
Python爬蟲遇到字體反爬?教你輕松搞定!
人生苦短,快學(xué)Python!
大家在使用Python爬蟲時,經(jīng)常會遇到各種反爬問題。今天就以貓眼電影為例,看看如何解決其中的 字體反爬 !

由于對于一部電影來說,它的票房和評分?jǐn)?shù)據(jù)是非常重要的,所以網(wǎng)站開發(fā)人員對它進(jìn)行了保護(hù),也就是字體反爬,今天的目標(biāo)是破解貓眼電影網(wǎng)站的字體反爬。
一、需求分析
我們是需要爬取論壇文本數(shù)據(jù),如下圖所示:
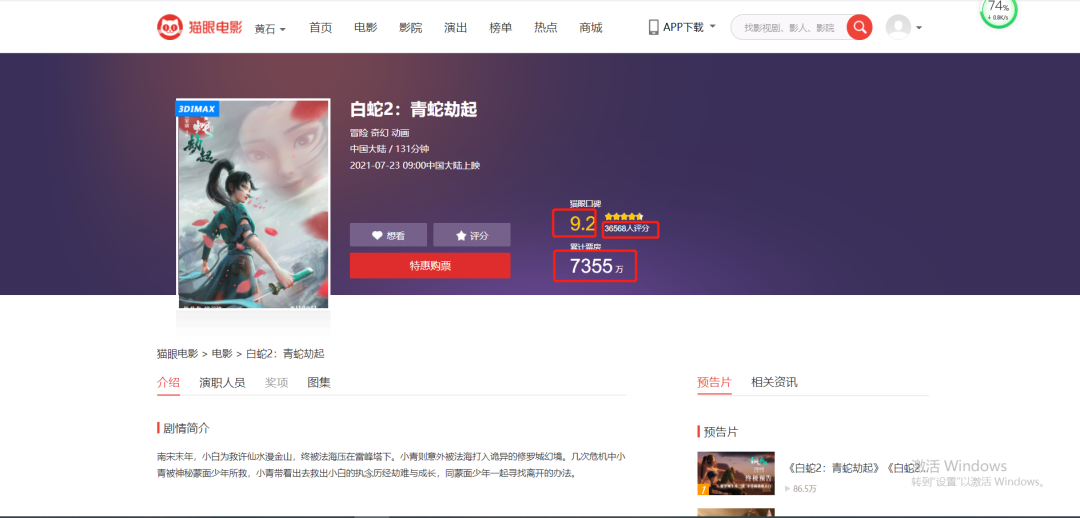
部分網(wǎng)頁源碼展示:
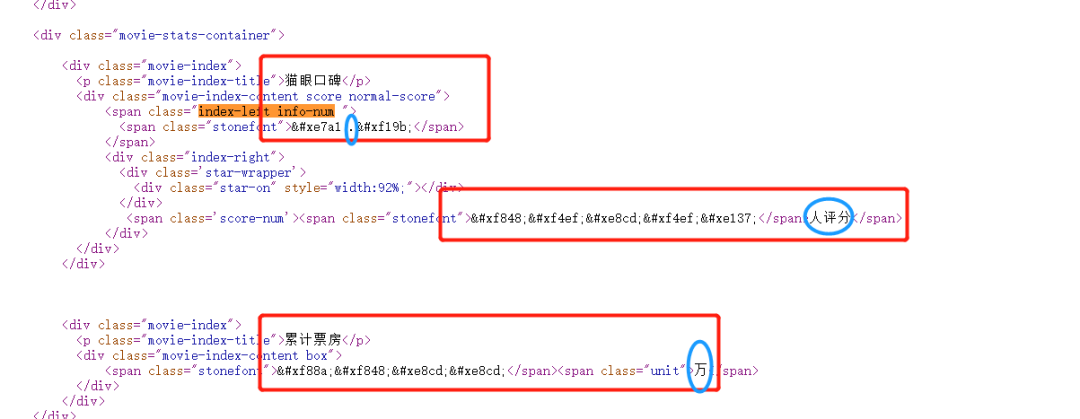
我們發(fā)現(xiàn)數(shù)據(jù)是不在網(wǎng)頁源碼里面,而是以一種特殊的字符存在的。
二、發(fā)起請求
import requests
url = "https://maoyan.com/films/1298542"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
r = requests.get(url,headers=headers)
print(r.text)
然后得到如下數(shù)據(jù)(部分?jǐn)?shù)據(jù)截圖):
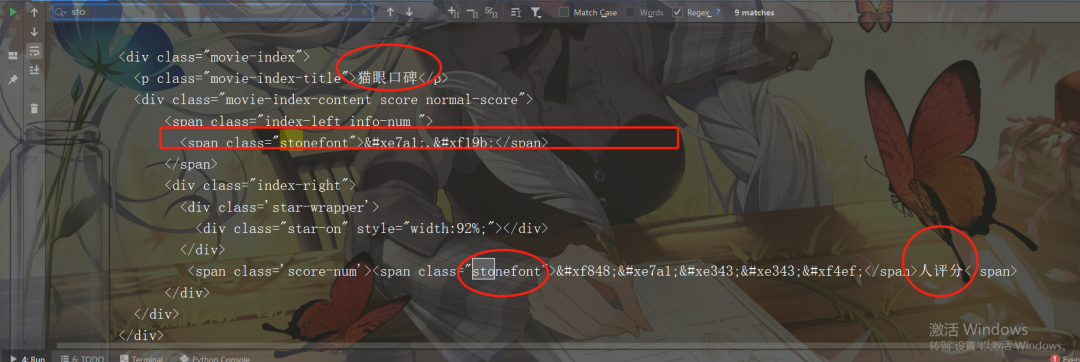
和網(wǎng)頁源碼里面的數(shù)據(jù)一樣,通過requests簡單請求之后發(fā)現(xiàn)評分,票房數(shù)據(jù)被特殊字符替換掉了,此時再次查看Elenments對應(yīng)的標(biāo)簽里的數(shù)據(jù),如下圖所示:
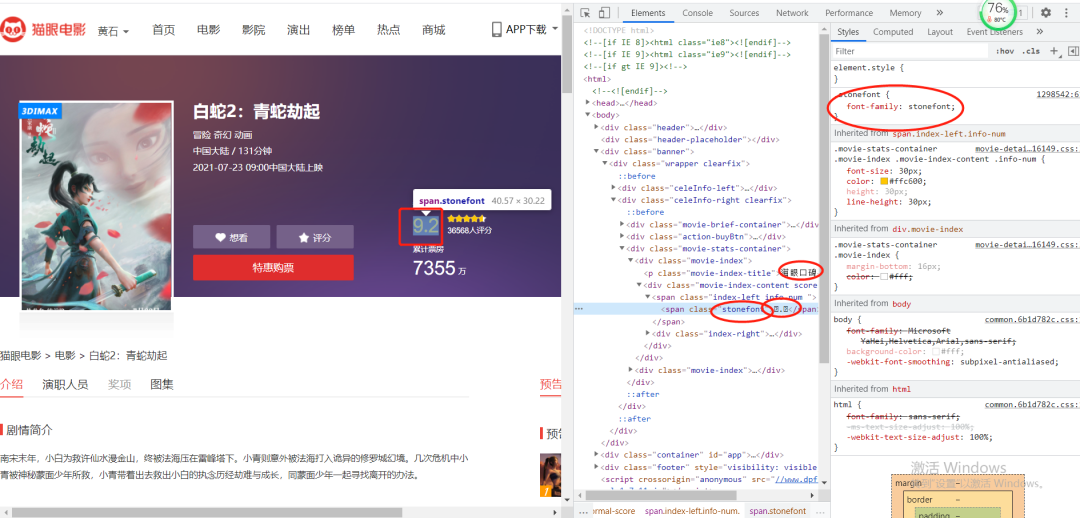
由圖可以發(fā)現(xiàn)有的字被替換掉了,所以我們需要找到數(shù)字被替換的方式(規(guī)律),然后替換回去。
三、替換規(guī)律
通過上面分可知,該網(wǎng)站中使用的字體對應(yīng)的是stonefont,它是該網(wǎng)站為了反爬設(shè)置的自定義字體,它一定存在于style(樣式)標(biāo)簽里面:
