「小樣本深度學(xué)習(xí)圖像識別」最新2022綜述
技術(shù)來自于點擊下方卡片,關(guān)注“新機器視覺”公眾號
視覺/圖像重磅干貨,第一時間送達
小樣本深度學(xué)習(xí)圖像識別最新綜述論文
圖像識別是圖像研究領(lǐng)域的核心問題, 解決圖像識別問題對人臉識別、自動駕駛、機器人等各領(lǐng)域研究都有重要意義. 目前廣泛使用的基于深度神經(jīng)網(wǎng)絡(luò)的機器學(xué)習(xí)方法, 已經(jīng)在鳥類分類、人臉識別、日常物品分類等圖像識別數(shù)據(jù)集上達到了超過人類的水平, 同時越來越多的工業(yè)界應(yīng)用開始考慮基于深度神經(jīng)網(wǎng)絡(luò)的方法, 以完成一系列圖像識別業(yè)務(wù). 但是深度學(xué)習(xí)方法極度依賴大規(guī)模標(biāo)注數(shù)據(jù), 這一缺陷極大地限制了深度學(xué)習(xí)方法在實際圖像識別任務(wù)中的應(yīng)用. 針對這一問題, 越來越多的研究者開始研究如何基于少量的圖像識別標(biāo)注樣本來訓(xùn)練識別模型. 為了更好地理解基于少量標(biāo)注樣本的圖像識別問題, 廣泛地討論了幾種圖像識別領(lǐng)域主流的少量標(biāo)注學(xué)習(xí)方法, 包括基于數(shù)據(jù)增強的方法、基于遷移學(xué)習(xí)的方法以及基于元學(xué)習(xí)的方法, 通過討論不同算法的流程以及核心思想, 可以清晰地看到現(xiàn)有方法在解決少量標(biāo)注的圖像識別問題上的優(yōu)點和不足. 最后針對現(xiàn)有方法的局限性, 指出了小樣本圖像識別未來的研究方向.
地址:
http://www.jos.org.cn/jos/article/abstract/6342?st=article_issue
現(xiàn)在的機器學(xué)習(xí)方法, 尤其是基于深度神經(jīng)網(wǎng)絡(luò)的機器學(xué)習(xí)方法已經(jīng)在人臉識別[1]、自動駕駛[2]、機器人[3] 等圖像識別相關(guān)領(lǐng)域取得了巨大的成就, 有的甚至已經(jīng)超過人類目前的識別水平. 然而在深度學(xué)習(xí)取得巨大成就 的同時, 人們發(fā)現(xiàn)把其應(yīng)用到實際問題中卻困難重重. 首先是標(biāo)注數(shù)據(jù)的問題, 目前的深度學(xué)習(xí)方法需要大量的標(biāo) 注數(shù)據(jù)來進行訓(xùn)練[4] , 但是實際應(yīng)用中數(shù)據(jù)獲取往往是困難的, 這之中既有個人隱私的問題, 比如人臉數(shù)據(jù), 也有 問題對象本身就很少的問題, 比如識別珍稀保護動物的問題, 除此之外, 數(shù)據(jù)標(biāo)注工作往往需要耗費大量人力物力, 從而阻礙了深度學(xué)習(xí)技術(shù)在圖像識別領(lǐng)域的落地. 其次是算力問題, 深度學(xué)習(xí)方法在提高算法性能的同時, 往往伴隨著龐大的網(wǎng)絡(luò)運算, 這也就使得深度學(xué)習(xí)的方法很難部署在計算資源受限的設(shè)備上, 因此在一些算力受限 的應(yīng)用場景, 比如自動駕駛、機器人、道路監(jiān)控等問題中, 圖像識別任務(wù)目前大多還是使用一些低智能化、低算力消耗的技術(shù)完成的, 這同樣嚴(yán)重阻礙了智能化圖像識別技術(shù)的發(fā)展.
與之相反, 人類的識別卻是相對輕量的, 即并不需要收集大量的數(shù)據(jù)來進行學(xué)習(xí), 更不需要長時間的思考或者 計算[5] . 比如父母教新生嬰兒識字, 分辨動物, 只需要簡單地在家里貼上一兩幅相應(yīng)的字畫即可, 小孩很快就會認(rèn) 識上面的內(nèi)容. 如何在保留現(xiàn)在的深度學(xué)習(xí)方法強大的知識表示能力的同時, 使其可以快速從少量樣本中學(xué)習(xí)到 有用的知識, 這種基于小樣本的圖像識別問題已經(jīng)逐漸引起了人們的注意.
