
Hudi 原理 | 一文徹底弄懂 Apache Hudi 不同表類型

1. 摘要
Apache Hudi提供了不同的表類型供根據(jù)不同的需求進(jìn)行選擇,提供了兩種類型的表
?Copy On Write(COW)?Merge On Read(MOR)
2. 術(shù)語介紹
在深入研究 COW 和 MOR 之前,讓我們先了解一下 Hudi 中使用的一些術(shù)語,以便更好地理解以下部分。
2.1 數(shù)據(jù)文件/基礎(chǔ)文件
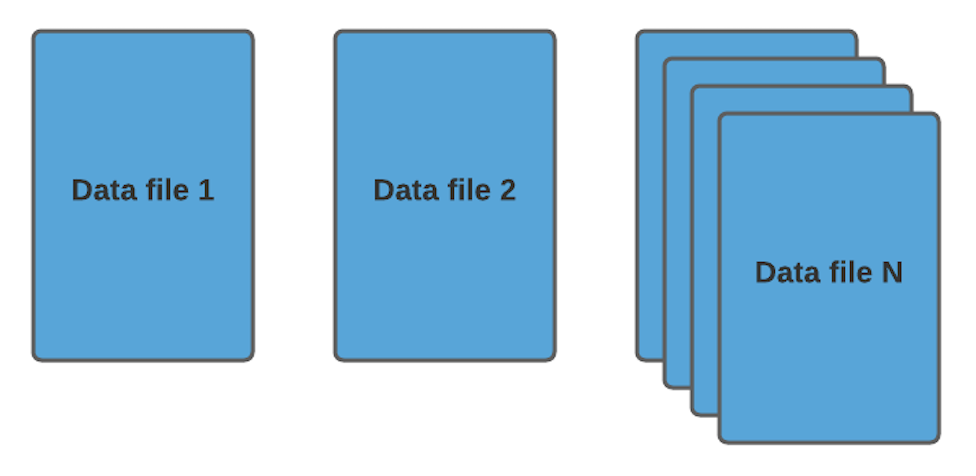
Hudi將數(shù)據(jù)以列存格式(Parquet/ORC)存放,稱為數(shù)據(jù)文件/基礎(chǔ)文件,該列出格式是非常高效的并在整個行業(yè)中廣泛使用,數(shù)據(jù)文件和基本文件通常可以互換使用,但兩者的含義相同。
2.2 增量日志文件
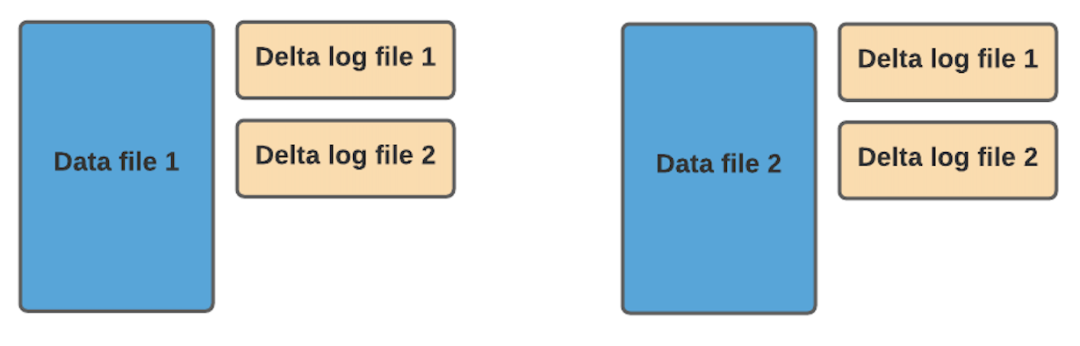
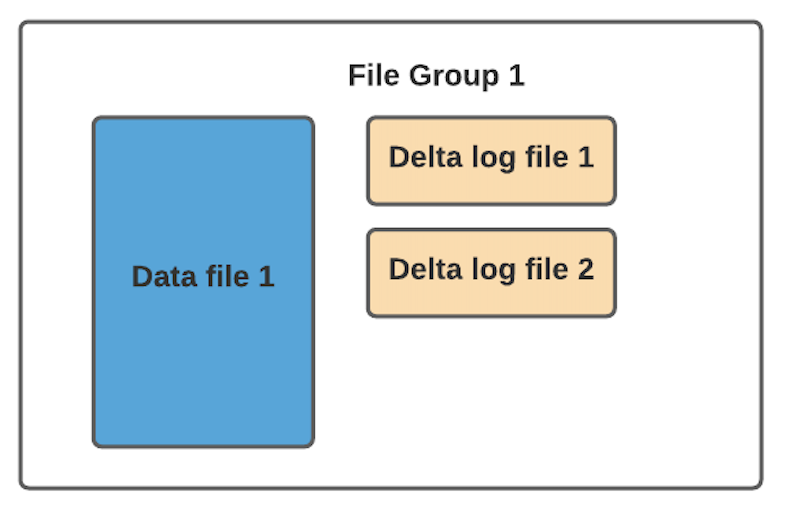
在 MOR 表格式中,更新被寫入到增量日志文件中,該文件以 avro 格式存儲。這些增量日志文件始終與基本文件相關(guān)聯(lián)。假設(shè)有一個名為 data_file_1 的數(shù)據(jù)文件,對 data_file_1 中記錄的任何更新都將寫入到新的增量日志文件。在服務(wù)讀取查詢時,Hudi 將實時合并基礎(chǔ)文件及其相應(yīng)的增量日志文件中的記錄。
