
一次Python爬蟲實戰(zhàn),解決反爬問題!

人生苦短,快學(xué)Python!
隨著互聯(lián)網(wǎng)的發(fā)展,Python的崛起,很多網(wǎng)站經(jīng)常被外面的爬蟲程序騷擾,有什么方法可以阻止爬蟲嗎?
阻止爬蟲也就稱之為反爬蟲,反爬蟲涉及到的技術(shù)比較綜合,說簡單也簡單,說復(fù)雜也復(fù)雜,看具體要做到哪種保護程度了。

針對于不同的網(wǎng)站,它的反爬措施不一樣,常見的反爬有User-Agent、ip代理、cookie認(rèn)證,js加密等等,與之對應(yīng)所保護的數(shù)據(jù)也不一樣。比如某寶某貓等電商網(wǎng)站,那么店鋪信息用戶信息就比較重要了,像是某眼電影網(wǎng)站,它對于電影評分,票房等信息做了反爬處理。
我們今天的采集目標(biāo)網(wǎng)站是某論壇,當(dāng)對其文章的文本數(shù)據(jù)進行采集時,但是發(fā)現(xiàn)有字體反爬措施,就是有的文本數(shù)據(jù)被替換了。
一、需求分析
我們是需要爬取論壇文本數(shù)據(jù),如下圖所示:
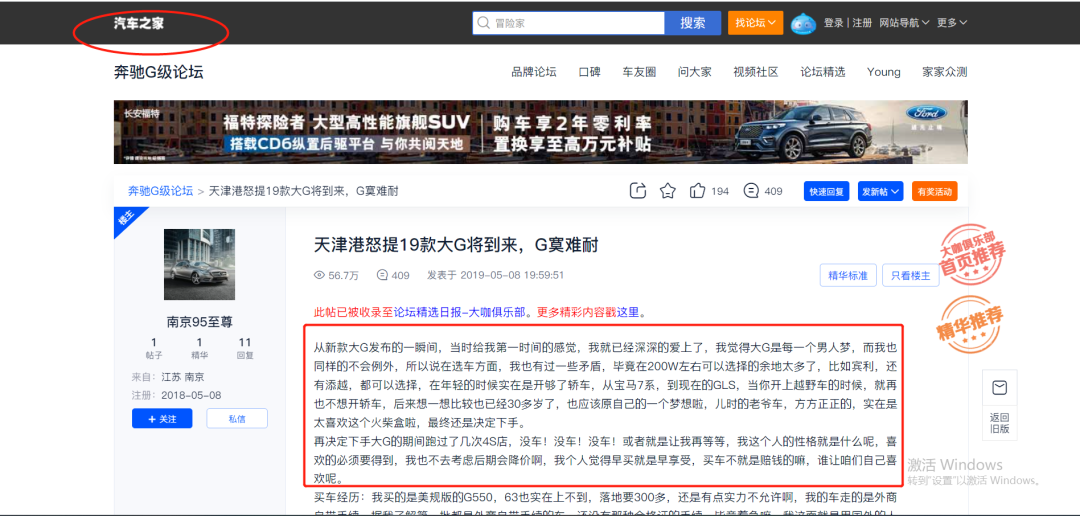
部分網(wǎng)頁源碼展示:

我們發(fā)現(xiàn)文本數(shù)據(jù)是在網(wǎng)頁源碼里面的。
二、發(fā)起請求
import requests
url = "https://club.autohome.com.cn/bbs/thread/665330b6c7146767/80787515-1.html"