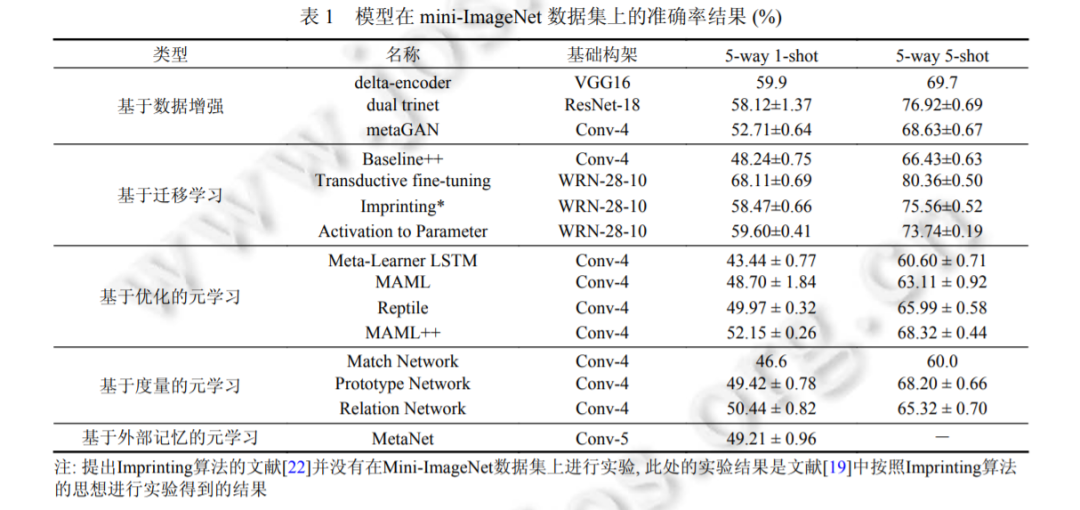
本文將按照下面的順序來展開討論, 首先在第 1 節(jié)介紹小樣本圖像識別的問題描述, 然后會在第 2 節(jié)介紹基 于數(shù)據(jù)增強的小樣本學(xué)習(xí)算法, 在第 3 部分介紹基于遷移學(xué)習(xí)的算法, 在第 4 節(jié)介紹基于元學(xué)習(xí)的算法, 會在第 5 節(jié)介紹現(xiàn)在廣泛使用的小樣本圖像識別問題評價指標(biāo), 并對比上面介紹的算法在該問題基準(zhǔn)上的性能, 最后會在 第 6 部分指出現(xiàn)有算法的不足以及未來的發(fā)展方向.
1 小樣本學(xué)習(xí)簡介
小樣本圖像識別任務(wù)需要機器學(xué)習(xí)模型在少量標(biāo)注數(shù)據(jù)上進行訓(xùn)練和學(xué)習(xí), 目前經(jīng)常研究的問題為 N-way Kshot 形式, 即問題包括 N 種數(shù)據(jù), 每種數(shù)據(jù)只包含 K 個標(biāo)注樣本[6] . 現(xiàn)有的小樣本圖像識別問題可以看做是基于深 度遷移學(xué)習(xí)的圖像識別問題, 這里我們把上面提到的少量標(biāo)注數(shù)據(jù)稱作目標(biāo)數(shù)據(jù)域, 后續(xù)的識別任務(wù)都是基于目 標(biāo)數(shù)據(jù)所包含的類別進行的; 然后為了輔助模型的訓(xùn)練, 通常會引入一個和目標(biāo)數(shù)據(jù)域類別互斥的輔助數(shù)據(jù)集, 和 目標(biāo)數(shù)據(jù)域的少量標(biāo)注相反, 輔助數(shù)據(jù)集的標(biāo)注樣本更加豐富, 類別也更加多.
解決 N-way K-shot 形式的小樣本圖像識別任務(wù), 大多數(shù)方法會從輔助數(shù)據(jù)集學(xué)習(xí)先驗知識, 然后在標(biāo)注有限 的目標(biāo)數(shù)據(jù)域上利用這些先驗知識完成學(xué)習(xí)和預(yù)測任務(wù). 在下面的章節(jié)我們會詳細(xì)討論如何基于輔助數(shù)據(jù)集來學(xué) 習(xí)先驗知識, 以及如何利用這些先驗知識來在小樣本圖像識別問題上完成學(xué)習(xí)和預(yù)測.