2.3 文件組(FileGroup)
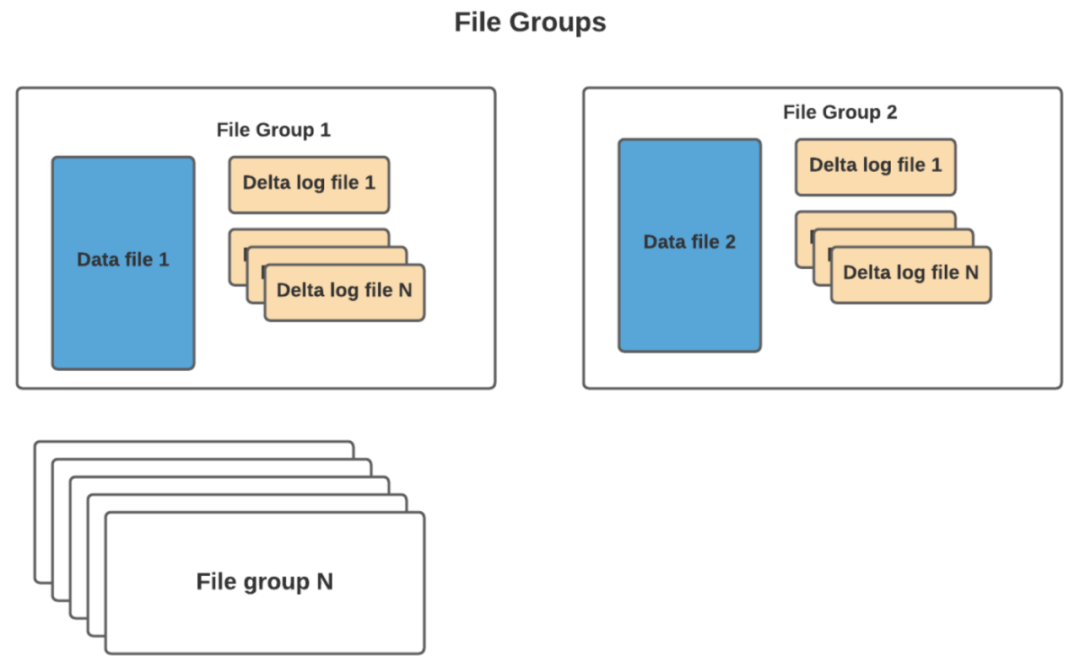
通常根據(jù)存儲的數(shù)據(jù)量,可能會有很多數(shù)據(jù)文件。每個數(shù)據(jù)文件及其對應(yīng)的增量日志文件形成一個文件組。在 COW 的情況下,它要簡單得多,因為只有基本文件。
2.4 文件版本
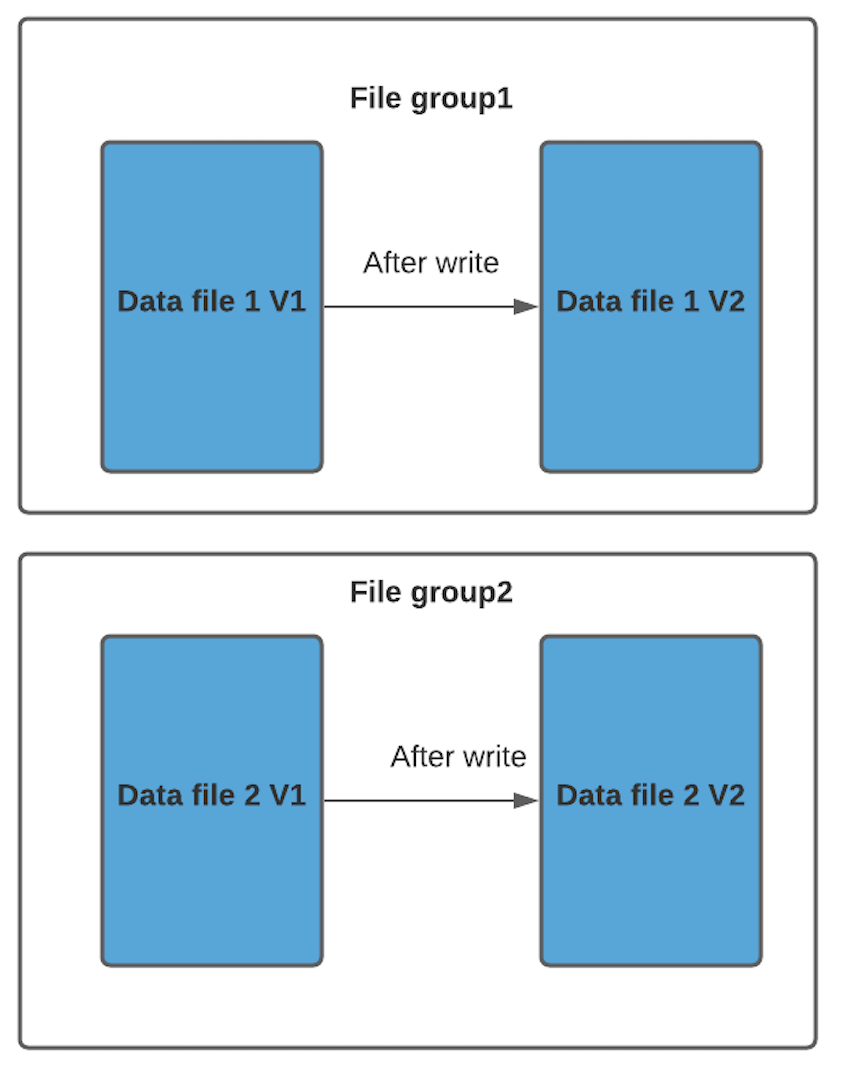
我們以 COW 格式表為例來解釋文件版本。每當(dāng)數(shù)據(jù)文件發(fā)生更新時,將創(chuàng)建數(shù)據(jù)文件的較新版本,其中包含來自較舊數(shù)據(jù)文件和較新傳入記錄的合并記錄。
2.5 文件切片(FileSlice)
對于每個文件組,可能有不同的文件版本。因此文件切片由特定版本的數(shù)據(jù)文件及其增量日志文件組成。對于 COW,最新的文件切片是指所有文件組的最新數(shù)據(jù)/基礎(chǔ)文件。對于 MOR,最新文件切片是指所有文件組的最新數(shù)據(jù)/基礎(chǔ)文件及其關(guān)聯(lián)的增量日志文件。
有了這些上下文,讓我們看看 COW 和 MOR 表類型。
3. COW表
