
注意力機(jī)制研究現(xiàn)狀綜述(Attention mechanism)
點(diǎn)擊上方“機(jī)器學(xué)習(xí)與生成對(duì)抗網(wǎng)絡(luò)”,關(guān)注星標(biāo)
獲取有趣、好玩的前沿干貨!
知乎作者:好好先生 侵刪
https://zhuanlan.zhihu.com/p/361893386
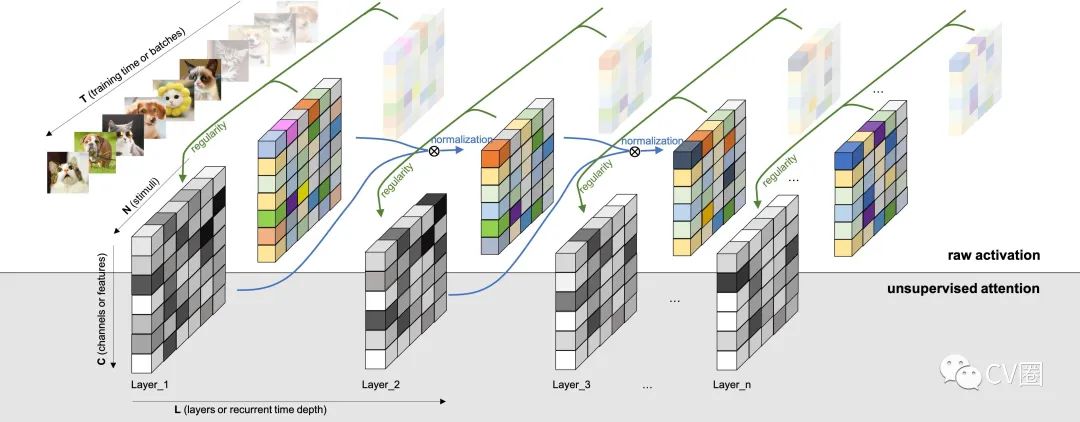

1 背景知識(shí)
2 注意力機(jī)制的原理與分類
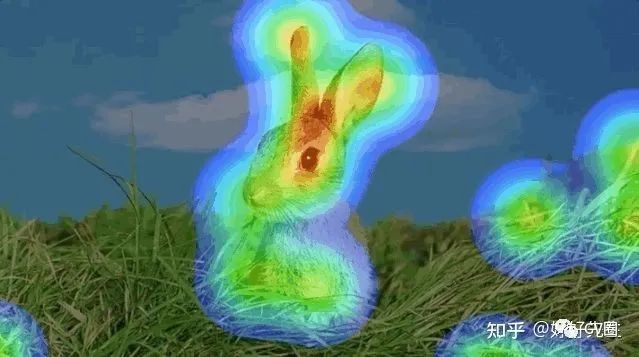
2.1 注意力機(jī)制原理
2.2 注意力機(jī)制分類
軟注意力機(jī)制。可分為基于輸入項(xiàng)的軟注意力(Item-wise Soft Attention)和基于位置的軟注意力(Location-wise Soft Attention)
強(qiáng)注意力機(jī)制。可分為基于輸入項(xiàng)的強(qiáng)注意力(Item-wise Hard Attention)和基于位置的強(qiáng)注意力(Location-wise Hard Attention)。
自注意力機(jī)制。是注意力機(jī)制的變體,其減少了對(duì)外部信息的依賴,更擅長(zhǎng)捕捉數(shù)據(jù)或特征的內(nèi)部相關(guān)性。自注意力機(jī)制在文本中的應(yīng)用,主要是通過(guò)計(jì)算單詞間的互相影響,來(lái)解決長(zhǎng)距離依賴問(wèn)題。
3 軟注意力機(jī)制(soft-attention)
3.1 具有視覺(jué)注意的神經(jīng)圖像字幕生成
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention Edit
主要思想:受機(jī)器翻譯和目標(biāo)檢測(cè)領(lǐng)域最新工作的啟發(fā),文章引入了一種基于注意力的模型,該模型可自動(dòng)學(xué)習(xí)以描述圖像的內(nèi)容。文章描述了如何使用標(biāo)準(zhǔn)反向傳播技術(shù)以確定性的方式并通過(guò)最大化變分下界隨機(jī)地訓(xùn)練該模型。 文章還通過(guò)可視化展示了模型如何能夠自動(dòng)學(xué)習(xí)將注視固定在顯著對(duì)象上,同時(shí)在輸出序列中生成相應(yīng)的單詞。文章通過(guò)三個(gè)基準(zhǔn)數(shù)據(jù)集的最新性能驗(yàn)證了注意力的使用:Flickr8k,F(xiàn)lickr30k和MS COCO。
論文地址:https://arxiv.org/pdf/1502.03044v3.pdf
代碼地址:https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning
3.2 使用視覺(jué)注意的動(dòng)作識(shí)別
Action Recognition using Visual Attention
主要思想:針對(duì)視頻中的動(dòng)作識(shí)別任務(wù),文章提出了一種基于軟注意力的模型。文章使用具有長(zhǎng)短期記憶(LSTM)單元的多層遞歸神經(jīng)網(wǎng)絡(luò)(RNN),它們?cè)诳臻g和時(shí)間上都很深。 文章的模型學(xué)會(huì)了選擇性地專注于視頻幀的各個(gè)部分,并在瞥了一眼之后對(duì)視頻進(jìn)行了分類。該模型從本質(zhì)上了解框架中的哪些部分與手頭任務(wù)相關(guān),并對(duì)其賦予更高的重要性。文章在UCF-11(YouTube動(dòng)作),HMDB-51和Hollywood2數(shù)據(jù)集上評(píng)估了該模型,并分析了該模型如何根據(jù)場(chǎng)景和所執(zhí)行的動(dòng)作來(lái)集中注意力。
論文地址:https://arxiv.org/pdf/1511.04119v3.pdf