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}
r = requests.get(url, headers=header)
html = etree.HTML(r.text)
content = html.xpath("http://div[@class='tz-paragraph']//text()")
print(content)
然后得到如下數(shù)據(jù)(部分?jǐn)?shù)據(jù)截圖):
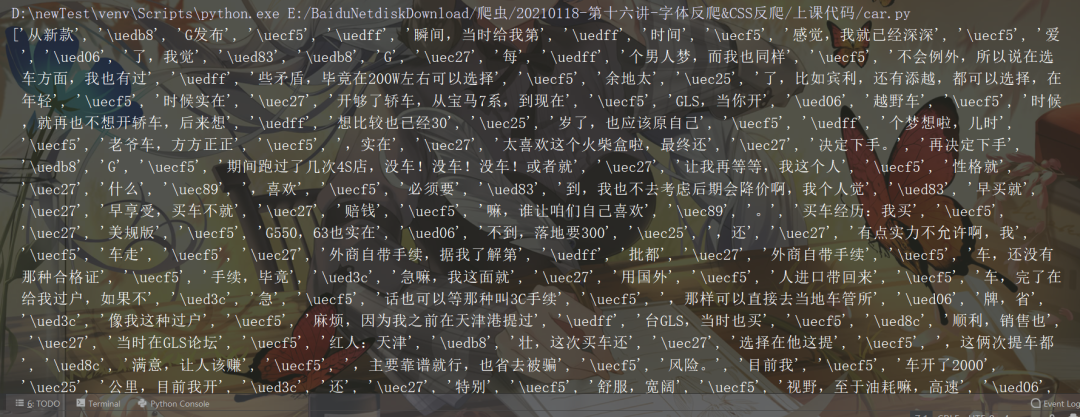
雖然在網(wǎng)頁源碼里面存在目標(biāo)數(shù)據(jù),但是通過requests簡單請求之后發(fā)現(xiàn)有的文字被特殊字符替換掉了,此時再次查看Elenments對應(yīng)的標(biāo)簽里的數(shù)據(jù),如下圖所示:
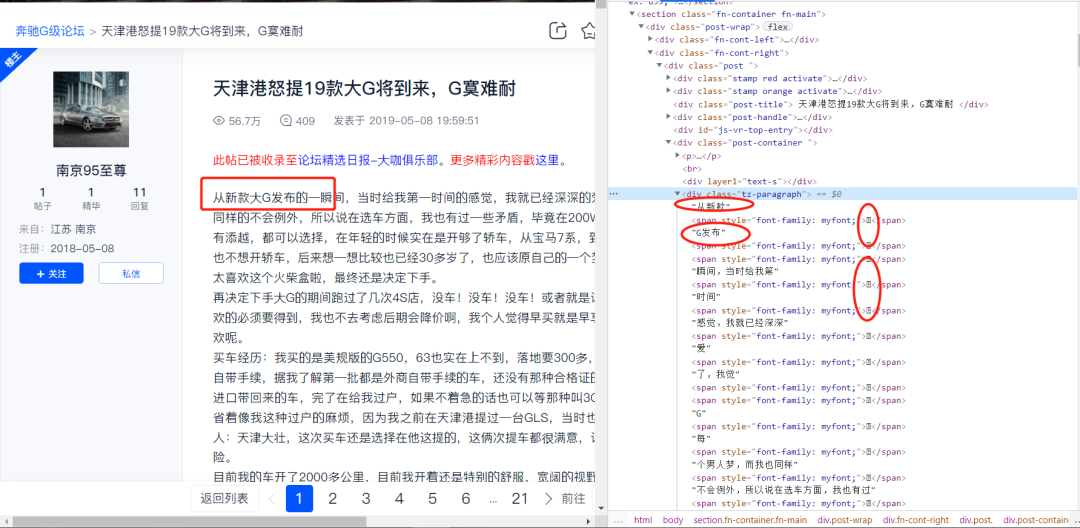
由圖可以發(fā)現(xiàn)有的字被替換掉了,所以我們需要找到漢字被替換的方式,然后替換回去。
三、字體替換
我們知道系統(tǒng)字體一般都是xxxx.ttf的文件形式,如下圖所示:
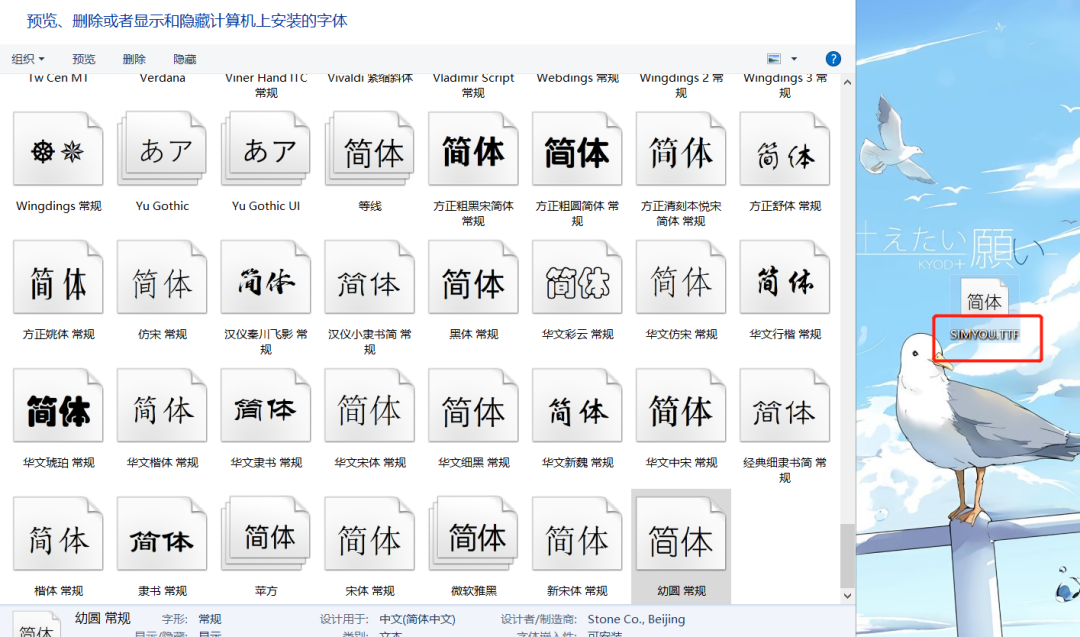
通過檢查發(fā)現(xiàn)該網(wǎng)站中使用的字體對應(yīng)的是myfont,這個很明顯是網(wǎng)站為了反爬設(shè)置的自定義的字體:
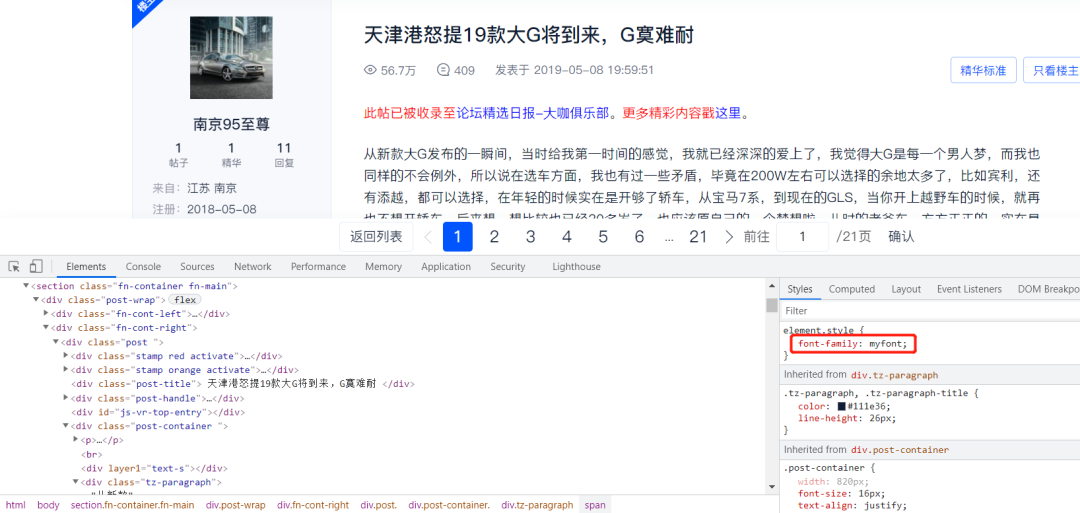
