
Hudi 原理 | 一文徹底理解Apache Hudi的清理服務(wù)
Apache Hudi提供了MVCC并發(fā)模型,保證寫入端和讀取端之間快照級別隔離。在本篇博客中我們將介紹如何配置來管理多個文件版本,此外還將討論用戶可使用的清理機制,以了解如何維護(hù)所需數(shù)量的舊文件版本,以使長時間運行的讀取端不會失敗。
1. 回收空間以控制存儲成本
Hudi 提供不同的表管理服務(wù)來管理數(shù)據(jù)湖上表的數(shù)據(jù),其中一項服務(wù)稱為Cleaner(清理服務(wù))。隨著用戶向表中寫入更多數(shù)據(jù),對于每次更新,Hudi會生成一個新版本的數(shù)據(jù)文件用于保存更新后的記錄(COPY_ON_WRITE) 或?qū)⑦@些增量更新寫入日志文件以避免重寫更新版本的數(shù)據(jù)文件 (MERGE_ON_READ)。在這種情況下,根據(jù)更新頻率,文件版本數(shù)可能會無限增長,但如果不需要保留無限的歷史記錄,則必須有一個流程(服務(wù))來回收舊版本的數(shù)據(jù),這就是 Hudi 的清理服務(wù)。
2. 問題描述
在數(shù)據(jù)湖架構(gòu)中,讀取端和寫入端同時訪問同一張表是非常常見的場景。由于 Hudi 清理服務(wù)會定期回收較舊的文件版本,因此可能會出現(xiàn)長時間運行的查詢訪問到被清理服務(wù)回收的文件版本的情況,因此需要使用正確的配置來確保查詢不會失敗。
3. 深入了解 Hudi清理服務(wù)
針對上述場景,我們先了解一下 Hudi 提供的不同清理策略以及需要配置的相應(yīng)屬性,Hudi提供了異步或同步清理兩種方式。在詳細(xì)介紹之前我們先解釋一些基本概念:
?Hudi 基礎(chǔ)文件(HoodieBaseFile):由壓縮后的最終數(shù)據(jù)組成的列式文件,基本文件的名稱遵循以下命名約定:<fileId>_<writeToken>_<instantTime>.parquet。在此文件的后續(xù)寫入中文件 ID 保持不變,并且提交時間會更新以顯示最新版本。這也意味著記錄的任何特定版本,給定其分區(qū)路徑,都可以使用文件 ID 和 instantTime進(jìn)行唯一定位。?**文件切片(FileSlice)**:在 MERGE_ON_READ 表類型的情況下,文件切片由基本文件和由多個增量日志文件組成。?**Hudi 文件組(FileGroup)**:Hudi 中的任何文件組都由分區(qū)路徑和文件ID 唯一標(biāo)識,該組中的文件作為其名稱的一部分。文件組由特定分區(qū)路徑中的所有文件片組成。此外任何分區(qū)路徑都可以有多個文件組。