代碼地址:https://github.com/kracwarlock/action-recognition-visual-attention
3.3 利用時(shí)間結(jié)構(gòu)描述視頻
Describing Videos by Exploiting Temporal Structure
主要思想:在使用遞歸神經(jīng)網(wǎng)絡(luò)(RNN)進(jìn)行圖像描述方面的最新進(jìn)展激發(fā)了對(duì)其在視頻描述中的應(yīng)用的探索。但是,盡管圖像是靜態(tài)的,但處理視頻需要對(duì)它們的動(dòng)態(tài)時(shí)間結(jié)構(gòu)進(jìn)行建模,然后將這些信息正確地集成到自然語(yǔ)言描述中。 在這種情況下,提出了一種成功考慮視頻的本地和全局時(shí)間結(jié)構(gòu)以產(chǎn)生描述的方法。首先,文章的方法結(jié)合了短時(shí)態(tài)動(dòng)力學(xué)的時(shí)空3-D卷積神經(jīng)網(wǎng)絡(luò)(3-D CNN)表示。對(duì)3-D CNN表示進(jìn)行視頻動(dòng)作識(shí)別任務(wù)方面的訓(xùn)練,以生成適合于人類動(dòng)作和行為的表示。其次,文章提出了一種時(shí)間注意機(jī)制,該機(jī)制可以超越本地時(shí)間建模,并學(xué)習(xí)在給定生成文本的RNN的情況下自動(dòng)選擇最相關(guān)的時(shí)間段。
論文地址:https://arxiv.org/pdf/1502.08029v5.pdf
代碼地址:https://github.com/yaoli/arctic-capgen-vid
3.4 用于改善超聲掃描平面檢測(cè)
Attention-Gated Networks for Improving Ultrasound Scan Plane Detection
主要思想:在這項(xiàng)工作中,將注意門控網(wǎng)絡(luò)應(yīng)用于實(shí)時(shí)自動(dòng)掃描平面檢測(cè)以進(jìn)行胎兒超聲篩查。胎兒超聲中的掃描平面檢測(cè)是一個(gè)具有挑戰(zhàn)性的問(wèn)題,因?yàn)閳D像質(zhì)量差,導(dǎo)致臨床醫(yī)生和自動(dòng)算法的解釋性差。 為了解決這個(gè)問(wèn)題,文章建議結(jié)合自門控軟注意力機(jī)制。軟注意力機(jī)制會(huì)生成一個(gè)端到端可訓(xùn)練的門控信號(hào),從而使網(wǎng)絡(luò)能夠?qū)?duì)預(yù)測(cè)有用的本地信息關(guān)聯(lián)起來(lái)。所提出的注意力機(jī)制是通用的,可以輕松地合并到任何現(xiàn)有的分類體系結(jié)構(gòu)中,而只需要幾個(gè)附加參數(shù)。文章表明,當(dāng)基礎(chǔ)網(wǎng)絡(luò)具有高容量時(shí),合并的注意力機(jī)制可以在提高整體性能的同時(shí)提供有效的對(duì)象定位。當(dāng)基本網(wǎng)絡(luò)的容量較低時(shí),該方法將大大優(yōu)于基準(zhǔn)方法,并大大減少了誤報(bào)率。
論文地址:https://arxiv.org/pdf/1804.05338v1.pdf
代碼地址:https://github.com/ozan-oktay/Attention-Gated-Networks
3.5 使用軟注意力機(jī)制的自適應(yīng)物理信息神經(jīng)網(wǎng)絡(luò)
