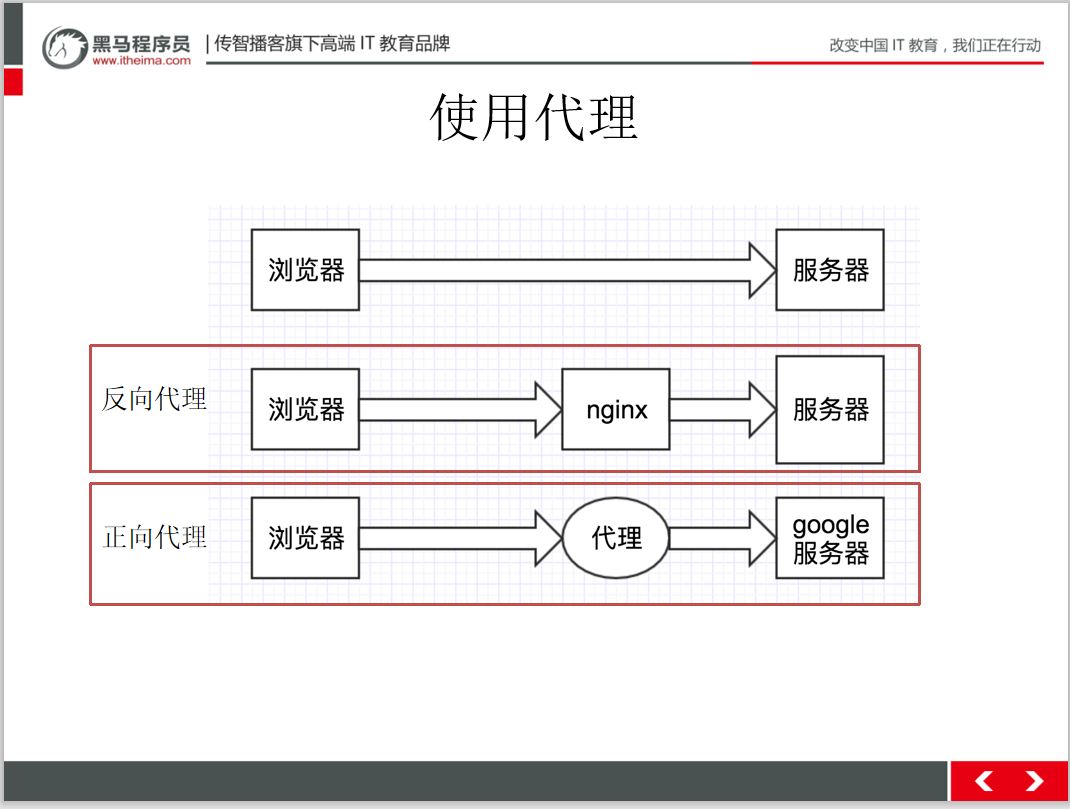
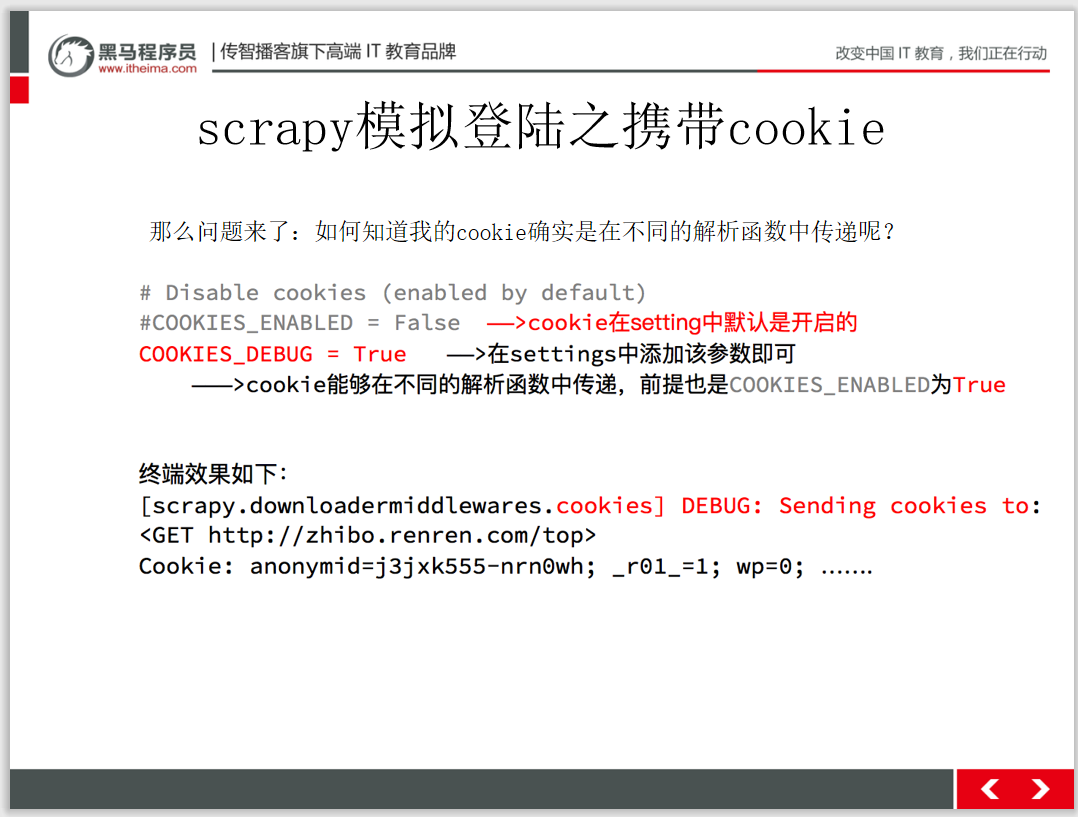
當(dāng)我們在用 requests 抓取頁面的時候,得到的結(jié)果可能會和在瀏覽器中看到的不一樣:在瀏覽器中正常顯示的頁面數(shù)據(jù),使用 requests 卻沒有得到結(jié)果。
這是為什么呢?因為 requests 獲取的都是原始 HTML 文檔,而瀏覽器中的頁面則是經(jīng)過 JavaScript 數(shù)據(jù)處理后生成的結(jié)果。這些數(shù)據(jù)的來源有多種,可能是通過 Ajax 加載的,可能是包含在 HTML 文檔中的,也可能是經(jīng)過 JavaScript 和特定算法計算后生成的。
對于第 1 種情況,數(shù)據(jù)加載是一種異步加載方式,原始頁面不會包含某些數(shù)據(jù),只有在加載完后,才會向服務(wù)器請求某個接口獲取數(shù)據(jù),然后數(shù)據(jù)才被處理從而呈現(xiàn)到網(wǎng)頁上,這個過程實際上就是向服務(wù)器接口發(fā)送了一個 Ajax 請求。
按照 Web 的發(fā)展趨勢來看,這種形式的頁面將會越來越多。網(wǎng)頁的原始 HTML 文檔不會包含任何數(shù)據(jù),數(shù)據(jù)都是通過 Ajax 統(tǒng)一加載后再呈現(xiàn)出來的,這樣在 Web 開發(fā)上可以做到前后端分離,并且降低服務(wù)器直接渲染頁面帶來的壓力。
所以如果你遇到這樣的頁面,直接利用 requests 等庫來抓取原始頁面,是無法獲取有效數(shù)據(jù)的。這時我們需要分析網(wǎng)頁后臺向接口發(fā)送的 Ajax 請求,如果可以用 requests 來模擬 Ajax 請求,就可以成功抓取了。
