
python爬蟲反反爬:搞定CSS反爬加密
0 慣性嘚瑟
剛開始搞爬蟲的時(shí)候聽到有人說爬蟲是一場(chǎng)攻堅(jiān)戰(zhàn),聽的時(shí)候也沒感覺到特別,但是經(jīng)過了一段時(shí)間的練習(xí)之后,深以為然,每個(gè)網(wǎng)站不一樣,每次爬取都是重新開始,所以,爬之前誰都不敢說會(huì)有什么結(jié)果。

??????前兩天,應(yīng)幾個(gè)小朋友的邀請(qǐng),動(dòng)心思玩了一下大眾點(diǎn)評(píng)的數(shù)據(jù)爬蟲,早就聽說大眾點(diǎn)評(píng)的反爬方式不一般,貌似是難倒了一片英雄好漢,當(dāng)然也成就了網(wǎng)上的一眾文章,專門講解如何爬取大眾點(diǎn)評(píng)的數(shù)據(jù),筆者一邊閱讀這些文章尋找大眾點(diǎn)評(píng)的破解思路,一邊為大眾點(diǎn)評(píng)的程序員小哥哥們鳴不平,辛辛苦苦寫好的加密方式,你們這些爬蟲寫手們這是鬧哪樣?破解也就算了,還發(fā)到網(wǎng)上去,還發(fā)這么多~????

? ? ? ?筆者在閱讀完這些文章之后,自信心瞬間爆棚,有如此多的老師,還有爬不了的網(wǎng)站,于是,筆者信誓旦旦的開始了爬大眾點(diǎn)評(píng)之旅,結(jié)果,一上手就被收拾了,各個(gè)大佬們給出的爬蟲方案中竟然有手動(dòng)構(gòu)建對(duì)照表的過程,拜托,如果我想手動(dòng),還要爬蟲做什么?別說手動(dòng),半自動(dòng)都不行。
?????? 大家看到這里或許頭上有些霧水了,什么手動(dòng)?什么半自動(dòng)?還對(duì)照表?大佬,你這是什么梗?再不解釋一些我就要棄劇了,葛優(yōu)都拉不回來~

????????
? ? ? 大家先不要著急,靜一靜~,對(duì)照表后面會(huì)講,這里只需要知道我遇到困難了,就可以了,不過咨詢了幾個(gè)大佬之后,好在解決了,革命的路上雖有羈絆,終歸還是有同志的~
?????? 好,現(xiàn)在開始入正題,點(diǎn)評(píng)的程序員哥哥請(qǐng)不要寄刀片:
1 基礎(chǔ)環(huán)節(jié)
?大眾點(diǎn)評(píng)的數(shù)據(jù)爬蟲開始還是很正常的,各個(gè)題目、菜單基本上都可以搞下來:
?????? 代碼如下:
#!/usr/bin/env python
?import?requests
?from?lxml import?etree
?
?header = {"Accept":"application/json, text/javascript",
???????????"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
???????????"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
???????????"Cookie":"cy=1; cye=shanghai; _lxsdk_cuid=16ca41d3344c8-050eb4ac8f1741-4d045769-1fa400-16ca41d3345c8; _lxsdk=16ca41d3344c8-050eb4ac8f1741-4d045769-1fa400-16ca41d3345c8; _hc.v=38ae2e43-608f-1198-11ff-38a36dc160a4.1566121473; _lxsdk_s=16ce7f63e0d-91a-867-5a%7C%7C20; s_ViewType=10"
???????????}
?url = 'http://www.dianping.com/beijing/ch10/g34060o2'
?response = requests.get(url, headers=header)
?data = etree.HTML(response.text)
?title = data.xpath('//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[1]/a/@title')
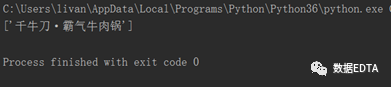
?print(title)
????????爬取的結(jié)果為:
??????? ?????
?????
???????按照常規(guī)的套路,爬蟲可以說是寫成了。但是,現(xiàn)在的網(wǎng)站大多使用了反爬,一方面擔(dān)心自己的服務(wù)器會(huì)被爬蟲搞的超負(fù)荷,另一方面也為了保護(hù)自己的數(shù)據(jù)不被其他人獲取。?
????? ??
????????大眾點(diǎn)評(píng)就是眾多帶反爬的網(wǎng)站中的佼佼者,使用了比較高級(jí)的反爬手法,他們把頁面上的關(guān)鍵數(shù)字隱藏了起來,增加了爬蟲難度,不信~你看:
2 CSS加密
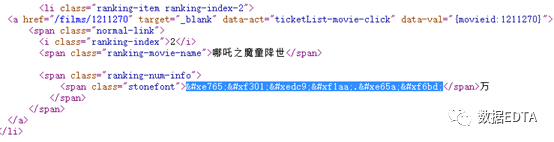
???????我們用如下字段爬取商店的評(píng)論數(shù):
data?= etree.HTML(response.text)
?title = data.xpath('//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[2]/a[1]/b/svgmtsi[1]/text()')
?print(title)
?????? 結(jié)果得到的卻是如下字段:
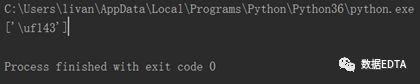
?????? 一看傻了,這是什么鬼?
?????? 我們緊接著審查了網(wǎng)站數(shù)據(jù),看到的內(nèi)容卻是:
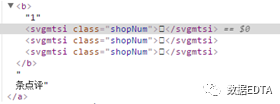
?????? 這是什么鬼?評(píng)論數(shù)呢?
 ?
?
????????查看了網(wǎng)站的源代碼:

