
【Attention九層塔】注意力機制的九重理解

極市導(dǎo)讀
Attention現(xiàn)在已經(jīng)火爆了整個AI領(lǐng)域,不管是機器視覺還是自然語言處理,都離不開Attention、transformer或者BERT。本文作者效仿EM九層塔,提出Attention九層塔。 >>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
Attention現(xiàn)在已經(jīng)火爆了整個AI領(lǐng)域,不管是機器視覺還是自然語言處理,都離不開Attention、transformer或者BERT。下面我效仿EM九層塔,提出Attention九層塔。希望能與大家交流。有更好的想法也歡迎在評論區(qū)提出一起討論。
Attention九層塔——理解Attention的九層境界目錄如下:
看山是山——Attention是一種注意力機制 看山看石——數(shù)學(xué)上看,Attention是一種廣泛應(yīng)用的加權(quán)平均 看山看峰——自然語言處理中,Attention is all you need 看山看水——BERT系列大規(guī)模無監(jiān)督學(xué)習(xí)將Attention推到了新的高度 水轉(zhuǎn)山回——計算機視覺中,Attention是有效的非局域信息融合技術(shù) 山高水深——計算機視覺中,Attention will be all you need 山水輪回——結(jié)構(gòu)化數(shù)據(jù)中,Attention是輔助GNN的利器 山中有山——邏輯可解釋性與Attention的關(guān)系 山水合一——Attention的多種變種及他們的內(nèi)在關(guān)聯(lián)
1. Attention是一種注意力機制
顧名思義,attention的本意是生物的注意力機制在人工智能中的應(yīng)用。注意力機制有什么好處呢?簡單地說,可以關(guān)注到完成目標場景中所需要的特征。比如說有一系列的特征 。可能目標場景僅僅需要 ,那么attention可以有效地“注意到”這兩個特征,而忽略其他的特征。attention最早出現(xiàn)在了遞歸神經(jīng)網(wǎng)絡(luò)(RNN)中[1],作者Sukhbaatar舉了這樣的例子:

上圖中,如果我們需要結(jié)合(1)到(4)這四句話,根據(jù)問題Q回答出正確答案A。可以看到,Q與(3)沒有直接的關(guān)聯(lián),但是我們需要從(3)中得到正確答案bedroom。一個比較自然地想法是,我們引導(dǎo)模型的注意力,從問題開始,從四句話中尋找線索,從而回答問題。

如上圖所示,通過問題中的apple,我們轉(zhuǎn)到了第四句話,然后注意力轉(zhuǎn)移到第三句話,確定回答中的bedroom。
到這里,我們應(yīng)該已經(jīng)抓住了attention最早的理解,達到了第一層——看山是山。
現(xiàn)在我們的問題是,如何設(shè)計這樣的模型,以達到這樣的效果?
