
Hudi 原理 | Apache Hudi 如何維護(hù)最佳文件大小
Apache Hudi 是一種數(shù)據(jù)湖平臺(tái)技術(shù),可提供構(gòu)建和管理數(shù)據(jù)湖所需的多種功能。Hudi 提供的一項(xiàng)重要功能是自動(dòng)管理文件大小,用戶不需要手動(dòng)維護(hù)。由于查詢引擎不得不多次打開(kāi)/讀取/關(guān)閉文件,以計(jì)劃和執(zhí)行查詢,因此擁有大量小文件將使其難以實(shí)現(xiàn)良好的查詢性能。但是對(duì)于流數(shù)據(jù)湖用例而言,固有的攝入量將最終具有較小的寫(xiě)入量,如果不進(jìn)行特殊處理,則可能導(dǎo)致大量小文件。
During Write vs After Write
解決小文件引起的系統(tǒng)可伸縮性問(wèn)題,常見(jiàn)的方法是寫(xiě)入非常小的文件然后將它們合并在一起,但可能會(huì)因?yàn)榘研∥募┞对诓樵冎卸`反查詢SLA。實(shí)際上,可以通過(guò)運(yùn)行Clustering 輕松地在 Hudi 表上執(zhí)行此操作。
此篇文章討論初始寫(xiě)入期間在 Hudi 中進(jìn)行文件大小優(yōu)化的情況,因此不必為了調(diào)整文件大小而再次重新寫(xiě)入所有數(shù)據(jù)。如果要同時(shí)具有(a)自我管理的文件大小和(b)避免將小文件暴露給查詢,自動(dòng)調(diào)整文件大小的功能將幫助你解決上述問(wèn)題。
執(zhí)行 Insert/Upsert 操作時(shí),Hudi 能夠保持配置的目標(biāo)文件大小。注意 bulk_insert 操作不提供此功能,類(lèi)似于 spark.write.parquet。
Configs
為了說(shuō)明問(wèn)題,只介紹 COPY_ON_WRITE 表。
在我們深入研究算法之前,先看看幾個(gè)配置。
max file size(hoodie.parquet.max.file.size):給定數(shù)據(jù)文件的最大大小,Hudi將努力把文件大小保持在這個(gè)配置值上。