? ? ? ?發(fā)現(xiàn)原來顯示點(diǎn)評(píng)數(shù)的字段顯示成了:
?????? 這是為什么呢?
?????? 好在網(wǎng)上的大神們給出了解答,這就是CSS加密。
?????? 接下來我們就介紹如何破解CSS加密:
?????? 我們把源代碼上加密的部分取下來觀察一下:
?????
?????? 我們發(fā)現(xiàn)了網(wǎng)上一直在討論的svgmtsi標(biāo)簽,這個(gè)標(biāo)簽是矢量圖的標(biāo)簽,基本上意思就是顯示在這里的文字是一個(gè)矢量圖,解析這個(gè)矢量圖需要到另外一個(gè)地方找一個(gè)對(duì)照表,通過對(duì)照表將編碼內(nèi)容翻譯成人類可以識(shí)別的數(shù)字。
![]()
? ? ? ?那么,對(duì)照表在哪里呢?
?????? 我們先記錄下標(biāo)簽中的class值:shopNum(為什么記錄,先不要著急,后面會(huì)講到),然后在源代碼中查找svg,我們發(fā)現(xiàn)了如下內(nèi)容:?
? ? ? ?大寶藏被挖掘了。
?????? 這好像是個(gè)鏈接,我們點(diǎn)擊一下,發(fā)現(xiàn)頁面跳轉(zhuǎn)到了一個(gè)全新的水月洞天:

????????這真是個(gè)偉大的發(fā)現(xiàn),他預(yù)示著我們的爬蟲找到了門路,我們?cè)谶@個(gè)頁面上查找剛才class中的值shopNum,然后,我們看到了如下內(nèi)容:???
url("http://s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/bc2c52b3.woff");}
.shopNum{font-family: 'PingFangSC-Regular-shopNum';}@font-face{font-family:
"PingFangSC-Regular-reviewTag";
src:url("http://s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/07758223.eot");
? ? ? 在這段代碼中距離shopNum最近的地方,我們找到一個(gè)woff文件。
? ? ? 你沒有猜錯(cuò),這個(gè)woff文件就是我們的對(duì)照表。
? ? ? 同樣的思路,這是一個(gè)網(wǎng)址,我們可以把他下載下來,把這個(gè)網(wǎng)址復(fù)制到瀏覽器的地址欄中,點(diǎn)回車,會(huì)跳出如下快樂的界面。
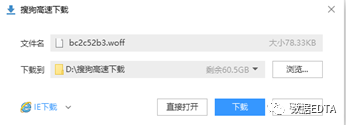
? ? ? ?下載完成后,我們?cè)跒g覽器中打開woff的翻譯工具:
????????http://fontstore.baidu.com/static/editor/index.html
? ? ? ?我們把前面的&#x去掉并替換成uni,后面的;去掉,得到字段為:unif784。
????????秘密揭曉了:

?????? 是不是很眼熟?
?????? 是不是很驚喜?
?????? 是不是很意外?
?????? 恭喜你,第一步成功了~
?????? 這個(gè)編碼在woff文件中對(duì)應(yīng)的值為7。
? ? ? ?就是我們要找的親人~