最早的實現(xiàn)是基于顯式的存儲器,把每一步的結(jié)果都存下來,“人工實現(xiàn)”注意力的轉(zhuǎn)移。
還是上面的例子,

如上圖所示,通過對存儲器的處理,和對注意到的東西的更新,實現(xiàn)attention。這種方法比較簡單,但是很hand-crafted,后來已經(jīng)逐漸廢棄了,我們需要升級我們的認知,達到比較抽象層次。
2. Attention是一種加權(quán)平均
Attention的經(jīng)典定義,是來源于Attention is all you need這篇曠世奇作[2]。雖然前面一些工作也發(fā)現(xiàn)了類似的技術(shù)(如self-attention),但是這篇文章因為提出了“attention就是一切你想要的”這一大膽而逐漸被證實的論斷,而享有了載入史冊的至高榮耀。這一經(jīng)典定義,就是下面的公式。
公式含義下面講,先講講意義。這一公式,也基本上是近五年來,科研人員最早接觸到的經(jīng)典定義。這一公式在自然語言處理中的地位,即將接近牛頓定律在經(jīng)典力學(xué)中的地位,已經(jīng)成為了搭建復(fù)雜模型的基本公式。
這個公式看似復(fù)雜,但是理解了之后就會發(fā)現(xiàn)非常的簡單和基本。先講一下每個字母的含義。字面意思:Q表示query,表示的是K表示key,V表示value, 是K的維度。這時候就要有人問了,什么是query,什么是key,什么是value?因為這三個概念都是這篇文章引入的,所以說,這篇文章中的公式擺在Q的這個位置的東東就是query,擺在K這個位置的就叫key,擺在V這個位置的就是value。這就是最好的解讀。換句話說,這個公式類似于牛頓定律,本身是可以起到定義式的作用的。
為了便于大家理解,我在這里舉幾個例子解釋一下這三個概念。
1、 【搜索領(lǐng)域】在bilibili找視頻,key就是bilibili數(shù)據(jù)庫中的關(guān)鍵字序列(比如宅舞、鬼畜、馬保國等),query就是你輸入的關(guān)鍵字序列,比如馬保國、鬼畜,value就是你找到的視頻序列。
2、【推薦系統(tǒng)】在淘寶買東西,key就是淘寶數(shù)據(jù)庫中所有的商品信息,query就是你最近關(guān)注到的商品信息,比如高跟鞋、緊身褲,value就是推送給你的商品信息。
上面兩個例子比較的具體,我們往往在人工智能運用中,key,query,value都是隱變量特征。因此,他們的含義往往不那么顯然,我們需要把握的是這種計算結(jié)構(gòu)。
回到公式本身,這個公式本質(zhì)上就是表示按照關(guān)系矩陣進行加權(quán)平均。 關(guān)系矩陣就是 ,而softmax就是把關(guān)系矩陣歸一化到概率分布,然后按照這個概率分布對V進行重新采樣,最終得到新的attention的結(jié)果。
下圖展示了在NLP中的Attention的具體含義。我們現(xiàn)在考慮一個單詞it的特征,那么它的特征將根據(jù)別的單詞的特征加權(quán)得到,比如說可能the animal跟it的關(guān)系比較近(因為it指代the animal),所以它們的權(quán)值很高,這種權(quán)值將影響下一層it的特征。更多有趣的內(nèi)容請參看 The Annotated Transformer[3]和illustrate self-attention[4]。