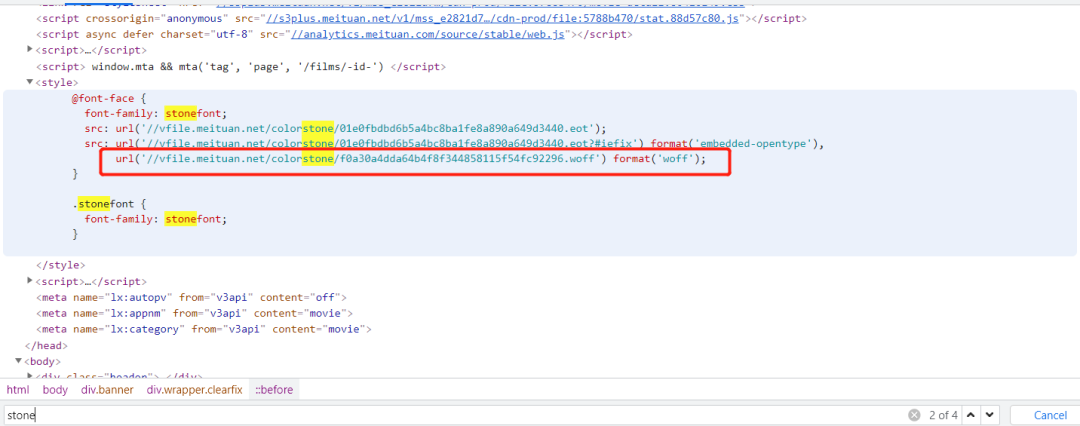
然后拿到url對應(yīng)屬性(xxx57..woff),它是不同于.ttf的字體文件,但是同樣可以使用FontCreator打開:
//k3.autoimg.cn/g1/M02/D0/99/wKgHFVsUz1eAH_VRAABj9PS-ubk57..ttf
注意:如果該屬性打不開文件,可以在屬性前加上 https://maoyan.com
查看后發(fā)現(xiàn)是一個字體文件:
然后打開字體查看文件,把字體文件拖拽進(jìn)去,如下圖所示:(使用軟件為FontCreator,可以查看字體的軟件)
如果不想使用軟件,可以打開百度字體平臺網(wǎng)站,對應(yīng)頁面和軟件打開是一樣的
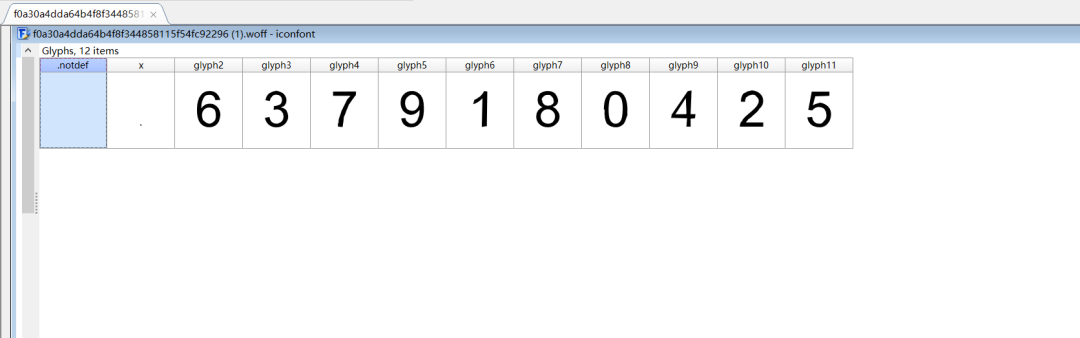
粗略一看其實發(fā)現(xiàn)不了什么,所以我們需要使用fontTools第三方庫查看字體文件:
from fontTools.ttLib import TTFont
font = TTFont('./f0a30a4dda64b4f8f344858115f54fc92296 (1).woff')
print(font.getGlyphOrder())
結(jié)果如下圖所示:
['glyph00000', 'x', 'uniF4EF', 'uniF848', 'uniF88A', 'uniE7A1', 'uniE343', 'uniE137', 'uniF489', 'uniE5E2', 'uniF19B', 'uniE8CD']
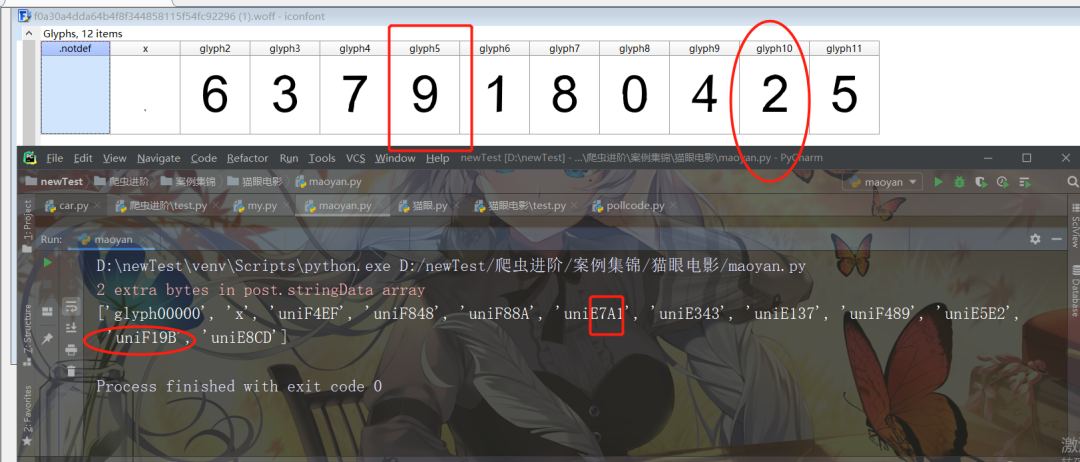
然后我們發(fā)現(xiàn)比如在先前的網(wǎng)頁源碼中發(fā)現(xiàn)的,
. # 對應(yīng)網(wǎng)頁中的9.2
然后由此查看后綴,9----e7a1,在上圖中
四、數(shù)據(jù)抓取
1、導(dǎo)包,我們使用re第三方庫解析
import requests
import re
from fontTools.ttLib import TTFont