3 woff文件處理
????? ?事情到這里其實(shí)就可以畫個(gè)句號(hào)了,因?yàn)榻酉聛淼乃悸肪妥兊姆浅:?jiǎn)單了,我們用上面的通用爬蟲下載下網(wǎng)站上所有編碼和對(duì)應(yīng)的class值,然后根據(jù)class值找到對(duì)應(yīng)的woff文件,再在woff文件中確定編碼對(duì)應(yīng)的數(shù)字或漢字就可以。
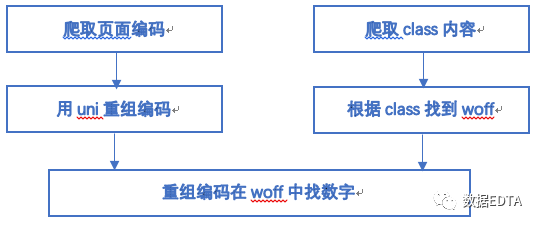
? ? ??但是,當(dāng)我們擴(kuò)充這一思路的時(shí)候卻遇到了兩個(gè)問題:
1)如何讀取出woff文件中的數(shù)字,大眾點(diǎn)評(píng)有多個(gè)woff文件,怎么對(duì)照讀取呢?難不成要一個(gè)個(gè)寫出來?根據(jù)前面網(wǎng)站里的文章來講,對(duì)的,你猜的很準(zhǔn),這就是我文章一開始寫的半自動(dòng),崩潰了吧,好在筆者找到了新的方法,取代了半自動(dòng)的問題,這個(gè)新的方法就是OCR識(shí)別,后面我會(huì)仔細(xì)講解。
2)頁面的編碼是變動(dòng)的,你沒有看錯(cuò),這個(gè)值是會(huì)變的,好在這個(gè)事件沒有發(fā)生在大眾點(diǎn)評(píng)中,但是汽車之家、貓眼等網(wǎng)站使用的CSS加密會(huì)隨頁面的刷新發(fā)生變動(dòng),有沒有驚到你?
如果你只需要大眾點(diǎn)評(píng),第二個(gè)問題幾乎可以不用考慮了,但是筆者認(rèn)為要做一個(gè)有理想的爬蟲,盡量多的獲取知識(shí)點(diǎn)才是正確的,所以,筆者研究了汽車之家、貓眼、天眼等幾個(gè)用CSS加密的網(wǎng)站,找到了一個(gè)通用的方法,下面我們來介紹一下這個(gè)通用方法。
先看一下貓眼網(wǎng)站上編碼的動(dòng)態(tài)效果:
如圖:
? ? ? 我們先找到一個(gè)加密編碼,把他復(fù)制出來,看到的編碼如下:

