
計(jì)算機(jī)視覺(jué)中的半監(jiān)督學(xué)習(xí)
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

作者:Amit Chaudhary
編譯:ronghuaiyang
圖解半監(jiān)督的各種方法的關(guān)鍵思想。
計(jì)算機(jī)視覺(jué)的半監(jiān)督學(xué)習(xí)方法在過(guò)去幾年得到了快速發(fā)展。目前最先進(jìn)的方法是在結(jié)構(gòu)和損失函數(shù)方面對(duì)之前的工作進(jìn)行了簡(jiǎn)化,以及引入了通過(guò)混合不同方案的混合方法。
在該半監(jiān)督公式中,對(duì)有標(biāo)簽數(shù)據(jù)進(jìn)行訓(xùn)練,并對(duì)沒(méi)有標(biāo)簽的數(shù)據(jù)進(jìn)行偽標(biāo)簽預(yù)測(cè)。然后對(duì)模型同時(shí)進(jìn)行 ground truth 標(biāo)簽和偽標(biāo)簽的訓(xùn)練。
a. 偽標(biāo)簽
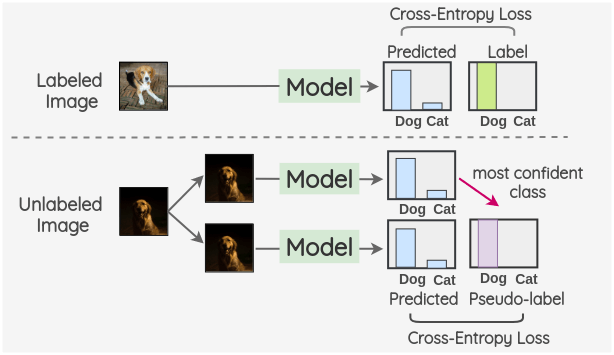
Dong-Hyun Lee[1]在 2013 年提出了一個(gè)非常簡(jiǎn)單有效的公式 —— 偽標(biāo)簽。
這個(gè)想法是在一批有標(biāo)簽和沒(méi)有標(biāo)簽的圖像上同時(shí)訓(xùn)練一個(gè)模型。在使用交叉熵?fù)p失的情況下,以普通的監(jiān)督的方式對(duì)有標(biāo)簽圖像進(jìn)行訓(xùn)練。利用同一模型對(duì)一批沒(méi)有標(biāo)簽的圖像進(jìn)行預(yù)測(cè),并使用置信度最大的類(lèi)作為偽標(biāo)簽。然后,通過(guò)比較模型預(yù)測(cè)和偽標(biāo)簽對(duì)沒(méi)有標(biāo)簽的圖像計(jì)算交叉熵?fù)p失。
總的 loss 是有標(biāo)簽和沒(méi)有標(biāo)簽的 loss 的加權(quán)和。
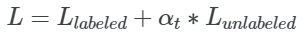
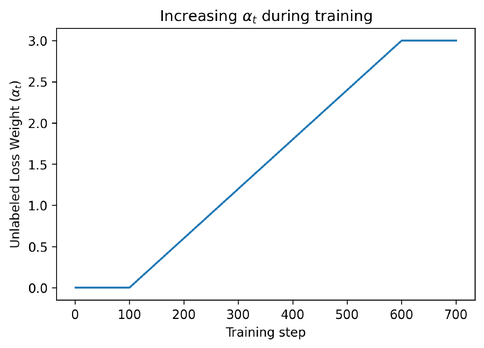