2 基于數(shù)據(jù)增強的小樣本圖像識別方法
小樣本圖像識別任務(wù)的核心問題是標(biāo)注數(shù)據(jù)不足, 所以通過算法生成人工標(biāo)注數(shù)據(jù), 來擴充原有的數(shù)據(jù)量是 一種非常直觀的方法[7] . 在小樣本圖像識別任務(wù)領(lǐng)域, 目前常用的數(shù)據(jù)增強方法基本上都是利用少量的標(biāo)注數(shù)據(jù) 來生成更多的偽數(shù)據(jù), 比如人工合成圖像, 同時需要給這些偽數(shù)據(jù)打上標(biāo)簽, 然后作為標(biāo)注數(shù)據(jù)來輔助訓(xùn)練, 本質(zhì) 上和遷移學(xué)習(xí)的方法是異曲同工的[8] . 按照偽數(shù)據(jù)的使用方式, 可以將其劃分為兩種類型: 一種是使用偽數(shù)據(jù)來填 補標(biāo)注不足的小樣本數(shù)據(jù), 另外一種是使用偽數(shù)據(jù)來顯式地銳化分類算法學(xué)習(xí)到的決策邊界. 下面就這兩種方法 以及對應(yīng)的具體算法展開討論.
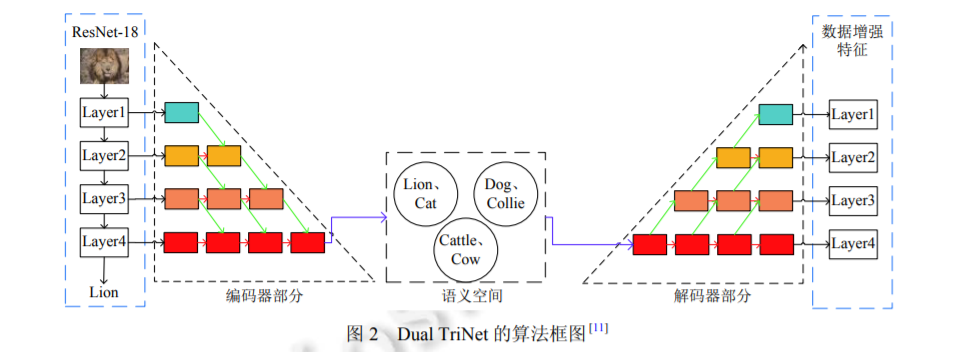
基于數(shù)據(jù)增強的思路來解決小樣本學(xué)習(xí)問題是一種最直觀的思路, 而且該類方法更加靈活, 通過設(shè) 計數(shù)據(jù)增強模塊生成偽數(shù)據(jù), 將其擴充到小樣本數(shù)據(jù)中, 使用混合數(shù)據(jù)直接對識別模型進行更新即可. 但是因為實 際樣本數(shù)目較少, 目前廣泛使用的基于深度神經(jīng)網(wǎng)絡(luò)的方法在實際的數(shù)據(jù)增強中, 容易出現(xiàn)知識偏移以及過擬合 的問題, 所以實際的應(yīng)用效果會比后面介紹的幾類方法差一些. 但是這種數(shù)據(jù)增強的思路對于解決實際的樣本缺 失問題來說更具有普遍意義, 所以將數(shù)據(jù)增強的思路融入遷移學(xué)習(xí)或者元學(xué)習(xí)的算法中, 是未來值得研究的方向.
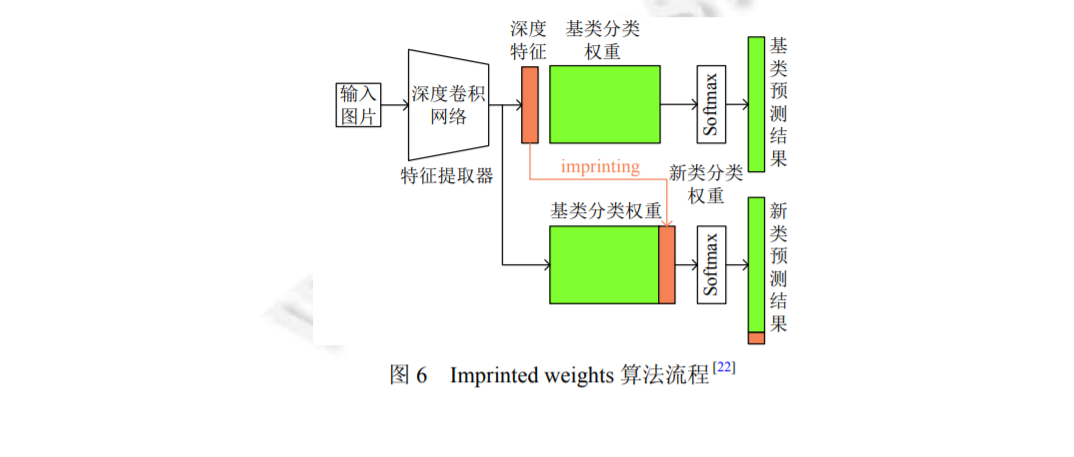
3 基于遷移學(xué)習(xí)的小樣本圖像識別方法
面對標(biāo)注限制的機器學(xué)習(xí)任務(wù), 一個很自然的思路就是將模型在大數(shù)據(jù)集上進行預(yù)訓(xùn)練, 從中學(xué)習(xí)到一些有 利于當(dāng)前任務(wù)的先驗知識, 從而來彌補標(biāo)注數(shù)據(jù)不足的問題. 這一方法在機器學(xué)習(xí)領(lǐng)域, 尤其是近幾年普遍使用的 神經(jīng)網(wǎng)絡(luò)方法中取得了不錯的效果, 下面關(guān)于為什么遷移學(xué)習(xí)[16]可以應(yīng)用于小樣本學(xué)習(xí), 以及遷移學(xué)習(xí)如何應(yīng)用 于小樣本學(xué)習(xí)進行討論。