顧名思義,對 Hudi 的每一個新批次寫入都將創(chuàng)建相應(yīng)數(shù)據(jù)文件的新版本,新版本文件包括舊版本文件的記錄以及來自傳入批次的記錄。接下來我們用一個示例進(jìn)行說明。
假設(shè)我們有 3 個文件組,其中包含如下數(shù)據(jù)文件。
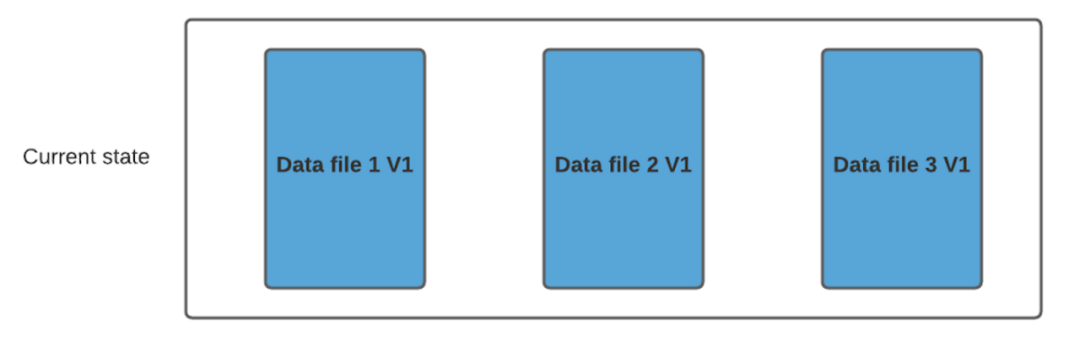
我們進(jìn)行一批新的寫入,在索引后,我們發(fā)現(xiàn)這些記錄與File group 1 和File group 2 匹配,然后有新的插入,我們將為其創(chuàng)建一個新的文件組(File group 4)。
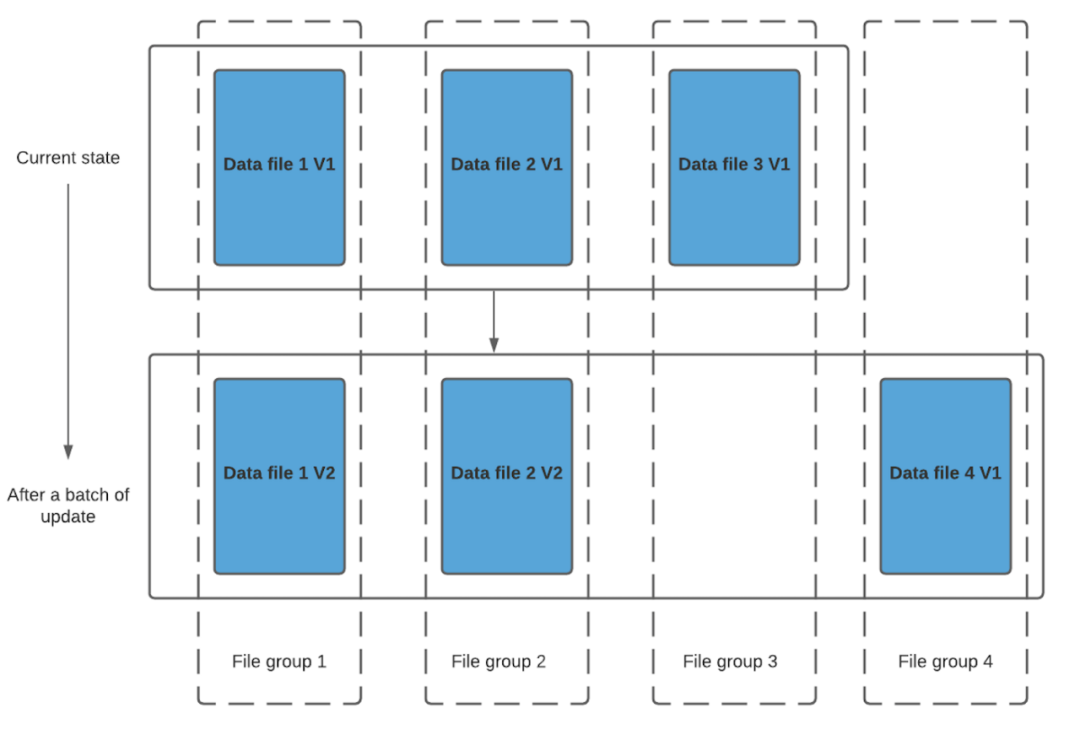
因此data_file1 和 data_file2 都將創(chuàng)建更新的版本,數(shù)據(jù)文件 1 V2 是數(shù)據(jù)文件 1 V1 的內(nèi)容與數(shù)據(jù)文件 1 中傳入批次匹配記錄的記錄合并。
由于在寫入期間進(jìn)行合并,COW 會產(chǎn)生一些寫入延遲。但是COW 的優(yōu)勢在于它的簡單性,不需要其他表服務(wù)(如壓縮),也相對容易調(diào)試。
4. MOR表
顧名思義,合并成本從寫入端轉(zhuǎn)移到讀取端。因此在寫入期間我們不會合并或創(chuàng)建較新的數(shù)據(jù)文件版本。標(biāo)記/索引完成后,對于具有要更新記錄的現(xiàn)有數(shù)據(jù)文件,Hudi 創(chuàng)建增量日志文件并適當(dāng)命名它們,以便它們都屬于一個文件組。