主要思想:提出了一種從根本上新的方法來(lái)自適應(yīng)地訓(xùn)練PINN,其中的適應(yīng)權(quán)重是完全可訓(xùn)練的,因此神經(jīng)網(wǎng)絡(luò)可以自己了解解決方案的哪些區(qū)域是困難的并被迫專注于解決方案的區(qū)域,這讓人聯(lián)想到軟計(jì)算機(jī)視覺(jué)中使用的乘法蒙版注意機(jī)制。這些自適應(yīng)PINN的基本思想是在相應(yīng)的損失較高的地方使權(quán)重增加,這是通過(guò)訓(xùn)練網(wǎng)絡(luò)以同時(shí)最小化損失和最大權(quán)重(即在成本表面找到鞍點(diǎn))來(lái)實(shí)現(xiàn)的。文章顯示,這在形式上等效于使用基于懲罰的方法來(lái)解決PDE約束的優(yōu)化問(wèn)題,盡管在某種意義上單調(diào)非遞減懲罰系數(shù)是可訓(xùn)練的。在使用Allen-Cahn剛性PDE進(jìn)行的數(shù)值實(shí)驗(yàn)中,自適應(yīng)PINN在L2誤差方面的表現(xiàn)優(yōu)于其他最新的PINN算法,同時(shí)使用的訓(xùn)練次數(shù)更少。附錄包含Burger's和Helmholtz PDE的其他結(jié)果,這些結(jié)果證實(shí)了Allen-Cahn實(shí)驗(yàn)中觀察到的趨勢(shì)。在成本表面找到鞍點(diǎn)。文章顯示,這在形式上等效于使用基于懲罰的方法來(lái)解決PDE約束的優(yōu)化問(wèn)題,盡管在某種意義上單調(diào)非遞減懲罰系數(shù)是可訓(xùn)練的。在使用Allen-Cahn剛性PDE進(jìn)行的數(shù)值實(shí)驗(yàn)中,自適應(yīng)PINN在L2誤差方面的表現(xiàn)優(yōu)于其他最新的PINN算法,同時(shí)使用的訓(xùn)練次數(shù)更少。附錄包含Burger's和Helmholtz PDE的其他結(jié)果,這些結(jié)果證實(shí)了Allen-Cahn實(shí)驗(yàn)中觀察到的趨勢(shì)。在成本表面找到鞍點(diǎn)。文章顯示,這在形式上等效于使用基于懲罰的方法來(lái)解決PDE約束的優(yōu)化問(wèn)題,盡管在某種意義上單調(diào)非遞減懲罰系數(shù)是可訓(xùn)練的。在使用Allen-Cahn剛性PDE進(jìn)行的數(shù)值實(shí)驗(yàn)中,自適應(yīng)PINN在L2誤差方面的表現(xiàn)優(yōu)于其他最新的PINN算法,同時(shí)使用的訓(xùn)練次數(shù)更少。附錄包含Burger's和Helmholtz PDE的其他結(jié)果,這些結(jié)果證實(shí)了Allen-Cahn實(shí)驗(yàn)中觀察到的趨勢(shì)。在使用Allen-Cahn剛性PDE進(jìn)行的數(shù)值實(shí)驗(yàn)中,自適應(yīng)PINN在L2誤差方面的表現(xiàn)優(yōu)于其他最新的PINN算法,同時(shí)使用的訓(xùn)練次數(shù)更少。附錄包含Burger's和Helmholtz PDE的其他結(jié)果,這些結(jié)果證實(shí)了Allen-Cahn實(shí)驗(yàn)中觀察到的趨勢(shì)。在使用Allen-Cahn剛性PDE進(jìn)行的數(shù)值實(shí)驗(yàn)中,自適應(yīng)PINN在L2誤差方面的表現(xiàn)優(yōu)于其他最新的PINN算法,同時(shí)使用的訓(xùn)練次數(shù)更少。附錄包含Burger's和Helmholtz PDE的其他結(jié)果,這些結(jié)果證實(shí)了Allen-Cahn實(shí)驗(yàn)中觀察到的趨勢(shì)。
論文地址:https://arxiv.org/pdf/2009.04544v2.pdf
代碼地址:https://github.com/levimcclenny/SA-PINNs
3.6 視覺(jué)注意的遞歸模型
Recurrent Models of Visual Attention