為了確保模型已經(jīng)從有標(biāo)簽的數(shù)據(jù)中學(xué)到了足夠的知識(shí),在最初的 100 個(gè) epoch 中,αt 被設(shè)置為 0。然后逐漸增加到 600 個(gè) epochs,然后保持不變。
b. Noisy Student
Xie 等[2]在 2019 年提出了一種受知識(shí)蒸餾啟發(fā)的半監(jiān)督方法“Noisy Student”。
關(guān)鍵的想法是訓(xùn)練兩種不同的模型,即“Teacher”和“Student”。Teacher 模型首先對(duì)有標(biāo)簽的圖像進(jìn)行訓(xùn)練,然后對(duì)沒(méi)有標(biāo)簽的圖像進(jìn)行偽標(biāo)簽推斷。這些偽標(biāo)簽可以是軟標(biāo)簽,也可以通過(guò)置信度最大的類(lèi)別轉(zhuǎn)換為硬標(biāo)簽。然后,將有標(biāo)簽和沒(méi)有標(biāo)簽的圖像組合在一起,并根據(jù)這些組合的數(shù)據(jù)訓(xùn)練一個(gè) Student 模型。使用 RandAugment 進(jìn)行圖像增強(qiáng)作為輸入噪聲的一種形式。此外,模型噪聲,如 Dropout 和隨機(jī)深度也用到了 Student 模型結(jié)構(gòu)中。
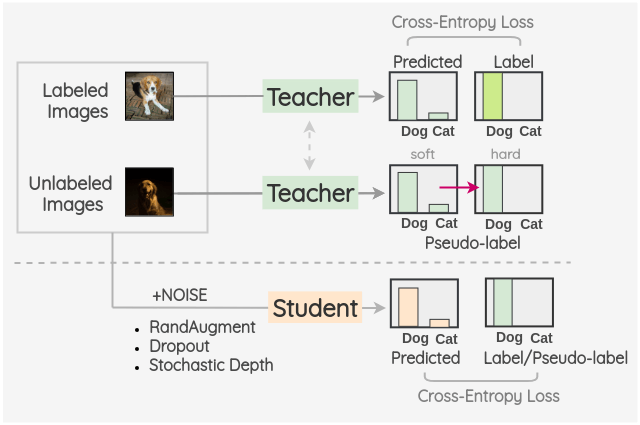
一旦學(xué)生模型被訓(xùn)練好了,它就變成了新的老師,這個(gè)過(guò)程被重復(fù)三次。
這種模式使用的理念是,即使在添加了噪聲之后,對(duì)未標(biāo)記圖像的模型預(yù)測(cè)也應(yīng)該保持不變。我們可以使用輸入噪聲,如圖像增強(qiáng)和高斯噪聲。噪聲也可以通過(guò)使用 Dropout 引入到結(jié)構(gòu)中。
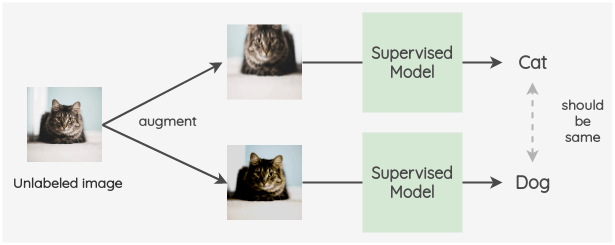
a. π-model
該模型由Laine 等[3]在 ICLR 2017 年的一篇會(huì)議論文中提出。
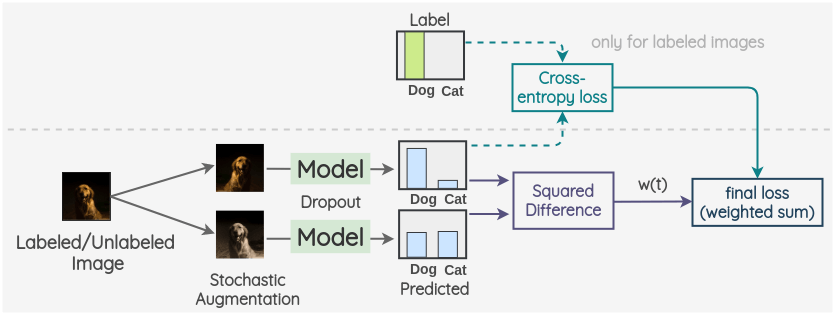