了解css的伙計應(yīng)該知道,網(wǎng)頁的字體樣式放在了style標(biāo)簽里面,如下圖所示:
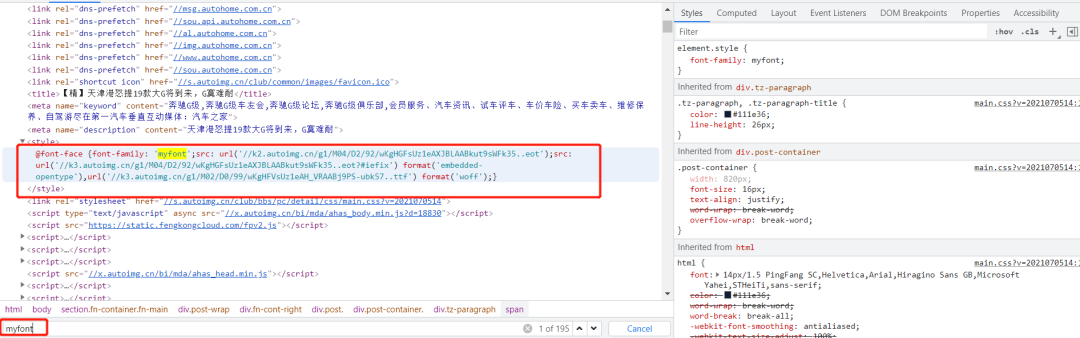
然后拿到url對應(yīng)屬性(xxx57..ttf),
//k3.autoimg.cn/g1/M02/D0/99/wKgHFVsUz1eAH_VRAABj9PS-ubk57..ttf
查看后發(fā)現(xiàn)是一個字體文件:
然后打開字體查看文件,把字體文件拖拽進去,如下圖所示:(使用軟件為FontCreator,可以查看字體的軟件)
如果不想使用軟件,可以打開百度字體平臺網(wǎng)站,對應(yīng)頁面和軟件打開是一樣的
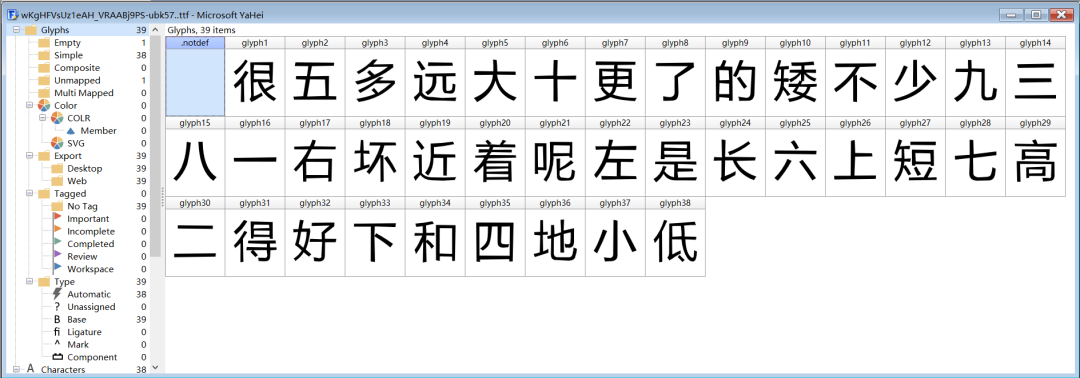
粗略一看其實發(fā)現(xiàn)不了什么,所以我們需要使用fontTools第三方庫查看字體文件:
from fontTools.ttLib import TTFont
font = TTFont('./wKgHFVsUz1eAH_VRAABj9PS-ubk57..ttf')
print(font.getGlyphOrder())
結(jié)果如下圖所示:

然后我們發(fā)現(xiàn)比如在先前的特殊字符表中,

這三個字應(yīng)該分別對應(yīng)于,大 、的、一,首先大對應(yīng)的后綴為edb8,在字體文件的輸出的列表中中有一個uniEDB8,對應(yīng)于第六個,然后再FontCreator軟件中剛好對應(yīng)第六個漢字大,如下圖所示:
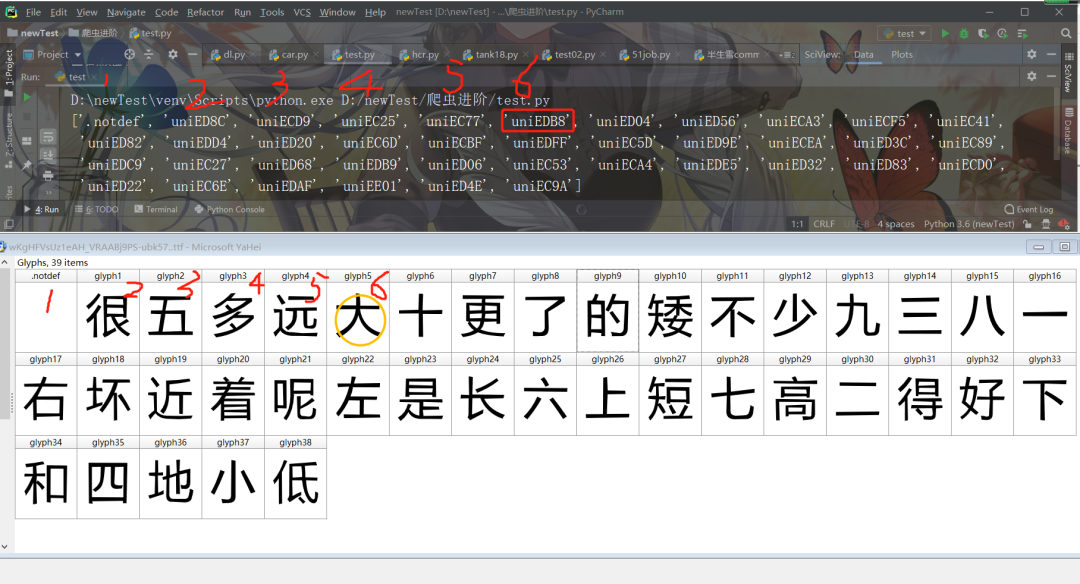