主要思想:將卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用于大圖像在計(jì)算上是昂貴的,因?yàn)橛?jì)算量與圖像像素的數(shù)量成線性比例。文章提出了一種新穎的遞歸神經(jīng)網(wǎng)絡(luò)模型,該模型能夠通過(guò)自適應(yīng)選擇區(qū)域或位置的序列并僅以高分辨率處理選定的區(qū)域,從而從圖像或視頻中提取信息。 像卷積神經(jīng)網(wǎng)絡(luò)一樣,提出的模型具有內(nèi)置的平移不變性程度,但是可以獨(dú)立于輸入圖像大小來(lái)控制其執(zhí)行的計(jì)算量。盡管模型是不可微的,但可以使用強(qiáng)化學(xué)習(xí)方法來(lái)學(xué)習(xí)特定于任務(wù)的策略,從而對(duì)其進(jìn)行訓(xùn)練。文章在幾個(gè)圖像分類任務(wù)上評(píng)估文章的模型,其中模型在雜亂圖像上的表現(xiàn)明顯優(yōu)于卷積神經(jīng)網(wǎng)絡(luò)基線,而在動(dòng)態(tài)視覺(jué)控制問(wèn)題上,模型學(xué)習(xí)該模型來(lái)學(xué)習(xí)跟蹤簡(jiǎn)單對(duì)象,而沒(méi)有明確的訓(xùn)練信號(hào)。
論文地址:https://arxiv.org/pdf/1406.6247v1.pdf
代碼地址:https://github.com/kevinzakka/recurrent-visual-attention
4 強(qiáng)注意力機(jī)制(hard-attention)
4.1 基于注意力從街景圖像中提取結(jié)構(gòu)化信息
Attention-based Extraction of Structured Information from Street View Imagery
主要思想:文章提出了一種基于CNN,RNN和新穎的注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)模型,該模型在具有挑戰(zhàn)性的法國(guó)街道名稱標(biāo)志(FSNS)數(shù)據(jù)集上實(shí)現(xiàn)了84.2%的準(zhǔn)確性,大大優(yōu)于之前的最新水平(Smith'16)。達(dá)到72.46%。此外,文章的新方法比以前的方法更簡(jiǎn)單,更通用。 為了證明文章模型的通用性,文章證明了它在源自Google街景的更具挑戰(zhàn)性的數(shù)據(jù)集上也能很好地發(fā)揮作用,該數(shù)據(jù)集的目標(biāo)是從店面中提取商戶名稱。最后,文章研究了使用不同深度的CNN特征提取器所導(dǎo)致的速度/精度折衷。令人驚訝的是,文章發(fā)現(xiàn)更深層次并不一定總是更好(就準(zhǔn)確性和速度而言)。文章生成的模型簡(jiǎn)單,準(zhǔn)確,快速,可以在各種具有挑戰(zhàn)性的現(xiàn)實(shí)文本提取問(wèn)題中大規(guī)模使用。
論文地址:https://arxiv.org/pdf/1704.03549v4.pdf
代碼地址:https://github.com/tensorflow/models
4.2 字符級(jí)的非單調(diào)強(qiáng)注意力
Hard Non-Monotonic Attention for Character-Level Transduction
主要思想:字符級(jí)字符串到字符串的轉(zhuǎn)換是各種NLP任務(wù)的重要組成部分。目標(biāo)是將輸入字符串映射到輸出字符串,其中這些字符串的長(zhǎng)度可能不同,并且具有取自不同字母的字符。 最近的方法已將序列到序列模型與注意機(jī)制一起使用,以了解模型在輸出字符串的生成過(guò)程中應(yīng)關(guān)注輸入字符串的哪些部分。軟注意力和硬單調(diào)注意力都已被使用,但是硬非單調(diào)注意力只被用于其他序列建模任務(wù)中,例如圖像字幕,并且需要隨機(jī)近似來(lái)計(jì)算梯度。在這項(xiàng)工作中,文章引入了一種精確的多項(xiàng)式時(shí)間算法來(lái)邊緣化兩個(gè)字符串之間非單調(diào)對(duì)齊的指數(shù)數(shù)量,這表明辛苦的注意力模型可以看作是經(jīng)典IBM Model 1的神經(jīng)重新參數(shù)化。