4. 清理服務(wù)
Hudi 清理服務(wù)目前支持以下清理策略:
?KEEP_LATEST_COMMITS:這是默認(rèn)策略。該清理策略可確保回溯前X次提交中發(fā)生的所有更改。假設(shè)每 30 分鐘將數(shù)據(jù)攝取到 Hudi 數(shù)據(jù)集,并且最長的運行查詢可能需要 5 小時才能完成,那么用戶應(yīng)該至少保留最后 10 次提交。通過這樣的配置,我們確保文件的最舊版本在磁盤上保留至少 5 小時,從而防止運行時間最長的查詢在任何時間點失敗,使用此策略也可以進(jìn)行增量清理。?KEEP_LATEST_FILE_VERSIONS:此策略具有保持 N 個文件版本而不受時間限制的效果。當(dāng)知道在任何給定時間想要保留多少個 MAX 版本的文件時,此策略很有用,為了實現(xiàn)與以前相同的防止長時間運行的查詢失敗的行為,應(yīng)該根據(jù)數(shù)據(jù)模式進(jìn)行計算,或者如果用戶只想維護(hù)文件的 1 個最新版本,此策略也很有用。
5. 例子
假設(shè)用戶每 30 分鐘將數(shù)據(jù)攝取到 COPY_ON_WRITE 類型的 Hudi 數(shù)據(jù)集,如下所示:
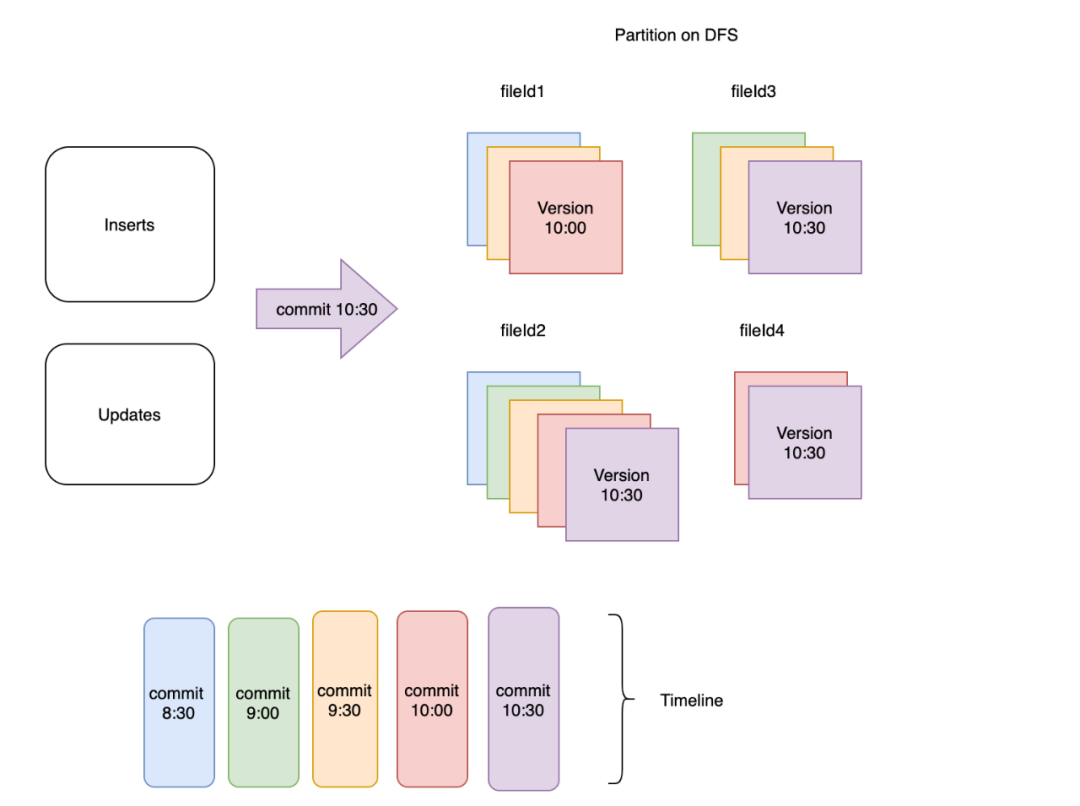
圖1:每30分鐘將傳入的記錄提取到hudi數(shù)據(jù)集中
該圖顯示了 DFS 上的一個特定分區(qū),其中提交和相應(yīng)的文件版本是彩色編碼的。在該分區(qū)中創(chuàng)建了 4 個不同的文件組,如 fileId1、fileId2、fileId3 和 fileId4 所示。fileId2 對應(yīng)的文件組包含所有 5 次提交的記錄,而 fileId4 對應(yīng)的組僅包含最近 2 次提交的記錄。
假設(shè)使用以下配置進(jìn)行清理:
hoodie.cleaner.policy=KEEP_LATEST_COMMITShoodie.cleaner.commits.retained=2
Cleaner 通過處理以下事項來選擇要清理的文件版本:
?不應(yīng)清理文件的最新版本。?確定最后 2 次(已配置)+ 1 次提交的提交時間。在圖 1 中,commit 10:30 和 commit 10:00 對應(yīng)于時間線中最新的 2 個提交。包含一個額外的提交,因為保留提交的時間窗口本質(zhì)上等于最長的查詢運行時間。因此如果最長的查詢需要 1 小時才能完成,并且每 30 分鐘發(fā)生一次攝取,則您需要保留自 2*30 = 60(1 小時)以來的最后 2 次提交。此時最長的查詢?nèi)匀豢梢允褂靡韵喾错樞蛟诘?3 次提交中寫入的文件。這意味著如果一個查詢在 commit 9:30 之后開始執(zhí)行,當(dāng)在 commit 10:30 之后觸發(fā)清理操作時,它仍然會運行,如圖 2 所示。?現(xiàn)在對于任何文件組,只有那些沒有保存點(另一個 Hudi 表服務(wù))且提交時間小于第 3 次提交(下圖中的“提交 9:30”)的文件切片被清理。
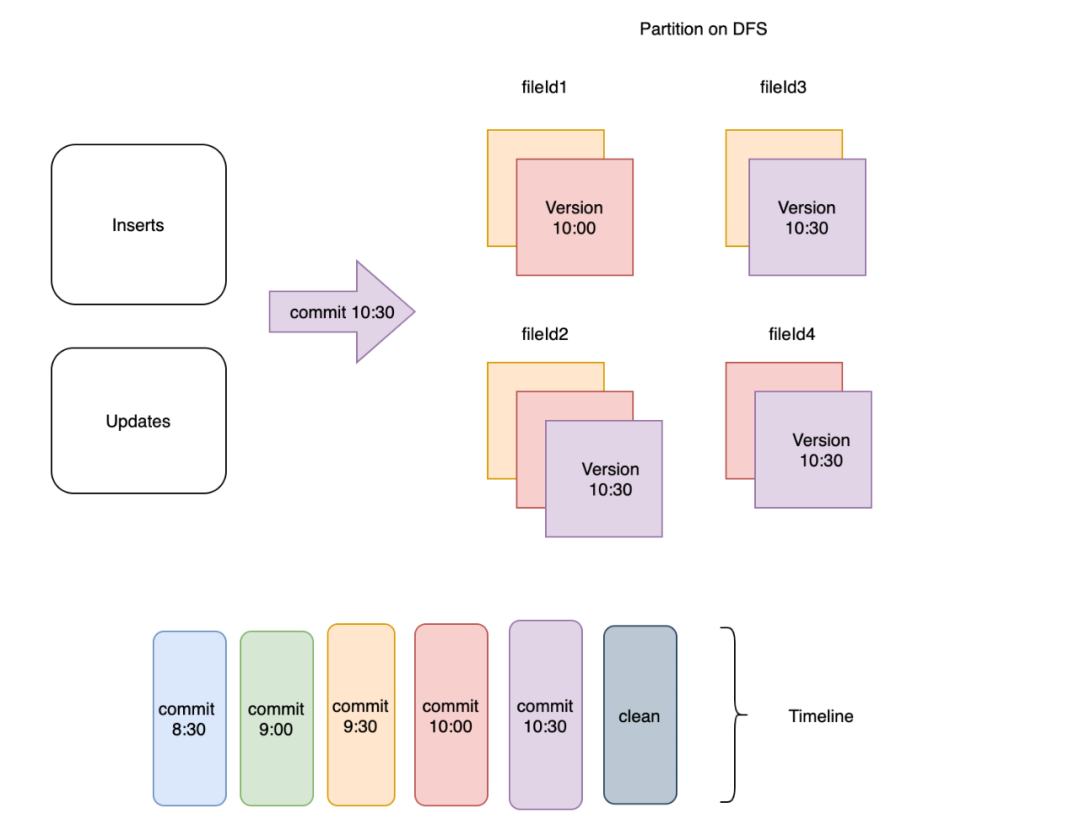
圖2:保留最近3次提交對應(yīng)的文件
假設(shè)使用以下配置進(jìn)行清理:
hoodie.cleaner.policy=KEEP_LATEST_FILE_VERSIONShoodie.cleaner.fileversions.retained=1
清理服務(wù)執(zhí)行以下操作:
?對于任何文件組,文件切片的最新版本(包括任何待壓縮的)被保留,其余的清理掉。如圖 3 所示,如果在 commit 10:30 之后立即觸發(fā)清理操作,清理服務(wù)將簡單地保留每個文件組中的最新版本并刪除其余的。
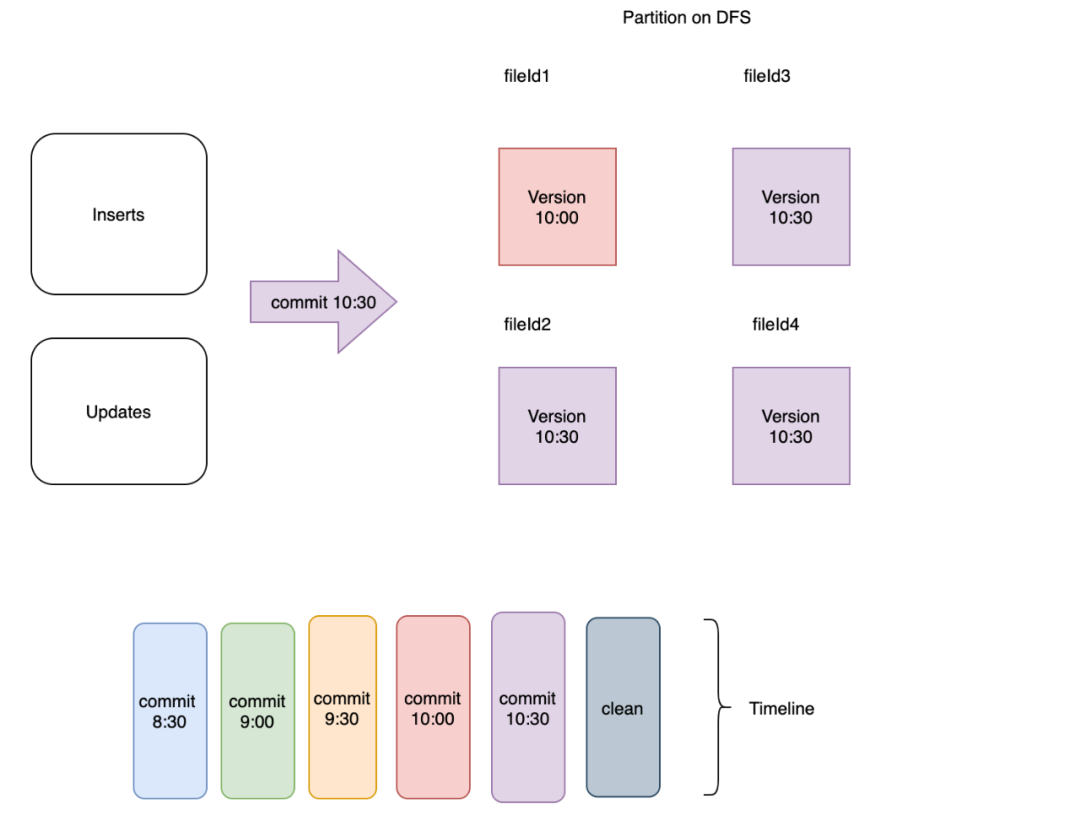
圖3:保留每個文件組中的最新文件版本
6. 配置
可以在 此處[1] 中找到有關(guān)所有可能配置的詳細(xì)信息以及默認(rèn)值。
7. 運行命令
Hudi 的清理表服務(wù)可以作為單獨的進(jìn)程運行,可以與數(shù)據(jù)攝取一起運行。正如前面提到的,它會清除了任何陳舊文件。如果您想將它與攝取數(shù)據(jù)一起運行,可以使用配置同步或異步運行[2]。或者可以使用以下命令獨立運行清理服務(wù):
[hoodie]$ spark-submit --class org.apache.hudi.utilities.HoodieCleaner \--props s3:///temp/hudi-ingestion-config/config.properties \--target-base-path s3:///temp/hudi \--spark-master yarn-cluster