關(guān)鍵思想是為標(biāo)記數(shù)據(jù)和未標(biāo)記數(shù)據(jù)創(chuàng)建兩個(gè)隨機(jī)的圖像增強(qiáng)。然后,使用帶有 dropout 的模型對(duì)兩幅圖像的標(biāo)簽進(jìn)行預(yù)測(cè)。這兩個(gè)預(yù)測(cè)的平方差被用作一致性損失。對(duì)于標(biāo)記了的圖像,我們也同時(shí)計(jì)算交叉熵?fù)p失。總損失是這兩個(gè)損失項(xiàng)的加權(quán)和。權(quán)重 w(t)用于決定一致性損失在總損失中所占的比重。
b. Temporal Ensembling
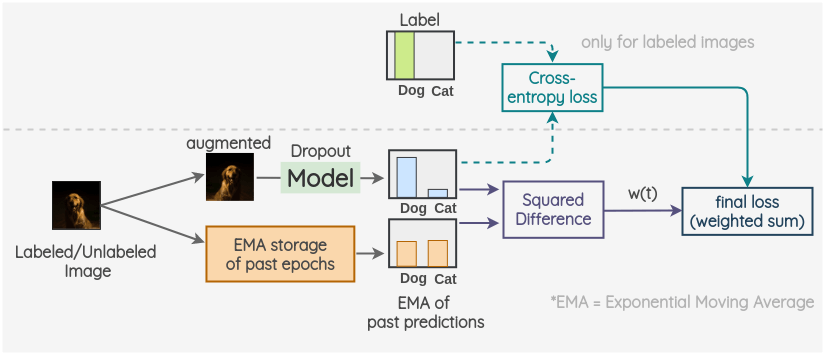
該方法也是由Laine 等[4]在同一篇論文中提出的。它通過(guò)利用預(yù)測(cè)的指數(shù)移動(dòng)平均(EMA)來(lái)修正模型。
關(guān)鍵思想是對(duì)過(guò)去的預(yù)測(cè)使用指數(shù)移動(dòng)平均作為一個(gè)觀測(cè)值。為了獲得另一個(gè)觀測(cè)值,我們像往常一樣對(duì)圖像進(jìn)行增強(qiáng),并使用帶有 dropout 的模型來(lái)預(yù)測(cè)標(biāo)簽。采用當(dāng)前預(yù)測(cè)和 EMA 預(yù)測(cè)的平方差作為一致性損失。對(duì)于標(biāo)記了的圖像,我們也計(jì)算交叉熵?fù)p失。最終損失是這兩個(gè)損失項(xiàng)的加權(quán)和。權(quán)重 w(t)用于決定稠度損失在總損失中所占的比重。
c. Mean Teacher
該方法由Tarvainen 等[5]提出。泛化的方法類(lèi)似于 Temporal Ensembling,但它對(duì)模型參數(shù)使用指數(shù)移動(dòng)平均(EMA),而不是預(yù)測(cè)值。
關(guān)鍵思想是有兩種模型,稱(chēng)為“Student”和“Teacher”。Student 模型是有 dropout 的常規(guī)模型。教師模型與學(xué)生模型具有相同的結(jié)構(gòu),但其權(quán)重是使用學(xué)生模型權(quán)重的指數(shù)移動(dòng)平均值來(lái)設(shè)置的。