論文地址:https://arxiv.org/pdf/1808.10024v2.pdf
代碼地址:https://github.com/shijie-wu/neural-transducer
4.2 提高視覺(jué)硬注意力模型的準(zhǔn)確性
Saccader: Improving Accuracy of Hard Attention Models for Vision
主要思想:提出了一個(gè)新穎的硬注意力模型,文章稱其為Saccader。Saccader的關(guān)鍵是預(yù)培訓(xùn)步驟,該步驟僅需要類標(biāo)簽,并為策略梯度優(yōu)化提供了最初的關(guān)注位置。文章最好的模型縮小了與通用ImageNet基準(zhǔn)的差距,從而實(shí)現(xiàn)了75% top-1和 91%前5名,而只關(guān)注不到三分之一的圖片。
論文地址:https://arxiv.org/pdf/1908.07644v3.pdf
代碼地址:https://github.com/google-research/google-research
4.3 艱巨的任務(wù)克服災(zāi)難性的遺忘
Overcoming catastrophic forgetting with hard attention to the task
主要思想:當(dāng)神經(jīng)網(wǎng)絡(luò)在對(duì)后續(xù)任務(wù)進(jìn)行訓(xùn)練后丟失了在先前任務(wù)中學(xué)習(xí)的信息時(shí),就會(huì)發(fā)生災(zāi)難性的遺忘。對(duì)于具有順序?qū)W習(xí)能力的人工智能系統(tǒng)來(lái)說(shuō),這個(gè)問(wèn)題仍然是一個(gè)障礙。 在本文中,文章提出了一種基于任務(wù)的硬注意力機(jī)制,該機(jī)制可以保留先前任務(wù)的信息,而不會(huì)影響當(dāng)前任務(wù)的學(xué)習(xí)。通過(guò)隨機(jī)梯度下降可以同時(shí)針對(duì)每個(gè)任務(wù)學(xué)習(xí)硬性注意遮罩,并且可以利用以前的遮罩來(lái)調(diào)節(jié)這種學(xué)習(xí)。文章表明,所提出的機(jī)制可有效減少災(zāi)難性遺忘,將電流率降低45%至80%。文章還表明它對(duì)不同的超參數(shù)選擇具有魯棒性,并且它提供了許多監(jiān)視功能。該方法具有控制學(xué)習(xí)知識(shí)的穩(wěn)定性和緊湊性的可能性,文章認(rèn)為這對(duì)于在線學(xué)習(xí)或網(wǎng)絡(luò)壓縮應(yīng)用程序也很有吸引力。
論文地址:https://arxiv.org/pdf/1801.01423v3.pdf
代碼地址:https://github.com/joansj/hat
5 自注意力機(jī)制(self-attention)
5.1 增強(qiáng)的自我注意網(wǎng)絡(luò)
Reinforced Self-Attention Network: a Hybrid of Hard and Soft Attention for Sequence Modeling
主要思想:文章將軟注意力和硬注意力整合到一個(gè)上下文融合模型中,即 "強(qiáng)化自我注意力(ReSA)",以達(dá)到相互促進(jìn)的目的。在ReSA中,硬注意修剪了一個(gè)序列供軟自注意處理,而軟注意則反饋獎(jiǎng)勵(lì)信號(hào)以方便訓(xùn)練硬注意。為此,文章開(kāi)發(fā)了一種名為 "強(qiáng)化序列采樣(RSS) "的新型硬注意力,并行選擇標(biāo)記,并通過(guò)策略梯度進(jìn)行訓(xùn)練。使用兩個(gè)RSS模塊,ReSA有效地提取每對(duì)選擇的tokens之間的稀疏依賴關(guān)系。最后,文章提出了一個(gè)完全基于ReSA的無(wú)RNN/CNN的句子編碼模型--"強(qiáng)化自注意力網(wǎng)絡(luò)(ReSAN)"。它在斯坦福自然語(yǔ)言推理(SNLI)和涉及成分知識(shí)的句子(SICK)數(shù)據(jù)集上都達(dá)到了最領(lǐng)先的性能。