如果您希望與寫入異步運行清理服務(wù),可以配置如下內(nèi)容:
hoodie.clean.automatic=truehoodie.clean.async=true
此外還可以使用 Hudi CLI[3] 來管理 Hudi 數(shù)據(jù)集。CLI 為清理服務(wù)提供了以下命令:
?cleans show?clean showpartitions?clean run
可以在 org.apache.hudi.cli.commands.CleansCommand 類[4] 中找到這些命令的更多詳細(xì)信息和相關(guān)代碼。
8. 未來計劃
目前正在進(jìn)行根據(jù)已流逝的時間間隔引入新的清理策略,即無論攝取發(fā)生的頻率如何,都可以保留想要的文件版本,可以在 此處[5] 跟蹤進(jìn)度。
我們希望這篇博客能讓您了解如何配置 Hudi 清理服務(wù)和支持的清理策略。請訪問博客部分[6] 以更深入地了解各種 Hudi 概念。
引用鏈接
[1] 此處: https://hudi.apache.org/docs/configurations.html#compaction-configs[2] 同步或異步運行: https://hudi.apache.org/docs/configurations.html#withAsyncClean[3] Hudi CLI: https://hudi.apache.org/docs/deployment.html#cli[4] org.apache.hudi.cli.commands.CleansCommand 類: https://github.com/apache/hudi/blob/master/hudi-cli/[5] 此處: https://issues.apache.org/jira/browse/HUDI-349[6] 博客部分: https://hudi.apache.org/blog.html
推薦閱讀
對話Apache Hudi VP,洞悉數(shù)據(jù)湖的過去現(xiàn)在和未來
基于 Apache Hudi 構(gòu)建實時數(shù)據(jù)湖在百信銀行的實踐
恭喜!Apache Hudi社區(qū)新晉頂級互聯(lián)網(wǎng)公司的PMC和Committer
基于Apache Hudi 湖倉一體的大數(shù)據(jù)生態(tài)體系