soft file limit(hoodie.parquet.small.file.limit):最大文件大小,低于這個(gè)大小的數(shù)據(jù)文件被認(rèn)為是小文件。
insert split size(hoodie.copyonwrite.insert.split.size):?jiǎn)蝹€(gè)分區(qū)的插入分組數(shù)量。這個(gè)值應(yīng)該與單個(gè)文件中的記錄數(shù)相匹配(可以根據(jù)最大文件大小和每個(gè)記錄大小來(lái)確定)。
例如,如果你的第一個(gè)配置值是120MB,第二個(gè)配置值設(shè)置為100MB,那么任何大小<100MB的文件將被視為小文件。
如果你想關(guān)閉這個(gè)功能,把 Soft file limit 的配置值設(shè)為0。
Example
比方說(shuō),這是一個(gè)特定分區(qū)的數(shù)據(jù)文件分布
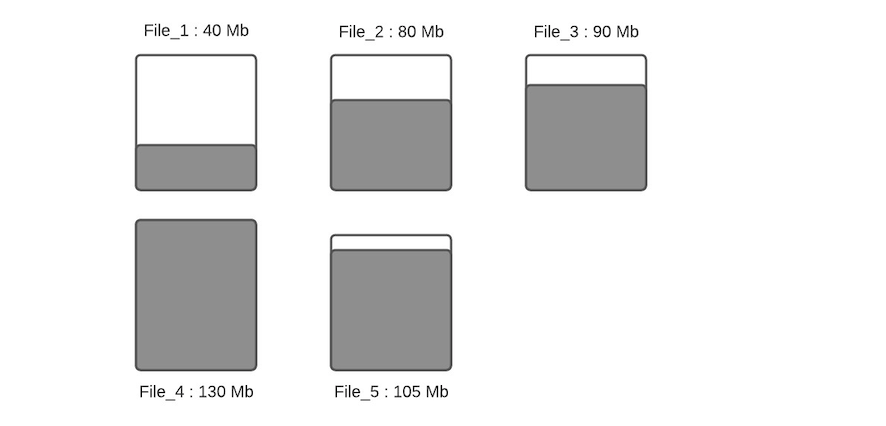
讓我們假設(shè)最大文件大小和小文件大小限制的配置值為120MB和100MB。File_1 的當(dāng)前大小為40MB,F(xiàn)ile_2 的大小為80MB,F(xiàn)ile_3 的大小為90MB,F(xiàn)ile_4 的大小為130MB,F(xiàn)ile_5 的大小為105MB。讓我們看看當(dāng)有新的寫(xiě)入發(fā)生時(shí),會(huì)發(fā)生什么。
Step 1:將更新分配給文件。在這一步,我們查找索引以找到標(biāo)記的位置,記錄被分配到各自的文件。請(qǐng)注意,我們假設(shè)更新只會(huì)增加文件的大小,這只會(huì)帶來(lái)一個(gè)更大的文件。當(dāng)更新降低了文件的大小(例如清空很多字段),那么隨后的寫(xiě)入將被視為一個(gè)小文件。