論文地址:https://arxiv.org/pdf/1801.10296v2.pdf
代碼地址:https://github.com/taoshen58/DiSAN
5.2 注意就是您所需要的
Attention Is All You Need
主要思想:優(yōu)勢(shì)序列轉(zhuǎn)導(dǎo)模型基于編碼器-解碼器配置中的復(fù)雜遞歸或卷積神經(jīng)網(wǎng)絡(luò)。表現(xiàn)最佳的模型還通過(guò)注意力機(jī)制連接編碼器和解碼器。 文章提出了一種新的簡(jiǎn)單網(wǎng)絡(luò)體系結(jié)構(gòu),即Transformer,它完全基于注意力機(jī)制,完全消除了遞歸和卷積。在兩個(gè)機(jī)器翻譯任務(wù)上進(jìn)行的實(shí)驗(yàn)表明,這些模型在質(zhì)量上具有優(yōu)勢(shì),同時(shí)具有更高的可并行性,并且所需的訓(xùn)練時(shí)間明顯更少。文章的模型在WMT 2014英德翻譯任務(wù)中達(dá)到了28.4 BLEU,比現(xiàn)有的最佳結(jié)果(包括合奏)提高了2 BLEU。在2014年WMT英語(yǔ)到法語(yǔ)翻譯任務(wù)中,文章的模型在八個(gè)GPU上進(jìn)行了3.5天的訓(xùn)練后,建立了新的單模型最新的BLEU分?jǐn)?shù)41.8。
論文地址:https://arxiv.org/pdf/1706.03762v5.pdf
代碼地址:https://github.com/tensorflow/tensor2tensor
5.3 抽象句摘要的神經(jīng)注意模型
A Neural Attention Model for Abstractive Sentence Summarization
主要思想:基于文本提取的摘要本質(zhì)上受到限制,但是事實(shí)證明,生成樣式的抽象方法難以構(gòu)建。在這項(xiàng)工作中,文章提出了一種完全由數(shù)據(jù)驅(qū)動(dòng)的抽象句子摘要方法。 文章的方法利用了基于自注意力的模型,該模型生成以輸入句子為條件的摘要的每個(gè)單詞。盡管該模型在結(jié)構(gòu)上很簡(jiǎn)單,但是可以輕松地對(duì)其進(jìn)行端到端培訓(xùn),并可以擴(kuò)展為大量的培訓(xùn)數(shù)據(jù)。該模型顯示了DUC-2004共享任務(wù)的性能顯著提高(與幾個(gè)強(qiáng)基準(zhǔn)相比)。
論文地址:https://arxiv.org/pdf/1509.00685v2.pdf
代碼地址:https://github.com/toru34/rushemnlp2015
5.4 通過(guò)共同學(xué)習(xí)對(duì)齊和翻譯的神經(jīng)機(jī)器翻譯
Neural Machine Translation by Jointly Learning to Align and Translate
主要思想:神經(jīng)機(jī)器翻譯是最近提出的機(jī)器翻譯方法。與傳統(tǒng)的統(tǒng)計(jì)機(jī)器翻譯不同,神經(jīng)機(jī)器翻譯的目的是構(gòu)建可以聯(lián)合調(diào)整以最大化翻譯性能的單個(gè)神經(jīng)網(wǎng)絡(luò)。 最近提出的用于神經(jīng)機(jī)器翻譯的模型通常屬于編碼器-解碼器家族,并且由將源句子編碼為固定長(zhǎng)度向量的編碼器組成,解碼器根據(jù)該固定長(zhǎng)度向量生成翻譯。在本文中,文章推測(cè)使用固定長(zhǎng)度向量是提高此基本編碼器-解碼器體系結(jié)構(gòu)性能的瓶頸,并建議通過(guò)允許模型自動(dòng)(軟)搜索對(duì)象的部分來(lái)擴(kuò)展此范圍。與預(yù)測(cè)目標(biāo)單詞相關(guān)的源句子,而不必明確地將這些部分形成為一個(gè)困難的部分。