看到這里,大概能明白attention的基礎(chǔ)模塊,就達到了第二層,看山看石。
3. 自然語言處理中,Attention is all you need。
Attention is all you need這篇文章的重要性不只是提出了attention這一概念,更重要的是提出了Transformer這一完全基于attention的結(jié)構(gòu)。完全基于attention意味著不用遞歸recurrent,也不用卷積convolution,而完全使用attention。下圖是attention與recurrent,convolution的計算量對比。

可以看到,attention比recurrent相比,需要的序列操作變成了O(1),盡管每層的復(fù)雜性變大了。這是一個典型的計算機內(nèi)犧牲空間換時間的想法,由于計算結(jié)構(gòu)的改進(如加約束、共享權(quán)重)和硬件的提升,這點空間并不算什么。
convolution也是典型的不需要序列操作的模型,但是其問題在于它是依賴于2D的結(jié)構(gòu)(所以天然適合圖像),同時它的計算量仍然是正比于輸入的邊長的對數(shù)的,也就是Ologk(n)。但是attention的好處是最理想情況下可以把計算量降低到O(1)。 也就是說,在這里我們其實已經(jīng)能夠看到,attention比convolution確實有更強的潛力。
Transformer的模型放在下面,基本就是attention模塊的簡單堆疊。由于已經(jīng)有很多文章講解其結(jié)構(gòu),本文在這里就不展開說明了。它在機器翻譯等領(lǐng)域上,吊打了其他的模型,展示了其強大的潛力。明白了Transformer,就已經(jīng)初步摸到了attention的強大,進入了看山看峰的境界。
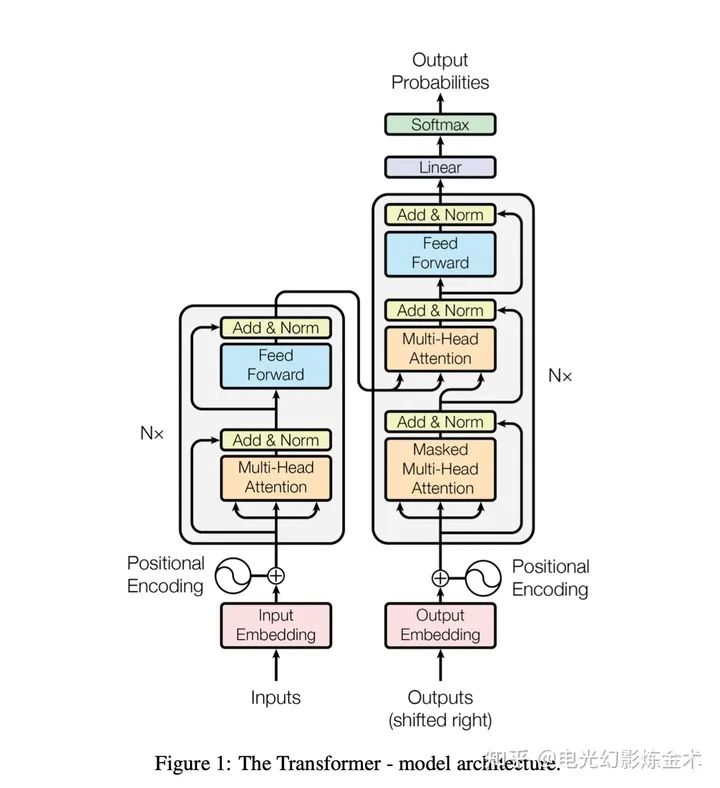
4. 看山看水——BERT系列大規(guī)模無監(jiān)督學(xué)習(xí)將Attention推到了新的高度。
BERT[5]的推出,將attention推到了一個全新的層次。BERT創(chuàng)造性地提出在大規(guī)模數(shù)據(jù)集上無監(jiān)督預(yù)訓(xùn)練加目標數(shù)據(jù)集微調(diào)(fine-tune)的方式,采用統(tǒng)一的模型解決大量的不同問題。BERT的效果非常好,在11個自然語言處理的任務(wù)上,都取得了非凡的提升。GLUE上提升了7.7%,MultiNLI提升了4.6%,SQuAD v2.0提升了5.1%。
BERT的做法其實非常簡單,本質(zhì)就是大規(guī)模預(yù)訓(xùn)練。利用大規(guī)模數(shù)據(jù)學(xué)習(xí)得到其中的語義信息,再把這種語義信息運用到小規(guī)模數(shù)據(jù)集上。BERT的貢獻主要是:1)提出了一種雙向預(yù)訓(xùn)練的方式。(2)證明了可以用一種統(tǒng)一的模型來解決不同的任務(wù),而不用為不同的任務(wù)設(shè)計不同的網(wǎng)絡(luò)。(3)在11個自然語言處理任務(wù)上取得了提升。