對(duì)于已標(biāo)記或未標(biāo)記的圖像,我們創(chuàng)建圖像的兩個(gè)隨機(jī)增強(qiáng)的版本。然后,利用學(xué)生模型預(yù)測(cè)第一張圖像的標(biāo)簽分布。利用教師模型對(duì)第二幅增強(qiáng)圖像的標(biāo)簽分布進(jìn)行預(yù)測(cè)。這兩個(gè)預(yù)測(cè)的平方差被用作一致性損失。對(duì)于標(biāo)記了的圖像,我們也計(jì)算交叉熵?fù)p失。最終損失是這兩個(gè)損失項(xiàng)的加權(quán)和。權(quán)重 w(t)用于決定稠度損失在總損失中所占的比重。

d. Virtual Adversarial Training
該方法由Miyato 等[6]提出。利用對(duì)抗性攻擊的概念進(jìn)行一致性正則化。
關(guān)鍵的想法是生成一個(gè)圖像的對(duì)抗性變換,著將改變模型的預(yù)測(cè)。為此,首先,拍攝一幅圖像并創(chuàng)建它的對(duì)抗變體,使原始圖像和對(duì)抗圖像的模型輸出之間的 KL 散度最大化。
然后按照前面的方法進(jìn)行。我們將帶標(biāo)簽/不帶標(biāo)簽的圖像作為第一個(gè)觀測(cè),并將在前面步驟中生成的與之對(duì)抗的樣本作為第二個(gè)觀測(cè)。然后,用同一模型對(duì)兩幅圖像的標(biāo)簽分布進(jìn)行預(yù)測(cè)。這兩個(gè)預(yù)測(cè)的 KL 散度被用作一致性損失。對(duì)于標(biāo)記了的圖像,我們也計(jì)算交叉熵?fù)p失。最終損失是這兩個(gè)損失項(xiàng)的加權(quán)和。采用加權(quán)偏置模型來(lái)確定一致性損失在整體損失中所占的比重。
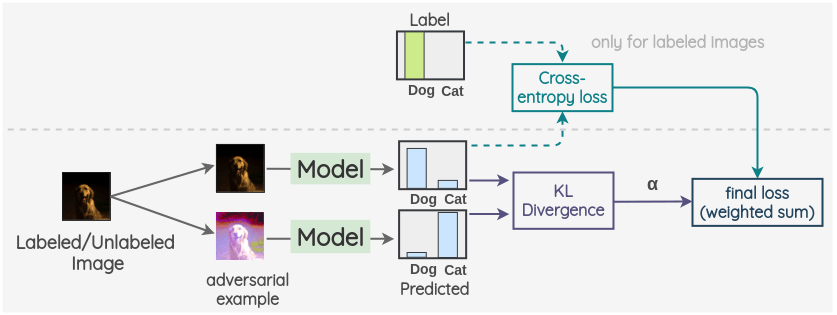
e. Unsupervised Data Augmentation
該方法由Xie 等[7]提出,適用于圖像和文本。在這里,我們將在圖像的上下文中理解該方法。