論文地址:https://arxiv.org/pdf/1409.0473v7.pdf
代碼地址:https://github.com/graykode/nlp-tutorial
5.5 具有相對(duì)位置表示的自我注意
Self-Attention with Relative Position Representations
主要思想:Vaswani等人介紹的Transformer完全依賴于注意力機(jī)制。(2017)取得了機(jī)器翻譯的最新成果。與遞歸和卷積神經(jīng)網(wǎng)絡(luò)相反,它沒(méi)有在其結(jié)構(gòu)中顯式地建模相對(duì)或絕對(duì)位置信息。 相反,它需要在其輸入中添加絕對(duì)位置的表示。在這項(xiàng)工作中,文章提出了一種替代方法,擴(kuò)展了自我注意機(jī)制以有效考慮相對(duì)位置或序列元素之間距離的表示。在WMT 2014英語(yǔ)到德語(yǔ)和英語(yǔ)到法語(yǔ)的翻譯任務(wù)中,這種方法分別比絕對(duì)位置表示法改進(jìn)了1.3 BLEU和0.3 BLEU。值得注意的是,文章觀察到將相對(duì)位置和絕對(duì)位置表示相結(jié)合并不能進(jìn)一步提高翻譯質(zhì)量。文章描述了文章方法的有效實(shí)現(xiàn),并將其轉(zhuǎn)換為關(guān)系感知的自我注意機(jī)制的實(shí)例,該機(jī)制可以推廣到任意圖標(biāo)記的輸入
論文地址:https://arxiv.org/pdf/1803.02155v2.pdf
代碼地址:https://github.com/tensorflow/tensor2tensor
5.6 結(jié)構(gòu)化的自注意力句子嵌入
A Structured Self-attentive Sentence Embedding
主要思想:本文提出了一種通過(guò)引入自我注意來(lái)提取可解釋句子嵌入的新模型。代替使用向量,文章使用二維矩陣表示嵌入,矩陣的每一行都位于句子的不同部分。 文章還為該模型提出了一種自注意力機(jī)制和一個(gè)特殊的正則化術(shù)語(yǔ)。作為副作用,嵌入帶有一種直觀的方式,可以直觀地看到句子的哪些特定部分被編碼到嵌入中。文章在3個(gè)不同的任務(wù)上評(píng)估文章的模型:作者概況分析,情感分類和文本蘊(yùn)涵。結(jié)果表明,在所有這3個(gè)任務(wù)中,與其他句子嵌入方法相比,文章的模型產(chǎn)生了顯著的性能提升。
論文地址:https://arxiv.org/pdf/1703.03130v1.pdf
代碼地址:https://github.com/facebookresearch/pytext
猜您喜歡:
等你著陸!【GAN生成對(duì)抗網(wǎng)絡(luò)】知識(shí)星球!
CVPR 2021 | GAN的說(shuō)話人驅(qū)動(dòng)、3D人臉論文匯總
CVPR 2021 | 圖像轉(zhuǎn)換 今如何?幾篇GAN論文
【CVPR 2021】通過(guò)GAN提升人臉識(shí)別的遺留難題
CVPR 2021生成對(duì)抗網(wǎng)絡(luò)GAN部分論文匯總
最新最全20篇!基于 StyleGAN 改進(jìn)或應(yīng)用相關(guān)論文
附下載 | 經(jīng)典《Think Python》中文版
附下載 | 《Pytorch模型訓(xùn)練實(shí)用教程》
附下載 | 最新2020李沐《動(dòng)手學(xué)深度學(xué)習(xí)》
附下載 | 《可解釋的機(jī)器學(xué)習(xí)》中文版
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實(shí)戰(zhàn)》