讀取端將實時合并基本文件及其各自的增量日志文件。你可能會想到這種方式,每次的讀取延遲都比較高(因為查詢時進(jìn)行合并),所 以 Hudi 使用壓縮機制來將數(shù)據(jù)文件和日志文件合并在一起并創(chuàng)建更新版本的數(shù)據(jù)文件。
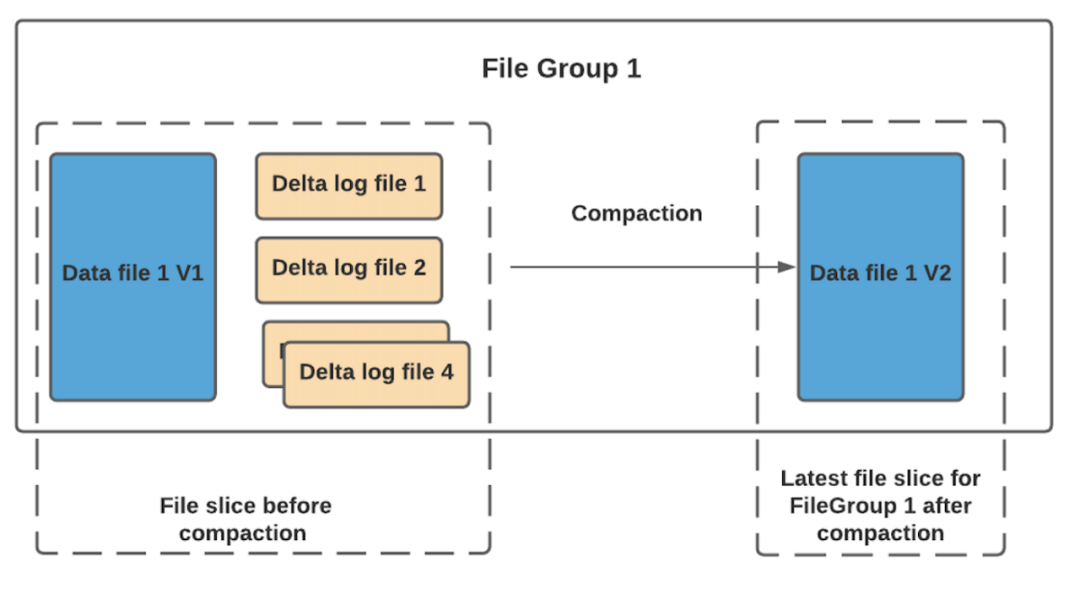
用戶可以選擇內(nèi)聯(lián)或異步模式運行壓縮。Hudi也提供了不同的壓縮策略供用戶選擇,最常用的一種是基于提交的數(shù)量。例如您可以將壓縮的最大增量日志配置為 4。這意味著在進(jìn)行 4 次增量寫入后,將對數(shù)據(jù)文件進(jìn)行壓縮并創(chuàng)建更新版本的數(shù)據(jù)文件。壓縮完成后,讀取端只需要讀取最新的數(shù)據(jù)文件,而不必關(guān)心舊版本文件。
讓我們根據(jù)某些重要標(biāo)準(zhǔn)比較 COW 與 MOR。
5. 對比
5.1 寫入延遲
正如我們之前所討論,由于寫入期間發(fā)生同步合并,與 MOR 相比COW 具有更高的寫入延遲。
5.2 讀取延遲
由于我們在 MOR 中進(jìn)行實時合并,因此與 COW 相比MOR 往往具有更高的讀取延遲。但是如果根據(jù)需求配置了合適的壓縮策略,MOR 可以很好地發(fā)揮作用。