關(guān)鍵思想是使用自動(dòng)增強(qiáng)創(chuàng)建一個(gè)增強(qiáng)版本的無(wú)標(biāo)簽圖像。然后用同一模型對(duì)兩幅圖像的標(biāo)簽進(jìn)行預(yù)測(cè)。這兩個(gè)預(yù)測(cè)的 KL 散度被用作一致性損失。對(duì)于有標(biāo)記的圖像,我們只計(jì)算交叉熵?fù)p失,不計(jì)算一致性損失。最終的損失是這兩個(gè)損失項(xiàng)的加權(quán)和。權(quán)重 w(t)用于決定稠度損失在總損失中所占的比重。

a. MixMatch
這種整體方法是由Berthelot 等[8]提出的。
為了理解這個(gè)方法,讓我們看一看每個(gè)步驟。
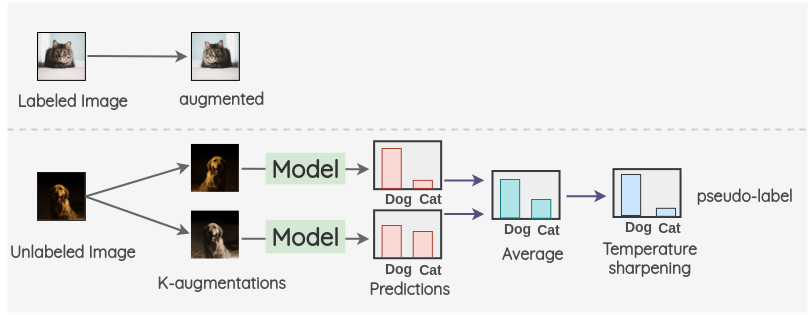
i. 對(duì)于標(biāo)記了的圖像,我們創(chuàng)建一個(gè)增強(qiáng)圖像。對(duì)于未標(biāo)記的圖像,我們創(chuàng)建 K 個(gè)增強(qiáng)圖像,并對(duì)所有的 K 個(gè)圖像進(jìn)行模型預(yù)測(cè)。然后,對(duì)預(yù)測(cè)進(jìn)行平均以及溫度縮放得到最終的偽標(biāo)簽。這個(gè)偽標(biāo)簽將用于所有 k 個(gè)增強(qiáng)。
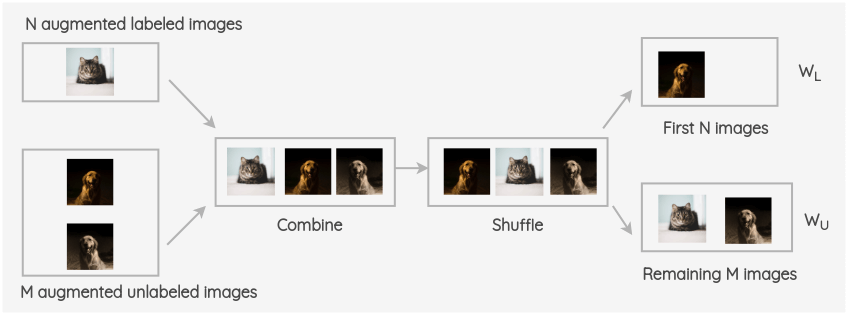
ii. 將增強(qiáng)的標(biāo)記了的圖像和未標(biāo)記圖像進(jìn)行合并,并對(duì)整組圖像進(jìn)行打亂。然后取該組的前 N 幅圖像為 W~L~,其余 M 幅圖像為 W~U~。
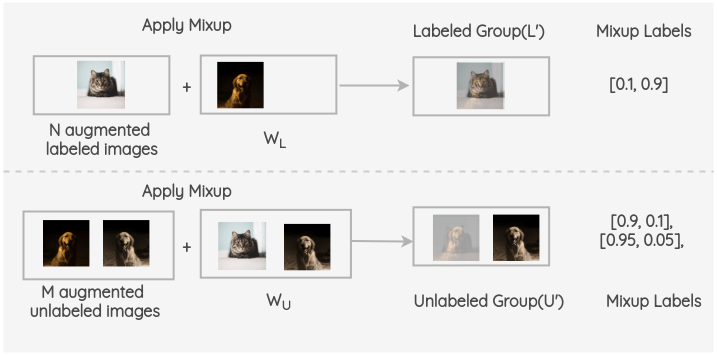
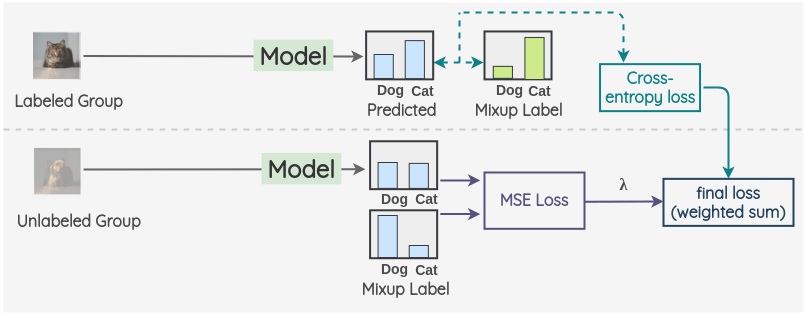
iii. 現(xiàn)在,在增強(qiáng)了的有標(biāo)簽的 batch 和 W~L~之間進(jìn)行 Mixup。同樣,對(duì) M 個(gè)增強(qiáng)過(guò)的未標(biāo)記組和 W~U~中的圖像和進(jìn)行 mixup。因此,我們得到了最終的有標(biāo)簽組和無(wú)標(biāo)簽組。
iv. 現(xiàn)在,對(duì)于有標(biāo)簽的組,我們使用 ground truth 混合標(biāo)簽進(jìn)行模型預(yù)測(cè)并計(jì)算交叉熵?fù)p失。同樣,對(duì)于沒(méi)有標(biāo)簽的組,我們計(jì)算模型預(yù)測(cè)和計(jì)算混合偽標(biāo)簽的均方誤差(MSE)損失。對(duì)這兩項(xiàng)取加權(quán)和,用 λ 加權(quán) MSE 損失。