4 基于元學(xué)習(xí)的小樣本圖像識別方法
元學(xué)習(xí)[24]的目標(biāo)是使得網(wǎng)絡(luò)模型具有快速學(xué)習(xí)的能力, 快速學(xué)習(xí)是人類與生俱來的一種生存能力, 元學(xué)習(xí)方 法希望模型具有像人類一樣, 通過較少的示例就可以在較短的時間內(nèi)學(xué)會分辨新的事物的能力. 通過元學(xué)習(xí)的問 題定義可以發(fā)現(xiàn), 元學(xué)習(xí)方法是處理小樣本學(xué)習(xí)問題的一個重要思路. 本節(jié)將圍繞 3 種用于小樣本圖像識別問題 的元學(xué)習(xí)方法展開討論, 這 3 種方法分別為基于優(yōu)化器的小樣本學(xué)習(xí)算法, 基于度量的小樣本學(xué)習(xí)算法以及基于 外部記憶的小樣本學(xué)習(xí)算法.
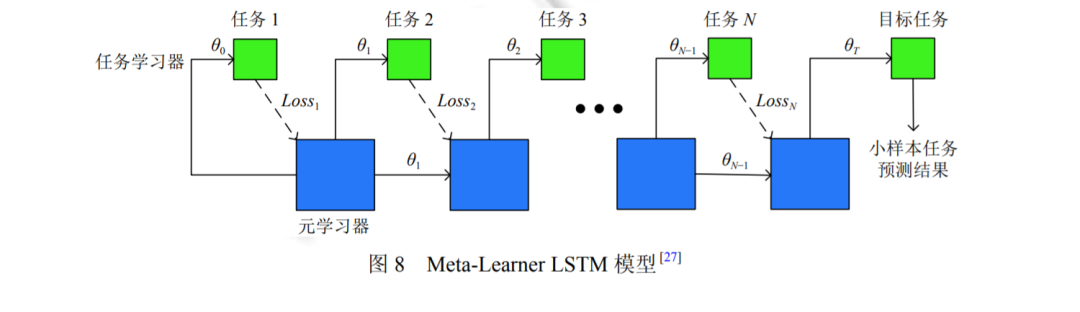
基于元學(xué)習(xí)的思路來解決小樣本學(xué)習(xí)問題, 是近兩年該領(lǐng)域的研究熱點, 如何劃分任務(wù)通用參數(shù)和任務(wù)特定 參數(shù), 如何更加有效地訓(xùn)練元學(xué)習(xí)模型等課題一直具有相當(dāng)?shù)幕盍? 元學(xué)習(xí)算法希望學(xué)習(xí)一個可以“自主”學(xué)習(xí)的模型, 使得模型在只有少量樣本的新任務(wù)上可以快速泛化. 盡管元學(xué)習(xí)方法在小樣本學(xué)習(xí)中已經(jīng)取得了不錯的效 果, 但是該類方法仍然存在一些問題.
(1) 元學(xué)習(xí)算法優(yōu)化難; 因為采用多任務(wù)交替訓(xùn)練的方式來更新模型, 不同任務(wù)的數(shù)據(jù)之間存在數(shù)據(jù)分布的不 同, 只是簡單地交替訓(xùn)練, 在任務(wù)數(shù)據(jù)分布差別較大的時候, 會導(dǎo)致最后的模型難以收斂的問題;
(2) 元學(xué)習(xí)算法缺乏相關(guān)的可解釋性; 元學(xué)習(xí)算法的思路具有一定的啟發(fā)性, 但是關(guān)于方法的有效性一直難以 被證明, 同時元學(xué)習(xí)方法和遷移學(xué)習(xí)方法之間的區(qū)別也一直是研究者們關(guān)注的重點, 如何從理論上解釋元學(xué)習(xí)的 有效性, 是未來的一個重要的研究方向.