(2)和(3)不需要過多解釋。這里解釋一下(1)。之前的OpenAI GPT傳承了attention is all you need,采用的是單向的attention(下圖右),也就是說輸出內(nèi)容只能attention到之前的內(nèi)容,但是BERT(下圖左)采用的是雙向的attention。BERT這種簡單的設(shè)計,使得他大幅度超過了GPT。這也是AI屆一個典型的小設(shè)計導(dǎo)致大不同的例子。
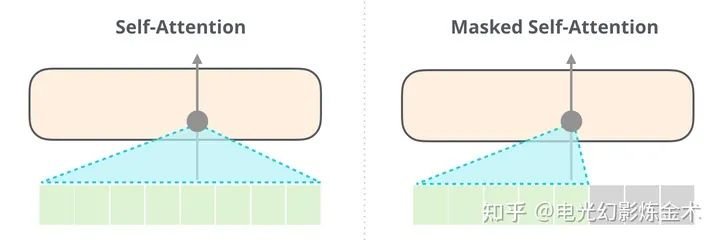
BERT和GPT的對比
BERT提出了幾個簡單的無監(jiān)督的預(yù)訓(xùn)練方式。第一個是Mask LM,就是擋住一句話的一部分,去預(yù)測另外一部分。第二個是Next Sentence Prediction (NSP) ,就是預(yù)測下一句話是什么。這種簡單的預(yù)訓(xùn)練使得BERT抓住了一些基本的語義信息和邏輯關(guān)系,幫助BERT在下流任務(wù)取得了非凡的成就。
理解了BERT是如何一統(tǒng)NLP江湖的,就進入了看山看水的新境界。
5. 水轉(zhuǎn)山回——計算機視覺中,Attention是有效的非局域信息融合技術(shù)。
Attention機制對于計算機視覺能不能起到幫助作用呢?回到我們最初的定義,attention本身是一個加權(quán),加權(quán)也就意味著可以融合不同的信息。CNN本身有一個缺陷,每次操作只能關(guān)注到卷積核附近的信息(local information),不能融合遠處的信息(non-local information)。而attention可以把遠處的信息也幫忙加權(quán)融合進來,起一個輔助作用。基于這個idea的網(wǎng)絡(luò),叫做non-local neural networks[6]。

比如圖中的球的信息,可能和人的信息有一個關(guān)聯(lián),這時候attention就要起作用了
這篇提出的non-local操作和attention非常像,假設(shè)有 和 兩個點的圖像特征,可以計算得到新的特征 為:
公式里的 為歸一化項,函數(shù)f和g可以靈活選擇(注意之前講的attention其實是f和g選了特例的結(jié)果)。在論文中,f取得是高斯關(guān)系函數(shù),g取得是線性函數(shù)。提出的non-local模塊被加到了CNN基線方法中,在多個數(shù)據(jù)集上取得了SOTA結(jié)果。
之后還有一些文獻提出了其他把CNN和attention結(jié)合的方法[7],都取得了提升效果。看到了這里,也對attention有了新的層次的理解。
6. 山高水深——計算機視覺中,Attention will be all you need。
在NLP中transformer已經(jīng)一統(tǒng)江湖,那么在計算機視覺中,transformer是否能夠一統(tǒng)江湖呢?這個想法本身是non-trivial的,因為語言是序列化的一維信息,而圖像天然是二維信息。CNN本身是天然適應(yīng)圖像這樣的二維信息的,但transformer適應(yīng)的是語言這種是一維信息。上一層已經(jīng)講了,有很多工作考慮把CNN和attention加以結(jié)合,那么能否設(shè)計純transformer的網(wǎng)絡(luò)做視覺的任務(wù)呢?