所以規(guī)律就是這樣的。
四、數(shù)據(jù)抓取
1、先把對應(yīng)的漢字打出來儲存在一個列表中;
word_list = ['很', '五', '多', '遠', '大', '十', '更', '了', '的', '矮', '不', '少', '九', '三', '八', '一', '右', '壞', '近', '著', '呢','左', '是', '長', '六', '上', '短', '七', '高', '二', '得', '好', '下', '和', '四', '地', '小', '低']
2、把字體文件對應(yīng)的特殊字符保存到另一個列表中,邊進行處理;
font = TTFont('wKgHFVsUz1eAH_VRAABj9PS-ubk57..ttf')
unilist = font.getGlyphOrder()
uni_list = []
for i in unilist[1:]:
s = r'\u' + i[3:]
uni_list.append(s)
print(uni_list)
但是問題出現(xiàn)了,結(jié)果如下:

我們發(fā)現(xiàn)出現(xiàn)了兩個反斜線,所以需要使用eval函數(shù)簡單修改:
font = TTFont('wKgHFVsUz1eAH_VRAABj9PS-ubk57..ttf')
unilist = font.getGlyphOrder()
# print(unilist)
uni_list = []
for i in unilist[1:]:
# print(i)
s = eval(r"'\u" + i[3:] + "'")