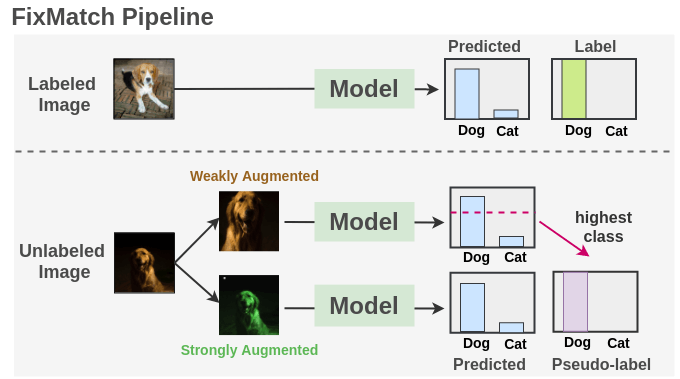
b. FixMatch
該方法由Sohn 等[9]提出,結(jié)合了偽標(biāo)簽和一致性正則化,極大地簡(jiǎn)化了整個(gè)方法。它在廣泛的基準(zhǔn)測(cè)試中得到了最先進(jìn)的結(jié)果。
如我們所見(jiàn),我們?cè)谟袠?biāo)簽圖像上使用交叉熵?fù)p失訓(xùn)練一個(gè)監(jiān)督模型。對(duì)于每一幅未標(biāo)記的圖像,分別采用弱增強(qiáng)和強(qiáng)增強(qiáng)方法得到兩幅圖像。弱增強(qiáng)的圖像被傳遞給我們的模型,我們得到預(yù)測(cè)。把置信度最大的類(lèi)的概率與閾值進(jìn)行比較。如果它高于閾值,那么我們將這個(gè)類(lèi)作為標(biāo)簽,即偽標(biāo)簽。然后,將強(qiáng)增強(qiáng)后的圖像通過(guò)模型進(jìn)行分類(lèi)預(yù)測(cè)。該預(yù)測(cè)方法與基于交叉熵?fù)p失的偽標(biāo)簽的方法進(jìn)行了比較。把兩種損失合并來(lái)優(yōu)化模型。
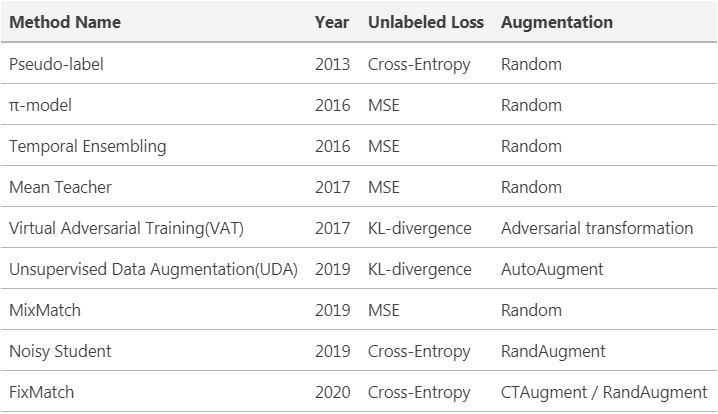
下面是對(duì)上述所有方法之間差異的一個(gè)高層次的總結(jié)。
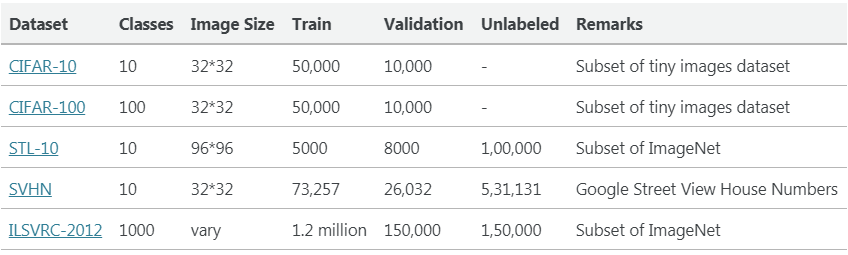
為了評(píng)估這些半監(jiān)督方法的性能,通常使用以下數(shù)據(jù)集。作者通過(guò)僅使用一小部分(例如:(40/250/4000/10000 個(gè)樣本),其余的作為未標(biāo)記的數(shù)據(jù)集。
我們得到了計(jì)算機(jī)視覺(jué)半監(jiān)督方法這些年是如何發(fā)展的概述。這是一個(gè)非常重要的研究方向,可以對(duì)該行業(yè)產(chǎn)生直接影響。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~