最近越來越多的文章表明,Transformer能夠很好地適應(yīng)圖像數(shù)據(jù),有望在視覺屆也取得統(tǒng)治地位。
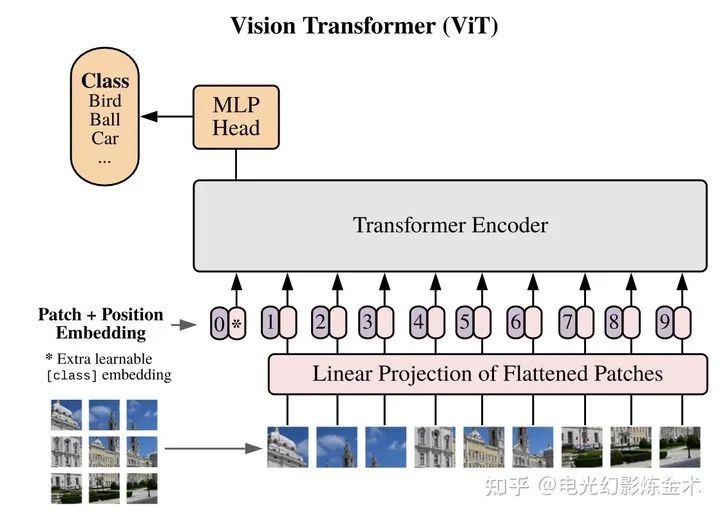
第一篇的應(yīng)用到的視覺Transformer來自Google,叫Vision Transformer[8]。這篇的名字也很有趣,an image is worth 16x16 words,即一幅圖值得16X16個單詞。這篇文章的核心想法,就是把一幅圖變成16x16的文字,然后再輸入Transformer進行編碼,之后再用簡單的小網(wǎng)絡(luò)進行下有任務(wù)的學(xué)習(xí),如下圖所示。
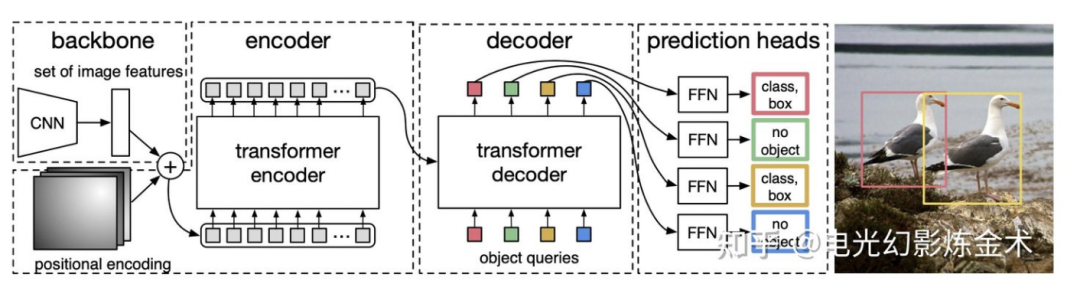
Vision transformer主要是把transformer用于圖像分類的任務(wù),那么能不能把transformer用于目標檢測呢?Facebook提出的模型DETR(detection transformer)給出了肯定的回答[9]。DETR的模型架構(gòu)也非常簡單,如下圖所示,輸入是一系列提取的圖片特征,經(jīng)過兩個transformer,輸出一系列object的特征,然后再通過前向網(wǎng)絡(luò)將物體特征回歸到bbox和cls。更詳細的介紹可以參看@陀飛輪的文章:https://zhuanlan.zhihu.com/p/266069794
在計算機視覺的其他領(lǐng)域,Transformer也在綻放新的活力。目前Transformer替代CNN已經(jīng)成為一個必然的趨勢,也就是說,Attention is all you need將在計算機視覺也成立。看到這里,你將會發(fā)現(xiàn)attention山高水深,非常玄妙。
7. 山水輪回——結(jié)構(gòu)化數(shù)據(jù)中,Attention是輔助GNN的利器。
前面幾層我們已經(jīng)看到,attention在一維數(shù)據(jù)(比如語言)和二位數(shù)據(jù)(比如圖像)都能有很好的應(yīng)用,那么對于高維數(shù)據(jù)(比如圖數(shù)據(jù)),能否有出色的表現(xiàn)呢?