????? 然后我們刷新一下頁面,再看源碼:
???????不管你驚不驚,反正我是驚到了~
?????? 針對(duì)這一變化,筆者心中產(chǎn)生了一個(gè)疑惑,如果說編碼會(huì)變,那瀏覽器是怎么獲取到準(zhǔn)確的值的呢?說明一定存在一個(gè)統(tǒng)一的方法供瀏覽器調(diào)用,于是,筆者重新研究了編碼的調(diào)用方式,驚奇的發(fā)現(xiàn)了其中的秘密:
?????? 我們以如下兩個(gè)編碼來揭露這個(gè)今天大冪冪:
?????? -->unif0d5
?????? -->unie765
?????? 這兩個(gè)字段都是表示數(shù)字中的1,那他們有什么規(guī)律呢?
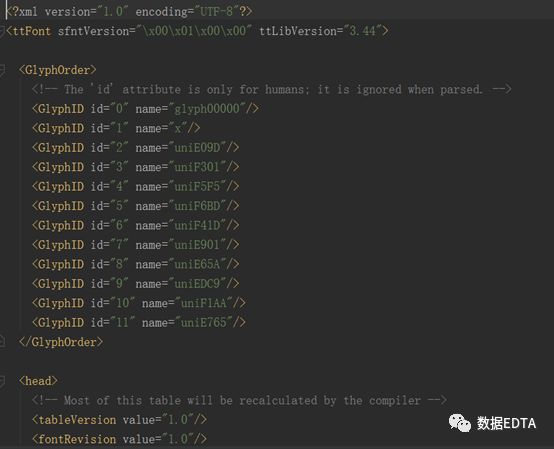
?????? 我們首先解碼woff文件成xml格式:
from?fontTools.ttLib import?TTFont
?font = TTFont('e765.woff')
?font.saveXML('e765.xml')
? ? ??在pycharm中我們打開xml文件:
 ?
?
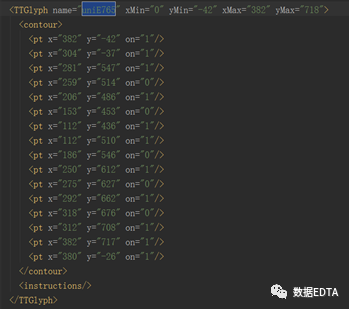
? ? ? 找到unie765所在的位置:
 ?
?
? ? ? ?這一串代碼是字形坐標(biāo),瀏覽器就是根據(jù)這個(gè)字形坐標(biāo)翻譯出我們能夠識(shí)別的漢字:1。
? ? ? ?同樣的思路,我們?cè)偃ソ馕鰑nif0d5的值,得到如下圖:
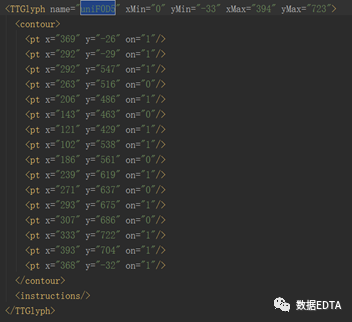
我們驚奇的發(fā)現(xiàn),這兩個(gè)竟然一樣,是不是所有的值對(duì)應(yīng)的字形坐標(biāo)都是唯一的呢,答案是肯定的,變化的只是上圖name中的編碼,坐標(biāo)與數(shù)字之間是一對(duì)一的,所以,我們的思路來了,我們只需要找到編碼所對(duì)應(yīng)的字形坐標(biāo),然后想辦法解析出這個(gè)字形坐標(biāo)所對(duì)應(yīng)的數(shù)字就可以了。
4 完整思路
???????問題展示基本上清楚了,我們接下來看一下怎么自動(dòng)化解決上面兩個(gè)問題:
?????? 首先展示一下思路:
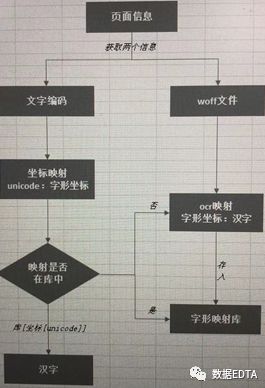
???????這是在excel里面畫的,大家可以只關(guān)注內(nèi)容,忽略掉背景線。
?????? 解釋一下上面的思路:
?????? 首先:我們從頁面上獲取到文字編碼和woff文件,注意,這里的字形編碼和woff文件一定要一起獲取,因?yàn)槊總€(gè)編碼對(duì)應(yīng)一個(gè)woff文件,一旦刷新頁面,編碼在woff文件中的對(duì)應(yīng)關(guān)系就會(huì)變化,找不到對(duì)應(yīng)的字形坐標(biāo)。
data?= etree.HTML(response.text)
title = data.xpath('//*[@id="shop-all-list"]/ul/li[1]/div[2]/div[2]/a[1]/b/svgmtsi[1]/text()')
print(title)
?????? 其次:我們把字形編碼轉(zhuǎn)化成uni開頭的編碼,并獲取到woff文件中的字形坐標(biāo)。
from fontTools.ttLib import TTFont
font = TTFont('f0d5.woff')
coordinate = font['glyf']['uniF0D5'].coordinates
print(coordinate)?????? 第三:用matplotlib解析這一坐標(biāo),并保存成圖片。
#!/usr/bin/env python
?# _*_ UTF-8 _*_
from?fontTools.ttLib import?TTFont
import?matplotlib.pyplot as?plt
font = TTFont('f0d5.woff')
coordinate = font['glyf']['uniF0D5'].coordinates
coordinate = list(coordinate)
fig, ax = plt.subplots()
x = [i[0] for?i in?coordinate]
y = [i[1] for?i in?coordinate]
plt.fill(x, y, color="k", alpha=1)
# 取消邊框
for?key, spine in?ax.spines.items():
?????if?key == 'right'?or?key == 'top'?or?key == 'bottom'?or?key == 'left':
?????????spine.set_visible(False)
plt.plot(x, y)
# 取消坐標(biāo):
plt.axis('off')
plt.savefig('uniF0D5.png')
plt.show()
?????? 通過上面的解析,我們可以得到1的圖片:
??????
? ? ? ?這個(gè)1好難看,不過好在解析出來了~
?????? 第四:使用OCR解析這個(gè)數(shù)字:
# 圖片轉(zhuǎn)化成string:
try:
???from?PIL import?Image
except?ImportError:
???import?Image
import?pytesseract
captcha = Image.open(r'uniF0D5.png')
print(captcha)
result = pytesseract.image_to_string(captcha, lang='eng', config='--psm 6 --oem 3 -c tessedit_char_whitelist=0123456789').strip()
print(result)
? ? ? ??自此,我們的文字就可以直接識(shí)別出來了,我們就再也不需要用半自動(dòng)的小米加步槍了,我們可以直接使用沖鋒槍了
??????不過需要注意的是使用OCR解碼文字需要一定的時(shí)間,耗時(shí)還是比較長(zhǎng)的,如果經(jīng)常使用這一思路,建議可以構(gòu)建一個(gè)“字形坐標(biāo):文字”的數(shù)據(jù)庫表,下次使用時(shí)解析出字形坐標(biāo),直接到數(shù)據(jù)庫里匹配對(duì)應(yīng)的文字就可以了。

介紹一篇OCR的文章吧,可以了解一下如何解析文字:
http://www.inimei.cn/archives/770.html
-本文完-