Ajax,全稱為Asynchronous JavaScript and XML,即異步的 JavaScript 和 XML。它不是一門編程語言,而是利用 JavaScript 在保證頁面不被刷新、頁面鏈接不改變的情況下與服務(wù)器交換數(shù)據(jù)并更新部分網(wǎng)頁的技術(shù)。
傳統(tǒng)的網(wǎng)頁,如果你想更新其內(nèi)容,那么必須要刷新整個頁面。有了 Ajax,便可以在頁面不被全部刷新的情況下更新其內(nèi)容。在這個過程中,頁面實際上在后臺與服務(wù)器進行了數(shù)據(jù)交互,獲取到數(shù)據(jù)之后,再利用 JavaScript 改變網(wǎng)頁,這樣網(wǎng)頁內(nèi)容就會更新了。
瀏覽網(wǎng)頁的時候,我們會發(fā)現(xiàn)很多網(wǎng)頁都有下滑查看更多的選項。
我們切換到微博頁面,發(fā)現(xiàn)下滑幾個微博后,后面的內(nèi)容不會直接顯示,而是會出現(xiàn)一個加載動畫,加載完成后下方才會繼續(xù)出現(xiàn)新的微博內(nèi)容,這個過程其實就是 Ajax 加載的過程,如圖所示:
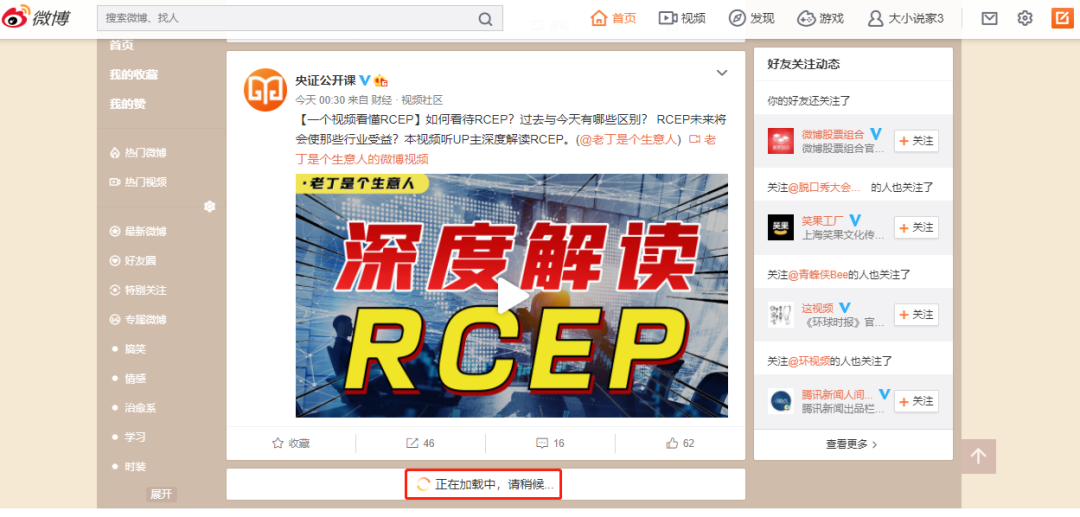
我們注意到頁面其實并沒有整個刷新,這意味著頁面的鏈接沒有變化,但是網(wǎng)頁中卻多了新內(nèi)容,也就是后面刷出來的新微博。這就是通過 Ajax 獲取新數(shù)據(jù)并呈現(xiàn)的過程。
初步了解了 Ajax 之后,我們再來詳細了解它的基本原理。發(fā)送 Ajax 請求到網(wǎng)頁更新的過程可以簡單分為以下 3 步:
發(fā)送請求
解析內(nèi)容
渲染網(wǎng)頁
