
復(fù)旦大學(xué)邱錫鵬組最新綜述:A Survey of Transformers!
作者 | Tnil@知乎
編輯 | NewBeeNLP
轉(zhuǎn)眼Transformer模型被提出了4年了。依靠弱歸納偏置、易于并行的結(jié)構(gòu),Transformer已經(jīng)成為了NLP領(lǐng)域的寵兒,并且最近在CV等領(lǐng)域的潛能也在逐漸被挖掘。盡管Transformer已經(jīng)被證明有很好的通用性,但它也存在一些明顯的問題,例如:
核心模塊自注意力對(duì)輸入序列長(zhǎng)度有平方級(jí)別的復(fù)雜度,這使得Transformer對(duì)長(zhǎng)序列應(yīng)用不友好。例如一個(gè)簡(jiǎn)單的32x32圖像展開就會(huì)包括1024個(gè)輸入元素,一個(gè)長(zhǎng)文檔文本序列可能有成千上萬個(gè)字,因此有大量現(xiàn)有工作提出了輕量化的注意力變體(例如稀疏注意力),或者采用『分而治之』的思路(例如引入recurrence);
與卷積網(wǎng)絡(luò)和循環(huán)網(wǎng)絡(luò)不同,Transformer結(jié)構(gòu)幾乎沒有什么歸納偏置。這個(gè)性質(zhì)雖然帶來很強(qiáng)的通用性,但在小數(shù)據(jù)上卻有更高的過擬合風(fēng)險(xiǎn),因此可能需要引入結(jié)構(gòu)先驗(yàn)、正則化,或者使用無監(jiān)督預(yù)訓(xùn)練。
近幾年涌現(xiàn)了很多Transformer的變體,各自從不同的角度來改良Transformer,使其在計(jì)算上或者資源需求上更友好,或者修改Transformer的部分模塊機(jī)制增大模型容量等等。
但是,很多剛接觸Transformer的研究人員很難直觀地了解現(xiàn)有的Transformer變體,例如前陣子有讀者私信我問Transformer相關(guān)的問題,聊了一會(huì)兒才發(fā)現(xiàn)他不知道Transformer中的layer norm也有pre-LN和post-LN兩種變體。因此,我們認(rèn)為很有必要對(duì)現(xiàn)有的各種Transformer變體做一次整理,于是產(chǎn)生了一篇survey ,現(xiàn)在掛在了arxiv上:
A Survey of Transformers[1] http://arxiv.org/abs/2106.04554

在這篇文章之前,已經(jīng)有一些很好的對(duì)PTM和Transformer應(yīng)用的綜述(例如Pre-trained Models for Natural Language Processing: A Survey』[2]和 『A Survey on Visual Transformer』[3])。在這篇文章中,我們把重心放在對(duì)Transformer結(jié)構(gòu)(模塊級(jí)別和架構(gòu)級(jí)別)的改良上,包括對(duì)Attention模塊的諸多改良、各種位置表示方法等。