最早地將attention用于圖結(jié)構(gòu)的經(jīng)典文章是Graph Attention Networks(GAT,哦對了這個不能叫做GAN)[10]。圖神經(jīng)網(wǎng)絡(luò)解決的基本問題是,給定圖的結(jié)構(gòu)和節(jié)點的特征,如何獲取一個圖的特征表示,來在下游任務(wù)(比如節(jié)點分類)中取得好的結(jié)果。那么爬到第七層的讀者們應(yīng)該可以想到,attention可以很好的用在這種關(guān)系建模上。
GAN的網(wǎng)絡(luò)結(jié)構(gòu)也并不復(fù)雜,即便數(shù)學(xué)公式有一點點多。直接看下面的圖。
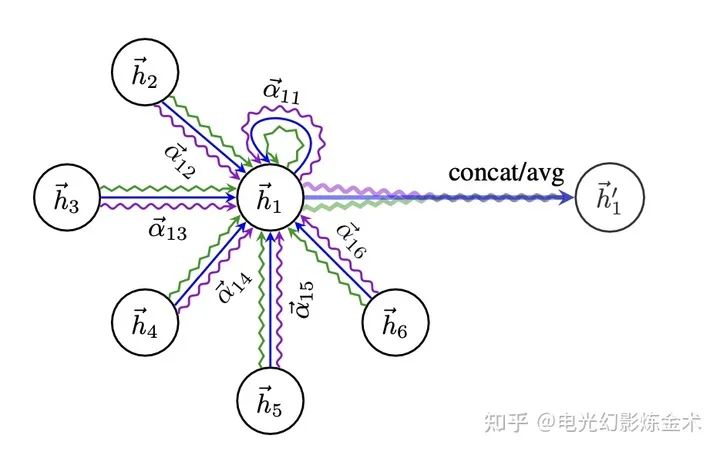
GAT的網(wǎng)絡(luò)結(jié)構(gòu)
每兩個節(jié)點之間先做一次attention獲取一組權(quán)重,比如圖中的 表示1和2之間的權(quán)重。然后再用這組權(quán)重做一個加權(quán)平均,再使用leakyRelu做一個激活。最后把多個head的做一個平均或者聯(lián)結(jié)即可。
看懂了原來GAT其實就是attention的一個不難的應(yīng)用,就進入了第七層,山水輪回。
8.山中有山——邏輯可解釋性與Attention的關(guān)系
盡管我們已經(jīng)發(fā)現(xiàn)attention非常有用,如何深入理解attention,是一個研究界未解決的問題。甚至進一步說,什么叫做深入理解,都是一個全新的問題。大家想想看,CNN是什么時候提出來的?LeNet也就是98年。CNN我們還沒理解的非常好,attention對于我們來說更新了。
我認為,attention是可以有比CNN更好的理解的。 為什么?簡單一句話,attention這種加權(quán)的分析,天然就具有可視化的屬性。而可視化是我們理解高維空間的利器。
給兩個例子,第一個例子是NLP中的BERT,分析論文顯示[11],學(xué)習(xí)到的特征有非常強的結(jié)構(gòu)性特征。
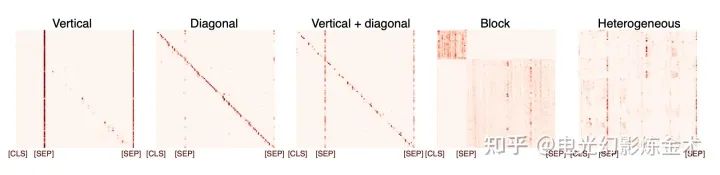
還有一個FACEBOOK最近的的工作DINO[12],下圖圖右是無監(jiān)督訓(xùn)練得到的attention map。是不是非常的震驚?