5.3 更新代價
由于我們?yōu)槊颗鷮懭雱?chuàng)建更新的數(shù)據(jù)文件,因此 COW 的 I/O 成本將更高。由于更新進(jìn)入增量日志文件,MOR 的 I/O 成本非常低。
5.4 寫放大
同樣當(dāng)我們創(chuàng)建更新版本的數(shù)據(jù)文件時,COW 會更高。假設(shè)您有一個大小為 100Mb 的數(shù)據(jù)文件,并且每次更新 10% 的記錄進(jìn)行 4 批寫入,4 次寫入后,Hudi 將擁有 5 個大小為 100Mb 的 COW 數(shù)據(jù)文件。你可以配置你的清理器(將在后面的博客中討論)清理舊版本文件,但如果沒有進(jìn)行清理,最終會有 5 個版本的數(shù)據(jù)文件,總大小約500Mb。MOR 的情況并非如此,由于更新進(jìn)入日志文件,寫入放大保持在最低限度。對于上面的例子,假設(shè)壓縮還沒有開始,在 4 次寫入后,我們將有 1x100Mb 的文件和 4 個增量日志文件(10Mb) 的大小約140Mb。
6. 結(jié)論
盡管 MOR 似乎有一些缺點,但它提供了不同的查詢功能,例如讀優(yōu)化查詢(將在后面的博客中討論),這可能不會產(chǎn)生額外的合并成本。如果有一個具有適當(dāng)配置的異步壓縮作業(yè),那么就可以獲得 MOR 的所有好處,而無需在延遲上進(jìn)行大量權(quán)衡。