# print(s)
uni_list.append(s)
3、由于之前得到的不完整的文章數(shù)據(jù)是以一個列表的形式,所以需要把他拼接為字符串,然后使用replace(old,new),進行替換:
# ....前面代碼省略
html = etree.HTML(result) # result為請求網(wǎng)頁源碼
content = html.xpath("http://div[@class='tz-paragraph']//text()")
contents = ''.join(content)
4、最后進行替換:
for i in range(len(uni_list)):
contents = contents.replace(uni_list[i], word_list[i])
print(contents)
結(jié)果如下,文字替換成功:
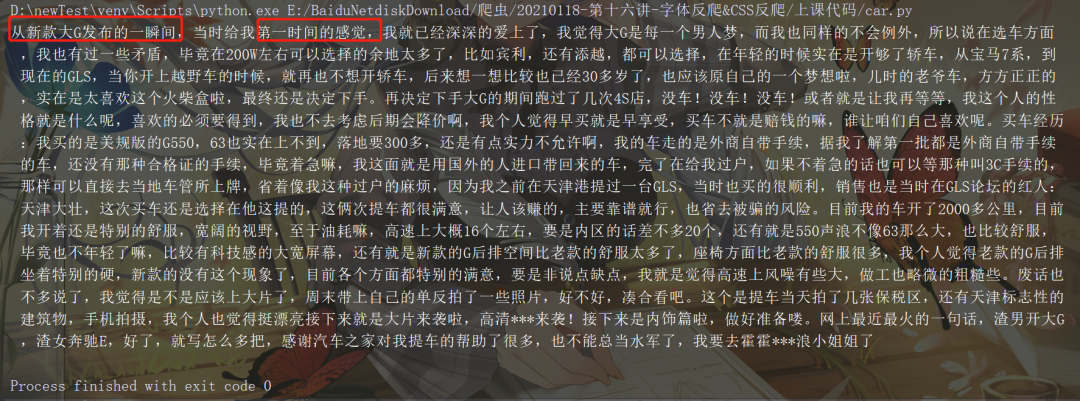
五、小結(jié)
通常在爬取一些網(wǎng)站的信息時,偶爾會碰到這樣一種情況:網(wǎng)頁瀏覽顯示是正常的,用 Python 爬取下來是亂碼,F(xiàn)12用開發(fā)者模式查看網(wǎng)頁源代碼也是亂碼。這種一般是網(wǎng)站設(shè)置了字體反爬。
字體反爬是一種比較常見的反爬方式,因為很多網(wǎng)站的文字信息是比較重要的,像是前面提到的貓眼電影電影票房評分等數(shù)據(jù),非常重要,網(wǎng)站維護者當(dāng)然會把這種數(shù)據(jù)進行反爬處理,只要好好分析,還是能夠抓取到目標(biāo)數(shù)據(jù)。