2、定制一個類(Maoyan),以及初始化屬性設(shè)置:
class MaoYan(object):
def __init__(self):
self.url = 'https://maoyan.com/films/1298542'
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"
}
self.font = TTFont('./f0a30a4dda64b4f8f344858115f54fc92296 (1).woff')
self.numList = ['6', '3', '7', '9', '8', '0', '4', '2', '5']
3、相關(guān)方法設(shè)置
發(fā)送請求獲取相應(yīng)
def get_html(self, url):
response = requests.get(url, headers=self.headers)
return response.content
處理字體文件
def getNewList(self):
newList = []
glyList = self.font.getGlyphOrder()[2:] # 前兩個數(shù)據(jù)是沒有用的,剔除
for gly in glyList:
m = gly.replace('uni', '&#x').lower() + ';' # replace字符替換
newList.append(m)
return newList
解析數(shù)據(jù)
def parseData(self, data):
for i in self.getNewList():
if i in data:
print(self.numList[self.getNewList().index(i)])
data = data.replace(i, self.numList[self.getNewList().index(i)])
return data
正則匹配以及最終輸出
def start_crawl(self):
html = self.get_html(self.url).decode('utf-8')
# 正則匹配星級
star = re.findall(r'<span class="index-left info-num ">\s+<span class="stonefont">(.*?)</span>\s+</span>', html)[0]
print(star)
star = self.parseData(star)
print('用戶評分: %s 星' % star)
4、最后運行:
if __name__ == '__main__':
maoyan = MaoYan()
maoyan.start_crawl()
結(jié)果如下,文字替換成功:

由于票房數(shù)據(jù)和這個評分有著異曲同工之妙,所以這里不再贅述,感興趣的小伙伴可以去試一下。
五、小結(jié)
通常在2爬取一些網(wǎng)站的信息時,偶爾會碰到這樣一種情況:網(wǎng)頁瀏覽顯示是正常的,用 Python 爬取下來是亂碼,F(xiàn)12用開發(fā)者模式查看網(wǎng)頁源代碼也是亂碼。這種一般是網(wǎng)站設(shè)置了字體反爬。字體反爬是一種比較常見的反爬方式,因為很多網(wǎng)站的文字信息是比較重要的,像是前面提到的貓眼電影電影票房評分等數(shù)據(jù),非常重要,網(wǎng)站維護(hù)者當(dāng)然會把這種數(shù)據(jù)進(jìn)行反爬處理,只要好好分析,還是能夠抓取到目標(biāo)數(shù)據(jù)。
注意點:
字符匹配以及替換,還有正則表達(dá)式的書寫規(guī)范 貓眼驗證,當(dāng)用戶頻繁的發(fā)起請求時,他會有一個驗證,滑塊驗證,這個時候最好使用selenium手動操作一下,然后就可以正常的請求數(shù)據(jù)。
我們的文章到此就結(jié)束啦,如果你喜歡今天的Python 實戰(zhàn)教程,請持續(xù)關(guān)注Python實用寶典。
有任何問題,可以在公眾號后臺回復(fù):加群,回答相應(yīng)紅字驗證信息,進(jìn)入互助群詢問。
原創(chuàng)不易,希望你能在下面點個贊和在看支持我繼續(xù)創(chuàng)作,謝謝!
點擊下方閱讀原文可獲得更好的閱讀體驗
Python實用寶典 (pythondict.com)
不只是一個寶典
歡迎關(guān)注公眾號:Python實用寶典