Step 2:確定每個(gè)分區(qū)路徑的小文件。這里將利用最大文件大小配置值來(lái)確定小文件。例子鑒于配置值被設(shè)置為100MB,小文件是 File_1(40MB)和 File_2(80MB)以及 File_3(90MB)。
Step 3:一旦確定了小文件,就給它們分配插入內(nèi)容,使它們達(dá)到最大容量120MB。File_1 將攝取80MB的數(shù)據(jù),F(xiàn)ile_2 將攝取40MB的數(shù)據(jù),F(xiàn)ile_3 將攝取30MB的數(shù)據(jù)。
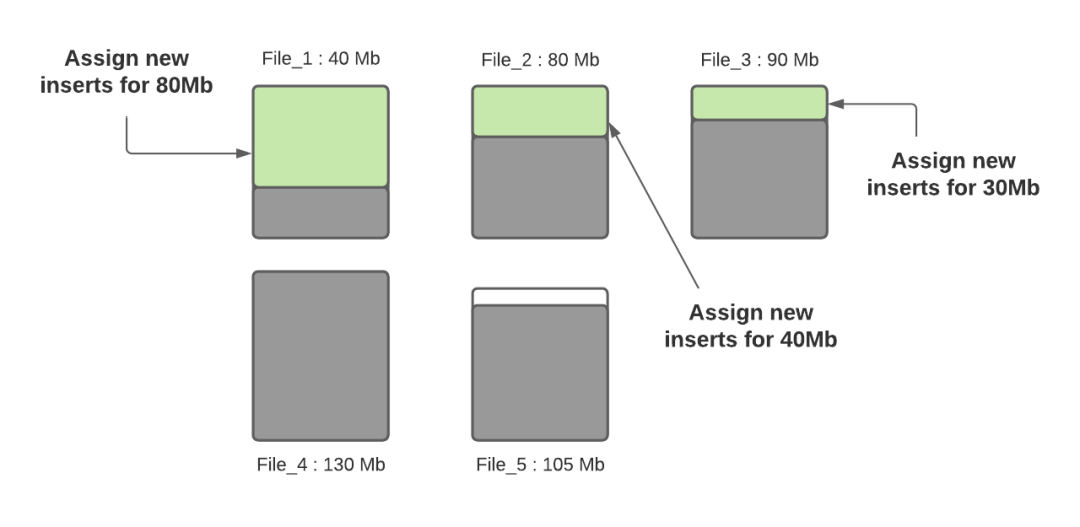
Step 4:一旦所有的小文件都達(dá)到最大容量,如果還有未分配的數(shù)據(jù),就會(huì)創(chuàng)建新的文件組/數(shù)據(jù)文件,并將插入文件分配給它們。每個(gè)新的數(shù)據(jù)文件的記錄數(shù)是由 insert split size 配置決定的。假設(shè) insert split size 配置為12萬(wàn)條記錄,如果有30萬(wàn)條剩余記錄,將創(chuàng)建3個(gè)新文件,其中2個(gè)文件(File_6 和 File_7)將被填入12萬(wàn)條記錄,最后一個(gè)文件(File_8)將被填入6萬(wàn)條記錄(假設(shè)每條記錄為1000字節(jié))。在未來(lái)的攝取中,第3個(gè)新文件將被認(rèn)為是一個(gè)小文件,將被裝入更多的數(shù)據(jù)
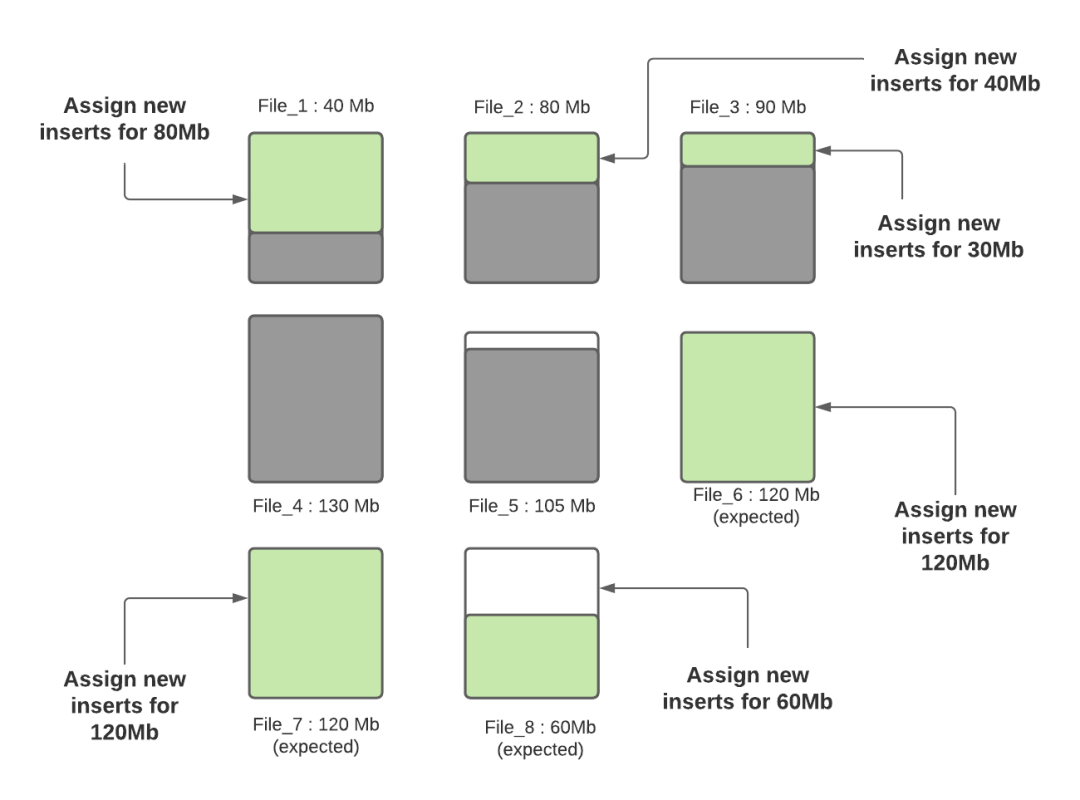
Hudi 利用諸如自定義分區(qū)之類(lèi)的機(jī)制來(lái)優(yōu)化記錄分配到不同文件的能力,從而執(zhí)行上述算法。在這一輪提取完成之后,除 File_8 以外的所有文件均已調(diào)整為最佳大小。每次提取期間都會(huì)遵循此過(guò)程,以確保 Hudi 表中沒(méi)有小文件。
英文地址:http://hudi.apache.org/blog/hudi-file-sizing/#configs