我們知道 JavaScript 可以實現(xiàn)頁面的各種交互功能,Ajax 也不例外,它是由 JavaScript 實現(xiàn)的,實際上執(zhí)行了如下代碼:
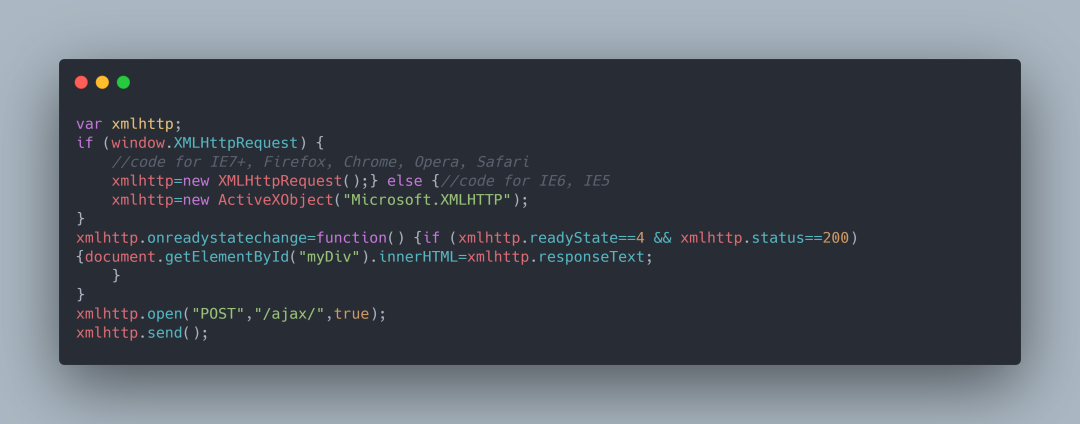
這是 JavaScript 對 Ajax 最底層的實現(xiàn),這個過程實際上是新建了 XMLHttpRequest 對象,然后調(diào)用 onreadystatechange 屬性設(shè)置監(jiān)聽,最后調(diào)用 open() 和 send() 方法向某個鏈接(也就是服務(wù)器)發(fā)送請求。
前面我們用 Python 實現(xiàn)請求發(fā)送之后,可以得到響應(yīng)結(jié)果,但這里請求的發(fā)送由 JavaScript 來完成。由于設(shè)置了監(jiān)聽,所以當(dāng)服務(wù)器返回響應(yīng)時,onreadystatechange 對應(yīng)的方法便會被觸發(fā),我們在這個方法里面解析響應(yīng)內(nèi)容即可。
得到響應(yīng)之后,onreadystatechange 屬性對應(yīng)的方法會被觸發(fā),此時利用 xmlhttp 的 responseText 屬性便可取到響應(yīng)內(nèi)容。這類似于 Python 中利用 requests 向服務(wù)器發(fā)起請求,然后得到響應(yīng)的過程。
返回的內(nèi)容可能是 HTML,也可能是 JSON,接下來我們只需要在方法中用 JavaScript 進一步處理即可。比如,如果返回的內(nèi)容是 JSON 的話,我們便可以對它進行解析和轉(zhuǎn)化。
