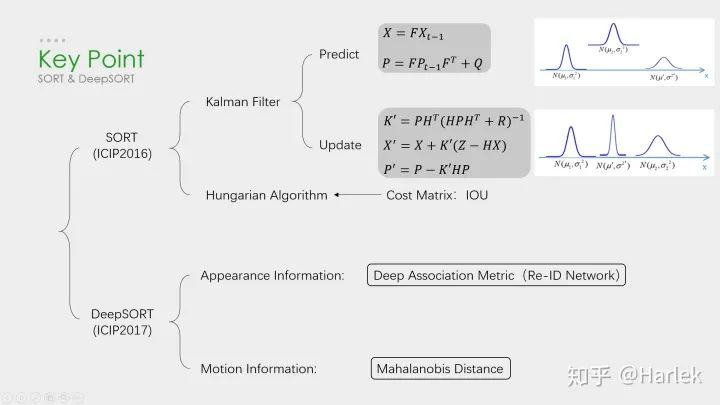
SORT
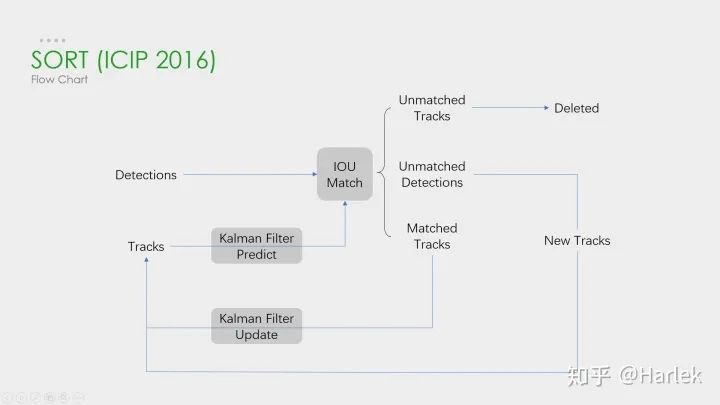
首先,恒定速度模型不能很好地預測真實的動力學,其次,我們主要關(guān)注的是幀到幀的跟蹤,其中對象的重新識別超出了本文的范圍。
DeepSORT
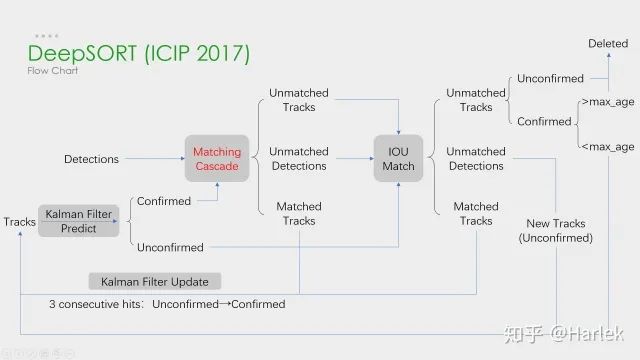
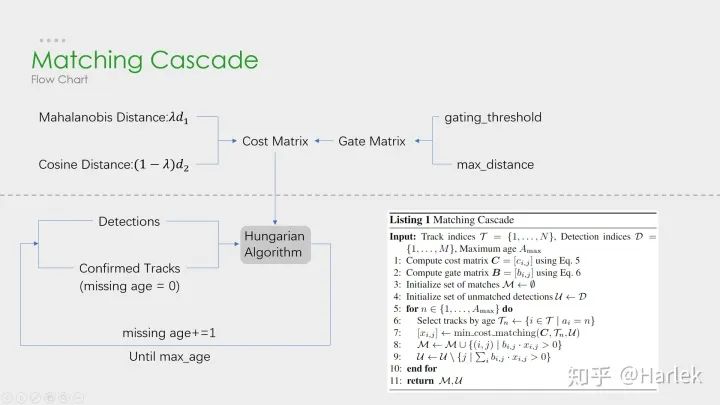
在我們的實驗中,我們發(fā)現(xiàn)當相機運動明顯時,將λ= 0設(shè)置是一個合理的選擇。
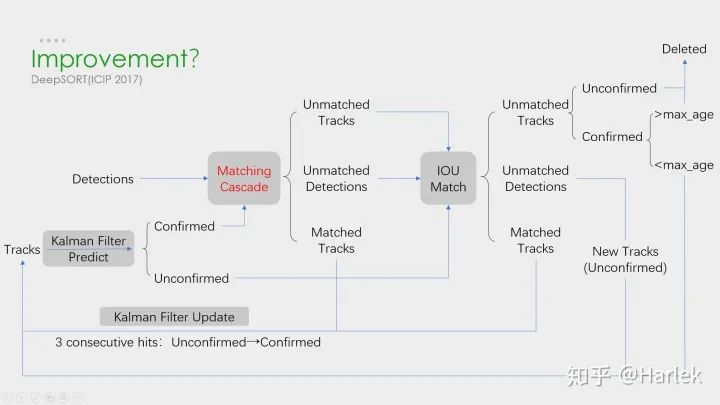
改進策略

最新進展

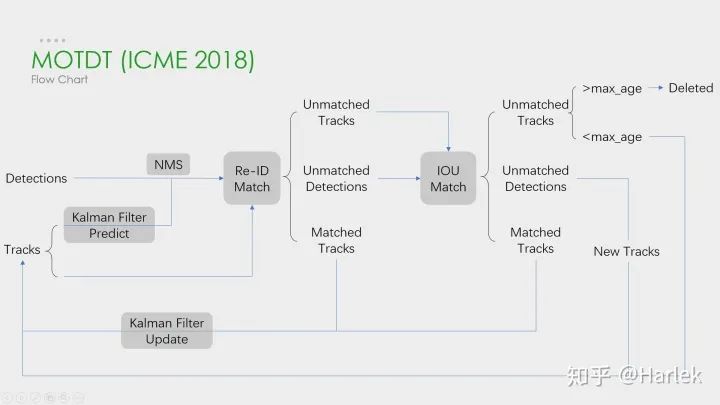
MOTDT
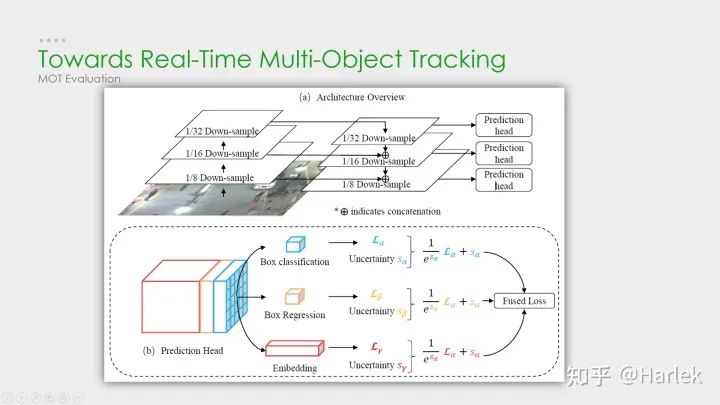
JDE
未來展望

評論
圖片
表情