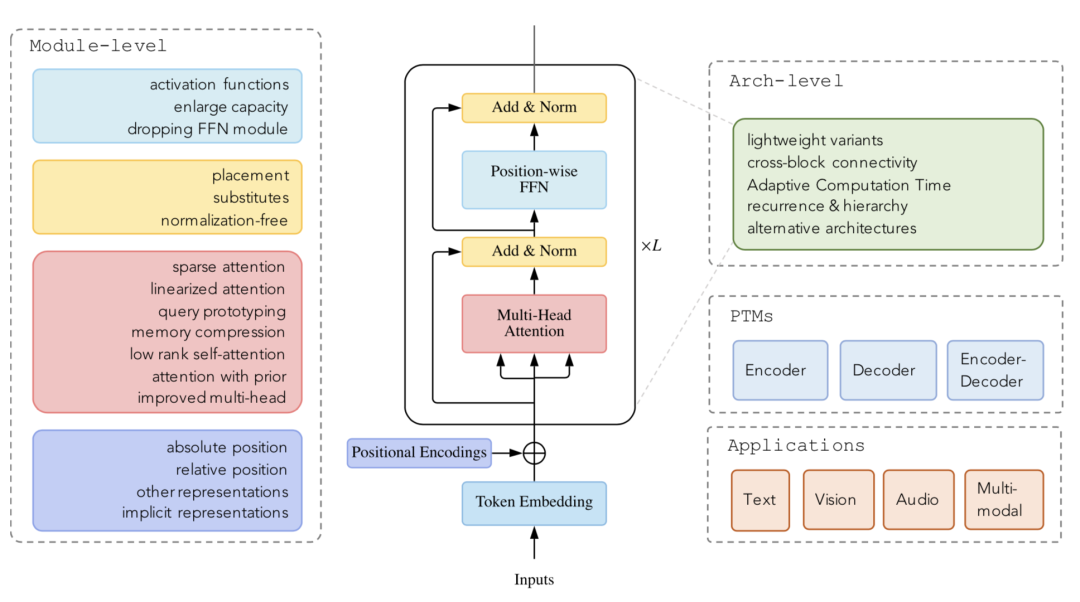
Transformer變體分類
值得一提的是,Google去年放出過一篇關(guān)于Transformer的綜述(『Efficient Transformers: A Survey』[4]),主要關(guān)注了Attention模塊的效率問題(這在我們的綜述中也覆蓋了)。雖然是一篇很好的review,但是筆者認(rèn)為它對(duì)于Attention變體的分類有一些模糊,例如作者將Compressive Transformer、ETC和Longformer這一類工作、以及Memory Compressed Attention都?xì)w類為一種基于Memory的改進(jìn),筆者認(rèn)為memory在這幾種方法中各自有不同的含義,使用Memory來概括很難捕捉到方法的本質(zhì)。我們的文章對(duì)這幾個(gè)方法有不同的分類:
Compressive Transformer是一種『分而治之』的架構(gòu)級(jí)別的改進(jìn),相當(dāng)于在Transformer基礎(chǔ)上添加了一個(gè)wrapper來增大有效上下文的長(zhǎng)度;
ETC和Longformer一類方法是一種稀疏注意力的改進(jìn),主要思路是對(duì)標(biāo)準(zhǔn)注意力代表的全鏈接二分圖的連接作稀疏化的處理;
Set Transformer、Memory Compressed Attention、Linformer對(duì)應(yīng)一種對(duì)KV memory壓縮的方法,思路是縮短注意力矩陣的寬。
論文中完整的對(duì)Transformer變體分類體系概覽如下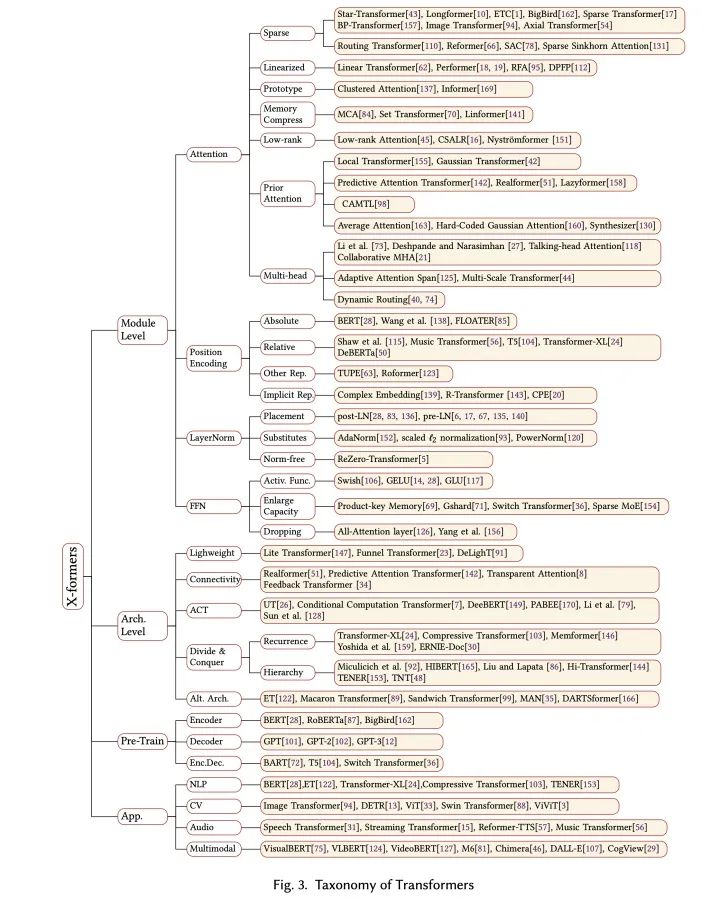
本文參考資料
A Survey of Transformers: http://arxiv.org/abs/2106.04554
[2]Pre-trained Models for Natural Language Processing: A Survey: https://arxiv.org/abs/2003.08271
[3]A Survey on Visual Transformer: https://arxiv.org/abs/2012.12556
[4]Efficient Transformers: A Survey: https://arxiv.org/abs/2009.06732
[5]A Survey of Transformers: https://arxiv.org/abs/2106.04554
- END -