JavaScript 有改變網(wǎng)頁內(nèi)容的能力,解析完響應(yīng)內(nèi)容之后,就可以調(diào)用 JavaScript 針對解析完的內(nèi)容對網(wǎng)頁進行下一步處理。比如,通過
document.getElementById().innerHTML
這樣的操作,對某個元素內(nèi)的源代碼進行更改,這樣網(wǎng)頁顯示的內(nèi)容就改變了,這種對 Document 網(wǎng)頁文檔進行如更改、刪除等操作也被稱作 DOM 操作。
document.getElementById("myDiv").innerHTML=xmlhttp.responseText
這個操作便將 ID 為 myDiv 的節(jié)點內(nèi)部的 HTML 代碼更改為服務(wù)器返回的內(nèi)容,這樣 myDiv 元素內(nèi)部便會呈現(xiàn)出服務(wù)器返回的新數(shù)據(jù),網(wǎng)頁的部分內(nèi)容看上去就更新了。
可以看到,發(fā)送請求、解析內(nèi)容和渲染網(wǎng)頁這 3 個步驟其實都是由 JavaScript 完成的。
我們再回想微博的下拉刷新,這其實是 JavaScript 向服務(wù)器發(fā)送了一個 Ajax 請求,然后獲取新的微博數(shù)據(jù),將其解析,并將其渲染在網(wǎng)頁中的過程。
因此,真實的數(shù)據(jù)其實都是通過一次次 Ajax 請求得到的,如果想要抓取這些數(shù)據(jù),我們需要知道這些請求到底是怎么發(fā)送的,發(fā)往哪里,發(fā)了哪些參數(shù)。如果我們知道了這些,不就可以用 Python 模擬這個發(fā)送操作,獲取到其中的結(jié)果了嗎?
哦對了,給剛學(xué)習(xí)python爬蟲的小伙伴準備了2021最新爬蟲資料,來看一下。從最簡答的html語法到進階的scrap爬蟲框架全都有,全給你!