到目前為止,讀者已經(jīng)到了新的境界,山中有山。
9.山水合一——Attention的多種變種及他們的內(nèi)在關(guān)聯(lián)
就跟CNN可以搭建起非常厲害的檢測模型或者更高級的模型一樣,attention的最厲害的地方,是它可以作為基本模塊搭建起非常復(fù)雜的(用來灌水的)模型。
這里簡單列舉一些attention的變種[13]。首先是全局attention和部分attention。
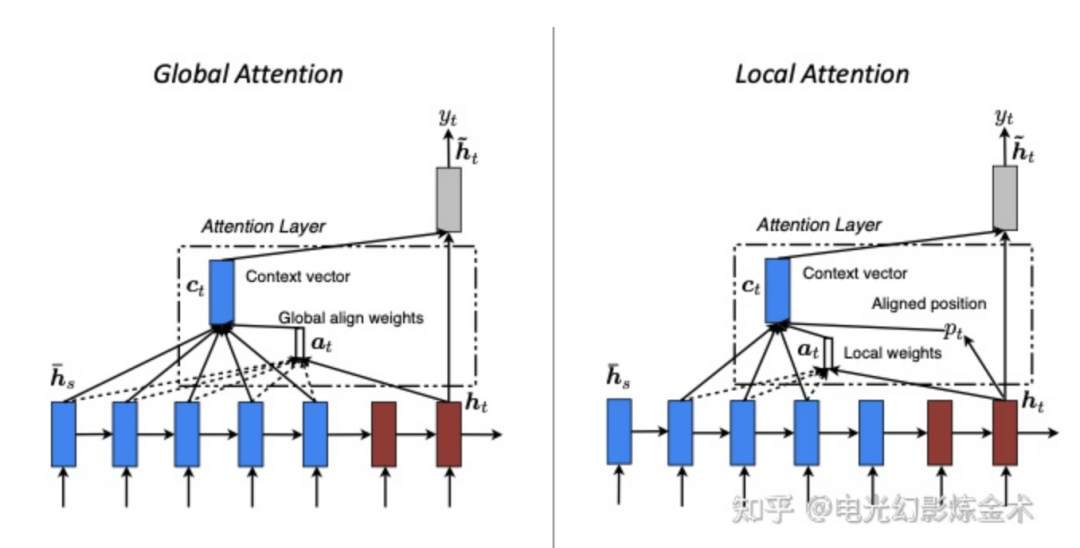
全局attention就是上面講的,部分attention主要是還允許某些特征在做attention之前先做融合,再進一步attention。最近爆火的swin transformer就可以看作是把這個變種發(fā)揚光大了。
視頻:靈魂畫手帶你一分鐘讀懂吊打CNN的swintransformer。
https://www.zhihu.com/zvideo/1359837715438149632
接下來是hard attention和soft attention。

之前我們講的基本都是soft attention。但是站到采樣的角度來講,我們可以考慮hard attention,把概率當成一個分布,然后再進行多項式采樣。這個或許在強化學(xué)習(xí)里面,有啟發(fā)性作用。
最近又有一堆覺得MLP也挺強的工作[14]。筆者認為,他們也是參考了attention的模式,采用了不同的結(jié)構(gòu)達到同一種效果。當然,說不定attention最后會落到被MLP吊打的下場。
但是attention的理念,永遠不會過時。attention作為最樸素也最強大的數(shù)據(jù)關(guān)系建模基本模塊,必將成為每個AI人的基本功。
還有不會過時的是對數(shù)據(jù)的理解和分析能力。上面介紹了大量的模型,但是真正我們能夠求解好某個特定的問題,還得來源于對問題結(jié)構(gòu)的充分認知。這個話題有機會我們再慢慢討論。
到這里已經(jīng)到了第九層山水合一的境界。萬象歸春,所有的模型都只是促進我們對數(shù)據(jù)的深入認知而已。
作者:知乎研究生板塊top1答主 @電光幻影煉金術(shù)
https://www.zhihu.com/people/zhao-ytc
參考:
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“RegNet”獲取資源鏈接~
頂會干貨:CVPR 二十年,影響力最大的 10 篇論文!| CVPR2021 最新18篇 Oral 論文|學(xué)術(shù)論文投稿與Rebuttal經(jīng)驗分享
實操教程:PyTorch自定義CUDA算子教程與運行時間分析|pytorch中使用detach并不能阻止參數(shù)更新
招聘面經(jīng):秋招計算機視覺匯總面經(jīng)分享|算法工程師面試題匯總
最新CV競賽:2021 高通人工智能應(yīng)用創(chuàng)新大賽|CVPR 2021 | Short-video Face Parsing Challenge

# CV技術(shù)社群邀請函 #
備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
